代码+通俗理解attention机制

 最新推荐文章于 2024-01-31 17:25:50 发布
最新推荐文章于 2024-01-31 17:25:50 发布
 阅读量1.6k
阅读量1.6k
 收藏
7
收藏
7


 点赞数
1
点赞数
1



attention机制在机器学习领域人尽皆知,并且逐渐成为了从NLP扩散到各个领域的科研密码,但是一直对attention的理解不是很深入。尤其是看网上各种各样对论文的翻译和截图,看的云里雾里,因此记录一下attention到底是什么以及其计算过程。
1 attention在直观理解上的作用
attention的作用是在一段文本中注意到关键的字词,或者在图片中注意到局部信息,比如:


因此,attention是用于特征增强的技术,即突出强调单个样本中部分特征的信息。然而,实现这一点并不是像传统数据增强算法一样对单个样本进行操作得到的,而是在一个batch上对多个样本进行操作得到的。
2 attention在数据层面上的作用
将attention看做一个黑盒模型,其在数据层面上的作用就是将1个batch的样本特征,通过变换后得到另一个batch的样本特征,样本数量不会改变,但是样本的特征数量可能会变多或者变少。因此可以理解为做了和全部样本归一化、全部样本缩放一样的操作,只不过attention机制后的样本有了一些新的变化:即更容易被机器训练或者识别了。

3 attention的流程
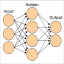
attention的种类随着各种变化有很多,在此只分析最传统的attention机制作为代表,相比于这个图:

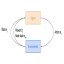
我更喜欢下面这个图代表attention的流程:

图中绿色的三个权重矩阵是生成Key、Query、Value的关键,需要训练学习出来。
整个流程用一个公式表示为:
A
t
t
e
n
t
i
o
n
(
X
)
=
s
o
f
t
m
a
x
(
Q
u
e
r
y
T
K
e
y
d
(
Q
u
e
r
y
,
K
e
y
)
)
V
a
l
u
e
Attention(X)=softmax(\frac{Query^TKey}{\sqrt{d_{(Query,Key)}}})Value
Attention(X)=softmax(d(Query,Key)QueryTKey)Value
其中
d
(
Q
u
e
r
y
,
K
e
y
)
d_{(Query,Key)}
d(Query,Key)代表的就是Query和Key的维度,二者是一样的,
1
d
(
Q
u
e
r
y
,
K
e
y
)
\frac{1}{\sqrt{d_{(Query,Key)}}}
d(Query,Key)1的意思类似对方针归一化,以方便softmax。
使用代码表示上述流程,可以表示为:
import torch
# 本质上Attention是对一个batch样本中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数
# 三个样本x1 x2 x3
x1 = torch.tensor([1.,2.,3.,4.,5.])
x2 = torch.tensor([2.,3.,4.,5.,6.])
x3 = torch.tensor([0.,0.,0.,0.,0.])
# 堆成一个batch
X = torch.stack([x1,x2,x3], dim=0) # shape 3*5
# 三个attention的矩阵Wq Wk Wv 5*3
# query:
Wq = torch.tensor([
[0,1,0],
[1,0,3],
[3,6,0],
[1,4,5],
[1,3,0]
], dtype=torch.float32)
# key:
Wk = torch.tensor([
[1,1,0],
[6,6,3],
[3,0,0],
[0,1,0],
[1,1,1]
], dtype=torch.float32)
# value:
Wv = torch.tensor([
[0,1,0],
[0,0,3],
[0,1,0],
[0,4,0],
[0,3,1]
], dtype=torch.float32)
# 条件都具备了,下面开始执行self-attention的计算流程
# 1-根据X计算query key value
query = torch.mm(X, Wq) # shape 3*5 * 5*3 = 3*3
key = torch.mm(X, Wk)
value = torch.mm(X, Wv)
# 2-计算attentiond的score=key*value
score = torch.mm(query, key) # shape 3*3 * 3*3 = 3*3
softmax_score = torch.softmax(score, dim=1) # shape 3*3 -> 3*3
# dim = 1 相当于矩阵的行不变,dim=1,dim指的是张量(列表)的dim
# 3-乘以value,得到最后的attention
attention = torch.mm(softmax_score, value)
print("初始值X:",X, '\n','attention结果:', attention)
4 attention的本质
分析一下attention机制的本质:在一个batch的样本集X中,利用样本 x 1 , x 2 , . . . x n x_1,x_2,...x_n x1,x2,...xn的关系,对各个样本中的特征向量进行重构,使得重构后的向量中特征更加明显,更方便机器进行识别。这个过程就相当于让机器戴了一层滤镜一样。
如何实现上面的过程?主要就是通过将原始样本集X先变换成三个相同尺寸的张量key,query,value,想象一个做数学题的场景:key就是会做的不同题目的完整解法,query就是要做的各个题目,value可以看做会的不同的做题技巧(也就是做题人本身),那么做题的过程就是先计算各个key与各个query的相似度,然后根据这个相似度去在大脑里搜寻应该采用哪些做题技巧的组合更好。















 1275
1275
 北京航空航天大学
北京航空航天大学





















 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: 不知道 算法 技能树是否可以帮到你:https://edu.csdn.net/skill/algorithm?utm_source=AI_act_algorithm
普通攻击往后拉: 动态规划还是应该尽量思考一两个递推位置的,少在里面用循环去做,尽量用选or不选的角度去做,少用选哪个的思路