

论文地址:https://arxiv.org/abs/2205.13535
代码地址:http://www.shoufachen.com/adaptformer-page/
导读
尽管经过预训练的视觉Transformer(ViT)在计算机视觉方面取得了巨大成功,但将ViT适应各种图像和视频任务仍具有挑战性,因为ViT的计算和存储负担很重,每个模型都需要独立地微调以适应不同的任务,从而限制了其在不同领域的可迁移性。为了应对这一挑战,作者提出了一种有效的Transformer自适应方法,即AdaptFormer,它可以将预训练好的VIT有效地适应许多不同的图像和视频任务。
它具有比现有技术相比的几个优点:
首先,AdaptFormer引入了轻量级模块,只向ViT添加了不到2%的额外参数,而它能够在不更新其原始预训练参数的情况下增加ViT的可迁移性,在动作识别基准上显著优于现有的完全微调的模型。
其次,它可以在不同的Transformer中即插即用,并可扩展到许多视觉任务。
第三,在五个图像和视频数据集上进行的大量实验表明,AdaptFormer在很大程度上改善了目标域中的ViTs。例如,当只更新1.5%的额外参数时,与Something-Something v2和HMDB51上的完全优化模型相比,它分别实现了约10%和19%的相对改进。
贡献
采用通用神经模型来处理各种不同的任务变得非常流行,因为它有助于减少对任务特定模型设计和训练的需求。最近,Transformer在这一目标上显示出巨大的潜力,因为它在各个领域都取得了成功,例如自然语言处理(NLP),视觉识别,密集预测,生成对抗网络(GAN),强化学习(RL)等等。然而,计算机视觉领域的现有文献倾向于关注具有任务特定权重场景的网络,其中单个网络用于从头开始训练或在特定数据集上完全微调。但是当任务数量增加时,不可能为每个数据集维护单独的模型权重,尤其是SOTA模型的模型容量不断增加(例如,ViT-g/14,参数超过18亿)。
与现有技术不同的是,作者朝着开发具有几乎相同权重的相同网络的方向迈进,并且通过只微调不到2%的参数来实现比完全微调方法更高的性能,剩余的98%以上的参数在不同的任务中共享。使用单一模型学习通用表示有两个挑战。第一个挑战在预训练阶段,这需要能够学习易于应用于许多任务的良好广义表示的算法。最近的自监督学习算法在一定程度上解决了这一问题。第二个是作者在这项工作中主要关注的问题,即构建一个有效的pipeline,通过尽可能少地调整参数并保持剩下参数不变,可以使在预训练阶段获得的模型适应各种下游任务。
虽然在NLP中已经广泛研究了微调预训练模型,但该主题在视觉领域中很少探讨,其中模型参数的全部微调仍然是适应视觉Transformer的主要策略。然而,由于它为每个任务分配了一组独立的权重,因此全部微调无法满足通用表示的目标。Linear probing是一种简单的方法,通过为每项任务调整一个特定的轻型分类头来维持预训练好的模型。然而,Linear probing往往表现不佳。
在这项工作中,作者提出了一个轻量级模块,即AdaptFormer,通过更新AdaptFormer的权重来适应视觉Transformer。作者从模型的角度引入可学习的参数,这与VPT不同,因为VPT将可学习的参数插入到token空间中。本文的AdaptFormer在概念上简单而有效。它由两个完全连接层,一个非线性激活函数和一个缩放因子组成。该模块与原始ViT模型的前馈网络 (FFN) 并行设置。当处理图像和视频数据的可缩放的视觉token时,这种设计对于模型迁移是有效的。
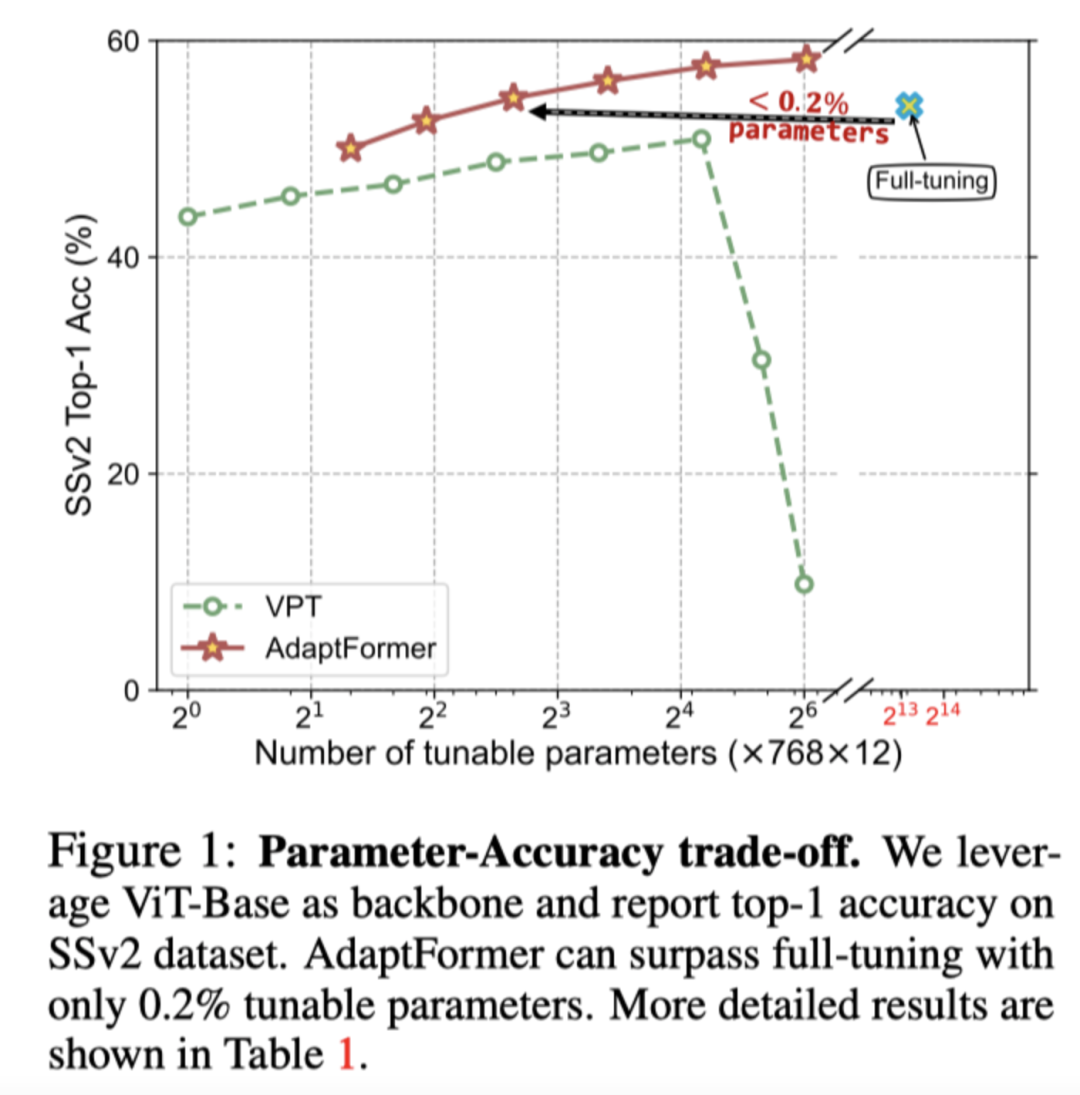
如上图所示,相比于完全微调整个模型,只微调0.1%参数的AdaptFormer达到了相似的性能。同时,AdaptFormer的可调参数不到2%时,在top-1精度上就超过了完全微调解决方案。
本文的主要贡献总结如下:
(1)作者提出了一个简单而有效的框架,即AdaptFormer,用于使视觉Transformer适应各种下游视觉识别任务,并避免彼此之间的干扰。这是第一项探索视频动作识别中高效微调的工作。
(2) 作者消融了多个设计选择,并证明了AdaptFormer在参数放大时具有优异的鲁棒性。
(3) 对各种下游任务的大量实验表明,AdaptFormer显著优于现有的微调方法。
方法
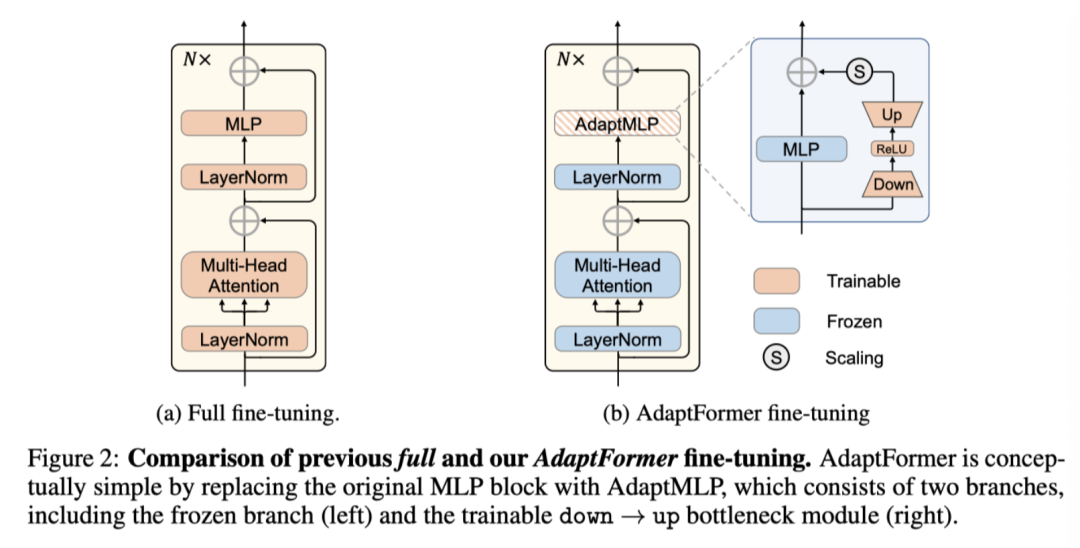
作者提出了AdaptFormer,用于在图像和视频领域有效地将预训练好的大型视觉Transformer模型迁移到下游任务。AdaptFormer只需微调少量额外参数,就能获得强大的迁移学习能力,避免任务之间的灾难性干扰。作者在上图b中展示了AdaptFormer的总体框架。
3.1 Preliminary and Notation
vanilla vision Transformer上由一个patch嵌入层和几个连续连接的编码器组成,如上图a所示。给定图像x,patch嵌入层首先将样本x分割并flatten成连续的patch xp,其中(H,W)表示输入图像的高度和宽度,(P,P)是每个图像patch的分辨率,d表示输出通道,N=HW/P 2是图像token的数量。预加的[CLS] token和图像tokenxp的整体组合被进一步馈送到Transformer编码器中用于注意力计算。
每个Transformer编码器主要由两种类型的子层组成,即多头自注意力层(MHSA)和MLP层。在MHSA中,token被线性投影并进一步重新表示为三个向量,即Q、K和V。通过以下方式对Q、K和V进行自注意计算:
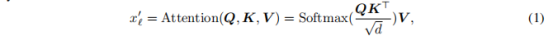
其中是第l层生成的token。输出token被进一步送到LayerNorm和MLP块,MLP块由两个全连接层组成,中间有一个GELU激活。表示如下:
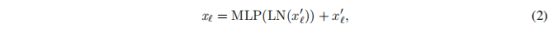
其中是l个编码器块的输出。在最后一个transformer层,使用[CLS] token进行最终对象识别。在本文的工作中,作者将MLP层替换为AdapteMLP模块,以实现高效的微调。
3.2 AdaptFormer
Architecture
AdaptFormer的设计原理简单而有效,如上图b所示。与普通的全微调方案相比,AdaptFormer用AdaptMLP代替了Transformer编码器中的MLP块,AdaptMLP由两个子分支组成。左分支中的MLP层与原始网络相同,而右分支是另外引入的用于任务特定优化的轻量级模块。具体而言,右分支设计为瓶颈结构,用于限制参数数量,包括参数为Wd的下投影层,参数为Wu的上投影层,其中d是瓶颈中间维度。此外,还有一个ReLU层在这些投影层之间,用于增强非线性特性:
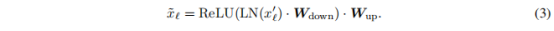
然后,通过残差连接将特征和与融合:
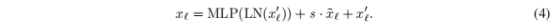
Fine-tuning
在微调阶段,原始模型部件(上图b中的蓝色块)从预训练的checkpoint加载权重,并保持不变,避免下游任务之间的交互。新添加的参数(橙色块)在特定数据域上随任务特定损失进行更新。
Inference
在微调后,作者保持共享参数固定,并额外加载前一阶段微调的额外参数的权重。在引入的轻量级模块的帮助下,单个整体模型能够适应多个任务。
3.3 Discussion
Tunable parameters analysis
本文的AdaptMLP模块是轻量级的。每层引入的参数总数为。与d相比,中间尺寸是一个较小的值。由于大多数共享参数是固定的,并且新引入的参数数量很少(小于预训练的模型参数的2%),因此当添加更多下游任务时,总模型大小增长几乎可以忽略不计。
Applicability
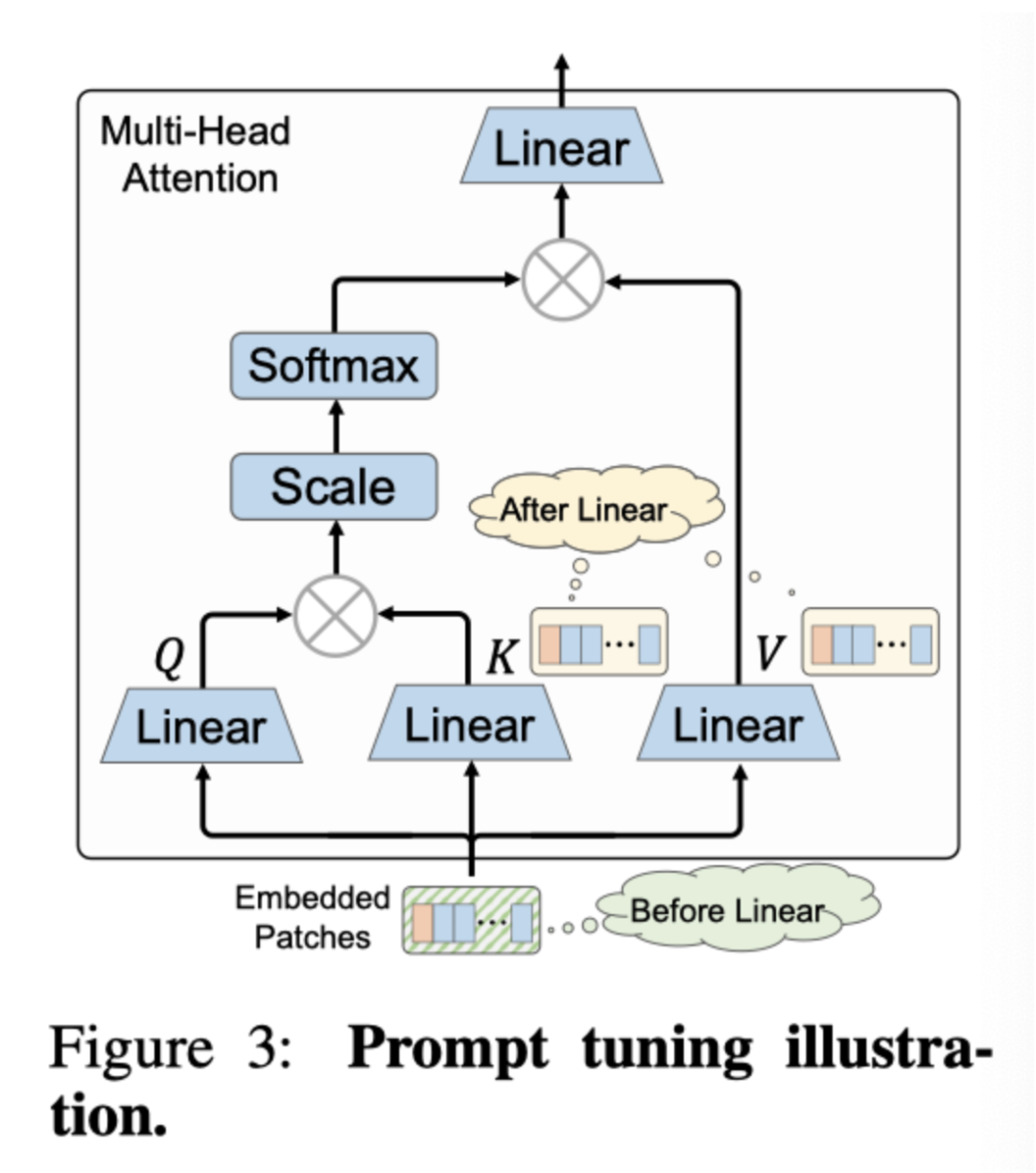
作者注意到AdaptMLP是一个即插即用模块,可以自适应地插入现有流行的vision transformer架构中。因为即使不同的ViT可能在MHSA架构中有所不同,但所有主干网络都有相同的MLP层。与本文的方法相比,作者注意到最近的prompt相关方法将可训练参数插入到token空间中,如上图所示。他们在线性投影之前将可学习的参数预先添加到嵌入的token中,或者在线性投影之后将添加到键值token中。因此,prompt相关方法不能直接适用于特殊MHSA变体,尤其是考虑金字塔空间的方法。此外,作者根据实验结果观察到,当patch token的数量从图像到视频规模增长时,prompt相关方法的性能不佳,
总的来说,本文提出了一种在一组可伸缩的视觉识别任务(如图像域和视频域)上微调预训练的视觉Transformer的策略。它为微调添加了有限的可学习参数,同时实现了与完全微调策略相当甚至更好的性能。此外,AdaptFormer可以作为一个通用模块,用于各种各样的识别任务。
实验
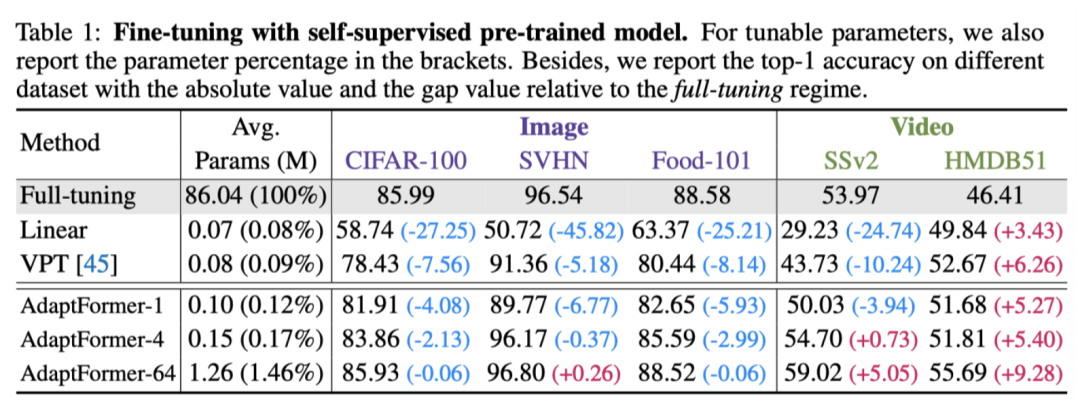
作者将上表中不同微调方法的性能与通过自监督范式预训练的主干进行比较。结果表明,AdaptFormer始终优于linear probing和Visual Prompt tuning(VPT)方法。
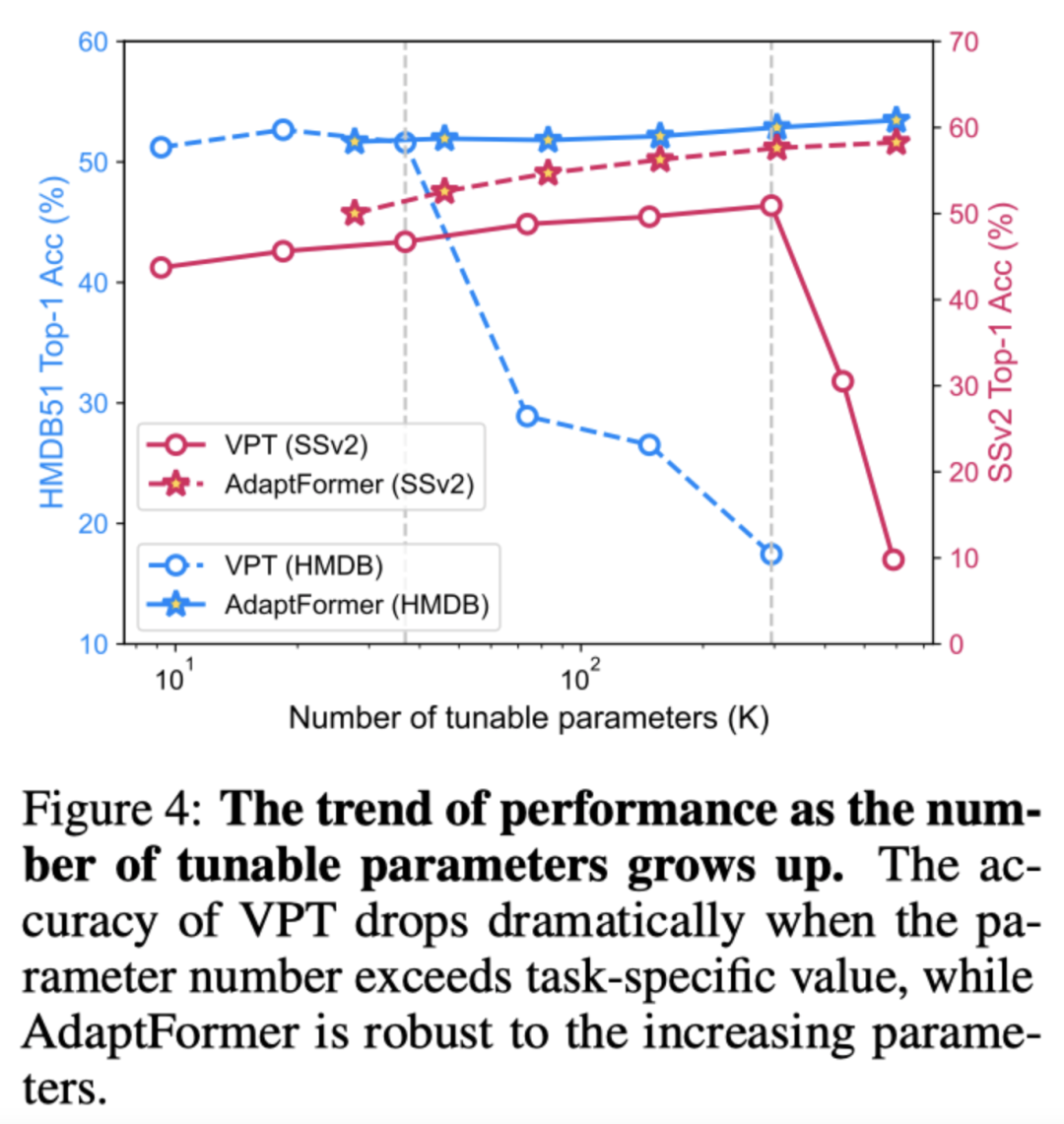
如上图所示,作者在SSv2和HMDB-51数据集上进行了可调参数实验。可以看出,相比于VPT方法,本文的方法在两个数据集上都能达到更高的性能。
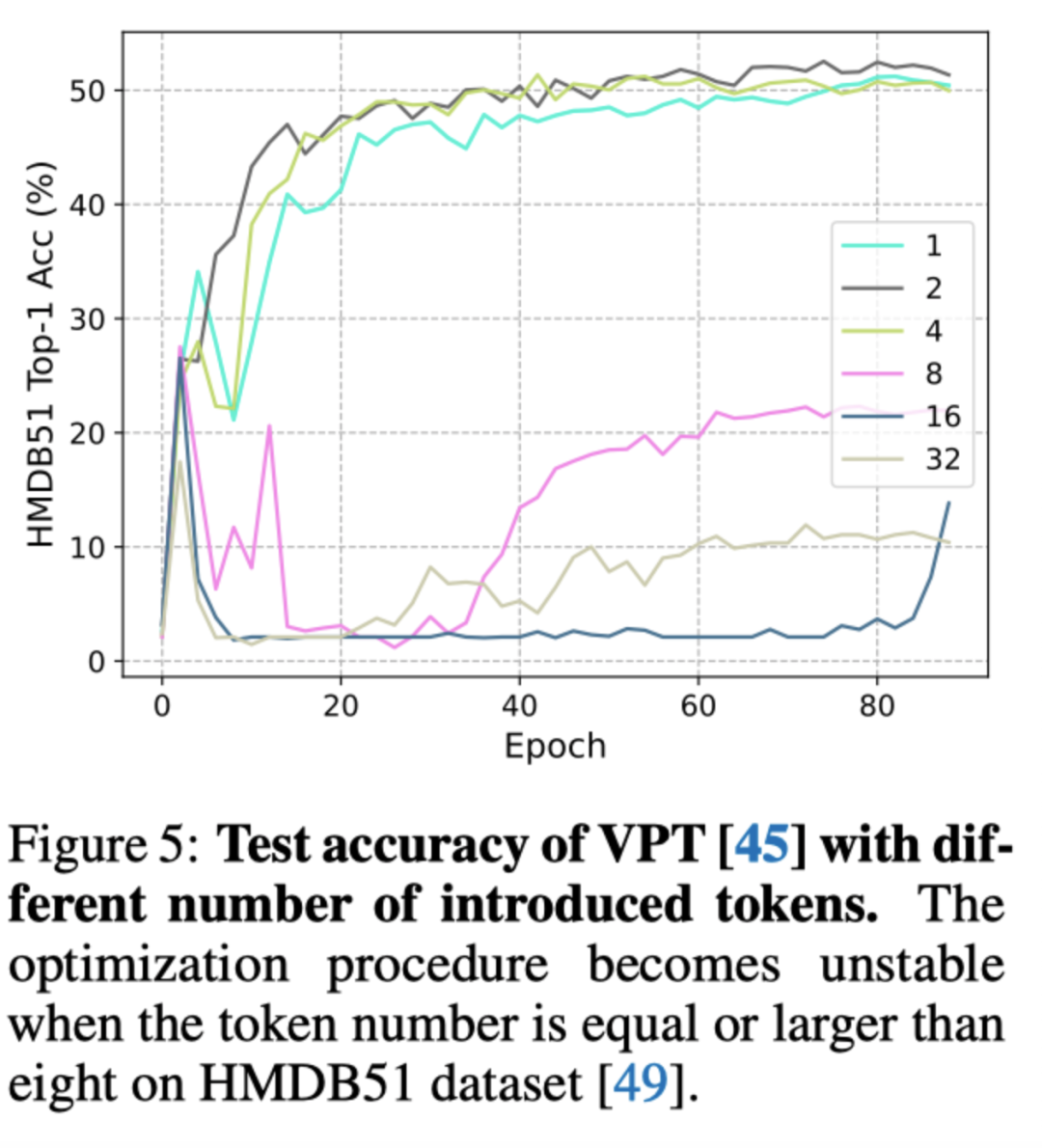
通过监测训练阶段的测试精度,作者进一步研究了VPT的优化过程。如上图所示,作者逐渐增加VPT中的token数量,并绘制每个epoch的Top-1精度。当token数小于或等于4时,训练阶段是稳定的,例如{1,2,4}。然而,当数字变为8或更大时,例如{8,16,32},训练过程在大约第十个epoch时崩溃,在训练阶段结束时表现不佳。
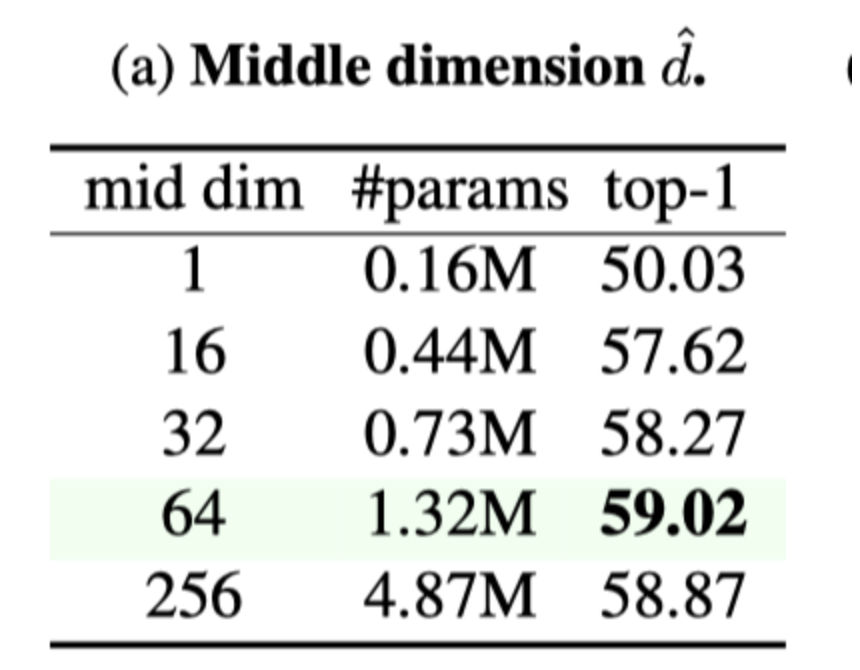
中间维度控制了AdaptFormer引入参数的数量。小的中间维度引入的参数较少,可能会带来性能成损失。作者在中间特征维度上进行消融来研究这种影响。如上表a所示,当中间尺寸增加到64时,精度持续提高,当中间尺寸约为64时,精度达到饱和点。
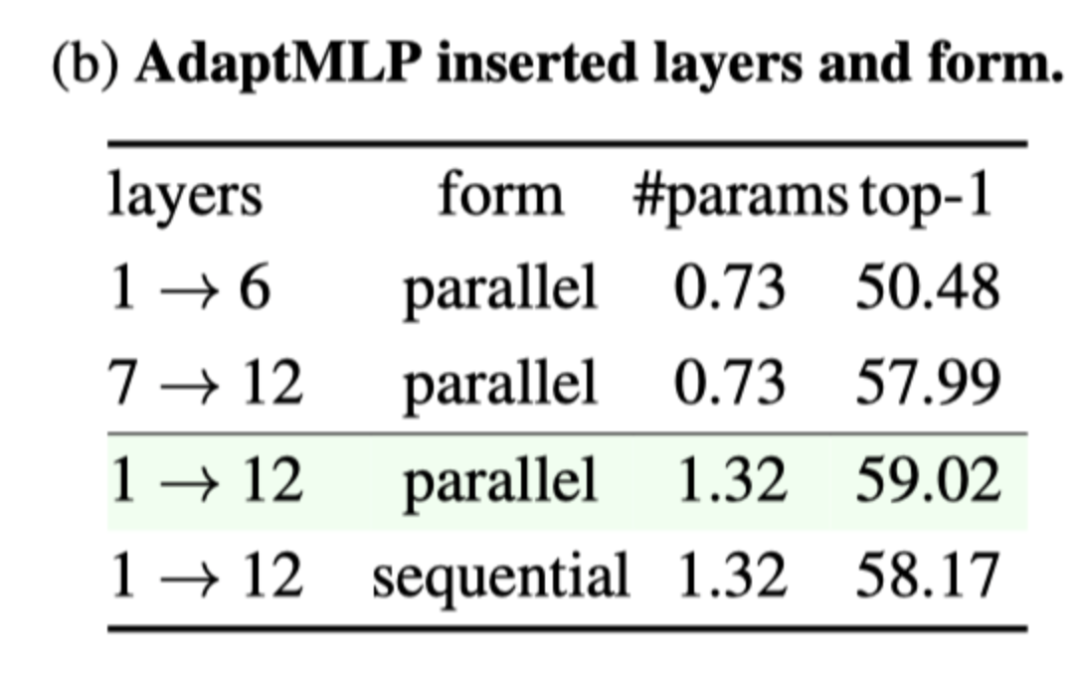
从上表中,我们观察到AdaptFormer的性能与添加的层数呈正相关。此外,当引入相同数量的层时,AdapterFormer更喜欢网络的顶部(远离输入图像的部分)而不是底部。
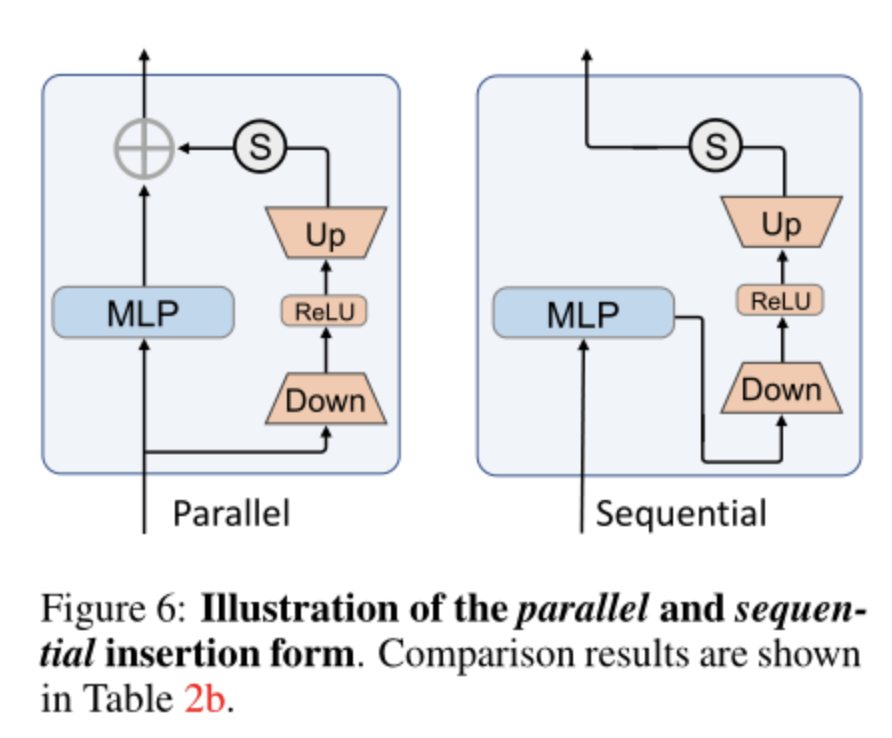
作者通过比较上图所示的并行和串行实例来研究插入方法。如上表所示,并行AdaptFormer比串行AdaptFormer的精度高出0.85%。
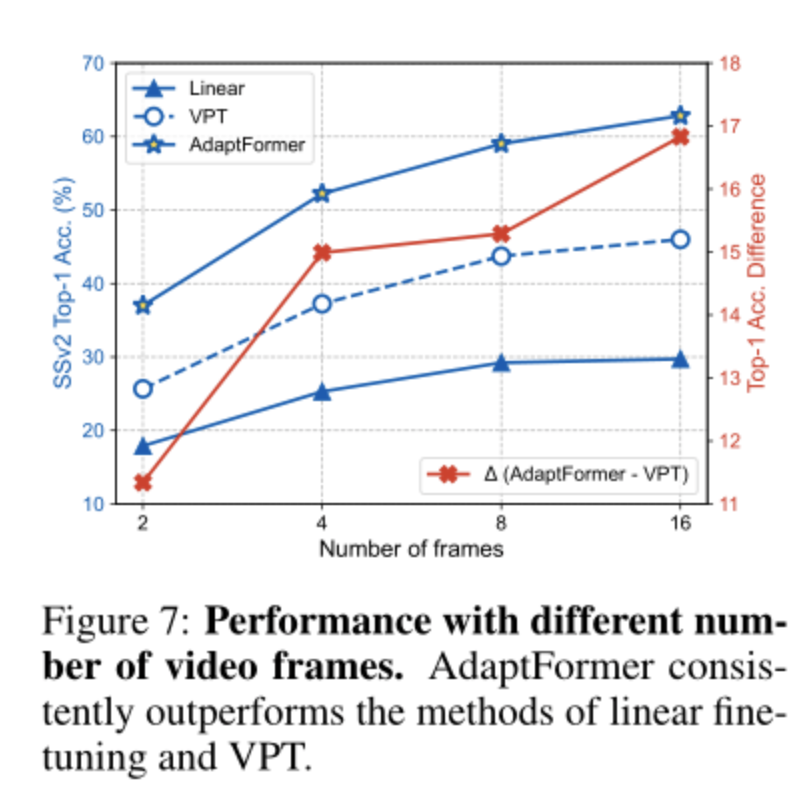
对于普通ViT,嵌入patch token的数量随着视频帧的数量线性增加。作者使用不同数量的帧进行了实验,即{2,4,8},结果如上图所示。作者观察到,增加帧数对所有这三种微调方法都是有益的。然而,AdaptFormer始终优于线性方式和VPT方法。
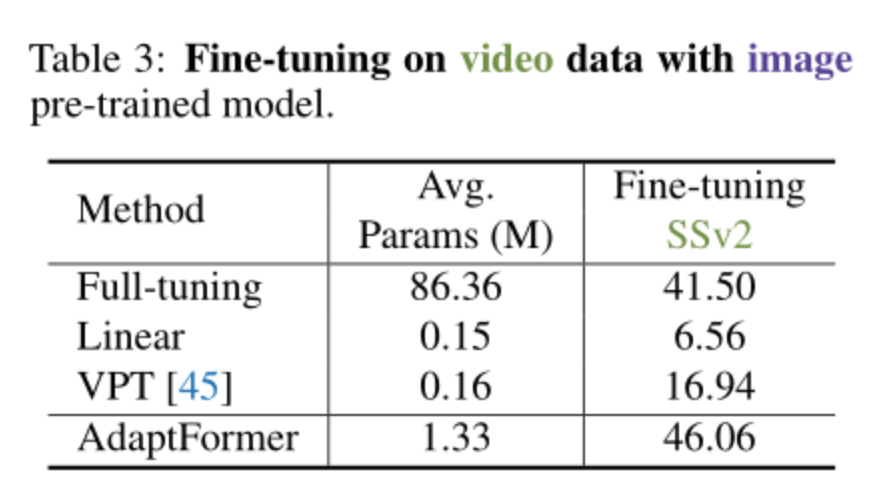
作者使用在ImagNet-21k上预训练的模型在SSv2和HMDB-51上进行动作识别。如上表所示,AdaptFormer对模态引起的域迁移具有鲁棒性。
5. 总结
本文提出了一个概念简单但有效的框架AdaptFormer,用于有效地将预训练的视觉Transformer(ViT)主干迁移到可伸缩的视觉识别任务。通过引入AdaptMLP,本文的AdaptFormer能够调整轻量级模块,以生成适应多个下游任务的特征。在五个数据集(包括图像和视频域)上进行的大量实验验证了本文提出的方法能够以较小的计算成本提高ViT的可迁移性。

评论
沙发等你来抢