引言
在自动驾驶汽车或者移动机器人上,通常会配备许多种传感器,比如:光学相机、激光雷达、毫米波雷达等。由于不同传感器的数据形式不同,如RGB图像,点云等,不同模态的数据的信息密度和特性也不同,如何能够有效地融合各个模态的数据使得车或机器人能够准备地感知周围的场景是一个非常关键的问题。

论文名称:
FUTR3D: A Unified Sensor Fusion Framework for 3D Detection
论文链接:
https://arxiv.org/abs/2203.10642
网站链接:
https://tsinghua-mars-lab.github.io/futr3d/
之前多模态融合的工作主要是为特定的传感器组合设计算法,比如用图像去增强点云(PointPainting,MVP)、用图像检测框去辅助点云检测(Frustum PointNet)等。而在FUTR3D中,我们试着在BEV下构建一个通用的可容纳各种不同传感器的3D目标检测框架。
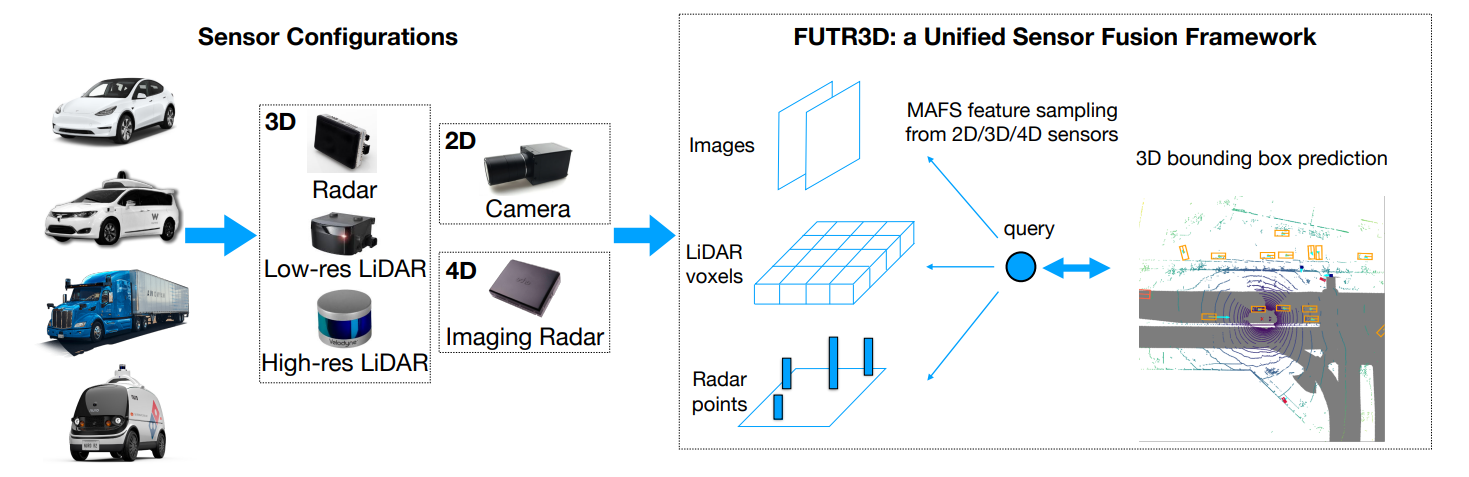
FUTR3D的主要贡献如下:
- 通用框架。 FUTR3D是第一个通用的可适应各种不同传感器的端到端的三维目标检测框架。
- 有效性。 它在Camera, LiDAR, Camera+LiDAR , Camera+Radar等不同的传感器组合情况下都能实现领先效果。
- 低成本。 FUTR3D在Camera+4线LiDAR的情况下能够超过32线LiDAR的结果,因此能够促进低成本的自动驾驶系统。
FUTR3D方案
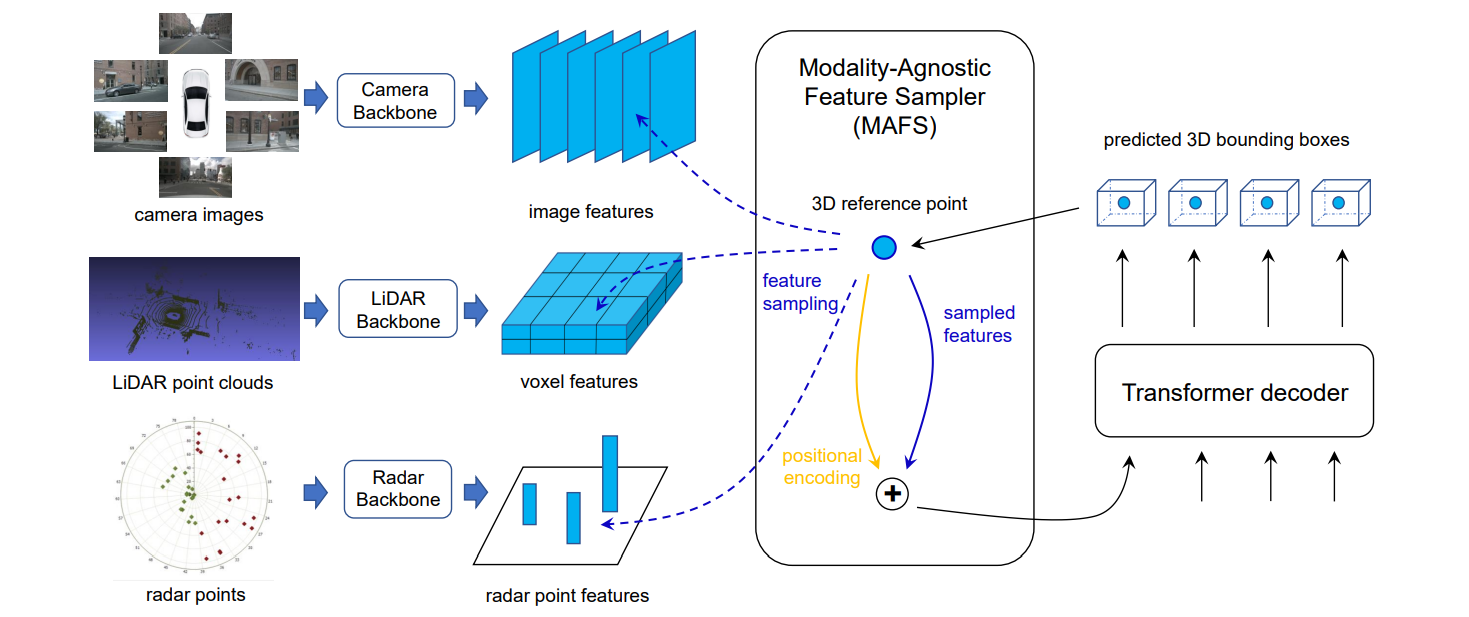
FUTR3D主要包括Modality-Specific Feature Extractor, Modality-Agnostic Feature Sampler和Loss。
Modality-Specific Feature Extractor
对于不同的传感器输入数据,我们根据它们各自的模态形式分别用不同的backbone去提取它们的特征。
- 对于camera images,采用ResNet50/101和FPN来对每张图片提取多尺度的特征图。
- 对于LiDAR point clouds,用PointPillar或者VoxelNet来提取点云的特征。
- 对于Radar point clouds,用3层MLP来提取每个Radar point的特征。