

Singular Value Fine-tuning: Few-shot Segmentation requires Few-parameters Fine-tuning
论文:https://arxiv.org/abs/2206.06122
代码:https://github.com/syp2ysy/SVF
1、引言
小样本分割的目的是利用少量densely-annotated样本分割出图像中的新类objects。在之前的工作中研究人员通过设计不同的分割头,使模型从少量样本中学习到尽量多的关于新类的知识,以提升few-shot seg的性能。然而众多few-shot seg的方法中有一个通用的设置---freeze backbone(冻结主干网络的参数)。因此传统few-shot seg模型的范式就是freeze backbone + seg head。众所周知,多数任务中finetune 会使backbone更加适应下游任务从而取得优越的性能。因此我们产生了疑惑-- few-shot seg 任务中freeze backbone是否是唯一的选择?能否通过fine-tune backbone来提高few-shot seg model的性能?
我们把传统的fine-tune backbone的方法分为fully fine-tune(微调整个backbone)和part fine-tune(微调backbone的部分参数)。因此我们在同一个few-shot seg model上对不同的fine-tune方法进行了实验。实验结果如下所示;我们发现无论是那种fine-tune方式都会出现过拟合现象 (training set表现优秀,test set表现拉夸)。
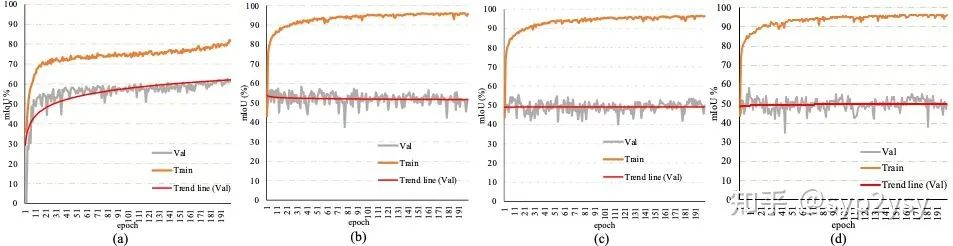
(a) free-backbone, (b)fine-tuning part layer, (c) fine-tuning part conv (d) fully fine-tune
我们猜测导致这种结果出现的原因有两个,第一个是由于few-shot seg独特的属性,training set中学习的类,是不会在test set中出现的,因此传统fine-tune方法使backbone更加适应training set中的类,从而影响了模型泛化到test set的能力;第二个是由于few-shot中的样本数量太少,从而极容易导致过拟合情况的发生。
为了找到few-shot seg中合适的fine-tune方法,我们尝试分析freeze backbone的成功原因。因为few-shot seg中学习的所有类别的知识(我们称之为语义线索)都存在于pre-train weight中(因为voc & coco中所有类别均在imagenet中的出现过)。所以freeze backbone可以保证pre-train中的语义线索不会丢失。但是有一个新问题出现--pre-train中所有的语义线索都是有利于few-shot seg 任务的吗?我们认为并不是的,那如何动态调整pre-train中语义线索的重要程度并不改变pre-train中的语义线索成为我们设计新fine-tune方法的初衷。
pre-trian weight实际上是不同的张量组成,那么如何提取weight中的语义线索,也就转化成为如何从一个张量中获取其中的主成分。我们想到了SVD分解,因为SVD分解会得到特征值和特征向量,而这与我们的初衷契合,特征值可以表示初始pre-train中不同语义线索的权重,而特征向量表示pre-train中不同的语义线索。这样的话我们只需要在训练过程中fine-tune pre-train weight的特征值就可以了。这就是我们SVF的核心思想。
2、方法介绍
核心思想--不改变pre-train中的语义线索,而改变不同语义线索的权重;
使用工具--SVD分解
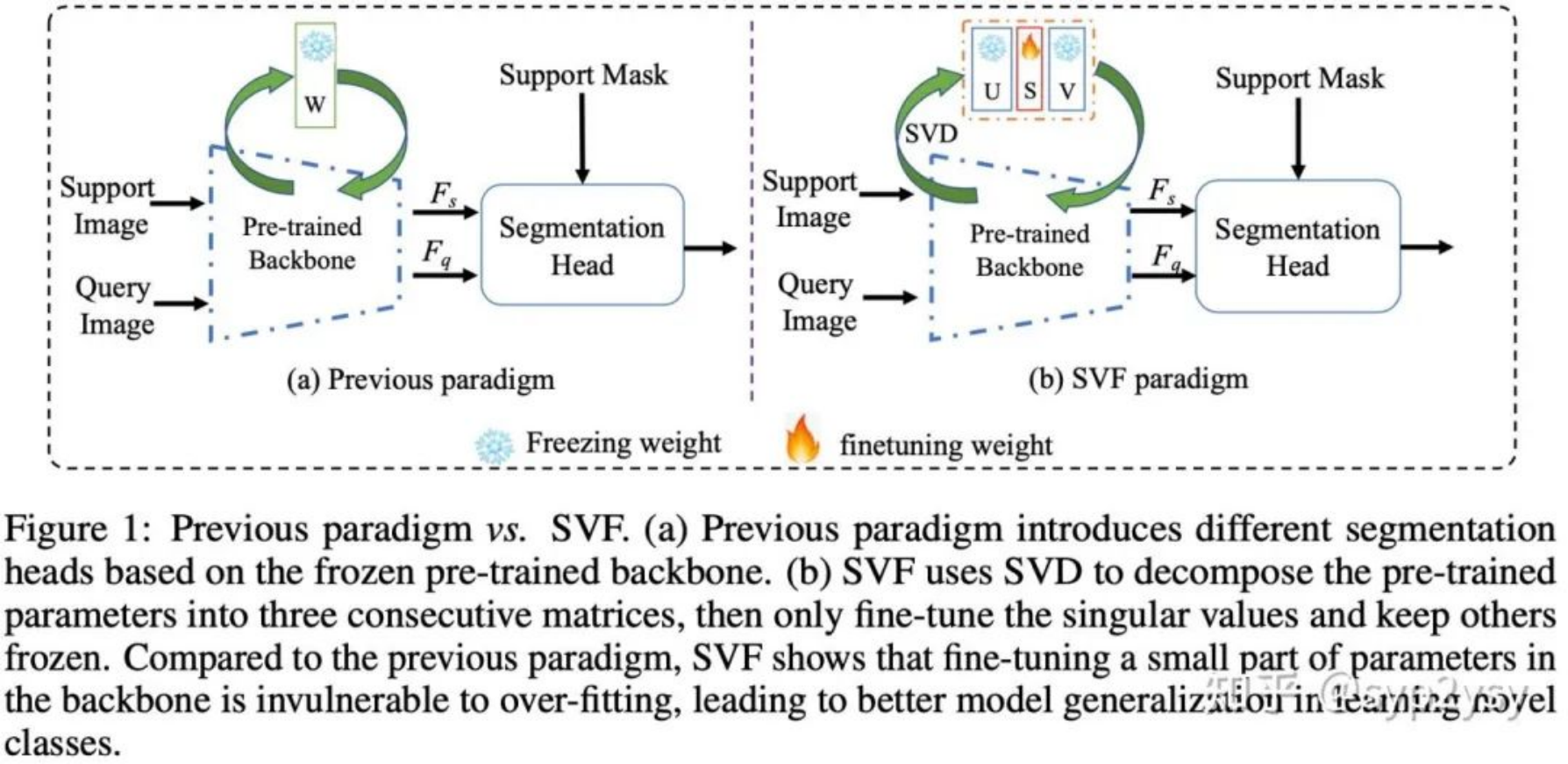
SVF的实现过程也非常简单,其与传统范式的区别如下图所示。不同与传统范式中freeze backbone的做法,SVF首先对pre-train weight进行SVD分解,然后freeze住特征向量空间U和V的参数,而放开特征值空间S的学习。由于SVF是针对backbone进行的,因此适用于大多数的few-shot seg 模型。

评论
沙发等你来抢