
BigCode刚刚发布了编程语言生成模型 StarCoder。 核心版本 StarCoderBase 具有 155 亿个参数,支持80多种编程语言,8192个token的上下文。
StarCoder: 在基座模型上额外使用350亿Python语言的Token训练而成。在有提示词环境下,HumanEval评分40.8%,超过一众早先发布的模型,以及replit-finetuned-v1-3b(30.5%)。
Github地址: https://github.com/bigcode-project/starcoder
项目地址: https://www.bigcode-project.org/ BigCodeProject

论文地址: https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view

、
BigCode是由 HuggingFace与 ServiceNow Research共同发起的代码大模型项目,与其姊妹项目BigScience一样,也是一个开放的研究项目。

更多阅读: https://twitter.com/BigCodeProject
开放式大型代码语言模型StarCoder
要点:
-
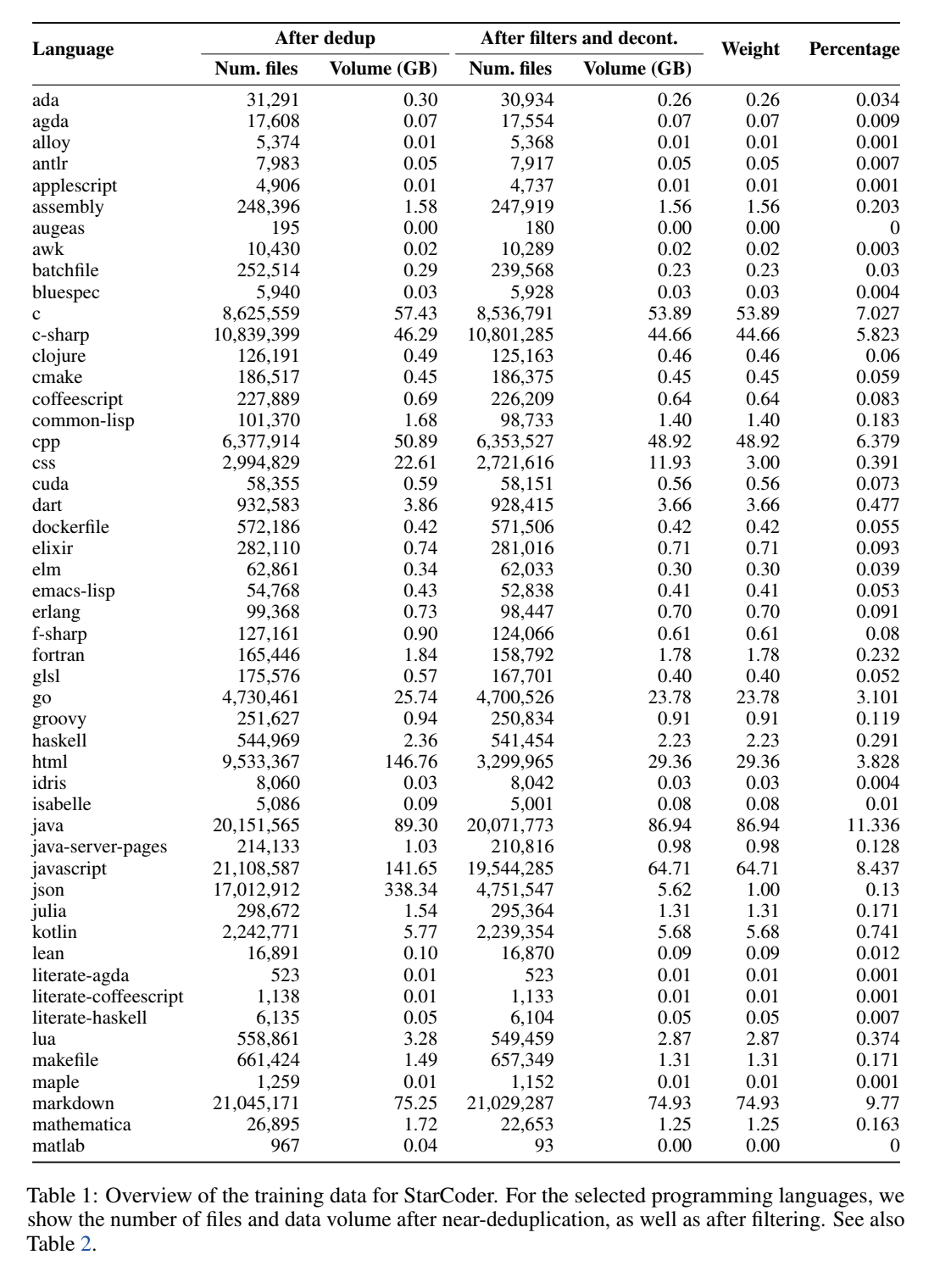
动机:BigCode社区致力于开发大型语言模型,StarCoder和StarCoderBase是其在代码LLM领域的最新成果,为研究和开发社区提供了开放、透明和可重复的代码LLM。 -
方法:通过使用大量开源代码库进行训练,结合改进的PII(个人识别信息)去标识化管道和新的归因工具,研究团队创建了StarCoder和StarCoderBase模型,并进行了广泛的代码LLM评估。 -
优势:StarCoder在多种编程语言上优于其他开源LLM模型,与OpenAI的闭源模型code-cushman-001相匹配或超越其性能。通过发布开放的负责任AI模型许可证和开源代码库,提高了代码LLM的可访问性、可重现性和透明性。
介绍了BigCode社区开发的StarCoder和StarCoderBase,使用代码进行训练的开放式大型语言模型(LLM)。通过组合多种能力和架构特征,StarCoder在广泛的编程语言上实现了卓越的性能,提供了全面的代码LLM评估和安全开放模型发布方案。

评论
沙发等你来抢