编者引语:“过犹不及”指做事做过了头,跟做得不够,都不好,这个词特别适用于HBase数据集群中region数量,region数要与业务量适配,少则分裂,多则合并。
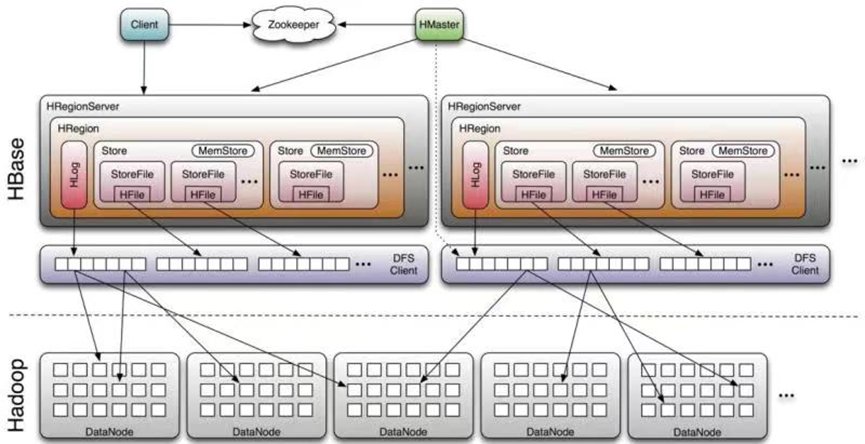
整个互联网都建立在数据库的底座之上,数据库又林林总总分为很多种,但每个互联网业务发展到一定规模都不可或缺的数据库只有这么几种:以MySQL为代表的关系型数据库以及其分布式解决方案,以Redis为代表的缓存数据库,以Elasitcsearch为代表的检索数据库,以Neo4j为代表的图数据库,以InfluxDB为代表的时序数据库,以Greenplum为代表的OLAP数据库, 再就是分布式持久化KV数据库。而在开源领域,尤其是国内,HBase几乎是分布式持久化KV数据库的首选方案。HBase应用的业务场景非常之多,比如用户画像、实时(离线)推荐、实时风控、社交Feed流、商品历史订单、社交聊天记录、监控系统以及用户行为日志等。
笔者属于银行金融从业者,所在的企业在积极拥抱数字化转型,在建设大数据基础平台的过程中引入了HBase集群。作为分布式持久化KV数据库,通过构建海量存储、高可靠性、高性能分布式的存储系统,为企业历史数据平台、外部数据平台、客户画像、数据服务平台、智能拼表等提供数据存储支持。
2.1 基本现状
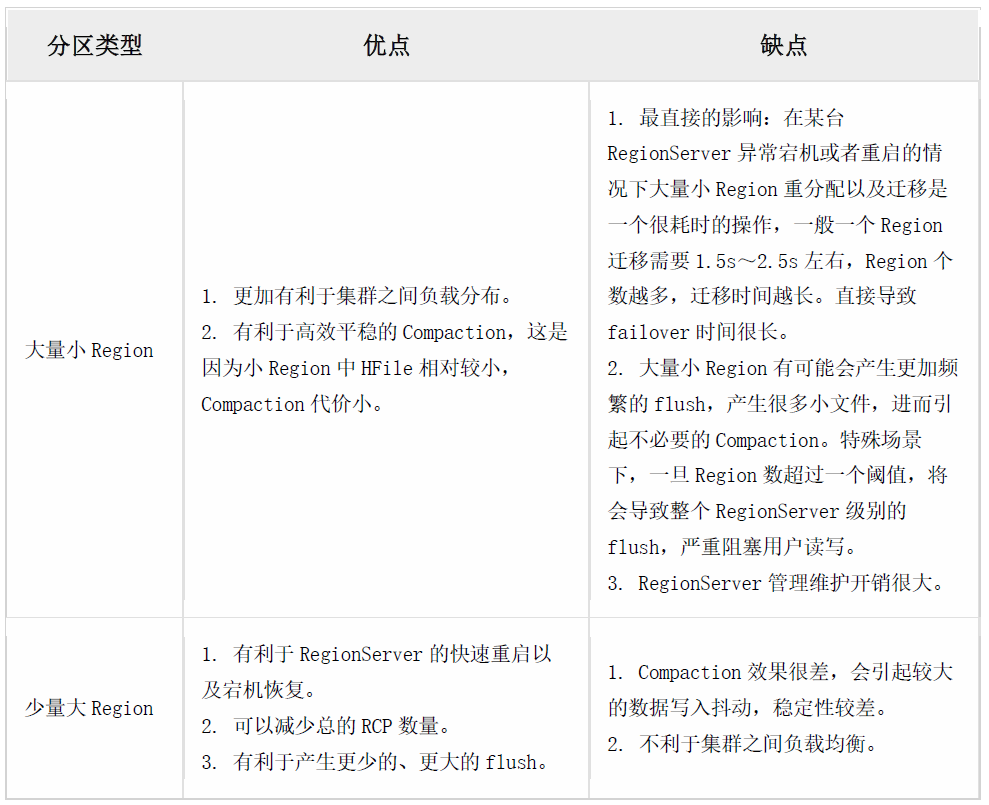
我们的HBase集群中已存在600+张表,8000个Region,存储使用26T空间。平均每个Region Server中服务了3000个Region。每个Region平均大小为1G。但我们的HBase集群存在大量小Region的问题,Region的不合理性将引发的一系列潜在问题,如下表所示:
2.2 现状分析
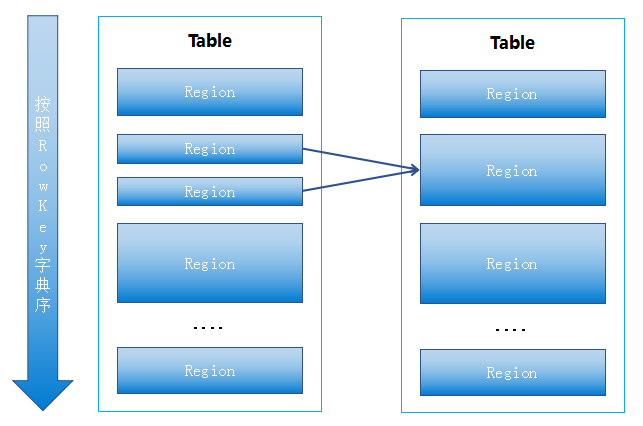
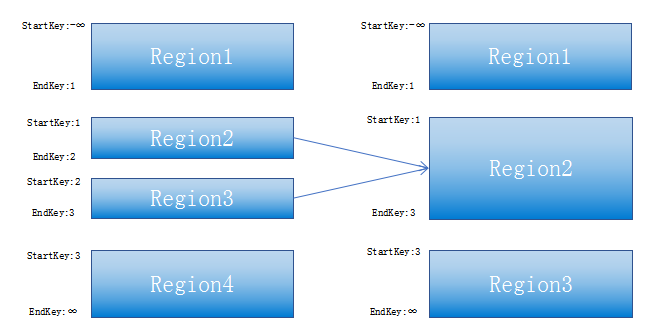
目前我们HBase集群Region Server单节点设置最大服务Region数量的阈值为2000个。如果按照每个Region最大存储大小为10G(HBase默认region最大存储为10G)计算,单节点可以承受2000*10G=20T空间基本可以做到单服务器存储物尽其用。因此,在HBase集群的存储空间没有充分利用的情况下(已用存储26T只占总存储空间的40%),我们HBase集群监控出现相应的告警信息-Region数量超过阈值,以及我们HBase上层应用程序也受到相应的影响-用户读写性能差。即在存储资源没有充分利用的情况下,Region数量已超过阈值,导致存储资源的浪费。对于HBase集群存在的种种问题,我们对问题引起的原因进行调研与分析。主要原因是三个方面:a.应用系统在使用HBase时,在对数据不了解的情况下,创建HBase表进行预分区,且预分区不合理,产生同一个表内存在很多Region无数据或少量数据。b.一些表随着数据量的增加,Region的不断分裂,Region数据增加;该情况属于正常情况,也是Region自动切分的特性。c.大量数据删除或老化导致原来的大region都变成了小region,导致小region的堆积。以上三个方面,导致HBase集群中存在大量region数量的主要原因是预分区的使用不合理与大region变为小region没有进行合并。由于Region预分区的不合理使用是导致Region数量过多的一个重要因素,因此我们需要了解一下什么是Region预分区?为什么业内很多使用HBase的业务应用比较喜欢使用Region预分区?Region预分区顾名思义就是预先进行分区操作。通常大批量数据往一个Region上写入时,会有写热点问题。Region大小达到阈值(默认设置为10G)时,Region会进行Split,Region Split会消耗宝贵的集群I/O资源。因此预分区能够避免大批量数据批量写入时的热点与region分裂时消耗I/O资源的问题。我们在选择使用HBase集群作为存储前,是经过对数据的分析了解评估之后,属于HBase分布式存储系统业务场景的需求,然后对HBase的rowkey进行充分设计的,因此使用者应该是熟悉数据结构的。这时,我们都喜欢在创建HBase表时使用预分区,根据数据rowkey分布结构与每个分区内粗略评估数据量大小进行合理划分各个分区的startkey和endkey。举个例子:在我们的业务中会使用客户ID号作为rowkey,而且我们清楚了解,客户ID号均为6位以0-9开头并均匀分布于000001到999999之间,因此我们会将预分区设置为(,1)(1,2)(2,3)(3,4)(4,5)(6,7)(7,8)(8,)八个预分区并且了解每个分区的数据量都在5G-10G之间。这样该HBase表就会生成8个Region分区,并且在海量数据批量写入时,会均匀分布于这8个region中。b.熟悉数据结构,数据集中于的rowkey段,合理划分预分区区间(startkey,endkey);Region自动切分是HBase能够拥有良好扩张性的最重要因素之一,也必然是所有分布式系统追求无限扩展性的一副良药。SteppingSplitPolicy是HBase2.0版本中Region的默认切分策略。这种切分策略的切分阈值又发生了变化,相比IncreasingToUpperBoundRegionSplitPolicy简单了一些,依然和待分裂Region所属表在当前Region Server上的Region个数有关系,如果Region个数等于1,切分阈值为flushsize * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小Region,而是适可而止。一般情况,若非海量数据批量写入HBase,而是流式写入,增量不大(小于10G),我们建议创建HBase表时不要进行Region预分区,让HBase根据切分策略自行分裂。Region不进行预分区,使用HBase自动切分region的适用场景:Region存在预先进行分区设定和自动切分策略,就意味着我们要对产生过多的Region进行相应的应对策略。开源HBase并没有自动化检测与自动合并region功能,因此我们基于开源HBase进行二次开发,实现Region的自动检测与合并功能,以解决小Region过多引起的集群问题与业务应用使用时的读写阻塞等问题。Region的合并设计思路其实很简单,一句话描述就是将HBase中Table中的两个或多个Region合并成一个Region的过程。在HBase中一个表(Table)中是由有一个或多个Region组成,每一个Region都有一个StartKey值与一个EndKey值(如果进行预分区,与预分区一致),并且前一个Region的EndKey值与相邻的下一个Region的StartKey值是相等的。我们在进行Region合并前需要对每个Table中Region大小进行检测评估,将两个相邻的小Region合并成一个相对大的Region,如下图所示,Region2与Region3要合并在一起,Region2的StartKey值为1,EndKey值为2;Region3的StartKey值为1,EndKey值为2;合并其实就是将新的Region2的StartKey设置为Region2的StartKey值1,EndKey设置为Region3的EndKey值3。我们通过自研的HBase合并工具获取每个Table中Region列表,Region列表通过StartKey与EndKey进行顺序排序,然后通过HDFS API获取到Region的存储大小;再通过配置文件进行配置合并规则进行相应的合并。合并规则配置分为设置合并大小规则和合并数量规则。
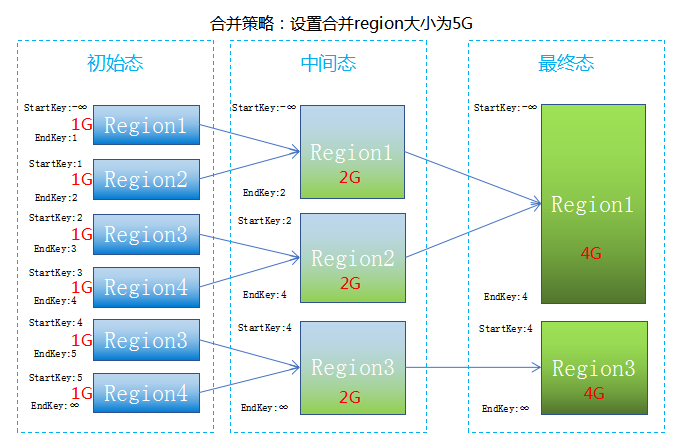
设置合并大小规则是指根据设置单表Region的存储大小来进行合并,将小于设置大小的两个相邻的region进行合并,然后通过我们编写的循环递归遍历合并算法进行合并。例如:设置合并规则为Table1的Region大小小于5G的Region进行合并,如果我们计算Region1和Region2的大小之和小于5G,Region1、Region2和Region3的大小之和大于5G,将进行Region1与Region2进行合并,合并为新的Region1;如果我们计算Region1、Region2和Region3的大小之和小于5G,我们将进行Region1与Region2进行合并为新的Region1,然后再用新的Region1与Region3进行合并。设置合并数量规则是指根据设置单表Region的数量进行合并,将按照设置目标值将两个相邻的Region进行合并,然后通过我们编写的循环递归遍历合并算法进行合并。例如:Table1表中原来为10个Region,设置合并策略设置为合并的目标数为5个,我们将会结合Region的大小进行合并,尽量保证合并后的5个Region大小均匀。
a.不了解数据结构情况,创建Table时过多分配预分区,产出大量小Region;b.已存在的数据表中,进行大批量数据删除或老化,导致大量Region变小。基于我们的HBase集群现状分析,我们一方面使用自主研发的合并工具,另一方面通过规范Region预分区设置的规范,巧妙的结合Region的分裂与合并,将我们的HBase集群中Region数量超过阈值的告警消除,优化后由8000多个Region降低到3000多个Region,平均每个region大小为3G以上,HBase集群存储资源充分利用,在不进行扩容的情况下承载更多应用接入;现有应用的读写数据阻塞问题得到缓解,用户读写数据阻塞产生的超时现象消失;HBase集群RegionServer单点宕机或重启大大减少了Region分配的耗时,节省了HBase运维管理的成本。HBase是目前分布式持久化KV数据库中主流存储系统,结合其优秀的存储特性去探索更多的金融业应用场景,有效支撑金融业数字化转型是我们的使命。规范的使用与功能的优化能够有效的提高HBase的稳定性与易用性,跟进开源社区,并在开源基础之上探索出符合自己应用场景的解决方案。未来,我们将继续探索,将Hadoop体系存储与对象存储相结合,将本地存储更换成对象存储,探索在存算分离的大数据架构下,进一步提高存的下、算的完的灵活性大数据基础平台;探索使用Elasticsearch作为二级索引存储,HBase作为实际数据存储的应用场景,补充HBase查询的弊端,发挥Elasticsearch快速查询的能力,二者互利互补,提高存的多、查的快的大数据基础平台的解决方案。