中文分词工具——jieba
汉字是智慧和想象力的宝库。 ——索尼公司创始人井深大
简介
在英语中,单词就是“词”的表达,一个句子是由空格来分隔的,而在汉语中,词以字为基本单位,但是一篇文章的表达是以词来划分的,汉语句子对词构成边界方面很难界定。例如:南京市长江大桥,可以分词为:“南京市/长江/大桥”和“南京市长/江大桥”,这个是人为判断的,机器很难界定。在此介绍中文分词工具jieba,其特点为:
- 社区活跃、目前github上有19670的star数目
- 功能丰富,支持关键词提取、词性标注等
- 多语言支持(Python、C++、Go、R等)
- 使用简单
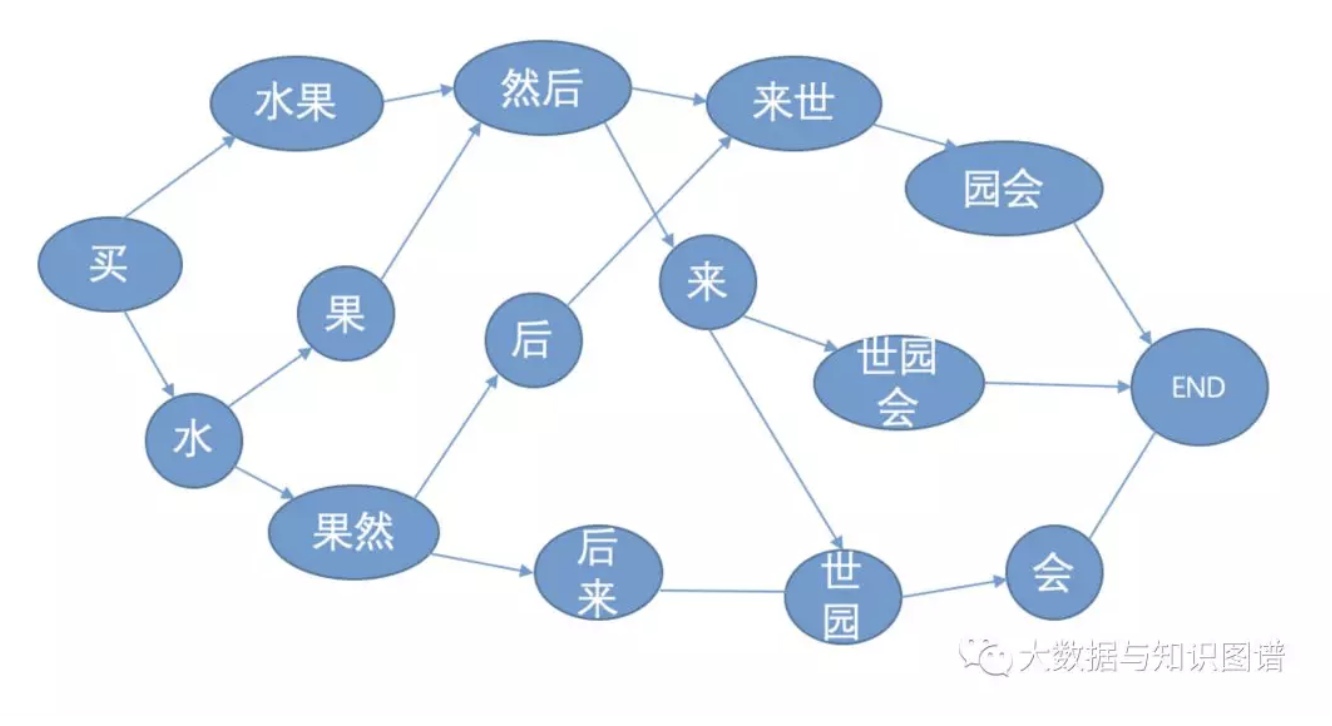
Jieba分词结合了基于规则和基于统计这两类方法。首先基于前缀词典进行词图扫描,前缀词典是指词典中的词按照前缀包含的顺序排列,例如词典中出现了“买”,之后以“买”开头的词都会出现在这一部分,例如“买水”,进而“买水果”,从而形成一种层级包含结构。若将词看成节点,词与词之间的分词符看成边,则一种分词方案对应着从第一个字到最后一个字的一条分词路径,形成全部可能分词结果的有向无环图。
jieba安装
安装很简单,先创建一个python3.6的虚拟环境,再激活环境,最后安装命令如下:
conda create -n nlp_py3 python=3.6
source activate nlp_py3
pip install jieba
jieba的三种分词模式
支持三种分词模式:
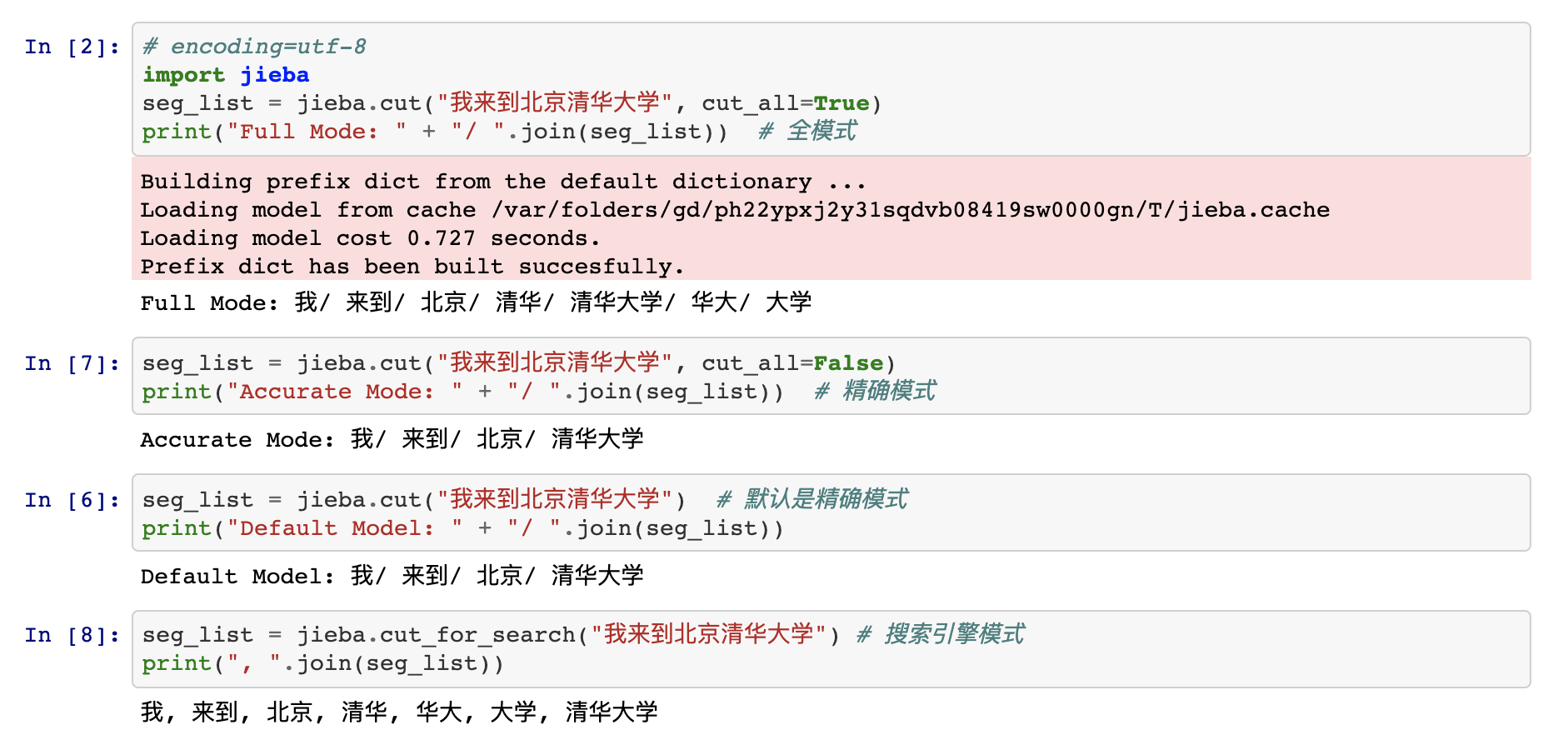
精确模式,试图将句子最精确地切开,适合文本分析。
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义词典
MIT 授权协议
主要功能
1. 分词
- jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
- jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM(隐马尔可夫) 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
- jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
执行示例:
2.添加自定义词典
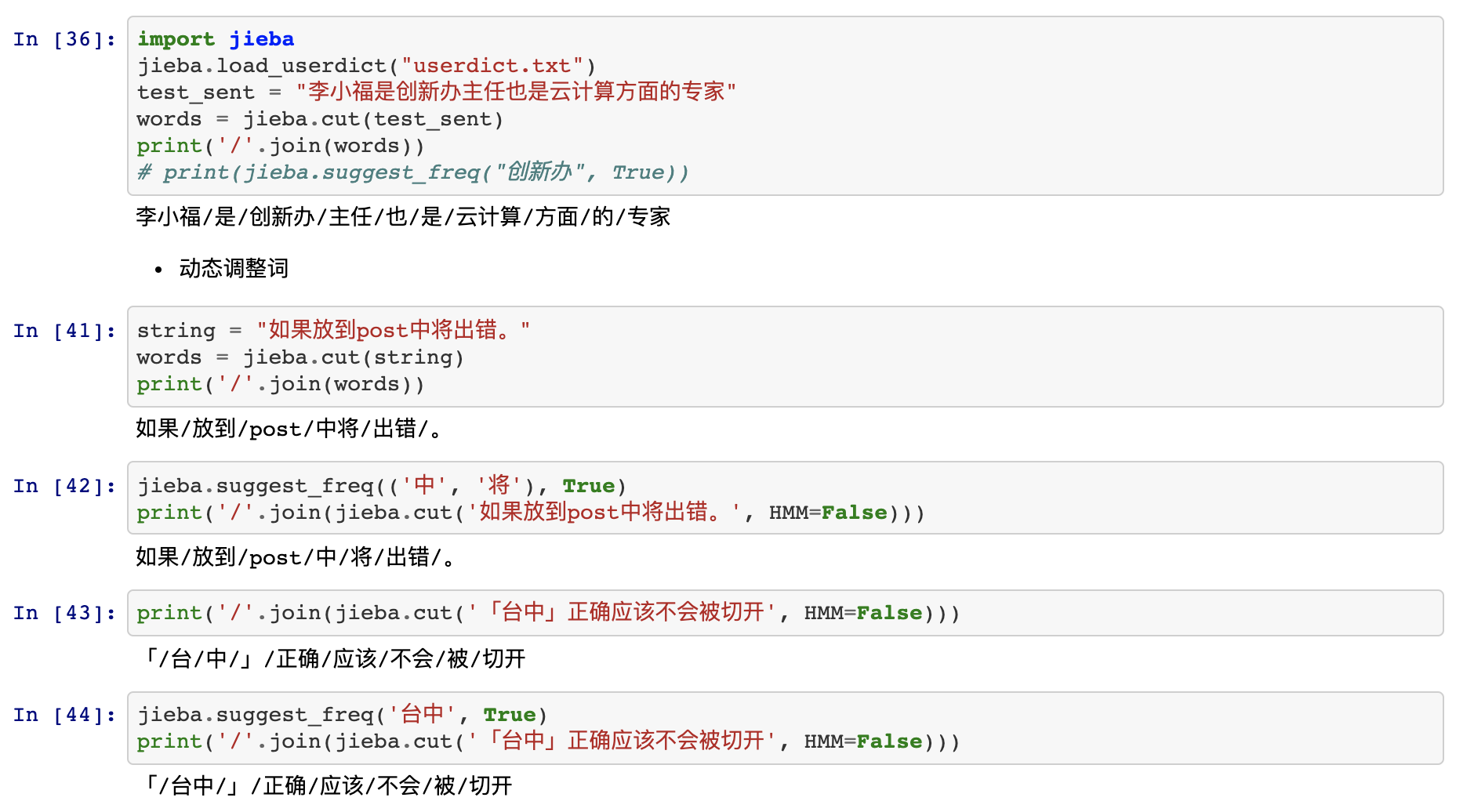
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
执行示例:
tips:
P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低
解决方法:强制调高词频
jieba.add_word('台中')
或者
jieba.suggest_freq('台中', True)
参考官网: https://github.com/fxsjy/jieba

中文分词工具——jieba的更多相关文章
- 中文分词工具jieba中的词性类型
jieba为自然语言语言中常用工具包,jieba具有对分词的词性进行标注的功能,词性类别如下: Ag 形语素 形容词性语素.形容词代码为 a,语素代码g前面置以A. a 形容词 取英语形容词 adje ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 开源中文分词工具探析(三):Ansj
Ansj是由孙健(ansjsun)开源的一个中文分词器,为ICTLAS的Java版本,也采用了Bigram + HMM分词模型(可参考我之前写的文章):在Bigram分词的基础上,识别未登录词,以提高 ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
随机推荐
- IDEA 打可执行jar包(maven项目)
1. Ctrl+Shift+Alt+S 打开 Project Structure 2.选择要执行的文件, 依次选择 项目, 方法所在文件(必须有main方法), 保存 3.如果之前路径下曾经打过 ...
- [转载] IE8+兼容小结
本文分享下我在项目中积累的IE8+兼容性问题的解决方法.根据我的实践经验,如果你在写HTML/CSS时候是按照W3C推荐的方式写的,然后下面的几点都关注过,那么基本上很大一部分IE8+兼容性问题都OK ...
- P2432 zxbsmk爱查错
描述:https://www.luogu.com.cn/problem/P2432 给你一个主串以及若干个子串,求最少需要删除几个字母,使得主串能由一些子串组成. dp [ i ] 表示前 i 个字符 ...
- Oracle触发器之替代触发器
替代触发器 替代视图增删改操作.视图可以认为成逻辑上的一张表,类似于把一个sql语句的执行结果永久的像表存储到数据 库中,视图一般用来做查询. 创建视图的语法: create view 视图名称 as ...
- Qt编程基础入门之二
QMainWindow 菜单栏 菜单栏 最多有一个 //菜单栏创建,一个 QMenuBar *menu = new QMenuBar(this); // this->setMenuBar(men ...
- LeetCode--LinkedList--83.Remove Duplicates from Sorted List(Easy)
题目地址https://leetcode.com/problems/remove-duplicates-from-sorted-list/ 83. Remove Duplicates from Sor ...
- Java变量相关
1.Java是强类型语言 所有的变量必须先声明,后使用: 指定类型后只能接受类型匹配的值: 2.变量声明 变量标识符由字母.数字.下划线和$组成: 关键字和保留字不能做标识符: 长度不限制: 大小写区 ...
- C# 数据操作系列 - 5. EF Core 入门
0.前言 上一章简单介绍了一下ORM框架,并手写了一个类似ORM的工具类.这一章将介绍一个在C#世界里大名鼎鼎的ORM框架--Entity Framework的Core版. Entity Framew ...
- 使用JDBC操作MySQL
使用JDBC操作MySQL 步骤 加载驱动 连接数据库 操作数据库(增删改查) 关闭结果集,操作,数据库 准备工作 java连接MySQL的jar包 加载数据库驱动 public class Load ...
- 【蓝桥杯C组】备赛基础篇之前缀和算法
算法介绍: 设a为数组,a[i]中储存的是前i 个数(包括自己)的总和,相当于我们中学学过的前N项和,那么,弄成这样的好处是什么呢?假如我们要多次访问一段区间的总和,难道每次都加一次进行重复运算吗?? ...