python编写知乎爬虫实践

作者:cpselvis
爬虫的基本流程
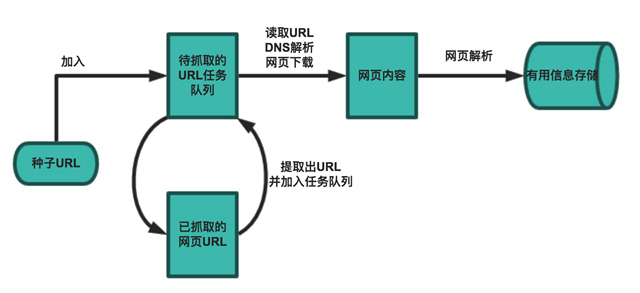
网络爬虫的基本工作流程如下:
首先选取一部分精心挑选的种子URL将种子URL加入任务队列从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。解析下载下来的网页,将需要的数据解析出来。数据持久话,保存至数据库中。
爬虫的抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
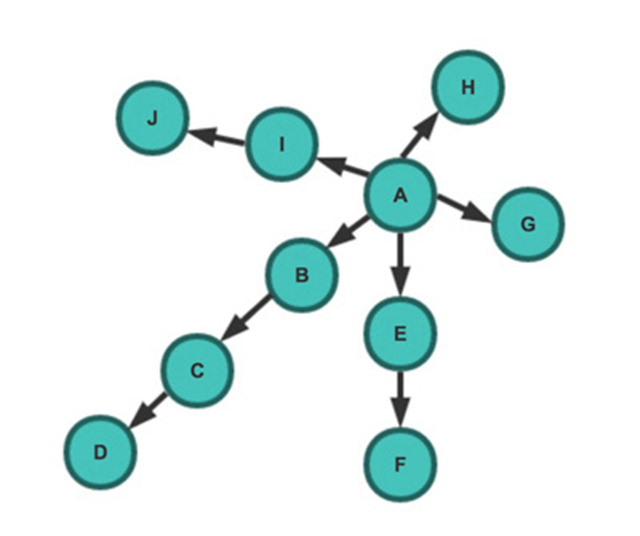
深度优先策略(DFS)
深度优先策略是指爬虫从某个URL开始,一个链接一个链接的爬取下去,直到处理完了某个链接所在的所有线路,才切换到其它的线路。
此时抓取顺序为:A -> B -> C -> D -> E -> F -> G -> H -> I -> J广度优先策略(BFS)
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
此时抓取顺序为:A -> B -> E -> G -> H -> I -> C -> F -> J -> D
了解了爬虫的工作流程和爬取策略后,就可以动手实现一个爬虫了!那么在python里怎么实现呢?
技术栈
requests人性化的请求发送Bloom Filter布隆过滤器,用于判重XPath解析HTML内容murmurhashAnti crawler strategy 反爬虫策略MySQL 用户数据存储
基本实现
下面是一个伪代码
importQueue initial_page ="https://www.zhihu.com/people/gaoming623"url_queue =Queue.Queue() seen =set() seen.insert(initial_page) url_queue.put(initial_page) while(True): #一直进行ifurl_queue.size()>0: current_url =url_queue.get() #拿出队例中第一个的urlstore(current_url) #把这个url代表的网页存储好fornext_url inextract_urls(current_url): #提取把这个url里链向的urlifnext_url notinseen: seen.put(next_url) url_queue.put(next_url) else: break
如果你直接加工一下上面的代码直接运行的话,你需要很长的时间才能爬下整个知乎用户的信息,毕竟知乎有6000万月活跃用户。更别说Google这样的搜索引擎需要爬下全网的内容了。那么问题出现在哪里?
布隆过滤器
需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有N个网站,那么分析一下判重的复杂度就是N*log(N),因为所有网页要遍历一次,而每次判重用set的话需要log(N)的复杂度。OK,我知道python的set实现是hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随url的数量而增长)以O(1)的效率判定url是否已经在set中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个url不在set中,BF可以100%确定这个url没有看过。但是如果这个url在set中,它会告诉你:这个url应该已经出现过,不过我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。
# bloom_filter.pyBIT_SIZE =5000000classBloomFilter:def__init__(self):# Initialize bloom filter, set size and all bits to 0bit_array =bitarray(BIT_SIZE) bit_array.setall(0) self.bit_array =bit_array defadd(self, url):# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)# Here use 7 hash functions.point_list =self.get_postions(url) forb inpoint_list: self.bit_array[b] =1defcontains(self, url):# Check if a url is in a collectionpoint_list =self.get_postions(url) result =Trueforb inpoint_list: result =result andself.bit_array[b] returnresult defget_postions(self, url):# Get points positions in bit vector.point1 =mmh3.hash(url, 41) %BIT_SIZE point2 =mmh3.hash(url, 42) %BIT_SIZE point3 =mmh3.hash(url, 43) %BIT_SIZE point4 =mmh3.hash(url, 44) %BIT_SIZE point5 =mmh3.hash(url, 45) %BIT_SIZE point6 =mmh3.hash(url, 46) %BIT_SIZE point7 =mmh3.hash(url, 47) %BIT_SIZE return[point1, point2, point3, point4, point5, point6, point7]
BF详细的原理参考我之前写的文章:布隆过滤器(Bloom Filter)的原理和实现
建表
用户有价值的信息包括用户名、简介、行业、院校、专业及在平台上活动的数据比如回答数、文章数、提问数、粉丝数等等。
用户信息存储的表结构如下:
CREATEDATABASE`zhihu_user`/*!40100 DEFAULT CHARACTER SET utf8 */; -- User base information tableCREATETABLE`t_user`( `uid`bigint(20) unsignedNOTNULLAUTO_INCREMENT, `username`varchar(50) NOTNULLCOMMENT'用户名', `brief_info`varchar(400) COMMENT'个人简介', `industry`varchar(50) COMMENT'所处行业', `education`varchar(50) COMMENT'毕业院校', `major`varchar(50) COMMENT'主修专业', `answer_count`int(10) unsignedDEFAULT0COMMENT'回答数', `article_count`int(10) unsignedDEFAULT0COMMENT'文章数', `ask_question_count`int(10) unsignedDEFAULT0COMMENT'提问数', `collection_count`int(10) unsignedDEFAULT0COMMENT'收藏数', `follower_count`int(10) unsignedDEFAULT0COMMENT'被关注数', `followed_count`int(10) unsignedDEFAULT0COMMENT'关注数', `follow_live_count`int(10) unsignedDEFAULT0COMMENT'关注直播数', `follow_topic_count`int(10) unsignedDEFAULT0COMMENT'关注话题数', `follow_column_count`int(10) unsignedDEFAULT0COMMENT'关注专栏数', `follow_question_count`int(10) unsignedDEFAULT0COMMENT'关注问题数', `follow_collection_count`int(10) unsignedDEFAULT0COMMENT'关注收藏夹数', `gmt_create`datetime NOTNULLCOMMENT'创建时间', `gmt_modify`timestampNOTNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'最后一次编辑', PRIMARYKEY(`uid`) ) ENGINE=MyISAM AUTO_INCREMENT=1DEFAULTCHARSET=utf8 COMMENT='用户基本信息表';
网页下载后通过XPath进行解析,提取用户各个维度的数据,最后保存到数据库中。
反爬虫策略应对-Headers
一般网站会从几个维度来反爬虫:用户请求的Headers,用户行为,网站和数据加载的方式。从用户请求的Headers反爬虫是最常见的策略,很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。
如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
cookies ={ "d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182", "login": "NzM5ZDc2M2JkYzYwNDZlOGJlYWQ1YmI4OTg5NDhmMTY=|1480901173|9c296f424b32f241d1471203244eaf30729420f0", "n_c": "1", "q_c1": "395b12e529e541cbb400e9718395e346|1479808003000|1468847182000", "l_cap_id": "NzI0MTQwZGY2NjQyNDQ1NThmYTY0MjJhYmU2NmExMGY=|1480901160|2e7a7faee3b3e8d0afb550e8e7b38d86c15a31bc", "d_c0": "AECA7v-aPwqPTiIbemmIQ8abhJy7bdD2VgE=|1468847182", "cap_id": "N2U1NmQwODQ1NjFiNGI2Yzg2YTE2NzJkOTU5N2E0NjI=|1480901160|fd59e2ed79faacc2be1010687d27dd559ec1552a"} headers ={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.3", "Referer": "https://www.zhihu.com/"} r =requests.get(url, cookies =cookies, headers =headers)
反爬虫策略应对-代理IP池
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
大多数网站都是前一种情况,对于这种情况,使用IP代理就可以解决。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过第一种反爬虫。目前知乎已经对爬虫做了限制,如果是单个IP的话,一段时间系统便会提示异常流量,无法继续爬取了。因此代理IP池非常关键。网上有个免费的代理IP API: http://api.xicidaili.com/free2016.txt
importrequests importrandom classProxy:def__init__(self):self.cache_ip_list =[] # Get random ip from free proxy api url.defget_random_ip(self):ifnotlen(self.cache_ip_list): api_url ='http://api.xicidaili.com/free2016.txt'try: r =requests.get(api_url) ip_list =r.text.split('\r\n') self.cache_ip_list =ip_list exceptExceptionase: # Return null list when caught exception.# In this case, crawler will not use proxy ip.printe return{} proxy_ip =random.choice(self.cache_ip_list) proxies ={'http': 'http://'+proxy_ip} returnproxies
后续
使用日志模块记录爬取日志和错误日志分布式任务队列和分布式爬虫
爬虫源代码:zhihu-crawler下载之后通过pip安装相关三方包后,运行$ python crawler.py即可(喜欢的帮忙点个star哈,同时也方便看到后续功能的更新)
运行截图:

End.
转载请注明来自36大数据(36dsj.com):36大数据» python编写知乎爬虫实践 返回搜狐,查看更多
责任编辑: