一种文本语义相似度分析方法与流程
本发明涉及文本分析领域,特别涉及到一种基于语义特征的文本相似度分析方法。
背景技术:
随着计算机互联网络的飞速发展,文本相似度计算在许多领域有着广泛的应用。例如,在机器翻译中,语义相似度通过衡量参考译文与机器翻译输出结果的等价程度来估量机器翻译的质量。此外,在信息检索、情感分析、文本分类、文本聚类、自动问答、语义消歧等领域中文本相似度计算更是一项基础而又重要的工作。
文本作为自然语言的载体,通常以一种非结构化或半结构化的形式存在,对其相似度的计算,则需要将非结构化的文本转化为便于计算机识别处理的结构化信息。迄今为止,文本相似度并没有一个统一的定义,都是根据具体模型给出的。传统的文本相似度计算模型主要可以分为三类:向量空间模型(vector space model,简称VSM)、广义向量空间模型(generalized vector space model,简称GVSM)以及隐性语义索引模型(latent semantic indexing,简称LSI)。向量空间模型借助索引来表示文本的内容,同时给予索引(即待选文本特征)一定的权重,以反映该索引分量对于文本内容的识别程度与价值。广义向量空间模型改善了VSM中文本特征词之间相互正交的假设,它利用文本而不是用词来表示词间关系。隐性语义索引模型LSI,又称潜在语义分析(latent semantic analysis,简称LSA),则扩充了广义向量空间模型,描述文本与文本之间的关系。
然而,传统文本相似度模型需要大规模语料库,并且经常忽略文本中的语法和组织结构以及语义信息。VSM利用词袋(bag-of-words)模型来构建特征空间,将每个文本转化为一个向量,该模型在特征匹配中通常采用“硬匹配”方法,无法解决“一义多词”和“一词多义”问题。LSI虽然利用词汇共现情况来获得词汇的潜在语义相关度,弥补了VSM模型的不足,但也存在一些缺陷。首先矩阵奇异值分解的复杂度很高,其次潜在语义模型考虑的并不是真实的语义关系,而是利用词汇共现获得的潜在语义,并不能真实反应文本中词汇的语义关系。
基于语义分析的文本相似度计算则是利用文本内部词汇内在的语义联系进行计算。自然语言处理中最重要的挑战之一是语言的变异性,即具有相同意义的文本可以有几种不同的表达方式,因此自然语言处理技术需要识别这些不同表现形式的相关性。语义相似度度量是处理语言变异的一个方法。例如,在文本摘要(text summarization)中,语义相似度作为一个度量标准,从完整段落中选择一个句子作为总结。语义相似性问题定义为度量和识别文本之间的语义关系。
技术实现要素:
本发明要解决的技术问题是提供一种基于语义特征的文本相似度分析方法,利用文本内部词汇内在的语义联系进行计算,以达到更加准确有效地分析文本之间的相似程度。
为达到上述发明目的,本发明提出一种基于语义特征的文本相似度分析方法,其特征在于,通过奇异值分解浅层分析文本之间以及词项之间的关联关系,借助贝叶斯网络构建词项-主题集,用互信息以及上下文计算词项之间的语义相似度,最后通过图结构计算文本的相似度,来实现文本分析过程中最核心的文本间相似度的度量。
本发明是通过下述技术方案实现的:
包括如下步骤:
(1)文本特征的表示与度量。给定关于某专业领域的一组文档集合,通过自然语言处理等预处理技术,获取语料库中的有用信息,进而构成特征词集,特征词由文本中的名词和动词组成。而每个文本由一个特征词集和一个特征词对集来表示,文本之间相似度的度量将考虑这两方面的因素。
(2)词对集构建。通过文本和特征词关联矩阵的奇异值分解,形成文本、主题和特征词之间的关联关系图,这个关系图可以用贝叶斯网络来描述;然后用关联规则FpGrowth算法提取频繁项集作为词对集,并根据贝叶斯网络描述的文本-主题-特征词关系,构建词对-主题集。
(3)词集相似度匹配。如果以传统的词袋模型直接计算词集相似度,会忽略文本中重要的语义信息。因此,以文本预处理结果中的特征词为节点,特征词共现关系为边,将文本转化为图结构表示。这种文本图将通过词汇之间的关联关系揭示词汇在文本中的语义地位。
(4)词对集相似度匹配。通过基于词对-主题集组成的贝叶斯网络,将两个文本表示为两个独立的主题集合,利用二部图模型来描述,并通过匈牙利算法找到最大权值二部匹配,计算这两个文本之间的相关性。
在上述方法中,所述步骤(1)中,设文本集D={d1,…,dN},其中包含N个文本。每个文本由一个词集和一个词对集组成,即d={d_w,d_couple},其中d_w={w1,…,wn}表示文本d的特征词集,n表示文本d的特征词的个数,d_couple={<wi,wj>|wi,wj∈d_w}表示d的词对集。文本相似度计算公式定义为:similarity(di,dj)=αWSM(di,dj)+βWCSM(di,dj),其中WSM(di,dj)为特征词匹配度,WCSM(di,dj)为词对匹配度,α,β分别为两个相似度衡量标准的权重。
在上述方法中,所述步骤(2)进一步包括下列子步骤:
a)通过将文本和特征词的关联矩阵进行奇异值分解,形成文本、主题和特征词之间的关联关系图,并用贝叶斯网络来描述文本-主题-特征词关系。
b)通过关联规则FpGrowth算法提取频繁项集作为特征词对集CP表示整个语料库的特征词对集合。
c)从特征词对集中选取一组词对<wi,wj>,查看贝叶斯网络中是否有与该二词都直接相关的主题,若有则转到d),否则转到e);
d)保存该主题并将词对加入主题中,执行步骤f);
e)新增一个主题,并将词对加入该主题中,更新贝叶斯网络,执行步骤f);
f)判断CP中的词对是否全部取完,若是则结束程序,否则转到c)。
在上述方法中,所述步骤(3)进一步包括下列子步骤:
1)构建文本图库Dg={g1,…,gN},其中gi表示第i个文本,V(gi)和E(gi)分别表示图gi的节点集和边集,|V(gi)|和|E(gi)|分别表示图gi的节点数和边数。
2)将任意两个文本d1,d2的词集相似度定义为:WSM(d1,d2)=γSim_node(g1,g2)+(1-γ)Sim_edge(g1,g2)其中γ∈[0,1]是节点相似度函数与边相似度函数对文本相似度影响程度的权值。
3)节点的相似度计算公式为:其中k表示两个g1和g2的特征词匹配个数,simNmaxi表示第i个节点匹配对的最大相似度,mcsi和maxi分别表示第i个节点匹配对的最大公共出现次数和单独出现的最大次数,用互信息来量化两个词的相关性。
4)边相似度定义为:其中weight1_ab和weight2_a′b′分别表示g1的边e1_ab和g2的边e2_a′b′上的权值,e1_ab和e2_a′b′是两个图中相同的边。
在上述方法中,所述步骤(4)进一步包括下列子步骤:
A.通过步骤(2)可以构建主题集库DT={T1,…,TN},Ti表示文档dj的主题集。
B.任意两个文本d1,d2可以分别用两个独立的主题集合T1,T2表示,用二部图(bipartite graph)模型来描述这两个文本之间的相似性。
C.构建二部图厨师连接,通过匈牙利算法(Hungarian algorithm)找到二部图最大权值匹配。
D.取剩余未匹配节点,重新形成二部图,重复步骤c),直到获得最大权值的最优匹配。
本发明能更加准确有效地度量和识别文本之间的语义关系。
附图说明
图1是本发明结构的方框图。
图2是本发明中主题集匹配算法结构图。
图3是本发明实施例上实验所得文本类内平均相似度与类间平均相似度结果。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对根据本发明实施的文本语义相似度分析方法进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明,即本发明的保护范围不限于下述的实施例,相反,根据本发明的发明构思,本领域普通技术人员可以进行适当改变,这些改变可以落入权利要求书所限定的发明范围之内。
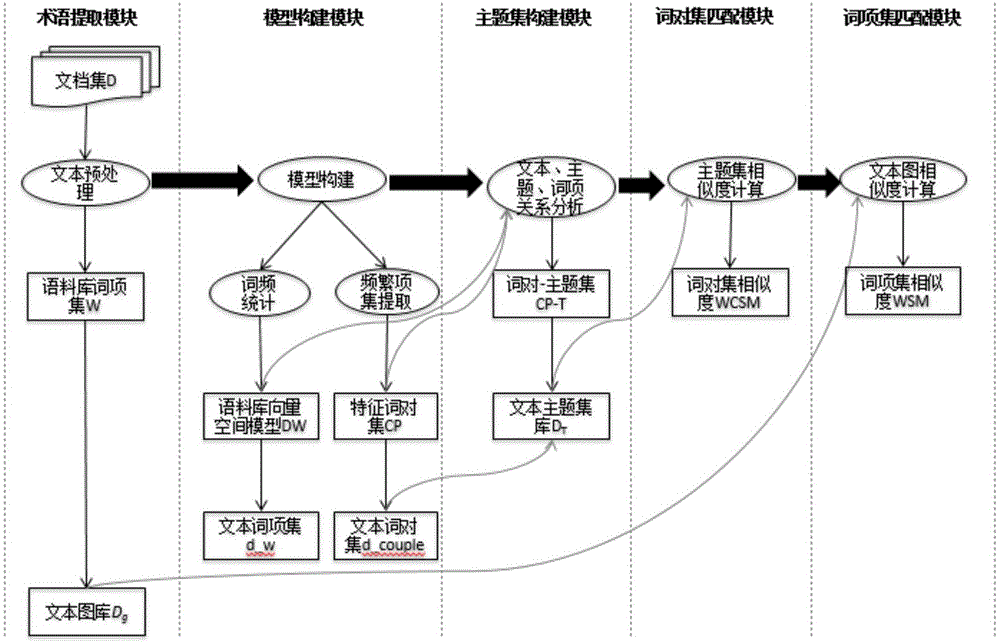
如图1的结构框图所示,根据本发明具体实施例包括如下步骤:
1)术语提取模块:
本实施例采用本发明所述的文本语义相似度分析方法,使用复旦大学计算机信息与技术系国际数据库中心自然语言处理小组提供的文本分类语料库,经过预处理从art、environment、agriculture、economy、politics、sports、computer、history和space中选取1114篇文档进行实验。经过分词处理、去停用词后保留11831个词项W。
2)模型构建模块:
用预处理后的词项集W构建语料库向量空间模型DW,然后用关联规则FpGrowth算法提取频繁项集构建特征词对集CP,语料库原有词对3837360组,经提取后生成特征词对304793组。整个文档集描述为D={d1,…,dN},本实施例中N=1114,每个文档d由一个词项集d_w和一个词对集d_couple组成d={d_w,d_couple},其中d_w={w1,…,wn},d_couple={<wi,wj>|wi,wj∈d_w}。文本相似度计算公式定义为:similarity(di,dj)=αWSM(di,dj)+βWCSM(di,dj),其中WSM(di,dj)为词项集匹配度函数,WCSM(di,dj)为词对及匹配度函数,α,β分别为两个相似度衡量标准的权重。本实施例中α=6.45,β=0.58时效果较优。
3)主题集构建模块:
通过步骤2)得到文档-词矩阵DW,对该矩阵进行奇异值分解,形成文本,主题和词项之间的关联关系图,用一个贝叶斯网络来描述这个关系图。循环从CP中取出词对<wi,wj>,判断在贝叶斯网络中是否已存在与该二词直接相关的主题,存在则在相应主题下添加该词对,否则增加一个新主题并将该词对添加到新主题下同时更新贝叶斯网络,循环以上过程直到CP中的词对全部取完为止。得到语料库词对-主题集CP-T。本实施例中对CP中304793个词对生成141个主题。
4)词对集相似度匹配:
根据步骤3)得到的词对-主题集CP-T,以及每个文本对应的词对集d_couple,通过一一对应的映射关系生成文本的主题集库DT={T1,…,TN},其中Ti表示文档di的主题集。从而任意两个文本可表示为两个独立的主题集合,用二部图模型来描述两个文本之间的相关性。
将两个文本分别以主题为节点构建二部图B(T1,T2),|V(T1)|个节点在一边,|V(T2)|个节点在另一边,V(T1)表示文本d1的节点集,同时用b(u)表示B(T1,T2)中相关节点u。对于每对节点u∈V(T1),v∈V(T2)当且仅当Sim(u,v)>0(即u和v存在一定相关性),那么b(u)和b(v)之间可以形成一条连线。主题之间的相关度则由主题下包含的词对集之间的相似度衡量。对于每条边(b(u),b(v))∈E(B(T1,T2)),边(b(u),b(v))的权值为w(b(u),b(v))=Sim(u,v)。构建二部图后,通过匈牙利算法找到最大权值二部匹配M(T1,T2),如图2所示。词对集相似度计算公式为WCSM=∑(b(u),b(v))∈M(T1,T2)w(b(u),b(v))。
5)词项集相似度匹配:
根据步骤2)文本的词项集d_w构建文本图库Dg={g1,…,gN},其中gi表示第i个文本的图结构。以一个句子为一个共现窗口,句子中任意两个特征词之间形成一条边,gi={[wia,wib,ei_ab,weighti_ab]|wia,wib∈V(gi),ei_ab∈E(gi)},其中#(wia,wib)表示wia和wib在文本dj中共现次数,#(wia)和#(wib)分别表示wia和wib在文本中单独出现次数。词项集相似度计算公式为WSM(d1,d2)=γSim_node(g1,g2)+(1-γ)Sim_edge(g1,g2),Sim_node函数表示节点相似度,Sim_edge函数表示变相似度,γ∈[0,1]是两个函数对文本相似度影响程度的权值。用互信息来量化两个词的相关性,构建特征词相似性矩阵Mg_12。具体的解决办法为:首先从大量文本中计算与其中一个目标词一起出现的互信息较大的一些词,然后再计算与另一目标词一起出现的互信息较大的一些词,最后用余弦定理计算得到两个词的相似度。我们用一个贪婪选择的迭代过程从词项相似性矩阵Mg_12中选取最优节点匹配计算文本图节点集相似度。同时,用边相似度计算公式计算两个图的变相似度。本实施例中γ取0.6来计算文本的相似度。
- 一种基于RCNN的图像检测以...
- 为图像特征点确定比较点对及二...
- 一种基于变形驱动的3D模型拓...
- 基于跟踪片段置信度和区分性外...
- 一种天线信号的获取方法及装置...
- 一种基于报表生成类型化维度X...
- 显示装置的制作方法
- 具有定温休眠模式的电子装置及...
- 3D场景分块加载方法及其系统...
- 训练数据的生成方法、搜索方法...
- 还没有人留言评论。精彩留言会获得点赞!
- 文本相似度的计算方法及系统、相似文本的查找方法及系统的制作方法
- 一种基于语义角色位置映射的文本水印嵌入及提取方法
- 在文本中确定语义关键词的方法和装置的制造方法
- 实现文本语义容错理解的方法及系统的制作方法
- 中文网络话题评论文本语义倾向分析的方法及装置的制造方法
- 基于联想网络的语义相关性计算方法
- 基于文本语义挖掘的标准化自动建档方法
- 一种问答系统中基于语义的相似度分析方法、系统及应用
- 基于语义相似度的层次式对等网络结构及构建方法
- 针对文本消息的基于用户的语义元数据的制作方法
- 一种基于内容的音频语义特征相似度比较方法
- 一种基于形态和语义相似度的对话短文本聚类方法
- 一种基于语义相似度区间的主观题自动评分系统及方法
- 一种基于本体集合概念相似度的语义匹配方法
- 基于WordNet语义相似度的多特征图像标签排序方法
- 一种数据驱动的中文词语义相似度计算方法
- 语义分析算法识别伪原创方法
- 基于异质网络时态语义路径相似度的人物唯一性识别方法
- 一种基于搜索引擎的概念语义相似度度量方法
- 一种藏语语义本体创建及词汇扩充方法
- 一种为文本集合生成语义标识的方法和装置制造方法
- 确定短文本相似度的方法和装置制造方法
- 基于细划分MapReduce的文本语义提取方法
- 一种基于语义的文本分类方法
- 基于语义分析和语义关系网络的文本相似度度量方法
- 文本语义的可视化表示与获取方法
- 一种用于短文本语义相似度计算的方法
- 利用图像处理技术及语义向量空间的文本语义处理方法和系统的制作方法
- 用于文本语义处理的方法、装置及产品的制作方法
- 基于语义的文本相似度计算方法
- 基于本体概念求解语义相似度的混合方法与制造工艺
- 一种确定关键词上下文窗口的混合方法与制造工艺
- 一种基于上下文窗口的词语语义相似度求解方法与制造工艺
- 一种改进的基于信息论的概念语义相似度计算方法与制造工艺
- 一种新的本体概念词汇语义相似度求解方法与制造工艺
- 一种改进的本体概念词汇语义相似度求解方法与制造工艺
- 一种确定关键词上下文范围的求解方法与制造工艺
- 基于新统计的词汇语义相似度求解算法的制造方法与工艺
- 智造行业中一种新的语义相似度求解方法与制造工艺
- 基于dmr的混合长度文本集的文本聚类方法
- 确定语义匹配度的方法和装置的制造方法
- 一种基于地形语义的路径规划方法
- 语义位置获取方法和装置的制造方法
- 一种文档的语义相关度计算方法
- 一种app软件用户评论一致性判断方法
- 一种词汇语义相关度的计算方法
- 一种基于药品本体库的语义查询方法
- 一种多阶段语义Web服务发现方法
- 视频语义可视化方法
- 语义相似度计算方法、搜索结果处理方法和装置制造方法