一种个人智能助手系统及数据处理方法与流程
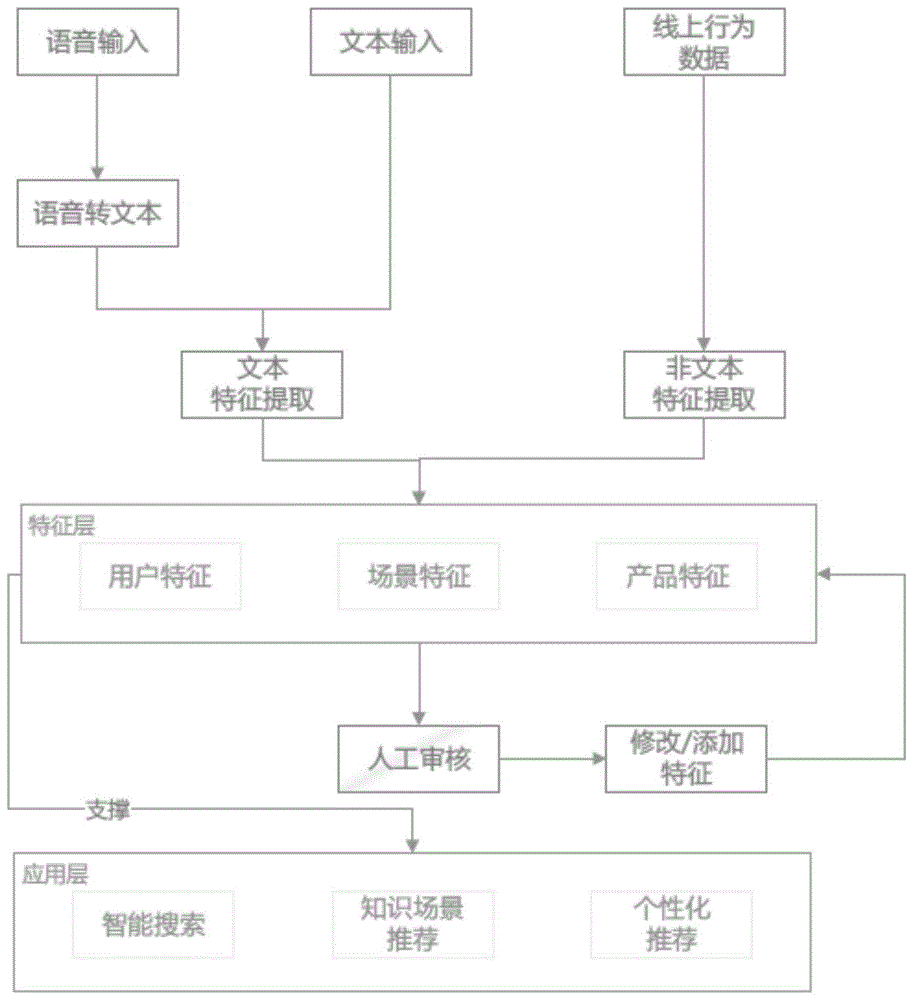
本发明属于计算机
技术领域:
下的自然语言处理
技术领域:
,具体涉及一种个人智能助手系统及数据处理方法。
背景技术:
:国网公司已初步建立了统一的95598知识管理平台,意在为话务人员和工单处理人员提供知识服务。随着应用的深入,知识库使用人员对知识库使用方面提出了更高的要求,现在主要存在与用户的场景契合度不够高,具体体现在知识展现渠道单一,知识的展现方式目前仅有文字内容,没有富媒体展现方式,不能实现个性化主动推荐,无法在现场作业时查询知识库等问题,亟需设计一套已适配、可拓展的电力营销知识服务系统,为用户提供更自然、无障碍的知识服务。技术实现要素:针对上述问题,本发明提出一种个人智能助手系统及数据处理方法,。为了实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:第一方面,本发明提供了一种个人智能助手系统,包括:智能搜索模块,其根据接收到的输入数据,检索出与输入数据相关的数据,并反馈;知识场景化推荐模块,其根据接收到的输入数据,结合用户办理的业务内容和用户意图识别,基于用户标签内容推荐技术,场景化推送知识内容;个性化知识推荐模块,其根据接收到的输入数据以及用户标签体系,完成基于协同过滤的个性化推荐。可选地,所述智能搜索模块包括:第一处理单元,用于基于接收到的语音输入数据,基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈;和/或第二处理单元,用于基于接收到的文本输入数据,基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈。可选地,所述知识场景化推荐模块包括:标签形成单元,用于根据接收到的输入数据,收集用户真实数据,运用中文语义分析技术,形成第一标签;标签修改单元,用于进行人工审核标签,由业务专家针对真实场景关联性筛选/修改相关的第一标签,形成第二标签;第一推荐单元,用于针对具有相同第二标签的知识进行反向关联,向用户推荐同与同一第二标签未读知识。可选地,所述个性化知识推荐模块包括:数据收集单元,用于根据接收到的输入数据,收集用户线上交互行为数据;特征萃取单元,用于利用特征提取相关技术从收集到的用户线上交互行为数据中萃取用户特征;计算单元,用于基于萃取得到的户特征计算用户相似度,获得用户的相似用户;第二推荐单元,用于针对相似用户的相关内容向某用户进行推荐。可选地,所述个人智能助手系统还包括多媒体互动式问答模块,用于基于获取到的输入数据以及群体智慧协同过滤技术实现多媒体互动。第二方面,本发明提供了一种个人智能助手的数据处理方法,包括:获取输入数据;基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行数据反馈或者场景化推送知识内容或者完成基于协同过滤的个性化推荐。可选地,所述基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行数据反馈,具体为:当输入数据为语音输入数据时,则基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈;和/或当接收到的文本输入数据时,则基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈。可选地,所述基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行场景化推送知识内容,具体为:收集用户真实数据,运用中文语义分析技术,形成第一标签;人工审核标签,由业务专家针对真实场景关联性筛选/修改相关的第一标签,形成第二标签;针对具有相同第二标签的知识进行反向关联,向用户推荐同与同一第二标签未读知识。可选地,所述基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行基于协同过滤的个性化推荐,具体为:收集用户线上交互行为数据;利用特征提取相关技术从收集到的用户线上交互行为数据中萃取用户特征;基于萃取得到的户特征计算用户相似度,获得用户的相似用户;针对相似用户的相关内容向某用户进行推荐。可选地,所述数据处理方法还包括:基于获取到的输入数据以及群体智慧协同过滤技术实现多媒体互动。与现有技术相比,本发明的有益效果:本发明将文本数据、语音数据、线上行为数据三种融合,运用自然语言处理(命名实体识别、句法分析)相关技术,处理数据并加工提取相关特征;特征层采用用户特征、场景特征、产品特征分开的方式进行建模;考虑到机器提取特征存在偏差性,本发明加入人工审核修改特征的模块用以斧正特征;运用相关特征设计一种个人智能助手系统,通过提供便捷、智能、贴近业务的知识搜索,帮助新老员工学习知识,业务协作辅助办公,专家参与分享经验,通过智能检索、语音输入、精准匹配获取、智能推荐、个性化推荐、主动推送等诸多方式,实现知识的碎片化应用,提供快消式的知识服务,给每位员工配备虚拟的智能助手。附图说明为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明,其中:图1为本发明一种实施例的方法的流程示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明的保护范围。下面结合附图对本发明的应用原理作详细的描述。实施例1本发明实施例中提供了一种个人智能助手系统,包括:智能搜索模块,其根据接收到的输入数据,检索出与输入数据相关的数据,并反馈;知识场景化推荐模块,其根据接收到的输入数据,结合用户办理的业务内容和用户意图识别,基于用户标签内容推荐技术,场景化推送知识内容;个性化知识推荐模块,其根据接收到的输入数据以及用户标签体系,完成基于协同过滤的个性化推荐。在本发明实施例的一种具体实施方式中,所述智能搜索模块包括:第一处理单元,用于基于接收到的语音输入数据,基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈;所述的检索可以是采用基于自然语言理解增强的检索模块来完成,比于一般的检索模块,本发明采用基于现有中文自然语言理解相关技术(分词、命名实体识别等),对于时间、数量词、地点、价格、数量区间等多种语义要素进行有效检索。和/或第二处理单元,用于基于接收到的文本输入数据,基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈;在具体实施过程中,所述文本输入数据包括中文字符、英文字符、词组、短语、句子等;所述的检索可以是采用基于自然语言理解增强的检索模块来完成,比于一般的检索模块,本发明采用基于现有中文自然语言理解相关技术(分词、命名实体识别等),对于时间、数量词、地点、价格、数量区间等多种语义要素进行有效检索。所述的第一处理单元和第二处理单元完成的是文本特征的提取,包括产品特征和场景特征。在本发明实施例的一种具体实施方式中,所述知识场景化推荐模块包括:标签形成单元,用于根据接收到的输入数据,收集用户真实数据,运用中文语义分析技术,形成第一标签;标签修改单元,用于进行人工审核标签,由业务专家针对真实场景关联性筛选/修改相关的第一标签,形成第二标签;第一推荐单元,用于针对具有相同第二标签的知识进行反向关联,向用户推荐同与同一第二标签未读知识。所述与同一第二标签未读知识包括:在本发明实施例的一种具体实施方式中,所述个性化知识推荐模块包括:数据收集单元,用于根据接收到的输入数据,收集用户线上交互行为数据;特征萃取单元,用于利用特征提取相关技术从收集到的用户线上交互行为数据中萃取用户特征,即完成非文本特征的提取;计算单元,用于基于萃取得到的户特征计算用户相似度,获得用户的相似用户;第二推荐单元,用于针对相似用户的相关内容向某用户进行推荐。在本发明实施例的一种具体实施方式中,所述个人智能助手系统还包括多媒体互动式问答模块,用于基于获取到的输入数据以及群体智慧协同过滤技术实现多媒体互动。实施例2本发明实施例中提供了一种个人智能助手的数据处理方法,如图1所示,具体包括以下步骤:(1)获取输入数据;(2)基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行数据反馈或者场景化推送知识内容或者完成基于协同过滤的个性化推荐。在本发明实施例的一种具体实施方式中,所述基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行数据反馈,具体为:当输入数据为语音输入数据时,则基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈;所述的检索可以是采用基于自然语言理解增强的检索模块来完成,比于一般的检索模块,本发明采用基于现有中文自然语言理解相关技术(分词、命名实体识别等),对于时间、数量词、地点、价格、数量区间等多种语义要素进行有效检索;和/或当接收到的文本输入数据时,则基于标签内容推荐技术,检索出与输入数据相关的数据,并反馈;在具体实施过程中,所述文本输入数据包括中文字符、英文字符、词组、短语、句子等;所述的检索可以是采用基于自然语言理解增强的检索模块来完成,比于一般的检索模块,本发明采用基于现有中文自然语言理解相关技术(分词、命名实体识别等),对于时间、数量词、地点、价格、数量区间等多种语义要素进行有效检索,完成文本特征的提取,包括产品特征和场景特征。在本发明实施例的一种具体实施方式中,所述基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行场景化推送知识内容,具体为:收集用户真实数据,运用中文语义分析技术,形成第一标签;人工审核标签,由业务专家针对真实场景关联性筛选/修改相关的第一标签,形成第二标签;针对具有相同第二标签的知识进行反向关联,向用户推荐同与同一第二标签未读知识。所述与同一第二标签未读知识包括:在本发明实施例的一种具体实施方式中,所述基于所述输入数据的类型,选择合适的数据处理规则,并基于选中的数据处理规则处理所述输入数据,最终进行基于协同过滤的个性化推荐,具体为:收集用户线上交互行为数据;利用特征提取相关技术从收集到的用户线上交互行为数据中萃取用户特征;基于萃取得到的户特征计算用户相似度,获得用户的相似用户;针对相似用户的相关内容向某用户进行推荐。在本发明实施例的一种具体实施过程中,具体为:基于物品的协同过滤算法itemcf;基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的知识点相似的知识内容。用户/知识知识点a知识点b知识点c用户a√√用户b√√√用户c√推荐实现步骤如图1所示:步骤1.收集用户线上交互行为数据,并对所述用户线上交互行为数据进行预处理,利用中文分词,词性标注,句法分析等相关技术完成原始用户文本数据的预处理工作,清洗数据中的杂质内容;步骤2.用户特征采集过程,针对每个用户行为数据,利用步骤1预处理结果,提取用户特有文字特征,例如领域实体、操作现象等。步骤3.人工审核用户特征萃取情况,并针对场景真实情况人工核对相关特征。步骤4.判断用户特征采集是否完成,若未完成返回步骤2继续发现新的用户特征。步骤5.根据用户的特征为其推荐相似特征的知识点,其中知识点的相似度计算采用皮尔逊相关系数;步骤6.根据步骤5计算结果计算出每个用户的推荐知识点;其中,皮尔逊相关系数的计算公式为:其中,p(x,y)表示用户x与知识点y的相关性,xi表示用户x的第i维数值化特征,yi表示知识点y的第i维数值化特征。基于item-cf的推荐算法需减少活跃用户对于数据的影响,算法判断活跃用户对物品相似度的贡献应该小于不活跃的用户,所以增加一个iuf(inverseuserfrequence)参数来修正物品相似度的计算公式:其中,n(u)表示用户u拥有物品的总个数,n(i)表示拥有物品i的总人数,n(j)表示拥有物品j的总个数,wij表示物品i与物品j的相似度。在本发明实施例的一种具体实施方式中,所述数据处理方法还包括:基于获取到的输入数据以及群体智慧协同过滤技术实现多媒体互动。以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。当前第1页12
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 一种智能终端的用户交互方法、...
- 问答匹配系统和方法及问答处理...
- 用于文档查询的文档玻尔兹曼机...
- 基于精标注文本的关键信息抽取...
- 一种自动生成答案的方法和系统...
- 基于语音识别结果进行意图分类...
- 基于人工智能的停电计划非结构...
- 一种领域知识图谱的本体模型构...
- 一种确定语料的方法、装置、设...
- 一种基于区块链的类案同判方法...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
数据处理相关技术
- 一种农业大数据科技精准化服务系统的制造方法与工艺
- 大数据即时调度方法与流程
- 一种多路控制的zigbee设备数据处理方法与流程
- 体素数据的同步方法和装置与流程
- 一种客户端事件处理系统及方法与流程
- 一种视频会议数据处理方法及系统与流程
- 一种文件的获取方法及获取装置与流程
- 一种提示信息的显示方法与流程
- 一种数据处理方法与流程
- 一种数据校验的方法和装置与流程