有哪些深度学习框架的源码适合学习?
3 个回答

torch7框架源码,可以看作有两部分组成:由C语言写的基本计算单元 和 lua写对基本计算单元的整合利用。
torch7中,把C语言实现的基本计算单元以及数据结构做成了一个库:libtorch.so,
然后lua通过加载libtorch.so,去获取C语言中实现的变量类型和基本算子。而libtorch.so的直接构成如下图。


libtorch.so中的包含有很多.o文件,其中实现核心计算的是lib/TH/libTH.0.so或者lib/TH/libTh.0.dylib.
libtorch.so通过链接lib/TH/libTH.0.dylib,包含torch7/lib/TH文件夹下所有的文件中的函数。而这些函数里,就包含着底层计算了,
- 包含各种指令集加速算子的适配。具体的在lib/TH/vector/SSE.c里实现基本算子,通过lib/TH/THVector.c,以及 lib/TH/generic/THVectorDispatch.c去做了适配,匹配完后去做卷积。
- 包含openblas库的使用;具体的在lib/TH/generic/THBlas.c中实现基本算子,通过lib/TH/generic/THTensorMath.c文件中去调用,实现基本的数学运算的加速;通过lib/TH/generic/THTensorConv.c中去调用,实现卷积运算的加速。
- 包含卷积的实现;具体的在lib/TH/generic/THTensorConv.c中,它调用lib/TH/generic/THBlas.c,和lib/TH/generic/THVector.c中的函数实现卷积。也就是说,卷积的实现没有直接调用openblas和sse基本算子,而是通过调用THBlas和THVector去调用的。
- 包含各种数据类型的适配:这个具体在一个具体的预编译宏上:#include TH_GENERIC_FILE.这个巧妙的宏的设置,让torch7库,只用实现一种数据类型的计算,比如 float型,就可以实现所有类型byte,int,short,double等类型的计算;这个宏在很多文件中都出现,读者朋友可以自行全局搜索一下。
在lib/TH/libTH.0.dylib中除了上述所说的,涉及到算子的,还包含基本的随机矩阵THTensorRandom.h,包含lapack库的基本算子lib/TH/generic/THTensorLapack.h.
lib/Th/libTH.0.dylib把这些函数,和 Tensor.c.o,Storrage.c.o 等上图所示的文件,一起链接成了libtorch.so.
由于lib torch.so是针对lua编写的库,所以lib/Th/libTh.0.dylib中的函数们,是通过Tensor.c.o,Stroage.c.o包装后,才能被lua使用的。
所以这里Tensor.c.o,Stroge.c.o实际上 调用了用C实现的卷积等基本计算函数去实现了一些让lua用起来方便的函数,然后等着lua调用的。 Tensor.c.o,Stroge.c.o主要功能是桥接。
下面我们说一下涉及到基本计算部分的代码:lib/TH/Tensor.h,lib/TH/Tensor.c.
lib/TH/Tensor.h:
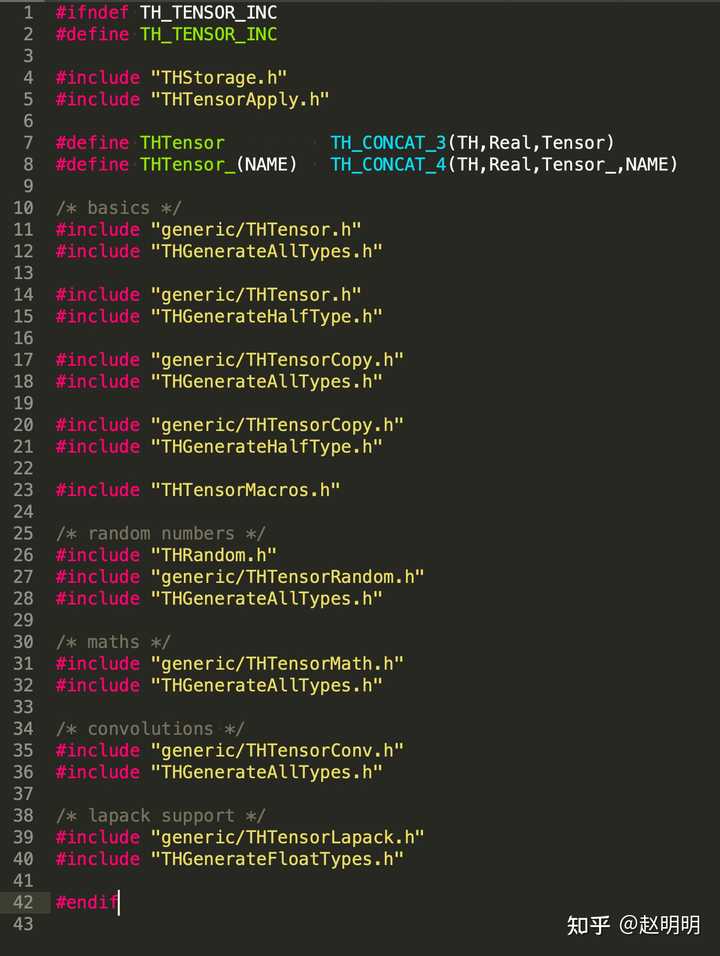

lib/TH/THTensor.c:
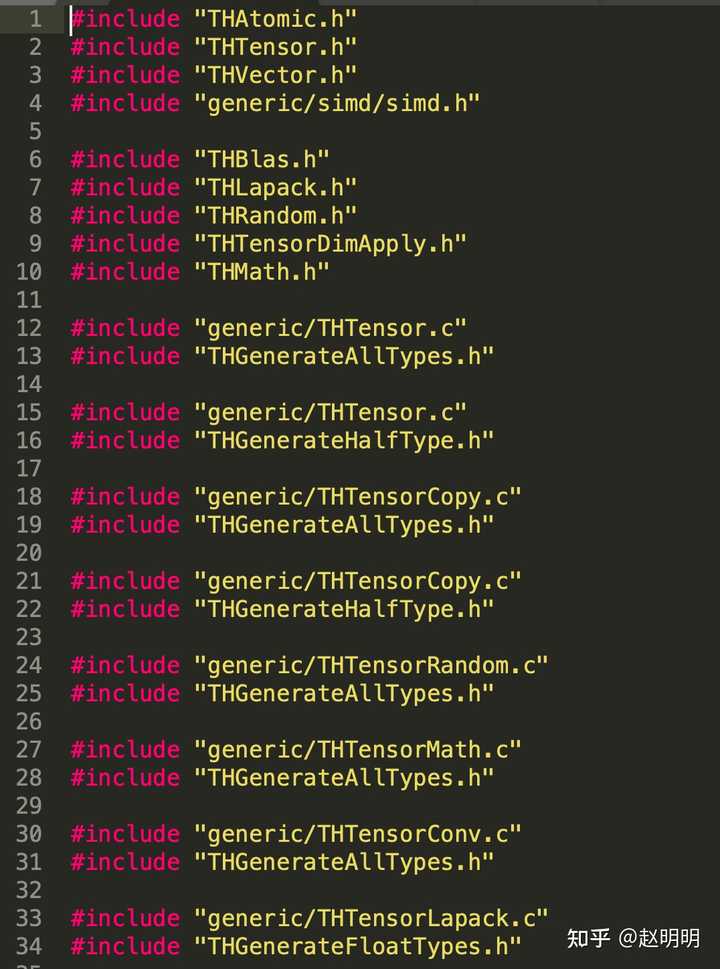

这两个文件都没有具体的实现,都调用了 lib/TH/generic/文件夹下的c文件来具体实现。
其中:generic/THTensor.c实现了矩阵的数据结构,以及矩阵的基本操作。
generic/THTensorRandom.c产生随机矩阵。
generic/THTensorConv.c实现卷积计算。
generic/THTensorMath.c实现一些矩阵的基本计算。
generic/THTensorLappack.c直接调用了Lapack计算库。
在generic/THTensor.h中有一个基本的数据结构:
结构体 THTensor 的代码:
typedef struct THTensor
{
long *size;
long *stride;
int nDimension;
THStorage *storage;
ptrdiff_t storageOffset;
int refcount;
char flag;
} THTensor;THTensor就是张量,就是矩阵,就是我们卷积所卷的那个矩阵。做卷积时,输入特征图,输出特征图,卷积核都是矩阵。所以此结构体,就这个深度学习框架的数据核心。
那么其对矩阵的计算是怎么实现的呢?
那么它是如何实现卷积的?
那么对不同数据类型是怎么支持的呢?
1. 矩阵计算的实现
通过THTensorMath.h,THTensorConv.h中声明的一些函数和THVector.h中声明的一些列函数来实现的。
节选的THTensorMath.h中的内容:
TH_API void THTensor_(add)(THTensor *r_, THTensor *t, real value);
TH_API void THTensor_(sub)(THTensor *self, THTensor *src, real value);
TH_API void THTensor_(mul)(THTensor *r_, THTensor *t, real value);
TH_API void THTensor_(div)(THTensor *r_, THTensor *t, real value);
TH_API void THTensor_(lshift)(THTensor *r_, THTensor *t, real value);
TH_API void THTensor_(rshift)(THTensor *r_, THTensor *t, real value);
。。。下面是THVector.h的全部内容:
#ifndef TH_GENERIC_FILE
#define TH_GENERIC_FILE "generic/THVector.h"
#else
TH_API void THVector_(fill)(real *x, const real c, const ptrdiff_t n);
TH_API void THVector_(cadd)(real *z, const real *x, const real *y, const real c, const ptrdiff_t n);
TH_API void THVector_(adds)(real *y, const real *x, const real c, const ptrdiff_t n);
TH_API void THVector_(cmul)(real *z, const real *x, const real *y, const ptrdiff_t n);
TH_API void THVector_(muls)(real *y, const real *x, const real c, const ptrdiff_t n);
TH_API void THVector_(cdiv)(real *z, const real *x, const real *y, const ptrdiff_t n);
TH_API void THVector_(divs)(real *y, const real *x, const real c, const ptrdiff_t n);
TH_API void THVector_(copy)(real *y, const real *x, const ptrdiff_t n);
/* Initialize the dispatch pointers */
TH_API void THVector_(vectorDispatchInit)(void);
#endif注意这些函数都有两个扩号,其中前一个括号是宏定义的,编译前需要展开,展开后就剩下后面一个括号了。详细解释在这里:
THTensorMath.h中的函数在ThTensorMath.c中实现:
void THTensor_(cadd)(THTensor *r_, THTensor *t, real value, THTensor *src)
{
THTensor_(resizeAs)(r_, t);
if (THTensor_(isContiguous)(r_) && THTensor_(isContiguous)(t) && THTensor_(isContiguous)(src) && THTensor_(nElement)(r_) == THTensor_(nElement)(src)) {
if(r_ == t) {
THBlas_(axpy)(THTensor_(nElement)(t), value, THTensor_(data)(src), 1, THTensor_(data)(r_), 1);
} else {
TH_TENSOR_APPLY3_CONTIG(real, r_, real, t, real, src, THVector_(cadd)(r__data, t_data, src_data, value, r__len););
}
} else {
TH_TENSOR_APPLY3(real, r_, real, t, real, src, *r__data = *t_data + value * *src_data;);
}
}可以看到,这里调用了THBlas_(axpy),和THVector_(cadd).
其中THBlas_是openblas高性能计算库函数的简单封装,在torch7/lib/TH/generic/THBlas.c中实现。
THVector_(cadd)就比较复杂了,它整合了SSE ,AVX等各种指令集优化的计算方法,所以源码结构比较复杂。
它主要靠lib/TH/generic/THVectorDispatch.c去做适配,这个适配过程比较复杂,详细可查:
2. 卷积计算的实现
通过THTensorConv.h中声明的一些函数和THVector.h中声明的一些列函数来实现的。
节选的THTensorConv.h:
TH_API void THTensor_(validXCorr2Dptr)(real *r_,
real alpha,
real *t_, long ir, long ic,
real *k_, long kr, long kc,
long sr, long sc);
TH_API void THTensor_(validConv2Dptr)(real *r_,
real alpha,
real *t_, long ir, long ic,
real *k_, long kr, long kc,
long sr, long sc);
TH_API void THTensor_(fullXCorr2Dptr)(real *r_,
real alpha,
real *t_, long ir, long ic,
real *k_, long kr, long kc,
long sr, long sc);
TH_API void THTensor_(fullConv2Dptr)(real *r_,
real alpha,
real *t_, long ir, long ic,
real *k_, long kr, long kc,
long sr, long sc);
这里我们重点看下THTensor_(fullConv2Dprt)的实现:
/*
2D Input, 2D kernel : convolve given image with the given kernel, full convolution.
*/
void THTensor_(fullConv2Dptr)(real *r_,
real alpha,
real *t_, long ir, long ic,
real *k_, long kr, long kc,
long sr, long sc)
{
long oc = (ic - 1) * sc + kc;
long xx, yy, kx, ky;
if ((sc != 1) || (ic < 4)) {
/* regular convolution */
for(yy = 0; yy < ir; yy++) {
for(xx = 0; xx < ic; xx++) {
/* Outer product in two dimensions... (between input image and the mask) */
real *po_ = r_ + yy*sr*oc + xx*sc;
real *pw_ = k_;
for(ky = 0; ky < kr; ky++)
{
real z = *t_ * alpha;
for(kx = 0; kx < kc; kx++) {
po_[kx] += z * pw_[kx];
}
po_ += oc; /* next input line */
pw_ += kc; /* next mask line */
}
t_++;
}
}
} else {
/* SSE-based convolution */
for(yy = 0; yy < ir; yy++) {
real *po_ = r_ + yy*sr*oc;
real *pw_ = k_;
for (ky = 0; ky < kr; ky++) {
real *pos_ = po_;
for (kx = 0; kx < kc; kx++) {
THVector_(cadd)(pos_, pos_, t_, alpha*pw_[kx], ic);
pos_++;
}
po_ += oc; /* next input line */
pw_ += kc; /* next mask line */
}
t_ += ic;
}
}
}这里面有THVector_(cadd),这个THVector_(cadd)就是通过指令集适配的基本算子。
这里的THTensor_(fullConv2Dptr)将会被编译到libtorch.so中,然后经过torchwrap包装,可被lua调用。
torch7/TensorMath.lua就是一个调用torchwrap包装后的Conv2D函数的例子。
3. 实现不同数据类型的计算
float,double,int类型,都是怎么支持的呢?这是C语言,不是高级面向对象语言,没有模版编程的概念,那么它是如何实现多类型的实现的呢?
依靠预编译宏定义。我们先看一个简单的例子。
要实现add函数对int,float型的适配,我们只用写add.h和add.c这样两个文件:
在add.c中:
real add(real a,real b){
Return a+b;
}在add.h中
#define real int
#line 1 “add.c”
#include “add.c”
#undefine real
#define real float
#line 1 “add.c”
#include “add.c”
#undifne real这样, 在编译时,就会将add.c中的add函数,编译两遍,第一遍的到int 类型的函数,第二遍的到float类型的函数。
torch7正是利用了这个办法,巧妙的实现了多种数据类型的计算支持,相当于C++种的模型函数。
它的实现在torch7/lib/TH/generic/的以Type.h结尾的文件里,
比如: THGenerateFloatType.h


第13行,#include了一个TH_GENERIC_FILE, 如果这个变量的值为torch7/lib/TH/generic/THBlash.c
那么也就是这里把THBlas.c中的所有以real为参数的函数,都用float代替后,编译了一遍。
也就是说,我们的到了一个float类型的blas算子。
那也就是说,如果这样写:
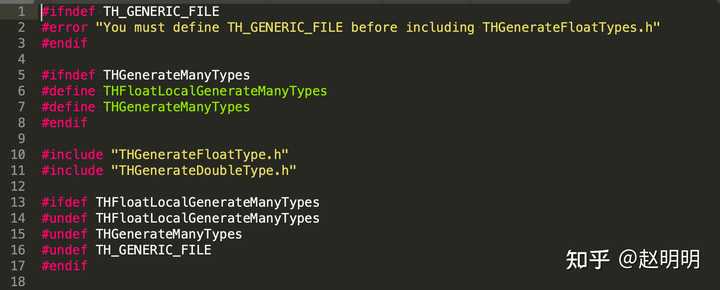

第10行后,再执行第11行,我们将的到float类型和double类型的blas算子。
如果这样写:


经过10,11,12,13,14行后,将得到byte, char,short,int long类型的blas算子。
这样我们就实现了7种数据类型的 blas算子。
那么:即然blas算子能够实现多种数据类型,其他算子,其他计算函数也可以。
在以下文件的第二行,都定义了TH_GENERIC_FILE
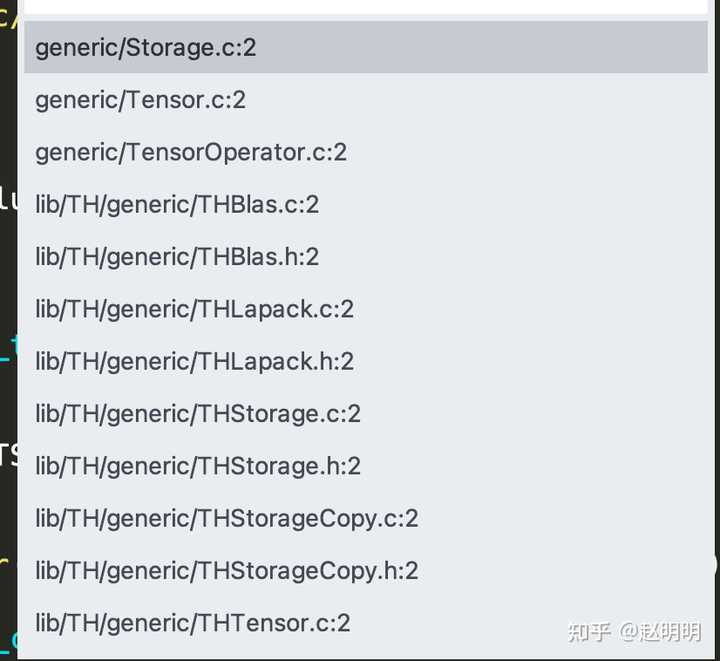

比如Torch7/lib/TH/generic/THTensor.c文件的第2行:


凡是对TH_GENERIC_FILE有定义的文件,都会在编译的时候,实现多种数据类型的支持。
可以把这样的预编译技术,称为C语言利用预编译法,实现模版函数。
4. 总结
torch7的源码,以C语言实现底层算子,lua包装底层算子,实现快速的应用。
c语言的实现部分都是torch7/lib/TH里,这个文件夹编译后,生成lib.TH.0.so/或者lib.TH.0.dylib。
lib.TH.0.dylib对应的源码中,有些代码对于C语言不熟悉的人来说,是比较复杂的:
1 函数的定义中出现两个括号。
2 以结构体为元素的数组的初始化。并且在初始化的语句中嵌入了大量宏定义。
3 C语言实现模版函数。这个就是本文的第3部分:实现不同数据类型的计算。


数据科学家必知五大深度学习框架!
目录
1) 什么是深度学习框架?
2) TensorFlow
3) Keras
4) PyTorch
5) Caffe
6) Deeplearning4j
7) 五个深度学习框架之间的对比
什么是深度学习框架?
让我们用一个例子来理解这个概念,来看以下图像集合:
在这个图像中有不同的分类:猫,骆驼,鹿,大象等。我们的任务是将这些图像归到相应的类(或类别)中。快速的Google搜索会告诉我们:卷积神经网络(CNNs)对于这类图像分类任务十分有效。
我们要做的工作就是实现这个模型,对吗?如果从头开始编写一个卷积神经网络,则需要几天(甚至几周)才能得到一个有效的模型,我们却没法等这么长的时间!
这正是深度学习框架真正改变了局面的地方。
深度学习框架是一种界面、库或工具,它使我们在无需深入了解底层算法的细节的情况下,能够更容易、更快速地构建深度学习模型。深度学习框架利用预先构建和优化好的组件集合定义模型,为模型的实现提供了一种清晰而简洁的方法。
利用恰当的框架来快速构建模型,而无需编写数百行代码,一个良好的深度学习框架具备以下关键特征:
1) 优化的性能
2) 易于理解和编码
3) 良好的社区支持,
4) 并行化的进程,以减少计算
5) 自动计算梯度
这五点也是我用来挑选五大顶级深度学习框架的标准。下面让我们详细研究一下它们。
TensorFlow
TensorFlow是由谷歌大脑团队的研究人员和工程师开发的,它是深度学习领域中最常用的软件库(尽管其他软件正在迅速崛起)。
我喜欢TensorFlow的原因有两点:它完全是开源的,并且有出色的社区支持。TensorFlow为大多数复杂的深度学习模型预先编写好了代码,比如递归神经网络和卷积神经网络。
TensorFlow如此流行的最大原因之一是支持多种语言来创建深度学习模型,比如Python、C和R,并且有不错的文档和指南。
TensorFlow有许多组件,其中最为突出的是:
1) Tensorboard:帮助使用数据流图进行有效的数据可视化:
2) TensorFlow:用于快速部署新算法/试验
TensorFlow的灵活架构使我们能够在一个或多个CPU(以及GPU)上部署深度学习模型。下面是一些典行的TensorFlow用例:
1. 基于文本的应用:语言检测、文本摘要
2. 图像识别:图像字幕、人脸识别、目标检测
3. 声音识别
4. 时间序列分析
5. 视频分析
用例远远不止这些,如果你知道TensorFlow还有以上所述之外的其他应用,我很乐意知道!可以在本文的评论部分告诉我,我们再做讨论。
安装TensorFlow也是一个非常简单的任务。
对于CPU:


对于启用CUDA的GPU卡:


Keras
你习惯使用Python吗?如果是,那么可以立即连接到Keras。这是一个完美的框架,开启你的深度学习之旅。
Keras用Python编写,可以在TensorFlow(以及CNTK和Theano)之上运行。TensorFlow的接口具备挑战性,因为它是一个低级库,新用户可能会很难理解某些实现。
而Keras是一个高层的API,它为快速实验而开发。因此,如果希望获得快速结果,Keras会自动处理核心任务并生成输出。Keras支持卷积神经网络和递归神经网络,可以在CPU和GPU上无缝运行。
深度学习的初学者经常会抱怨:无法正确理解复杂的模型。如果你是这样的用户,Keras便是你的正确选择!它的目标是最小化用户操作,并使其模型真正容易理解。
可以将Keras中的模型大致分为两类:
- 序列化:模型的层是按顺序定义的。这意味着当我们训练深度学习模型时,这些层次是按顺序实现的。下面是一个顺序模型的示例:


Keras有多种架构,如下所述,用于解决各种各样的问题,其中包括我的最爱之一:图像分类!
1. VGG 16
2. VGG 19
3. InceptionV 3
4. Mobilenet及更多
可以参考官方的Keras文档来详细了解框架是如何工作的。
仅需一行代码即可安装Keras:


PyTorch
还记得我们说过TensorFlow是目前最常用的深度学习框架吗?但是如果考虑到数据科学家和开发者们拥抱Facebook的PyTorch的速度,那它可能很快就要落伍了。
我是PyTorch的拥护者,在我所研究过的框架中,PyTorch最富灵活性。
PyTorch是Torch深度学习框架的一个接口,可用于建立深度神经网络和执行张量计算。Torch是一个基于Lua的框架,而PyTorch则运行在Python上。
PyTorch是一个Python包,它提供张量计算。张量是多维数组,就像numpy的ndarray一样,它也可以在GPU上运行。PyTorch使用动态计算图,PyTorch的Autograd软件包从张量生成计算图,并自动计算梯度。
与特定功能的预定义的图表不同,PyTorch提供了一个框架,用于在运行时构建计算图形,甚至在运行时也可以对这些图形进行更改。当不知道创建神经网络需要多少内存的情况下,这个功能便很有价值。
可以使用PyTorch处理各种来自深度学习的挑战,包括:
1. 影像(检测、分类等)
2. 文本(NLP)
3. 增强学习
想知道如何在机器上安装PyTorch,请请稍等片刻。安装步骤取决于操作系统、需要安装的PyTorch包、正在使用的工具/语言、CUDA等其他一些因素。
Caffe
CAFE是另一个面向图像处理领域的、比较流行的深度学习框架,它是由贾阳青(Yangqing Jia)在加利福尼亚伯克利大学读博士期间开发的。同样,它也是开源的!
首先,Caffe对递归网络和语言建模的支持不如上述三个框架。但是Caffe最突出的地方是它的处理速度和从图像中学习的速度。
Caffe可以每天处理超过六千万张图像,只需单个NVIDIA K40 GPU,其中 1毫秒/图像用于推理,4毫秒/图像用于学习。
它为C、Python、MATLAB等接口以及传统的命令行提供了坚实的支持。
通过 Caffe Model Zoo框架可访问用于解决深度学习问题的预训练网络、模型和权重。这些模型可完成下述任务:
1. 简单的递归
2. 大规模视觉分类
3. 用于图像相似性的SiameSE网络
4. 语音和机器人应用
Deeplearning4j
我们社区中有Java程序员吗?这是你理想的深度学习框架!Deeplearning4j是用Java实现的,因此与Python相比效率更高。它使用称为ND4J的张量库,提供了处理n维数组(也称为张量)的能力。该框架还支持CPU和GPU。
Deeplearning4j将加载数据和训练算法的任务作为单独的过程处理,这种功能分离提供了很大的灵活性。谁都喜欢这样,尤其是在深度学习中?!
Deeplearning4j也适用于不同的数据类型:
1. 图像
2. CSV
3. 纯文本等。
可以使用Deeplearning4j构建的深度学习模型有:
1. 卷积神经网络(CNNs)
2. 递归神经网络(RNNs)
3. 长短时记忆(LSTM)等多种结构.
阅读Deeplearning4j的安装步骤和文档,开始使用这个框架。
五种深度学习框架之间的对比
上面已经讨论了五个最流行的深度学习框架,每一个都独具特性,那么数据科学家会从中如何做出选择。
你决定用哪一种了吗?或者你打算换一个全新的框架?不管是什么情况,了解每个框架的优点和局限性非常重要。如果选对了正确的框架,当遇到错误时,便不会感到惊讶了!
某些框架在处理图像数据时工作得非常好,但无法解析文本数据;某些框架在处理图像和文本数据时,性能很好,但是它们的内部工作原理很难理解。
在本节中,将使用以下标准比较这五个深度学习框架:
1. 社区支持力度
2. 使用的语言
3. 接口
4. 对预训练的模型的支持
下表对这些框架进行了比较:
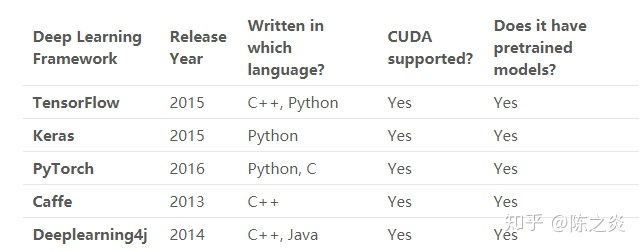

对于选择使用的框架来说,这是一个非常方便的对比表!
所有这些框架都是开源的,支持CUDA,并有预训练的模型。但是,应该如何正确开始,应该选择哪个框架来构建(初始)深度学习模型?让我们来做详细的讨论!
TensorFlow
我们先来说说TensortFlow。TensorFlow能处理图像以及基于序列的数据,如果你是深度学习的初学者,或者对线性代数和微积分等数学概念没有坚实的基础,那么TensortFlow的学习曲线将会令人畏惧地陡峭。
我完全理解,对于刚起步的人来说,这可能太复杂。但我建议你不断练习,不断探索社区,并继续阅读文章以掌握TensorFlow的诀窍。一旦对这个框架有了一个很好的理解,实现一个深度学习模型对你来说将是易如反掌。
Keras
Keras是一个非常坚实的框架,可以开启深度学习之旅。如果你熟悉Python,并且没有进行一些高级研究或开发某种特殊的神经网络,那么Keras适合你。
重点更多地放在取得成果上,而不是被模型的复杂之处所困扰。因此,如果有一个与图像分类或序列模型相关的项目,可以从Keras开始,很快便可以构建出一个工作模型。
Keras也集成在TensorFlow中,因此也可以使用tf.keras.构建模型。
Caffe
在图像数据上构建深度学习模型时,Caffe是不错的选择。但是,当谈到递归神经网络和语言模型时,Caffe落后于我们讨论过的其他框架。Caffe的主要优点是,即使没有强大的机器学习或微积分知识,也可以构建出深度学习模型。
Caffe主要用于建立和部署移动电话和其他计算受限平台的深度学习模型。
Deeplearning4j
正如之前所述,DeepleEarning4J是Java程序员的天堂。它为CNNS、RNN和LSTMS等不同的神经网络提供了大量的支持,它在不牺牲速度的情况下可以处理大量数据。听起来不错,有机会通过!