指标权重确定方法及具体步骤介绍?
7 个回答

本文将介绍八种权重计算方法,并且依据其原理进行分类,对方法所需的数据格式、指标结果解读进行介绍。
另外针对一些常见问题:如多级权重如何计算?用多种方法计算得到的权重如何合并为综合权重用于之后的分析?常见的不同权重计算方法的搭配方式,在之后的第二部分里进行详细说明。
一、第一部分:权重确定方法分类
权重计算的确定方法在综合评价中重中之重,不同的方法对应的计算原理并不相同。在实际分析过程中,应结合数据特征及专业知识选择适合的权重计算。
下面介绍的权重方法,共8种按照计算原理可分成四类。


- 第一类为AHP层次法和优序图法;此类方法利用数字的相对大小信息进行权重计算;此类方法为主观赋值法,通常需要由专家打分或通过问卷调研的方式,得到各指标重要性的打分情况,得分越高,指标权重越大。
此类方法适合于多种领域。比如想构建一个员工绩效评价体系,指标包括工作态度、学习能力、工作能力、团队协作。通过专家打分计算权重,得到每个指标的权重,并代入员工数据,即可得到每个员工的综合得分情况。
- 第二类为熵值法(熵权法);此类方法利用数据熵值信息即信息量大小进行权重计算。此类方法适用于数据之间有波动,同时会将数据波动作为一种信息的方法。
比如收集各地区的某年份的经济指标数据,包括产品销售率(X1)、资金利润率(X2)、成本费用利润率(X3)、劳动生产率(X4)、流动资金周转次数(X5),用熵值法计算出各指标权重,再对各地区经济效益进行比较。
- 第三类为CRITIC、独立性权重和信息量权重;此类方法主要是利用数据的波动性或者数据之间的相关关系情况进行权重计算。
比如研究利用某省医院2011年共计5个科室的数据指标(共计6个指标数据)进行CRITIC权重计算,最终可得到出院人数、入出院诊断符合率、治疗有效率、平均床位使用率、病床周转次数、出院者平均住院日这6个指标的权重。如果希望针对各个科室进行计算综合得分,那么可以直接将权重与自身的数据进行相乘累加即可,分值越高代表该科室评价越高。
- 第四类为因子分析和主成分法;此类方法利用了数据的信息浓缩原理,利用方差解释率进行权重计算。
比如对30个地区的经济发展情况的8项指标作主成分分析,主成分分析法可以将8个指标浓缩为几个综合指标(主成分),用这些指标(主成分)反映原来指标的信息,同时利用方差解释率得出各个主成分的权重。
1、AHP层次分析法
(1)方法原理及适用场景
AHP层次分析法是一种定性和定量的计算权重的研究方法,采用两两比较的方法,建立矩阵,利用了数字大小的相对性,数字越大越重要权重会越高的原理,最终计算得到每个因素的重要性。
适用场景:层次分析法适用于有多个层次的综合评价中。
(2)操作步骤
使用 SPSSAU【综合评价-AHP层次分析】。
数据格式
AHP层次分析法一般用于专家打分,让多位专家对比两两指标,根据相对重要性的打分判断矩阵,然后进行汇总(一般是去掉最大值和最小值,然后计算平均值得到最终的判断矩阵),最终计算得到各因素的权重。
首先用户需要构建判断矩阵,将专家打分结果填入判断矩阵中。如下图所示:


比如指标2相对于指标1的重要性更高,专家打分为3分。那么就在对应的单元格里填入3。


依次将所有打分结果数值填入,点击“开始分析”,即可计算权重及一致性检验结果。
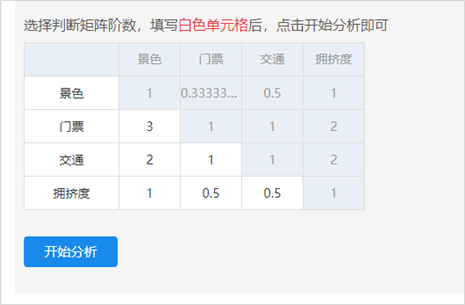

注:判断矩阵是‘下三角’完全对称矩阵,因此‘白色’底纹处的信息变化时,‘蓝色’背景的信息会自动变化。
结果解读
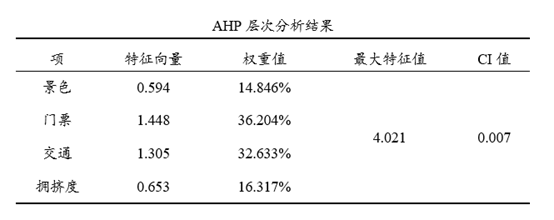



通过一致性检验,说明计算所得权重具有一致性,即可得到最终权重值。
如果未通过一致性检验,则需要检查是否存在逻辑问题等,重新录入判断矩阵进行分析。
(3)注意事项
- 如果计算二级权重或准则层权重?
当有多层级指标时,不论是准测层,还是方案层,计算权重的方法均一致,准测层单独录入判断矩阵进行计算权重即可。如果准测层和方案层均均测量了权重,可以手工进行相乘计算得到各方案层最终的权重值。
- 问卷数据如何使用AHP层次分析计算权重?
如果是问卷数据可以使用SPSSAU【问卷研究--权重】里的AHP权重进行分析。SPSSAU默认自动构建判断矩阵,并计算权重。
2、优序图法
(1)方法原理及适用场景
优序图法同样是利用了数字大小的相对性,数据上为专家针对各个指标进行大分析。优序图算法上会对指标先进行平均值计算,然后对两两指标进行比较,若指标A比指标B重要,则A得1分;若同等重要,则A得0.5分;若指标B比指标A重要,则A得0分。
适用场景:优序图的计算简单,容易操作,适合有较多指标时使用。
(2)操作步骤
使用 SPSSAU【问卷研究-权重-优序图】。

数据格式
使用优序图计算权重时,需将数据整理为以下格式:

1个样本为1行,1个计算权重的指标占1列数据即可。即直接使用正常的问卷研究数据即可。SPSSAU默认会首先计算出此各指标的平均值,然后利用平均值进行优序图矩阵的构建。
结果解读

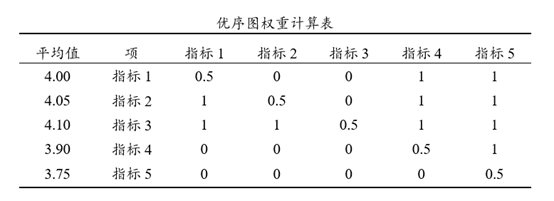
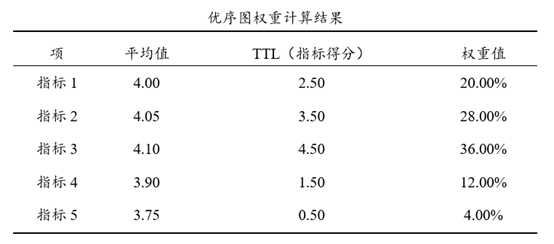
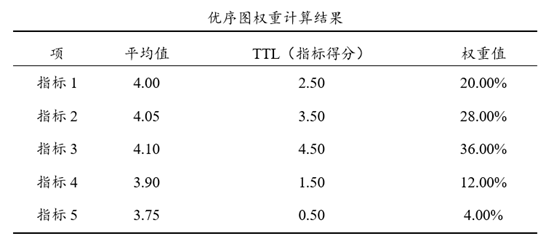
优序图权重表构建方式为:
第一:计算出各分析项的平均值,接着利用平均值大小进行两两对比;
第二:平均值相对更大时计为1分,相对更小时计为0分,平均值完全相等时计为0.5分;
第三:平均值越大意味着重要性越高(请确保是此类数据),权重也会越高。
3、熵值法
(1)方法原理及适用场景
熵值法属于一种客观赋值法,其利用数据携带的信息量大小计算权重,得到较为客观的指标权重。熵值是不确定性的一种度量,熵越小,数据携带的信息量越大,权重越大;相反熵越大,信息量越小,权重越小。
适用场景:熵值法广泛应用于各个领域,对于普通问卷数据(截面数据)或面板数据均可计算。在实际研究中,通常情况下是与其他权重计算方法配合使用,如先进行因子或主成分分析得到因子或主成分的权重,即得到高维度的权重,然后再使用熵值法进行计算,想得到具体各项的权重。
(2)操作步骤
使用 SPSSAU【综合评价-熵值法】。

数据格式
使用熵值法计算权重时,需将数据整理为以下格式:

1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。
结果解读


(3)注意事项
熵值法的计算公式上会有取对数,因此如果小于等于0的数字取对数,则会出现null值。此种情况共有两种办法。
第一种:SPSSAU非负平移功能是指,如果某列(某指标)数据出现小于等于0,则让该列数据同时加上一个‘平移值’【该值为某列数据最小值的绝对值+0.01】,以便让数据全部都大于0,因而满足算法要求。
第二种:研究者也可以手工查看数据并将小于等于0的数据设置为异常值,但此种做法会让样本减少。
4、CRITIC权重
(1)方法原理及适用场景
CRITIC权重法是一种客观赋权法。其思想在于用于两项指标,分别是对比强度和冲突性指标。对比强度使用标准差进行表示,如果数据标准差越大说明波动越大,权重会越高;冲突性使用相关系数进行表示,如果指标之间的相关系数值越大,说明冲突性越小,那么其权重也就越低。权重计算时,对比强度与冲突性指标相乘,并且进行归一化处理,即得到最终的权重。
适用场景:CRITIC权重综合考虑了数据波动情况和指标间的相关性,因此,CRITIC权重法适用于这样一类数据,即数据稳定性可视作一种信息,并且分析的指标或因素之间有着一定的关联关系时。比如医院里面的指标:出院人数、入出院诊断符合率、治疗有效率、平均床位使用率、病床周转次数共5个指标;此5个指标的稳定性是一种信息,而且此5个指标之间本身就可能有着相关性。因此CRITIC权重法刚好利用数据的波动性(对比强度)和相关性(冲突性)进行权重计算。
(2)操作步骤
使用 SPSSAU【综合评价-CRITIC权重】。

数据格式
使用CRITIC权重计算权重时,需将数据整理为以下格式:

1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,分析时并不需要使用。
结果解读


(3)注意事项
1、CRITIC分析之前是否需要进行量纲化处理?
SPSSAU建议在分析前需要对数据量纲化处理,以便统一数据的单位,避免量纲问题带来的干扰。但是并不建议标准化这种处理方式,原因在于标准化后所有指标的标准差都为1,导致指标变异性全部一致。SPSSAU建议使用正向化或逆向化处理指标进行量纲化处理。
5、独立性权重
(1)方法原理及适用场景
独立性权重是一种仅考虑指标相关性的权重计算方法,其思想在于利用指标之间的共线性强弱来确定权重。
适用场景:适合指标间本身带有一定的相关性的数据。
(2)操作步骤
使用 SPSSAU【综合评价-独立性权重】。

数据格式
使用独立性权重计算权重时,需将数据整理为以下格式:


1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,分析时并不需要使用。
结果解读


6、信息量权重
(1)方法原理及适用场景
信息量权重是一种仅考虑指标变异程度的权重计算方法,变异系数越大,说明其携带的信息越大,因此权重也会越大。
(2)操作步骤
使用 SPSSAU【综合评价-信息量权重】。
数据格式
使用信息量权重计算权重时,需将数据整理为以下格式:

1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,分析时并不需要使用。
结果解读


7、主成分分析
(1)方法原理及适用场景
主成分分析是对数据进行浓缩,将多个指标浓缩成为几个彼此不相关的概括性指标(主成分),从而达到降维的目的。主成分分析可同时计算主成分权重及指标权重。
(2)操作步骤
使用 SPSSAU【进阶方法-主成分分析】。


如果计算主成分权重,需要用到方差解释率。具体加权处理方法为:方差解释率除累积方差解释率。
比如本例中,5个指标共提取了2个主成分:
主成分1的权重:45.135%/69.390%=65.05%
主成分2的权重:24.254%/69.390%=34.95%
如果是计算指标权重,可直接查看“线性组合系数及权重结果表格”,SPSSAU自动输出了各指标权重占比结果。其计算原理分为三步:
第一:计算线性组合系数矩阵,公式为:loading矩阵/Sqrt(特征根),即载荷系数除以对应特征根的平方根;
第二:计算综合得分系数,公式为:累积(线性组合系数*方差解释率)/累积方差解释率,即上一步中得到的线性组合系数分别与方差解释率相乘后累加,并且除以累积方差解释率;
第三:计算权重,将综合得分系数进行归一化处理即得到各指标权重值。


(3)注意事项
1、分析之前是否需要对数据进行标准化处理?
SPSSAU默认就已经进行过标准化处理,因此不需要再对数据处理。当然标准化后的数据再次标准化依旧还是自身没有任何变化,结果永远均一致。
8、因子分析
(1)方法原理及适用场景
因子分析与主成分分析计算权重的原理基本一致,区别在于因子分析加带了‘旋转’的功能‘,旋转’功能可以让因子更具有解释意义,如果希望提取出的因子具有可解释性,一般使用因子分析法更多;并非说主成分出来的结果就完全没有可解释性,只是有时候其解释性相对较差而已,但其计算更快,因而受到广泛的应用。
(2)操作步骤
使用 SPSSAU【进阶方法-因子分析】。



- 如何计算因子权重?
在计算各因子权重时,使用到的是旋转后的方差解释率进行计算。具体加权处理方法为:旋转后方差解释率除累积方差解释率。
比如本例中,5个指标共提取了2个主成分:
主成分1的权重:37.898%/69.390%=54.62%
主成分2的权重:31.492%/69.390%=48.38%
- 如何计算指标权重?
计算指标权重时,其步骤与主成分分析计算指标权重步骤均一致,只是在第二步计算综合得分系数,使用的是旋转后的方差解释率。权重结果可直接在“线性组合系数及权重结果表格”里查看。


二、第二部分:权重计算的常见问题
1、多种权重计算方法组合使用,如何得到综合权重?
每种权重计算方法都有其适用范围,有时候往往需要采用多种方法测量同一份数据的权重,这样得到综合权重性能更高,更加能反映出数据的真实特征。比如同时使用熵值法和AHP法, AHP法能够体现专家对不同指标的经验,熵值法可以反映出数据本身提供的信息量特征,两者结合使用不仅可以减少AHP法赋权的主观性,也会减少数据变化导致权重的波动。
- 第一种情况:两种权重计算方法原理相同,属于同一类方法。
此时可计算平均值,所得结果即为综合权重。例如AHP层次分析法和优序图法,都属于主观赋值法,利用数字大小计算权重,此时可计算两者均值作为综合权重。
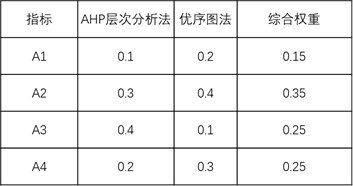
比如A1指标的综合权重为0.15,即(0.1+0.2)/2=0.15。
- 第二种情况:两种权重采用的计算原理不相同,利用的数据特征也不一致。
例如用熵值法和AHP法计算权重,一个是主观赋值权重,一个是客观赋值权重。将2种方法结合使得到的数据更加能反映实际情况。公式如下,即A*B/ (A*B的求和)。A、B为2种方法求得的权重。


计算综合权重的方法不止一种,建议在实际处理时以参考文献为准。例如主成分和AHP层次分析法结合计算,常用的综合权重计算公式如下:
W=tWahp+(1-t)Wpc
其中Wahp为AHP法所得权重,Wpc为主成分法所的权重。t的取值在0~1之间,其取决于AHP法各指标权重的差异程度:
- 如果AHP法各指标权重差距不大时,t应该取小些。
- 如果AHP法各指标权重差距较大时,t应该取大些。
- 如果两种方法计算结果差别不大,t值默认取0.5。

比如当t值取0.3,A1指标综合权重即WA1=0.3*0.1+(1-0.3)*0.2=0.17。其他指标计算过程以此类推。
2、多层级权重如何计算?
在多层次综合评价研究中,不光需要计算方案层权重,还有准则层权重。那么应该如何计算呢?
不论是准测层,还是方案层一般均需要测量权重。然后再手工进行相乘计算得到各方案层最终的权重值。


比如,有这样一个研究需要构建员工绩效评价体系,设计了如上图的评价指标体系,并通过专家打分收集数据。现需要通过AHP法计算各级权重,并使用该评价体系计算每个员工的综合得分情况。
在分析时,每一层的权重需要单独计算。首先使用SPSSAU【综合评价】--【AHP层次分析】计算工作态度下属各个指标的权重。将专家打分结果填入表格。


以此类推,分别计算出学习能力、工作能力、团队协作下各指标的权重。这样就得到了二级指标权重,即方案层的权重。
然后同样做法计算一级指标权重,将专家打分结果填入表格。


手工将方案层和准则层权重进行相乘计算得到各方案层最终的权重值。

比如,计算出一级指标权重分别为0.30、0.15、0.30、0.25。二级指标A1权重为0.23,则A1最终权重值为0.30*0.23=0.069。然后使用权重*得分即可得到综合得分。
不仅AHP法是这样计算权重,其他方法也同样如此。有一些常用的权重计算方法的搭配组合,比如AHP与熵值法,主成分与熵值法等,AHP或主成分法可能作为一级指标权重的方法。熵值法作为二级指标权重的方法。


这样的组合权重,分析时依然是分别得到一级权重和二级权重,再将一级权重、二级权重相乘,得到可用于分析计算的各指标权重。
参考资料: SPSSAU_权重确定的方法汇总
「更多内容登录SPSSAU官网了解」


权重计算九大计算方法
以SPSSAU为例


常见的权重计算方法主要有以下九种:


以上九种中最常用权重计算方法有以下四种:
1、AHP层次分析法
(1)方法原理
AHP层次分析法是一种定性和定量的计算权重的研究方法,采用两两比较的方法,建立矩阵,利用了数字大小的相对性,数字越大越重要权重会越高的原理,最终计算得到每个因素的重要性。
(2)适用场景
层次分析法适用于有多个层次的综合评价中。
(3)操作步骤
使用 SPSSAU【综合评价-AHP层次分析法】


2、熵值法
(1)方法原理
熵值法属于一种客观赋值法,其利用数据携带的信息量大小计算权重,得到较为客观的指标权重。熵值是不确定性的一种度量,熵越小,数据携带的信息量越大,权重越大;相反熵越大,信息量越小,权重越小。
(2)适用场景
熵值法广泛应用于各个领域,对于普通问卷数据(截面数据)或面板数据均可计算。在实际研究中,通常情况下是与其他权重计算方法配合使用,如先进行因子或主成分分析得到因子或主成分的权重,即得到高维度的权重,然后再使用熵值法进行计算,想得到具体各项的权重。
(3)操作步骤
使用 SPSSAU【综合评价-熵值法】


3、主成分分析法
(1)方法原
主成分分析是对数据进行浓缩,将多个指标浓缩成为几个彼此不相关的概括性指标(主成分),从而达到降维的目的。
(2)适用场景
主成分分析可同时计算主成分权重及指标权重
(3)操作步骤
使用 SPSSAU【进阶方法-主成分分析】


4、因子分析法
(1)方法原理
因子分析与主成分分析计算权重的原理基本一致,区别在于因子分析加带了‘旋转’的功能‘。
(2)适用场景
旋转’功能可以让因子更具有解释意义,如果希望提取出的因子具有可解释性,一般使用因子分析法更多。
(3)操作步骤
使用 SPSSAU【进阶方法-因子分析】


权重计算方法的应用分类
权重计算的确定方法在综合评价中重中之重,不同的方法对应的计算原理并不相同。在实际分析过程中,应结合数据特征及专业知识选择适合的权重计算以上九种权重计算方法特征如下表:


常用计算权重的方法,按照计算原理可分成四类
第一类为AHP层次法和优序图法;
此类方法利用数字的相对大小信息进行权重计算;此类方法为主观赋值法,通常需要由专家打分或通过问卷调研的方式,得到各指标重要性的打分情况,得分越高,指标权重越大。
此类方法适合于多种领域。比如想构建一个员工绩效评价体系,指标包括工作态度、学习能力、工作能力、团队协作。通过专家打分计算权重,得到每个指标的权重,并代入员工数据,即可得到每个员工的综合得分情况。
第二类为熵值法(熵权法);此类方法利用数据熵值信息即信息量大小进行权重计算。此类方法适用于数据之间有波动,同时会将数据波动作为一种信息的方法。
比如收集各地区的某年份的经济指标数据,包括产品销售率(X1)、资金利润率(X2)、成本费用利润率(X3)、劳动生产率(X4)、流动资金周转次数(X5),用熵值法计算出各指标权重,再对各地区经济效益进行比较。
第三类为CRITIC、独立性权重和信息量权重;此类方法主要是利用数据的波动性或者数据之间的相关关系情况进行权重计算。
比如研究利用某省医院2011年共计5个科室的数据指标(共计6个指标数据)进行CRITIC权重计算,最终可得到出院人数、入出院诊断符合率、治疗有效率、平均床位使用率、病床周转次数、出院者平均住院日这6个指标的权重。如果希望针对各个科室进行计算综合得分,那么可以直接将权重与自身的数据进行相乘累加即可,分值越高代表该科室评价越高。第四类为因子分析和主成分法;此类方法利用了数据的信息浓缩原理,利用方差解释率进行权重计算。
比如对30个地区的经济发展情况的8项指标作主成分分析,主成分分析法可以将8个指标浓缩为几个综合指标(主成分),用这些指标(主成分)反映原来指标的信息,同时利用方差解释率得出各个主成分的权重。
数据格式
第一次接触数据分析的小白选手往往直接将数据上传到分析系统中,忽略数据格式整理的步骤。然而,对于不同的分析方法而言,都有对应的数据格式。只有上传格式正确、规范的数据,才能得到正确的分析结果。
常见的权重计算方法数据格式说明,详情见下方SPSSAU帮助手册链接:
量纲化处理
怎样理解量纲化处理问题?
例如:
医院投入金额为1000000百万,出院率为90%。这两个指标会出现两种情况,分别为单位问题和方向问题。


量纲化处理方式:
量纲化有很多种方式,但具体应该使用哪一种方式,并没有固定的标准,而应该结合数据情况或者研究算法,选择最适合的量纲化处理方式,SPSSAU共提供11种量纲化处理方法,如下图:
使用 SPSSAU【数据处理-生成变量】



九种常用权重计算方法是否需要量纲化处理、需要进行什么样的量纲化处理详见下表:


若要了解权重计算相关的更详细知识,可进入 SPSSAU官网查看 帮助手册or联系 智能客服or 人工客服为您解答。

客观的指标权重确立方法主要是根据原始数据之间的关系,来确定各指标权重,其原始数据来自于各指标在评价中的实际数据。
常用的客观赋权法包括变异系数法、熵值法、CRITIC法、回归分析和结构方程模型等等,下面我们来简单介绍一下回归分析法和结构方程模型:
回归分析
回归分析(Regeression Analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的⼀种统计分析⽅法。它同样也可以被用来计算指标权重,具体方法如下:
- 去除量纲,指标正向化处理
- 建立回归模型,计算回归系数
- 使用回归系数作为原始相对影响力系数
- 影响力系数归⼀化处理: W(i)=X(i)/(X(1)+X(2) +X(3) +……+X(n)
这里要强调⼀下:去除量纲,是确定指标权重的第⼀步,也是最重要的⼀步。因为在实际研究中,不同的变量单位不同,数值差异极大,例如100g和1m,这样会给综合分析建模带来不便。因此,我们需要对收集得到的数据进行去量纲,即去掉单位对数值的影响,使所有的变量都在同等的水平上,才能“公平”地参与后续处理。

结构方程模型
结构方程模型(Structural Equation Modeling,简称SEM)是瑞典统计学家、心理测量学家Karl·G·Joreskog于20世纪70年代中期提出⼀种统计分析方法,主要用于探索变量之间的关系。那么,如何用它来计算指标权重呢?让我们用下图来举例说明:


1.计算各三级指标的权重系数
如上图所示,A对应的6个⼆级指标(B1-B6),B分别对应的三级指标。以B1为 例 , C1 的 权 重 系 数 =C1 的 因 子 负 荷 /C1-C3 的 因 子 负 荷 总 值 , 即 C1=0.65/ (0.65+0.70+0.78)≈0.33,最终得出三级指标的权重,如下表:


2.计算各⼆级指标的权重系数
仍以B1为例,B1的权重系数=B1的因子负荷/B1-B6的因子负荷总值,即B1=0.58/ (0.58+0.68+0.66+0.72+0.69+0.52),最终得出⼆级指标的权重,如下表:


另外几种客观赋权方法我们整理在了《体验度量:如何科学地确定指标权重?》总结报告里,报告也介绍了主观赋权的常用方法,感兴趣的话可以下载浏览~


「体验家XMPlus」提供以客户旅程为核心,集多源数据的收集-整合-分析-反馈于一体,覆盖互联网、连锁零售、医疗健康、智能制造、金融保险等多个行业的客户体验管理(CEM)解决方案。

一般有专家打分法;调查统计法;序列综合法;公式法;数理统计法;层次分析法;复杂度分析法。具体操作看文献

1.CRITIC简要简介
今天介绍的CRITIC权重赋值法也是一种不受主观因素影响,只由数据驱动的,客观地为指标赋权方法。
跟上之前介绍的熵权法不同的是,熵权法是围绕信息熵的计算展开的,然而CRITIC方法的核心是围绕两个概念展开的,这两个概念是:数据的波动度和冲突度。
那这两个概念是在计算权重的过程中起到了什么样的作用呢?接下来咱们就详细的说一说。
CRITIC法的具体流程如下:


2.CRITIC的的理论介绍
2.1 数据模型介绍
假设数据集由n个数据样本构成,在这个数据集的基础上定义了m个指标,抽象成数学语言表示如下:
X_1,X_2,\cdots,X_m
其中 {\ X}_i={x_1,x_2,\cdots,x_n}
2.2数据归一化处理
归一化是把数据经过缩放和平移的变换,把数据映射到[0,1]区间,这里的变化从本质上来讲是一种线性变化。
在做归一化之前需要注意一点,一定要判断指标的类型,通常情况下指标分为四种类型:
正向指标、负向指标、中间型指标和区间型指标。
1. 对正向指标进行归一化的计算方法是: Y_{ij}=\frac{X_{ij\ }-min(X_i)}{max(X_i)-min(X_i)}
2. 对负向指标进行归一化的计算方法是: Y_{ij}=\frac{max(X_i)-X_{ij\ }}{max(X_i)-min(X_i)}
3. 对中间型指标指标进行归一化的计算方法是:
M=max{|x_{i\ }-x_{best\ }|}{,Y}_i=1-\frac{|x_{i\ }-x_{best\ }|}{M}
4. 对区间型指标进行归一化的计算方法是:


2.3计算信息的承载量
1)波动度计算的公式是:
S_j=\sqrt{\frac{{\sum_{i=1}^{n}{(x_{ij}-\bar{x_j})}}^2}{n-1}}
其中j=1,...,m
细心的同学已经发现,波动度的计算方法跟统计学上计算标准差的方法是一样的,也就是说,CRITIC使用各指标内取值的差异情况来评价和决定如何分配权重。认为标准差越大,该指标所能反映的信息量越多,就应给给这个指标赋予更多权重。
2)冲突度计算的公式是:
R_j=\sum_{i=1}^{m}{(1-r_{ij})}
其中, r_{ij} 表示第i个指标与第j个指标的相关系数。
在统计学上,相关系数往往用来衡量两个变量之间的线性相关程度,它的取值范围是[-1,1]之间,如果两个变量计算出的相关系数越接近-1,则表示这两个变量之间有很强的负相关关系,如果两个变量计算出的相关系数越接近1,则表示这两个变量之间有很强的正相关关系。
从冲突度的计算方法可以看到,CRITIC方法认为指标之间的线性正相关系数数值越大,那么就说明冲突性越小,也就应该赋予更小的权重。
3)接下来计算信息的承载量,具体的计算方法是:
C_j=S_j\ast\ R_j
2.4计算指标权重
W_j=\frac{C_j}{\sum_{1}^{m}C_j}
3 python实现
import pandas as pd
import numpy as np
def data_prepare(data, flag=0):
'''
:param data: 输入数据,类型是DataFrame
:param flag: flag=0特征正向归一化,flag=1特征负向归一化
:return:返回 DataFrame数据
'''
data_columns = data.columns.values
maxnum = np.max(data,axis=0)
minnum = np.min(data, axis=0)
if flag == 0:#正向指标归一化计算
Y = (data - minnum)*1.0/(maxnum - minnum)
if flag == 1: #负向指标归一化计算
Y == (maxnum - minnum)/(maxnum - minnum)
#对ln0处理
Y0 = np.array(Y*1.0)
Y0[np.where(Y0==0)] = 0.00001
Y0 = pd.DataFrame(Y0,columns = data_columns)
return Y0
def CRITIC(data):
'''
:param data: 归一化预处理之后的DataFrame数据
:return: 返回权重Series以及按指标排序后的得分项
'''
n, m = data.shape
s = np.std(data,axis=0)
r = np.corrcoef(data,rowvar=False)
a = np.sum(1-r,axis=1)
c = s*a
w = c/np.sum(c)
score = np.round(np.sum(data * w, axis=1), 6)
data['score'] = score
data.sort_values(by=['score'], ascending=False, inplace=True)
return w, data
说明1:本文分享权重法,用于预测未来,所以是“预言家”;
说明2:参考资料《电商流量数据化运营》。
一、写在前面
我在两年前写的一篇文章中说过,数据分析师具有五重身份,包括取数机、对账工、背锅侠等等。
现在看来,数据分析师还有第六重身份:预言家。
预言家,通过蛛丝马迹,利用“通灵”、“先知”、“天眼”等“高级智慧”,预言未来;
数据分析师,根据历史数据,结合业务逻辑和多种分析方法,分析和预测数据。
两者不仅相似,甚至数据分析师在可复用、可解释方面,更胜一筹。
本文就从利用“权重法”预测数据展开。它是一种将数据进行合理拆分,然后再重组的方法。
事实上,之前分享的 seasonal_decompose拆解方法、 DAU的3种拆解方式,是从不同角度——数学和业务逻辑——出发的拆分重组手段,是相比于“权重法”更为常的预测数据的方法。
本文要讲的“权重法”,按层次由浅到深分为两种:
- 基础版:直接权重法。以预测DAU为例;
- 进阶版:历史权重法。以预测CTR为例。
二、基础版:直接权重法
直接将一组权重,赋予给历史数据,进行移动加权平均,实现数据预测。
比如,要预测T+0的DAU,可以为T-1、T-2、T-3这3天的DAU各自乘以一个由高到低的权重,三者总和再除以权重总和后,得到结果。
权重可以是1.0/0.8/0.6、1.0/0.9/0.8、1.2/1.0/0.8等等。
在上篇文章中 提到的时间衰变归因,也可以作为权重参数的选取依据。
如图1所示,为两种常用的权重参数。


应该选取多少天历史数据、选取多大的权重进行加权,可以根据实际与预测结果的差异综合衡量。
由于只是“毛估估”,计算周期选3-5天即可,权重参数选取尽可能简单。
图2为实际DAU与两种权重下DAU预测值的比较。


从图中可以看到,两组权重参数下的预测结果相当接近(橙线和红线基本重合)。另外,DAU波动较大时,预测结果的表现会“慢半拍”。
说明:不同权重间预测的结果差别不大;数据发生明显波动时,预测误差较大。
三、进阶版:历史权重法
将历史数据在某一特征下的均值,作为数据预测的参考标准。
比如按照日期进行预估时,需要对日期特征进行解构,这些特征包括:是否为工作日、星期几、月天数、几月份等等。
具体来说,计算过程分4步:
1、历史日期解构
Excel函数求取历史日期的时间特征,比如WEEKDAY函数判断星期几、DAY函数判断月天数。
图3中绿色底纹列是解构得到的时间特征。本文选择了3个特征以预测数据,即工作日(1代表工作日,0代表非工作日)、星期(1至7)、月天数(1~31)。
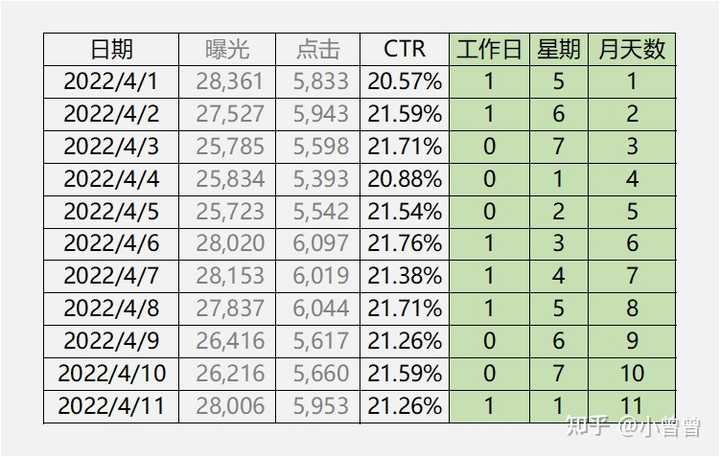

值得一提的是,由于调休,少量日期的工作日判断需要进行手动调整。比如图3中2022/4/2这一天,虽然是周六,但是因为清明节调休,所以调整为工作日。
2、特征聚合平均
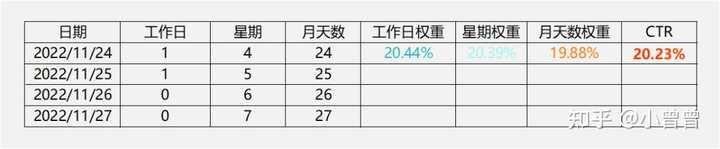
分别按照工作日、星期、月天数,进行聚合(数据透视),求取不同特征下的平均CTR(点击总和/曝光总和)。
图4为不同工作日、星期、月天数下的CTR。这个CTR即为后续预测的权重。


3、预测日期解构
与第1步类似,计算未来日期的时间特征。
4、特征加权平均
根据图4,匹配未来日期对应时间特征下的权重(VLOOKUP),对不同权重结果进行平均,得到预测值。
比如对于2022/11/24,工作日1对应20.44%,星期4对应20.39%,月天数24对应19.88%。最终预测结果为:
(20.44%+20.39%+19.88%)/3 = 20.23%
结果如图5所示。

四、写在最后
基础版和进阶版权重法,理解成本很低,在需要快速预测结果时,非常便捷实用。
在运用过程中,有4点需要注意:
【1】基础版权重法,在预测较长时间的数据时,会越来越不准确;
【2】要根据新的数据,不断修正预测结果;
【3】时间特征的选取依据,建立在指标受到特征影响的前提之下;
【4】特殊数据的处理,比如文中的调休,以及过年、大促等。
最后,数据分析师多掌握一些或细微、或冷门的分析技巧,在“跳身份”时,也能多一些依据,多一分自信
-End-
