菜鸟学习网络爬虫的最佳路线是什么?
22 个回答


谢邀。
最近快期末了,很多邀我的问题都忽略了,简单看了一下题主的主页,似乎是信安专业的。我也是信安的,深有同病相怜之感,所以来答。
信安作为一个计算机、通信、数学的交叉学科,开设课程是大都是理工科的基础课程和一些简单的编程,简单涉及密码学和网络安全基础,学的都比较浅,发展什么的就要看个人兴趣了。
在给出我的回答之前,我想先谈一谈你提的问题。
首先是「最佳路线」。讨论一个开放性的问题,很难有最佳解。而且,讨论最佳解,难免会有一种急功近利的嫌疑。国内有很多书冠以「21天」、「零基础」、「从入门到精通」的名头,这种书给我的印象就是「不靠谱」。所以你摆出一个「菜鸟」的身份,如果是想求得一份「21天零基础从入门到精通爬虫」的武林秘籍的话,我想就算有答案八成也是不靠谱的。
其次,你没有给出你现有的水平,和你希望达到的目标。你只是告诉我们你是「一名快要升大三的在校学生」。这句话除了能推断年龄以外毫无信息量,好比找工作的时候告诉别人我是一名应届毕业生——还没说是什么专业的。我猜一下,你应该学过C语言,Java和C++应该是选修课。那你要达到什么样的目标呢?是自己娱乐一下,还是立志要做一个很大的分布式爬虫,是当作提高工作效率的数据搜集工具,还是要以此作为未来的求职方向?你只说「学习」,也没说是要入门还是想精通,让别人怎么回答嘛。
最后,编程是为了解决问题。学习编程的关键其实不在于学习什么语言,而在于解决问题的能力。你现在有一个问题叫做「学习爬虫的最佳路线」,你有没有试着去解决这个问题呢?有太多太多的问题总不能挨个提问吧,你有没有试试搜索呢?

(百度一下)

(好吧你可能觉得百度不靠谱,那就Google一下)

(Google打不开?那好吧,你既然选择相信知乎的水平来知乎提问了,那有没有先搜一下呢)

(好吧知乎的搜索做的确实有点渣,那你有没有先去看一下爬虫话题的精华回答呢?
爬虫(计算机网络) - 话题精华)
我觉得,你只要是自己动手搜索过了,或者看过
如何入门 Python 爬虫? - 爬虫(计算机网络)下面的回答的话,应该就不会来提这个问题了。
我说这么多废话的原因是因为,你要培养自己独立解决问题的能力,而不是培养来知乎提问的能力,何况你的提问本身就不是一个很好的提问(与已有问题重复、描述信息不足)。
下面开始回答问题。
我应该算很水的,学爬虫也就是六月份用了一周时间而已。我的学习经历在
如何入门 Python 爬虫? - 段晓晨的回答里面说过了。这次大概总结一下我对爬虫的理解吧(Python)。
爬虫是一个按照一定规则,自动抓取互联网信息的脚本程序。
所以爬虫的工作过程就是访问网站-返回网站内容-从内容中获取我们需要的信息。
单纯的访问过程是很简单的,Python提供了内置的urllib库,你也可以使用requests库来实现网络请求。在最简单最理想的情况下,你已经得到网页的源代码了。
但是访问并不总是成功的。因为大家都在反爬虫。
理论上讲,我们能通过人工点击浏览器访问到的信息,都可以让爬虫来进行模拟。但是网站并不喜欢爬虫啊,因为你的频繁访问会占用很多网络资源。在其他的一些情况下,写脚本可能是为了批量注册账号、自动回复刷金币刷分。
所以网站会有很多措施来限制爬虫的访问,验证网线另一端的是不是人在操作。大多数情况下我们自然也会有相应的解决办法。
比如验证你的身份——添加headers,伪造Agent。
比如限制你的访问频率——添加程序运行间隔,爬取访问以后休息一下,频率不要太高。
比如封锁你的IP地址——添加代理IP,构造代理池。
比如验证码——特别简单的验证码可以程序识别,复杂的验证码可以人工打码,更复杂的…似乎没什么太好的办法。(验证码的确是防机器的好办法,但是要和用户体验作平衡,比如被人吐槽的12306新验证码)
所以你会发现,你要学的就是怎么反反爬虫(有点绕口),我觉得
高手们你们是怎么防爬虫的?有没有开源项目专做防爬虫? - pig pig 的回答这个回答就很好。
好的,假如你现在已经成功地反反爬虫,拿到了网页源码,可是这些源码是交给浏览器解释的,并不是让人直接阅读的,里面有太多你看不懂的东西(你有HTML基础吗…),那你要如何提取出你需要的信息呢?
答案是使用正则表达式进行匹配。这个是肯定得学得会用的。(就算你HTML没什么基础学的不怎么样也能够得到你想要的内容了)
有没有比正则更好的做法呢?有。BeautifulSoup。
但是前提是你掌握了HTML和CSS的语法基础。
到此我们就实现了访问网站-返回内容-获取所需内容的过程。这也是最简单的爬虫了。
还会遇到什么问题,或者更复杂的情况呢?
编码问题。(Windows/Linux;网页使用了什么编码;编程使用了什么编码;Python3的编码和Python2的编码有哪些不一样)
需要登陆才能访问到的内容,模拟登陆,维持会话。(requests.session和cookielib)
js渲染才能得到的信息、ajax异步自己构造请求地址(需要会通过网络抓包从服务器与浏览器的通信中找到正确的请求地址和传递数据的方式)
大概的内容也就是这样了,说的很草,因为自己也不专业。你可以详细地去看一下
如何入门 Python 爬虫? - 爬虫(计算机网络)中的回答。
总结一下就是。
需要一点Python的基础
需要了解HTML+CSS,会用Firebug分析网页
需要了解一点网络通信,会抓包分析网络请求
学习使用urllib库访问网站(推荐学习使用requests库)
学习写正则表达式
学习使用beautifulsoup库
(再往大往远说的话,可以去看一些设计性的、理念性的东西,或者去看一些大的项目是如何实现的,搜索引擎原理什么的,看你兴趣了)
如果说还有什么建议的话,我推荐的做法是给自己构造一个情境、一个需求,然后带着目的去做,去学。
比如你现在发现
爬虫(计算机网络) - 话题精华里的回答对你很有帮助,你如何写一个脚本来把所有的回答自动保存到本地呢?
(可以参考我的经历
第一次在知乎获得 1000 以上的赞是什么体验? - 段晓晨的回答和这里的代码
知乎将如何应对「狗日的知乎」计划? - 段晓晨的回答)
去试一试吧。期待你在一周内成功!
夹一点私货:
小段同学的杂记 - 知乎专栏知乎评论区“查看对话”初探 - 小段同学的杂记 - 知乎专栏
Python 爬虫笔记(1):综述 - 小段同学的杂记 - 知乎专栏
Python 爬虫笔记(2):插播——我也来做Facemash! - 小段同学的杂记 - 知乎专栏


我自学 Python 爬虫,到这个月出书《Python 网络爬虫:从入门到实践》(机械工业出版社出版),一共也就过去两年。这两年自学的过程,走过了无数的坑,多亏了各位大神无私地回答我的问题,我想我是有资格帮你解决零基础学爬虫技术的。
作为零基础的你,我想你可能是想解决工作中的一个实际问题,或者仅仅是很想学习一下爬虫的技术,多一技之长。其实我准备开始学 Python 爬虫的时候也是一样,老板派了任务,暂时没有人会爬虫,我只有自学顶硬上。因此,我可以用思维图给你理清楚,你应该干什么。
我零基础但我想学网络爬虫:
路径1:我不想写代码,那上面的回答已经列举了很多,Excel/八爪鱼,用这些工具的好处是你可以很快上手,但是只能爬一些简单的网站,一旦网站出现限制,这些方法就是个玩具。因此,想弄点数据玩玩,玩这些玩具就好。
路径2:我可以学写代码,但是会不会很难啊?我以我的经验告诉你,找一个好的老师比自我胡思乱想,自我设限好得多。写代码这个事不难学,这也是为什么市面上有那么多代码速成的教学。这也是为什么我有些同学1年转专业进 Google 的事情发生。
这里给你描画一下你的学习之路:
- 学会 Python 的基本代码: 假如你没有任何编程基础,时间可能花1-2周,每天3小时。假设你有编程基础(VBA 也算吧),1小时。
- 理解爬虫原理:5分钟。为什么这么重要?我自认为学一个东西就像建大楼,先弄清楚大框架,然后再从地基学起。很多时候我们的学习是,还没弄懂大框架,就直接看网上的碎片化的教学,或者是跟着网上教学一章一章学,很容易学了芝麻丢了西瓜。我的自学就在这上面走了很多弯路。请参见: 【爬虫二】爬虫的框架和基本议题
- 应用爬虫原理做一个简单爬虫:30分钟。请参见: 5分钟入门网络爬虫 - 原来可以这么简单易懂
- 先吃透获取网页:就是给一个网址发个请求,那么该网址会返回整个网页的数据。类似:你在浏览器键入网址,回车,然后你就看到了网站的整个页面。
- 再吃透解析网页:就是从整个网页的数据中提取你想要的数据。类似:你在浏览器中看到网站的整个页面,但是你想找到产品的价格,价格就是你想要的数据。
- 再学会储存数据:存储很简单,就是把数据存下来。
学会这些之后,你可以出去和别人说,我会 Python 爬虫,我想也没有人质疑你了。那么学完这一套下来,你的时间成本是多少呢?如果你有编程基础的话,1周吧。
所以,你是想当爬虫做个玩具玩玩,还是掌握一门实战利器。我觉得你可以自己衡量一下。
其实我已经把我这几年的心得,遇到的坑都浓缩在这本书里,希望大家的学习之路上少走点坑。
想系统学习 Python,对上面六步感兴趣的可以读: 如何有系统地学习Python爬虫?
贴个链接,希望大家支持:
京东: 《Python网络爬虫从入门到实践》(唐松,陈智铨)【摘要 书评 试读】- 京东图书
当当: 《Python网络爬虫从入门到实践》(唐松 陈智铨)【简介_书评_在线阅读】 - 当当图书

网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
设计并完成一个python爬虫的流程为
1. 选择目标网站并设定爬取目标:在编写爬虫之前要确定爬取网站的页面是哪些,爬取是否需要登录等情况,并确定爬取目标,一般爬取的目标有文本(如名称,数字等文本信息),图片和文件三种。
2. 编写爬虫,爬取页面信息:选择目标网站后就可以编写爬虫代码,并获取要爬取页面的信息了。python中获取页面信息的代码很简单,如下所示:
html = requests.get(url).text
其中url是要爬取的页面地址,html就是页面信息,通常用BeautifulSoup包进行页面信息解析。
soup = BeautifulSoup(html)
3. 分析页面元素,获取要爬取得数据:获取页面以后就需要根据需求从页面选取数据,一般使用css selector或者xpath选取页面信息。建议学习并使用xpath,xpath学习可以参考w3c xpath。使用xpath获得几种常见的数据方法如下:
获取超链接地址
href=soup.xpath('//a/@href')
获取文本信息
text=soup.xpath('//li/a/text()')
获取图片地址
imgSrc=soup.xpath('//a/img/@src')
4. 数据清洗:在将数据存入到数据库或文本中时需要将数据进行格式化或者整理,如去除所有的符号字符或按照设计要求组织数据格式。
5. 数据存储:选择存储策略,可以存储在数据库中,也可以写入csv等文本形式。
Python还有一个非常实用的爬虫框架Scrapy,可以去了解下;
Java爬虫框架:
1. Nutch
Nutch属于分布式爬虫,爬虫使用分布式,主要是解决两个问题:1)海量URL管理;2)网速。如果要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎,否则尽量不要选择Nutch作为爬虫。用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。
2. Heritrix
Heritrix 是个“Archival Crawler”——来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改。重新爬行对相同的URL不针对先前的进行替换。爬虫主要通过Web用户界面启动、监控和调整,允许弹性的定义要获取的url。
3. crawler4j
crawler4j是Java实现的开源网络爬虫。提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫。
4. WebCollector
WebCollector使用了Nutch的爬取逻辑(分层广度遍历),Crawler4j的的用户接口(覆盖visit方法,定义用户操作),以及一套自己的插件机制,设计了一套爬虫内核。
5. WebMagic
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。
6. HttpClient&Jsoup
爬虫实现的技术有很多,对于java语言来说,有以上很多的选择,可以是很多开源的爬虫框架,也可以使用基本httpClient,Jsoup来爬取网页。
httpClient负责模拟浏览器发送请求,Jsoup负责解析httpClient请求返回的HTML页面,解析获取需要的数据。
用谷歌浏览器开发者工具(F12)分析网页的结构。

直接来一张爬虫的最佳学习路线:
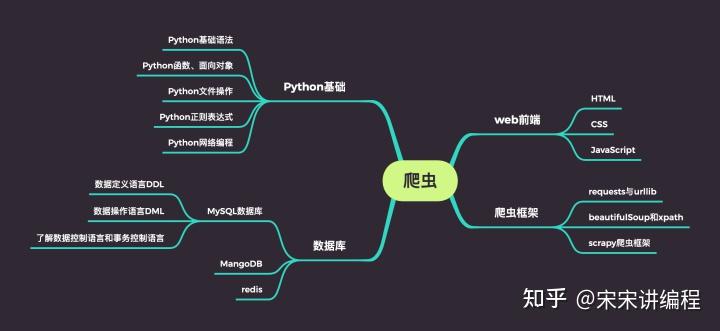

从图上可以看出,想学Python爬虫,建议先学习Python语言基础,掌握后再学习爬虫知识。
学习Python爬虫是要求你具备以下的几点基础知识:
1.Python基础,尤其基础中的正则表达式
2.web前端的基础,即有html+css+js
3.了解web服务的一些原理
4.熟悉数据库比如MySQL,redis等
5.学会使用集成开发工具比如Pycharm
只有以上的知识都打牢了,才能比较顺利地学习爬虫。如果上面的这些知识还不具备,就先一步步的来先掌握了这些知识再来学Python爬虫。
这份Python基础教程是在知乎发现的,是宋宋强推的一套零基础教程!
非常适合新手学习,从最基础的Python发展开始讲起,每个视频都是分开的一小节,知识点密集,能跟着直接上手操作,全133集:
本套视频旨在帮助大家快速上手 Python 语言,覆盖到的内容包括:Python 语言核心、常用数据类型、函数、面向对象编程、网络接口调用、办公自动化等内容,非常适合初学者和想深入了解 Python 语言的小伙伴。
经过Python基础内容的学习,就可以开始学习爬虫了~~~此时此刻,你准备好了吗?我们要开始爬虫的学习之路喽!
这些优质的Python爬虫学习路线、视频教程、练习案例,都是干货,可以收藏着去学习:
Python爬虫视频教程(快速上手,都是干货)
主要介绍爬虫入门相关知识,包含什么是爬虫、网页获取、正则网页解析、xpath网页解析等相关知识点。是对入门学习者量身定制的。 学完掌握,初学者学习完这部分内容,可以掌握初级爬虫知识体系。完成简单爬虫任务。对爬虫有比较全面认识,为以后继续深入学习爬虫,打下良好基础。
scrapy爬虫框架超强教学_入门+实战+项目_小白速成必备
在所有的爬虫框架中,Scrapy应该是最流行、最强大的框架。Scrapy是基于Python的一个非常流行的网络爬虫框架,可以用来抓取Web站点并从页面中提取结构化的数据。本套视频讲的是Python爬虫以及Scrapy爬虫框架等相关知识,教学视频通俗易懂,非常适合零基础的小伙伴。
Python爬虫实战教程:批量爬取某直播网站美女小姐姐图片
课程内容: 1. HTML基础, CSS基础 2. Python基础 3. 爬虫基础 4. 批量抓取美女照片
Python爬虫项目
如果需要案例可以参看我的这篇文章:
一文教你,利用Python爬虫获取招聘网站岗位数据!
干货分享!用Python爬取虎牙颜值区美女主播照片
一篇文章教会你利用Python爬虫获取变美攻略,建议收藏
如何利用Python爬虫,高效获取大规模数据?
用Python对美女内容采集,附完整代码!
用5行Python代码轻松爬取3000+ 上市公司的信息详解
一个Python爬虫案例,带你掌握xpath数据解析方法!
Python抓取B站(刘畊宏本草纲目)弹幕制作词云
用Python抓取腾视频所有电影的爬虫,不用钱就可以看会员电影!
推荐上百个github上Python爬虫案例
Python爬虫工具
推荐阅读:20天学会Python爬虫系列文章
- 第1天:初识爬虫
- 第2天:HTTP协议和Chrome浏览器开发者工具的使用
- 第3天:urllib模块的基本使用
- 第4天:一文带你轻松掌握requests模块
- 第5天:正则表达式真的很6,可惜你不会写
- 第6天:搞定MySQL数据库,看这一篇就够了!
- 第7天:菜鸟用Python操作MongoDB,看这一篇就够了
- 第8天:redis在爬虫中的应用
- 第9天:HTML结构分析
- 第10天:Python爬虫数据提取之bs4的使用方法
- 第11天:Python爬虫必杀技:XPath
- 第12天:Python爬虫入门:验证码处理
- 第13天:Python爬虫入门:selenium+极验滑块破解
- 第14天:JS逆向:滑块验证码加密分析
- 第15天:Scrapy框架介绍,看这一篇就够了!
- 第16天:详解Scrapy爬虫框架的基本使用
- 第17天:Scrapy框架—Spider类介绍
- 第18天: Scrapy框架通用爬虫CrawlSpider
- 第19天:Python爬虫入门:Scrapy框架中间件
- 第20天:Scrapy管道piplines
- 如何利用Python爬虫,高效获取大规模数据?
- 一篇文章教会你利用Python爬虫获取变美攻略,建议收藏
- 五分钟带你学会Python网络爬虫,超详细附教程!

大概总结一下我对网络爬虫的理解吧,主要是说python的网络爬虫。
Python爬虫要说简单它确实也简单,因为它不需要你完全学会Python之后才能上手去学爬虫,说难它确实也需要一下以下几个知识点来支撑:
Python的基础知识
部分网页知识
会用抓包分析工具
能学会用库访问网站
学习Beautifulsoup库
数据存储
反爬
在讲知识点之前先了解一下爬虫
什么是网络爬虫?
爬虫是一种按照一定规则自动抓取网页信息的程序或者脚本,好比我们通过浏览器搜索网页获得我们所需要的有效信息一样,输入链接地址——搜索网页——下载信息——保存在文件夹中。
而爬虫的工作方式则是:模拟浏览器发送请求——下载网页代码——提取所需有效信息——存放数据库。
区别在于爬虫抓取到的信息是已经筛选过的有效信息,不会像我们保存网页一样,整个网页上的信息都被保存下来了。
爬虫应用实例
信息化的告诉发展,能够利用爬虫抓取数据的工作越来越多,利用效率也越来越高,比如
市场分析:股票市场数据可视化分析、产品信息调查、市场调研等
电商分析:电商平台抓取产品销量、评论、用户产品使用场景、促销活动等数据
市场监控:对竞争对手的监控,通过对竞争对手的情况调整自身的经营策略、舆情监控等
商机发现:招标组利用数据抓取自动话汇合各招标网站更新的业务投标信息,及时跟进,更快的获取商机、挖掘潜在客户等
现在就来说说怎么学习Python爬虫吧
Python基础学习
在入门Python爬虫之前先学好Python的基础知识,这就跟你要学会打字,就得先把拼音练好一个道理,所以就不要再问要不要学Python了,肯定要!
Python爬虫需要掌握的常用知识点有
Python语法基础:表达式、条件判断、循环语句………
Python数据结构:列表、队列、字符串、正则表达式………
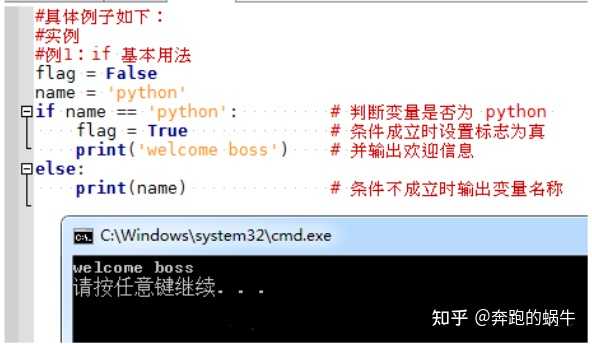

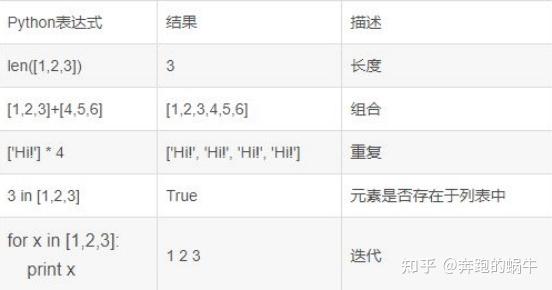

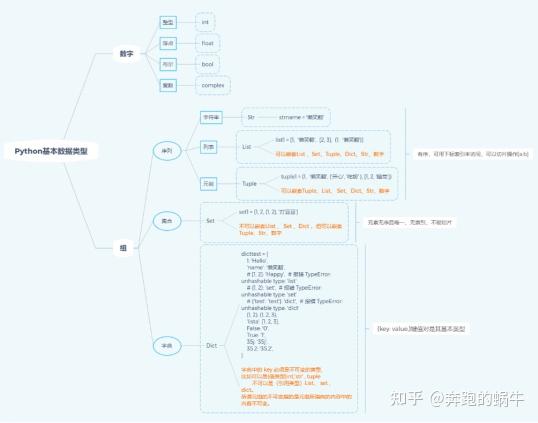

Python基础知识点的学习是掌握爬虫入门的第一步,Python简单易用的语言能使爬虫学习更快速上手,筛选和甄别学习哪些知识,在哪里去获取资源是许多初学者共同面临的问题。
如果你不知到从哪里搜集学习资料又没有人请教的话,推荐加入一个Python交流群,里面都是Python从业者大佬,在这块有任何不懂的,都可以在群里咨询,大佬们都会帮你解决。

网页知识要懂点
基础的HTML、CSS还是要能知道一点的额,毕竟爬虫主要靠数据抓取,解析网页,数据都在网页里放着,基本的网页内容都看不懂又如何去爬虫呢,开头就垮掉了。


什么是HTML?
HTML是用来描述网页的一种语言
HTML指的是超文本标记语言(hyper text markup language)
HTML不是一种编程语言,而是一种标记语言(markup language)
标记语言是一套标记标签(markup tag)
HTML使用标记标签来描述网页
了解完相关的Python和网页基础知识之后,就是顺着接下来的爬虫学习路径,一路升级打怪喽,这里为大家整理了一些爬虫学习路径的学习资料,有需要的可以下方自提⬇⬇⬇
会用Firebug分析网页
Firebug提供了非常实用的 检查元素功能,该功能允许将鼠标悬浮在不同的页面元素上, 显示相应元素的HTML代码。否则在如此多代码的HTML的body中手动搜索标签是十分痛苦的。
Firebug也是个除错工具,用户可以利用它除错、编辑、甚至删改任何网站的 CSS、HTML、DOM 以及JavaScript 代码。
主要的功能有
CSS调试:可以在这个查看器中直接添加、修改、删除一些CSS样式表属性,并在当前页面中直接看到修改后的结果
CSS尺标:利用Firebug来查看页面中某一区块的CSS样式表,如果进一步展开右侧Layout tab的话,它会以标尺的形式将当前区块占用的面积清楚地标识出来,精确到象素。
JS调试器:一个很不错的javascript脚本调试器。
修改HTML:它清楚地列出了一个html元素的parent、child以及root元素,可以在HTML查看器中直接修改HTML源代码。
会用抓包分析工具分析网络请求
抓包是指抓取我们本地电脑与远端服务器通信时候所传递的数据包
爬虫不可缺少的就是用抓包分析,有些网页的数据是动态加载的,只在请求网页时才加载数据,在源代码中是不显示的,所以需要会用抓包分析网络请求,只有在抓包分析后,才能构建先关提交数据
我那会儿学的是Fiddler,是Windows平台比较好用的可视化抓包工具,也是比较熟知的 HTTP 代理工具,功能非常强大,除了可以清晰的了解每个请求与响应之外,还可以进行断点设置,修改请求数据、拦截响应内容。
如果你想要自定义规则,通过修改脚本,加入自己的特殊处理,复杂一点的脚本需要懂不过懂C#。
过滤器功能使得你可以通过正则表达式规则将你关心的请求显示出来,如果你只需要抓特定网站的数据,这个功能就显得非常有用,可以去除很多干扰信息。
能学会用库访问网站
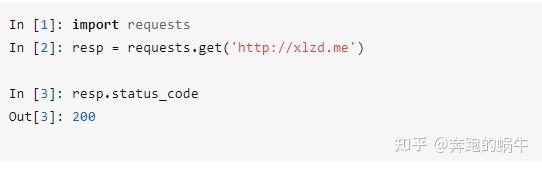
比较推荐学requests,功能强大的爬取网页信息的第三方库,可以进行自动爬取HTML页面及自动网络请求提交的操作


requests的简单使用,发送完整的一个HTTP强求,只需要一句代码就可以搞定,比较简洁

解析提取数据:Beautiful Soup库


它是一个工具箱,通过解析文档为用户提供需要抓取的数据,借助网页的结构和属性等特性来解析网页的工具,能自动转换编码。支持Python标准库中的HTML解析器,还支持一些第三方的解析器
如何存储数据
爬取下来的数据需要进行存储,小规模数据可以使用txt文件、json文件、csv文件,大规模数据就需要了解一些常用的数据库的使用像mysql,mongodb、redis等,就比较方便查询管理了。
你看,通过这条学习路径走下来,爬虫是不是没有那么困难了呢?以上的知识点框架。图表资料还有Python爬虫相关的资料都打包好放在下方了,有需要的找群管理要
应对反爬
有爬虫就会有反爬措施,比如验证码、加密数据、动态数据加载、字体反爬等,学会一些常用的反爬技巧,像
控制ip访问频率
字体反加密
禁止cookie
验证码OCR处理
用户代理池技术
……………
在高效开发和反爬虫之间网站通常会偏向前者,这也为爬虫提供了空间,掌握一些常用的反爬技巧,爬取绝大部分的网站已经没有很大问题啦!
学完以上的知识点,Python爬虫就基本没有问题了,如果想要爬虫技术水平更上一层楼,那上面的知识点就已经不够用了哦~还需要学习scrapy,分布式爬虫等一些高级知识点了,这些会让你的爬虫效率大大提升。
学会Python爬虫不是一件很难的事情,只要每一个部分的知识点并且有针对性的去学习,走完这一条顺畅的学习之路,你就能掌握python爬虫。

当初也是自己摸索学习的爬虫,后来就把自己学习爬虫的过程和心得整理成下面的爬虫文章。跟着爬虫文章学,基本上能学的差不多。


学习技术最好的方法是阅读源代码并动手写代码:阅读成熟项目源代码和文档,跟随项目的示例程序和测试用例执行、修改、添加,最后尝试修改成熟项目的核心代码。
教材能够起到的作用非常有限,尤其不建议购买纸质教材,个人不建议看视频教程。
如果要学习爬虫,首先可以了解一下爬虫的应用场景、核心难题和解决方案。这里我们整理了一份爬虫的应用场景、核心难题和解决方案,爬虫的常见问题和开发建议,希望能够有帮助:
网络爬虫在各种语言中都有实现,譬如 Java, Kotlin, Javascript, Python, Go, C++ 等。随着网站变得越来越复杂,页面变动越来越频繁,越来越多的网站由 Vue,React 等技术动态生成,建议网络爬虫直接从浏览器自动化工具开始。
浏览器自动化工具提供了编程驱动真实浏览器的能力,使得程序可以像真人一样访问网页,采集数据,譬如 Selenium,Playwright,Puppeteer,Crawlee,PulsarR 等。
浏览器自动化工具本身由某一种语言编写,但往往对使用者提供了多种语言绑定。譬如,Selenium 由 Java 编写,但是提供了 Java, Python, C#, Ruby, JavaScript, Perl, PHP, R, Objective-C, Haskell 这些语言的编程接口;Playwright 由 Javascript 写成,但是提供了 JavaScript, Java, Python, C# 的编程接口。
尤其不建议再用 Requests, Scrapy 等原始工具了,不要陷入花里胡哨、无穷无尽的爬虫对抗中,这种对抗很多时候是一条死胡同,譬如采用动态自定义字体技术,已经可以彻底阻断 HTTP 抓包方式的采集了。
很多人认为 Requests, Scrapy 等原始工具的具有效率优势,这并不正确:
- 数据点缺失。现代网页数据会由多次 异步请求返回组合,原始工具获得的数据点比浏览器少很多
- 效率假象。对浏览器进行优化和合理配置,譬如屏蔽无关资源,效率可以和原始 HTTP 媲美。Google 周期性采集 40 亿网页,都是通过浏览器渲染采集的
- 成本考虑。原始工具往往需要不成体系的额外知识,并增加人力成本,与之相比,硬件很便宜
- 爬虫对抗。目标站点的基础反爬机制迫使采集方主动降速
- 风险规避。对单一资源进行超出常规的访问会被视作 DDOS 攻击,从而带来法律风险
- 其他效率相关弊病
如果您的焦点是解决当前问题,暂不考虑后续业务发展,那么 Crawlee/PulsarR 都是很好的选择,它们是开箱即用的,解决了阻挡在你和网页数据之间的绝大多数拦路虎。此时不建议选用 Selenium,Playwright,Puppeteer 等,如果使用它们,还有一大批技术问题需要解决。
如果您的业务要求解决以下问题:
- 连续采集
- 大规模分布式
- 任务调度
- 性能保证
- 数据质量保证
- 系统架构设计
- API 设计
- 机器人流程自动化(RPA)
- 高级数据采集语言
- 高级信息提取算法
- 增强分析
- 机器学习
- 弹性计算
- 云化服务
- 存储处理
- 运维工具
- 降低数据获取成本
- 降低团队技能要求
- 提高数据规模
- 解决数据融合问题
- 提升时效价值
- 提高系统可维护性
或者如果您是专业人士,需要解决最具挑战的网络数据采集问题,譬如:
- 每日采集百万量级电商页面,或者数亿量级数据点,以满足市场调查和竞品分析的需要
- 采集数千个网站并降低规则失效率
- 采集整个互联网并建立搜索引擎、信息流产品或者知识图谱
- 开发一款供非技术人员用的“数据采集器”
- 架设自己的数据采集公有云
那么,PulsarR 是你唯一的选择。
PulsarR 为解决网络数据管理、多源异构数据融合、数据采集等问题,开发了一系列基础设施和前沿技术。类似 Playwright 这样的浏览器驱动,在 PulsarR 中仅仅只是一个不大的子系统,可见单单 Playwright 能够解决的问题极其有限。为了性能、稳定性、容错性等考虑,我们也不会使用 Playwright 作为浏览器驱动,而是基于 CDP 从头开发。
传统数据采集方案有哪些问题?
网络数据管理的核心难题是持续降低总体拥有成本。网络爬虫的难点在于数据规模、数据质量、综合性能、人力维护成本、硬件支出等,这些难题构成了总体拥有成本的难题。
具体来看:
- 数据能采集到(难)
- 数据质量和调度质量保证(难难)
- 运行性能和机器成本(难难难)
- 业务和数据分析(难)
- 大批量站点的信息抽取(难难难)
- 构建知识图谱(难难难难)
目前大家常用的主流的数据采集软件,包括 selenium, playwright, puppeteer 等,不是为数据采集开发的,不适合数据采集;而大家熟知的 scrapy, requests 等,已经越来越不适应现代网页了。
一、现在主流网站常用的反爬手段基本都用了,譬如Cookie跟踪,IP跟踪,访问频率限制,访问轨迹跟踪,CSS 混淆等等。
二、使用基本的 HTTP 协议采集,如 requests, scrapy, jsoup, nutch 等,会陷入无穷无尽的爬虫/反爬虫对抗中,得不偿失,并且未必能解决,譬如说采用了动态自定义字体的站点就不可能解决。
三、使用浏览器自动化工具如 selenium, playwright, puppeteer 等进行数据采集,会被检测出来并直接屏蔽。
四、使用 puppeteer-extra, apify/crawlee 这样的工具,虽然提供了 WebDriver 隐身特性,一定程度上缓解了这个问题,但仍然没有完全解决。
- 上述工具没有解决访问轨迹跟踪问题
- Headless 模式能够被检测出来。云端爬虫通常以 headless 模式运行,即使做了 WebDriver 隐身, headless 模式也能够被检测出来
- 其他爬虫对抗问题
即使解决完上述问题,也仅仅是入门而已。在稍稍正式一点的采集场景下,仍然面临诸多困难:
- 如何正确轮换IP,触发条件是什么?事实上,仅轮换IP是不够的,需要“隐私上下文轮换”
- 如何使用单台机器每天提取数千万数据点?
- 如何保证数据准确性?
- 如何保证调度准确性?
- 如何保证分布式系统弹性?
- 如何正确提取 CSS 混淆 的字段,它的 CSSPath/XPath/Regex 每个网页都不同,怎么解决?
- 如何采集数百个电商站点并避免爬虫失效?
- 如何降低总体拥有成本?
解决方案
PulsarR( 国内镜像)为解决网络数据管理、多源异构数据融合、网络数据挖掘、网络数据采集等问题,开发了一系列基础设施和前沿技术。类似 Playwright 这样的浏览器驱动,在 PulsarR 中仅仅只是一个不大的子系统,可见单单 Playwright 能够解决的问题极其有限。为了性能、稳定性、容错性等考虑,我们也不会使用 Playwright 作为浏览器驱动,而是基于 CDP 从头开发。
PulsarR 提供了大量顶级站点的采集示例,从入门到资深,包含各种采集模式,包括顶尖大站的全站采集代码、反爬天花板的站点的采集示例,您可以基于代码示例开始利益攸关的大数据项目:
- Exotic Amazon, 国内镜像 - 全球 TOP 1 电商网站全站数据采集真实项目
- Exotic Walmart, 国内镜像 - 顶尖电商网站数据采集示例
- Exotic Dianping, 国内镜像 - 最困难的数据采集示例
PulsarR 支持高质量的大规模数据采集和处理。PulsarR 开发了一系列基础设施和前沿技术,来保证即使是大规模数据采集场景,也能达到最高标准的性能、质量和总体拥有成本。
PulsarR 支持网络即数据库范式。PulsarR 像对待内部数据库一样对待外部网络,如果需要的数据不在本地存储中,或者现存版本不满足分析需要,则系统会从互联网上采集该数据的最新版本。我们还开发了 X-SQL 来直接查询互联网,并将网页转换成表格和图表。
PulsarR 支持浏览器渲染并将其作为数据采集的首要方法。将浏览器渲染作为数据采集的首要方法,我们在数据点规模、数据质量、人力成本和硬件成本之间实现了最佳平衡,并实现了最低的总体拥有成本。通过优化,如屏蔽不相关的资源文件,浏览器渲染的性能甚至可以与传统的单一资源采集方法相媲美。
PulsarR 支持 RPA 采集。PulsarR 包含一个 RPA 子系统,来实现网页交互:滚动、打字、屏幕捕获、鼠标拖放、点击等。该子系统和大家所熟知的 selenium, playwright, puppeteer 是类似的,但对所有行为进行了优化,譬如更真实的模拟操作,更好的执行性能,更好的并行性,更好的容错处理,等等。
PulsarR 支持退化的单一资源采集。PulsarR 的默认采集方式是通过浏览器渲染来采集完整的网页数据,如果您需要的数据可以通过单一接口获取,譬如可以通过某个 ajax 接口返回,也可以调用 PulsarR 的资源采集方法进行高速采集。
PulsarR 计划支持最前沿的信息提取技术。我们计划发布一个先进的人工智能,以显著的精度自动提取所有网页(譬如商品详情页)中的每一个字段,目前我们提供了一个 预览版本, 国内镜像。
代码示例
大多数抓取尝试可以从几乎一行代码开始:
fun main() = PulsarContexts.createSession().scrapeOutPages(
"https://www.amazon.com/", "-outLink a[href~=/dp/]", listOf("#title", "#acrCustomerReviewText"))上面的代码从一组产品页面中抓取由 css 选择器 #title 和 #acrCustomerReviewText 指定的字段。 示例代码可以在这里找到: kotlin, java,国内镜像: kotlin, java。
大多数 生产环境 数据采集项目可以从以下代码片段开始:
fun main() {
val context = PulsarContexts.create()
val parseHandler = { _: WebPage, document: Document ->
// use the document
// ...
// and then extract further hyperlinks
context.submitAll(document.selectHyperlinks("a[href~=/dp/]"))
}
val urls = LinkExtractors.fromResource("seeds10.txt")
.map { ParsableHyperlink("$it -refresh", parseHandler) }
context.submitAll(urls).await()
}示例代码可以在这里找到: kotlin, java,国内镜像: kotlin, java。
最复杂的数据采集项目可以使用 RPA 模式:
最复杂的数据采集项目往往需要和网页进行复杂交互,为此我们提供了简洁强大的 API。以下是一个典型的 RPA 代码片段,它是从顶级电子商务网站收集数据所必需的:
val options = session.options(args)
val event = options.event.browseEvent
event.onBrowserLaunched.addLast { page, driver ->
// warp up the browser to avoid being blocked by the website,
// or choose the global settings, such as your location.
warnUpBrowser(page, driver)
}
event.onWillFetch.addLast { page, driver ->
// have to visit a referrer page before we can visit the desired page
waitForReferrer(page, driver)
// websites may prevent us from opening too many pages at a time, so we should open links one by one.
waitForPreviousPage(page, driver)
}
event.onWillCheckDocumentState.addLast { page, driver ->
// wait for a special fields to appear on the page
driver.waitForSelector("body h1[itemprop=name]")
// close the mask layer, it might be promotions, ads, or something else.
driver.click(".mask-layer-close-button")
}
// visit the URL and trigger events
session.load(url, options)示例代码可以在这里找到: kotlin, 国内镜像。
如需了解更多,可以看 项目主页, 国内镜像 或者 知乎介绍 或者 在线教程。
希望这个回答有所帮助。

最新学习路线图,你可以参考一下!
很全面



爬虫课程推荐:(从零基础到精通精品课程)更有课件自来哦可以领取哦~
课件资料领取,私信我领取呀!
学习路线
抓取HTML页面:
- HTTP请求的处理: urllib, urlib2, requests
- 处理器的请求可以模拟浏览器发送请求,获取服务器响应的文件
解析服务器相应的内容:
- re, xpath, BeautifulSoup(bs4), jsonpath, pyquery等
- 使用某种描述性语言来给我们需要提取的数据定义一个匹配规则,符合这个规则的数据就会被匹配
采集动态HTML,验证码的处理
- 通用动态页面采集: Selenium + PhantomJS:模拟真实浏览器加载JS
- 验证码处理: Tesseract机器学习库,机器图像识别系统
Scrapy框架:
- 高定制性,高性能(异步网络框架twisted)->数据下载快
- 提供了数据存储,数据下载,提取规则等组件
分布式策略:
scrapy redis:在scarpy基础上添加了以redis数据库为核心的一套组件,主要在redis做请求指纹去重、请求分配、数据临时存储
爬虫、反爬虫、反反爬虫之间的斗争:
User-Agent, 代理, 验证码, 动态数据加载, 加密数据


爬虫的分类
通用爬虫:
1.定义: 搜索引擎用的爬虫系统
2.目标: 把所有互联网的网页爬取下来,放到本地服务器形成备份,在对这些网页做相关处理(提取关键字,去除广告),最后提供一个用户可以访问的借口
3.抓取流程:
a) 首先选取一部分已有的URL, 把这些URL放到带爬取队列中
b) 从队列中取出来URL,然后解析NDS得到主机IP,然后去这个IP对应的服务器里下载HTML页面,保存到搜索引擎的本地服务器里,之后把爬过的URL放入已爬取队列
c) 分析网页内容,找出网页里其他的URL连接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取一个新网站的URL:
5.通用爬虫注意事项
通用爬虫并不是万物皆可以爬,它必须遵守规则:
Robots协议:协议会指明通用爬虫可以爬取网页的权限
我们可以访问不同网页的Robots权限
6.通用爬虫通用流程:


7.通用爬虫缺点
只能提供和文本相关的内容(HTML,WORD,PDF)等,不能提供多媒体文件(msic,picture, video)及其他二进制文件
提供结果千篇一律,不能针对不同背景领域的人听不同的搜索结果
不能理解人类语义的检索
聚焦爬虫的优势所在
DNS 域名解析成IP: 通过在命令框中输入ping http://www.baidu.com,得到服务器的IP
聚焦爬虫:
爬虫程序员写的针对某种内容的爬虫-> 面向主题爬虫,面向需要爬虫



轻量级爬虫
“获取数据——解析数据——存储数据”是爬虫的三部曲,大部分爬虫都是按这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。1、获取数据
爬虫第一步操作就是模拟浏览器向服务器发送请求,基于python,你不需要了解从数据的实现,HTTP、TCP、IP的网络传输结构,一直到服务器响应和应达的原理,因为python提供了功能齐全的类库来帮我们完成这些请求。Python自带的标准库urllib2使用的较多,它是python内置的HTTP请求库,如果你只进行基本的爬虫网页抓取,那么urllib2足够用。Requests的slogen是“Requests is the only Non-GMO HTTP library for Python, safe for humanconsumption”,相对urllib2,requests使用起来确实简洁很多,并且自带json解析器。如果你需要爬取异步加载的动态网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化。对于爬虫来说,在能够爬取到数据地前提下当然是越快越好,显然传统地同步代码不能满足我们对速度地需求。
(ps:据国外数据统计:正常情况下我们请求同一个页面 100次的话,最少也得花费 30秒,但使用异步请求同一个页面 100次的话,只需要要 3秒左右。)
aiohttp是你值得拥有的一个库,aiohttp的异步操作借助于async/await关键字的写法变得更加简洁,架构更加清晰。使用异步请求库进行数据抓取时,会大大提高效率。
你可以根据自己的需求选择合适的请求库,但建议先从python自带的urllib开始,当然,你可以在学习时尝试所有的方式,以便更了解这些库的使用。


2、解析数据
爬虫爬取的是爬取页面指定的部分数据值,而不是整个页面的数据,这时往往需要先进行数据的解析再进行存储。
从web上采集回来的数据的数据类型有很多种,主要有HTML、 javascript、JSON、XML等格式。解析库的使用等价于在HTML中查找需要的信息时时使用正则,能够更加快捷地定位到具体的元素获取相应的信息。Css选择器是一种快速定位元素的方法。Pyqurrey使用lxml解析器进行快速在xml和html文档上操作,它提供了和jQuery类似的语法来解析HTML文档,支持CSS选择器,使用非常方便。
Beautiful Soup是借助网页的结构和属性等特性来解析网页的工具,能自动转换编码。支持Python标准库中的HTML解析器,还支持一些第三方的解析器。
Xpath最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。它提供了超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等,并且XQuery和XPointer都构建于XPath基础上。
Re正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。个人认为前端基础比较扎实的,用pyquery是最方便的,beautifulsoup也不错,re速度比较快,但是写正则比较麻烦。当然了,既然用python,肯定还是自己用着方便最好。
3、数据存储当爬回来的数据量较小时,你可以使用文档的形式来储存,支持TXT、json、csv等格式。但当数据量变大,文档的储存方式就行不通了,所以掌握一种数据库是必须的。Mysql 作为关系型数据库的代表,拥有较为成熟的体系,成熟度很高,可以很好地去存储一些数据,但在在海量数据处理的时候效率会显著变慢,已然满足不了某些大数据的处理要求。MongoDB已经流行了很长一段时间,相对于MySQL ,MongoDB可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。因为这里要用到的数据库知识其实非常简单,主要是数据如何入库、如何进行提取,在需要的时候再学习就行。Redis是一个不折不扣的内存数据库,Redis 支持的数据结构丰富,包括hash、set、list等。数据全部存在内存,访问速度快,可以存储大量的数据,一般应用于分布式爬虫的数据存储当中。
如果大家在学习中遇到困难,想找一个python学习交流环境,可以点击下方加入我们一起学习,欢迎零基础和大佬加入,可分享资源
有关Python问题都可以给我留言喔

如果你要自己编程的话,要学习Python,如果你是想要一个软件,gooseeker推荐给你,我们老师推荐的

网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
设计并完成一个python爬虫的流程为
1. 选择目标网站并设定爬取目标:在编写爬虫之前要确定爬取网站的页面是哪些,爬取是否需要登录等情况,并确定爬取目标,一般爬取的目标有文本(如名称,数字等文本信息),图片和文件三种。
2. 编写爬虫,爬取页面信息:选择目标网站后就可以编写爬虫代码,并获取要爬取页面的信息了。
3. 分析页面元素,获取要爬取得数据:获取页面以后就需要根据需求从页面选取数据,一般使用css selector或者xpath选取页面信息。建议学习并使用xpath,xpath学习可以参考w3c xpath。
4. 数据清洗:在将数据存入到数据库或文本中时需要将数据进行格式化或者整理,如去除所有的符号字符或按照设计要求组织数据格式。
5. 数据存储:选择存储策略,可以存储在数据库中,也可以写入csv等文本形式。
Python还有一个非常实用的爬虫框架Scrapy,可以去了解下;
Java爬虫框架:
1. Nutch
Nutch属于分布式爬虫,爬虫使用分布式,主要是解决两个问题:1)海量URL管理;2)网速。如果要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎,否则尽量不要选择Nutch作为爬虫。用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。
2. Heritrix
Heritrix 是个“Archival Crawler”——来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改。重新爬行对相同的URL不针对先前的进行替换。爬虫主要通过Web用户界面启动、监控和调整,允许弹性的定义要获取的url。
3. crawler4j
crawler4j是Java实现的开源网络爬虫。提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫。
4. WebCollector
WebCollector使用了Nutch的爬取逻辑(分层广度遍历),Crawler4j的的用户接口(覆盖visit方法,定义用户操作),以及一套自己的插件机制,设计了一套爬虫内核。
5. WebMagic
WebMagic项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。
6. HttpClient&Jsoup
爬虫实现的技术有很多,对于java语言来说,有以上很多的选择,可以是很多开源的爬虫框架,也可以使用基本httpClient,Jsoup来爬取网页。
httpClient负责模拟浏览器发送请求,Jsoup负责解析httpClient请求返回的HTML页面,解析获取需要的数据。
用谷歌浏览器开发者工具(F12)分析网页的结构。、
适合菜鸟入门的网络爬虫的视频教程:

这个知乎专栏写的都是爬虫类的文章,还有些实例教程,可以看看
数据工厂
Python是什么?这个问题必须给初学者解释一下。首先,Python是一门计算机编程语言,而且是一门简洁的、强大的、面向对象的编程语言,它类似php、java等语言。本文适合Python初学者,如有疑问欢迎在下方留言。无偿Python干货分享 @ 私聊小编领取。
在学习Python之前,一定要做好准备工作,安装Python相关软件就是其中关键的一步。下面介绍Python在Windows系统的安装和运行方法。


一、安装环境
系统:Windows 10
python版本:python 3.7.2
二、安装Python
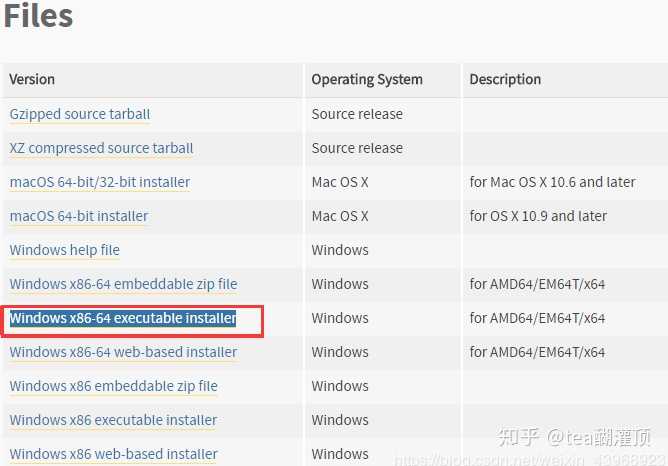
- 首先,在 python.org上下载Python安装包
选择:Windows x86-64 executable installer
下载文件:python-3.7.2-amd64.exe



- 双击下载本地的安装包,选择自定义安装

- 默认配置选项,点击 [Next] 下一步

- 默认或选择安装目标,点击 [Install] 开始安装



- 安装完成,点击 [Close] 关闭即可


三、测试Python
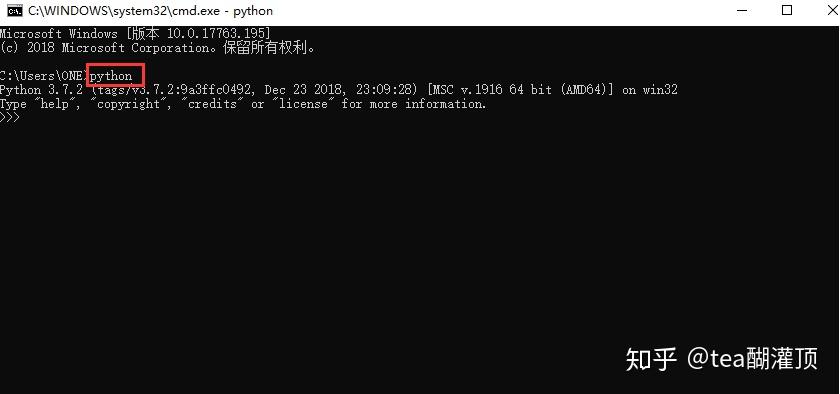
- 安装好 Python 后,组合键 win+r 输入 cmd 打开命令行输入「python」,以下显示为环境变量配置成功。

- 退出python,输入:exit()


- 到这里python基础环境就安装完成啦!
希望这些对想入坑的伙伴们有所帮助,让我们一起共同学习,共同成长。@ 私聊小编,免费领取全套Python教程


