 知乎话题的提问
知乎话题的提问如何定义「机器学习」?「机器学习」跟人工智能的关系是什么样的?
36 个回答

简单概括:
”人工智能“指是机器能以我们认为智能的方法去执行任务这样一个宽泛的概念。而”机器学习“是人工智能的一种应用,指的是机器可以自主地学习数据来达到对应的目标。
下面进行详细说明,这个问题涉及三个概念:
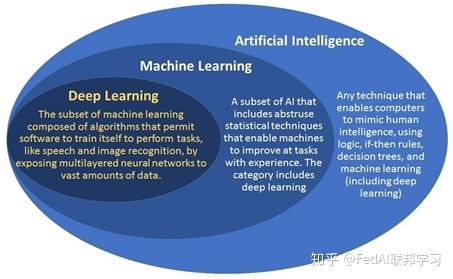
- Artificial Intelligence,就是正常说的人工智能
- Machine Learning,机器学习
- Deep Learning,深度学习
1. 概念Overview:
1.1 Artificial Intelligence:
简称AI。Artificial就意味着由人开发或本来不存在的东西构成。Intelligence意味着它有自主理解和思考的能力。Wikipedia中的将AI更精细地定义为"一个系统能获取外部数据并从这些数据中学习,并能利用学习到的知识来灵活适应特定的目标和任务的能力"。AI不是一个系统,而是构建了一个系统,系统所拥有的能力。
1.2 Machine Learning:
机器学习可以认为是一种数据驱动的决策方法,是人工智能的一种应用,为AI提供了一种自学习的能力。一般在机器学习任务中,我们都会定义具体的目标Goal和评估标准Metrics。机器学习可以不断地学习数据和计算评估标准并迭代来达到Goal。
按与数据的交互方式:
- 监督学习
- 非监督学习
- 半监督学习
按工作原理分:
- regression回归
- 决策树算法
- 贝叶斯算法
- 聚类算法
- 深度学习算法
- 集成学习算法
- 降维、关联规则、正则算法等
按领域分:
- 计算机视觉
- 自然语言处理
- 推荐系统
- 强化学习模型
- 生成模型等
1.3 Deep Learning:
深度学习是一种机器学习方法,隶属于机器学习的范畴,只因为过去几年,深度学习确实证明了自己能力之强大。在图像视觉、自然语言处理、语音、下棋、玩游戏、电商推荐等领域样样在行。所以我们目前主要都关注在深度学习又取得了什么进展上。
大体可以分为:
- 卷积神经网络。
- 图像分类:AlexNet,VGGNet,RexNet等。
- 图像检测:RCNN,YOLO,SSD,FPN,RetinaNet等。
- 图像分割:FCN,LinkNet等。
- 图像跟踪:HCF等。
- 网络轻量化:MobileNet V1等。
- 循环神经网络。典型代表是RNN/LSTM/GRU/ELMO/BERT。
- 深度强化学习。
- Q-Learning:DQN,Double-DQN等。
- Policy Gradient:DDPG等。
- 深度生成模型。典型代表是VAE和GAN。
- 图神经网络。GNN,GCN,DCNN。
- 神经结构搜索。属于AutoML的范畴。
但这并不意味着经典机器学习完全失势。在一些特定情况下使用最简单的LR或Random Forest可能比使用Deep Network更好。 简单拿经典机器学习方法与深度学习做个比较:
2. DL与ML的比较:
2.1 Deep Learning-深度学习的优势:
建模效果好
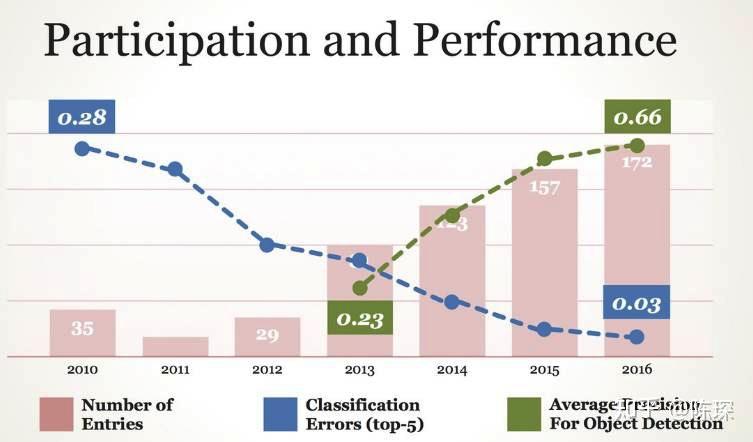
Deep Learning可以在许多领域做到远超经典ML的精度。比如在ImageNet 数据集上,2010与2011是使用经典机器学习方法能达到的效果,后面均使用的深度学习方法。

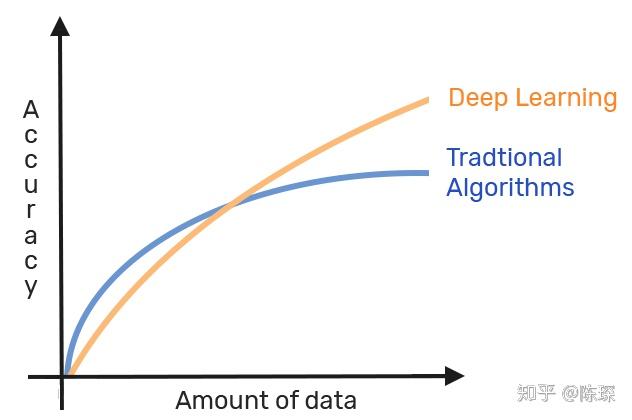
能吃进去更多的数据:
与传统的ML方法相比,DL可以学习更多的数据。通常情况下,只需要给更多的训练数据就能提高模型的准确性。但是如果使用经典的ML方法,就很容易达到准确率的饱和。达到瓶颈后,加入更多的数据往往不能带来更高的模型准确度,一般都需要设计更复杂的模型来进行效果提升。

不需要进行手动特征工程:
经典的ML方法往往需要非常复杂的人工特征工程才能达到较好的效果。首先,需要对数据做EDA。然后对数据进行降维处理来方便后续处理。最后再辅助以各种特征工程技巧来提升准确度。但是在深度学习当中,直接将原始的数据做为输入,网络自动做特征工程和参数训练,最后你会发现效果也不错。在实际的建模工作中,特征工程特别考验技巧和耐心,深度学习可以在一定程度上消除这个有挑战性的步骤。
适应性和迁移性:
深度学习比经典的机器学习模型更容易迁移到不同的领域和实际应用中去。首先,迁移学习使得pretrained的网络在同一个领域内的不同应用上都是有效的。例如,在计算机视觉领域,预训练的网络可以同时应用于目标检测和图像分割的特征提取。使用这些预训练的网络,可以极大地简化模型的训练步骤,并且可以在较短的时间内取得好的建模效果。此外,在不同的领域中深度学习的思想基本都是相通的、可转移的。例如,人们一旦理解了Attetion机制在翻译中的优势,就马上可以把它用在其他领域,因为他们都有着相似的base knowledge。但是对于经典ML模型来说,不同领域和应用的base knowledge是完全不同的,需要对每一个单独的领域做深入的研究。
2.2 Classical ML经典机器学习的优势:
在小数据集上工作的更好:
深度学习需要大量的数据。预训练网络需要几百万个样本。对于很多公司或者项目来说,这么大的数据集并不容易获得。这时候使用经典ML算法通常优于深度学习网络。
计算成本低:
深度学习训练时间很长,快速训练需要大量GPU设备、高端CPU,SSD存储以及很大的RAM。经典的ML仅需要一般的CPU设备就可以训练。相比较来说,经典算法的计算成本就很低。另外,训练和迭代地快也能帮助DS在算时间内对比不同的方法。
易于解释:
由于我们已经对数据做了大量的EDA和特征工程,对数据理解深入,调参和更改算法都更有针对性。对于算法表现出来的特性,也比较好理解与解释。这一点看似普通,但在实际业务中是非常重要的。而深度学习一般被称为“炼丹炉”,现在如何解释深度学习网络也是一个热门话题。不能够理解它,也就导致DL的调参和网络优化也是非常具有挑战性的。


在过去的几年中,术语“人工智能”和“机器学习”已开始在技术新闻和网站中频繁出现。 通常,两者被用作同义词,但是它们之间存在细微但真实的差异。
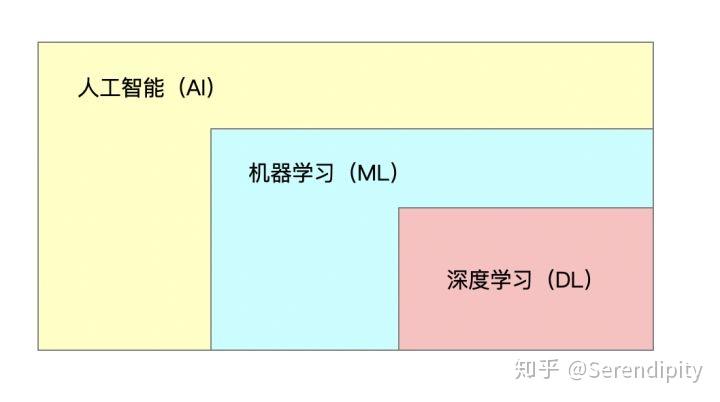
总的来说,有两件事是可以确定的:首先,术语人工智能(AI)比术语机器学习(ML)更古老,其次,大多数人认为机器学习是人工智能的一个子集。

首先,什么是人工智能(AI)?
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
人工智能的定义可以分为两部分,即“人工”和“智能”。
“人工”比较好理解,争议性也不大。有时我们会要考虑什么是人力所能及制造的,或者人自身的智能程度有没有高到可以创造人工智能的地步,等等。但总的来说,“人工系统”就是通常意义下的人工系统。
关于什么是“智能”,就问题多多了。这涉及到其它诸如意识(CONSCIOUSNESS)、自我(SELF)、思维(MIND)(包括无意识的思维(UNCONSCIOUS_MIND))等等问题。人唯一了解的智能是人本身的智能,这是普遍认同的观点。但是我们对我们自身智能的理解都非常有限,对构成人的智能的必要元素也了解有限,所以就很难定义什么是“人工”制造的“智能”了。
因此人工智能的研究往往涉及对人的智能本身的研究。其它关于动物或其它人造系统的智能也普遍被认为是人工智能相关的研究课题。

计算机科学家以许多不同的方式定义了人工智能,但从本质上讲,人工智能涉及以人类思维方式思考的机器。 当然,要确定机器是否在“思考”是非常困难的,因此在实践上,创建人工智能需要创建一个计算机系统,该计算机系统擅长做人类擅长的事情。
创造和人类一样聪明的机器的想法可以追溯到古希腊,他们对神创造的机器有很多神话。但实际上,这个想法直到1950年才真正开始流行起来。
在那一年,艾伦·图灵(Alan Turing)发表了一篇开创性的论文,名为“Computing Machinery and Intelligence”,提出了机器是否可以思考的问题。 他提出了著名的图灵测试,该测试从本质上说,如果人类法官无法判断他是在与人还是与机器交互,则可以说计算机是智能的。
人工智能是1956年由约翰·麦卡锡(John McCarthy)提出的,他在达特茅斯(Dartmouth)组织了一次有关该主题的学术会议。 在会议结束时,与会者建议进一步研究“这样的猜想,即理论上可以精确地描述学习的各个方面或智力的任何其他特征,以便可以制造出机器来对其进行仿真。 找到如何使机器使用语言,形成抽象和概念,解决现在人类所面临的各种问题并改善自身的方法。”
该提议预示了当今人工智能中最主要关注的许多主题,包括自然语言处理,图像识别和分类以及机器学习。
在第一次会议之后的几年中,人工智能研究蓬勃发展。
在过去的十年中,人工智能已经从科幻小说领域转移到了科学事实领域。关于 IBM's Watson AI winning the game show Jeopardy和 Google's AI beating human champions at the game of Go 的故事使得人工智能重新回到了大众的视线中。
如今,所有最大的科技公司都在投资AI项目,并且我们大多数人每天都在使用智能手机,社交媒体,Web搜索引擎或电子商务网站时与AI软件进行交互。 我们最常与之交互的AI类型之一就是机器学习。
其次,什么是机器学习(ML)?
机器学习可以认为是一种数据驱动的决策方法,是人工智能的一种应用,为AI提供了一种自学习的能力。一般在机器学习任务中,我们都会定义具体的目标Goal和评估标准Metrics。机器学习可以不断地学习数据和计算评估标准并迭代来达到Goal。

按照数据的处理方式可以分为:无监督学习、半监督学习、监督学习
按照算法原理来看可以分为:回归算法、决策树、贝叶斯、聚类算法、集成算法、深度学习、关联规则等。
按照不同领域可以分为:NLP、CV、推荐系统等等
短语“机器学习”也可以追溯到上世纪中叶。 1959年,亚瑟·萨缪尔(Arthur Samuel)将机器学习定义为“无需明确编程即可学习的能力”。 然后,他继续创建了一个计算机检查器应用程序,该应用程序是最早可以从自身的错误中吸取教训并随着时间的推移提高其性能的程序之一。
像AI研究一样,机器学习在很长一段时间里都不再流行,但是当数据挖掘的概念在1990年代左右开始兴起时,机器学习再次流行起来。 数据挖掘使用算法来查找给定信息集中的模式。 机器学习做同样的事情,但是又前进了一步–它根据学习到的内容改变程序的行为。
机器学习的一种近来非常流行的应用是图像识别。 首先必须对这些应用程序进行培训,换句话说,人类必须看一堆图片并告诉系统图片中的内容。 经过成千上万次重复,该软件可以了解哪些像素模式通常与马,狗,猫,花朵,树木,房屋等相关联,并且可以很好地猜测图像的内容。
许多基于Web的公司还使用机器学习来为其推荐引擎提供支持。 例如,当bilibili/zhihu决定要在你的推荐列表中显示什么内容时,当taobao突出显示你可能要购买的产品时,以及当douban建议你可能要观看的电影时,所有这些建议都是基于现有数据中的模式得出的预测。
当前,许多企业开始使用机器学习功能进行预测分析。 随着大数据分析变得越来越流行,机器学习技术已经变得越来越普遍,它是许多分析工具中的标准功能。
实际上,机器学习已经与统计,数据挖掘和预测分析紧密相关,以至于有人认为应该将其归类为与人工智能不同的领域。 毕竟,系统可以表现出诸如NLP或自动推理之类的AI功能,而没有任何机器学习功能,并且机器学习系统不一定需要具有任何其它人工智能功能。
有些人更喜欢使用“机器学习”一词,因为他们认为它比“人工智能”听起来更技术性和更少的畏惧感。有的程序员戏称道,两者之间的区别在于“机器学习确实有效”。
然而,机器学习从一开始就一直是围绕着人工智能讨论的一部分,并且两者在当今市场上的许多应用中仍然紧密地交织在一起。 例如,个人助理和机器人通常具有许多不同的AI功能,包括ML。
顺便介绍一下AI和ML的前沿研究领域:深度学习、神经网络和认知计算:
“机器学习”和“人工智能”并不是与计算机科学领域相关的唯一术语。 IBM经常使用术语“认知计算”,该术语或多或少与AI同义。
但是,其他一些术语确实具有非常独特的含义。 例如,人工神经网络或神经网络是一种设计用于以类似于生物大脑工作方式的方式处理信息的系统。因为神经网络往往特别擅长机器学习,因此有时会将这两个术语混为一谈。

此外,神经网络为深度学习提供了基础,深度学习是一种特殊的机器学习。深度学习使用一组在多层中运行的机器学习算法。使用GPU一次处理大量数据的系统在某种程度上使之成为可能。

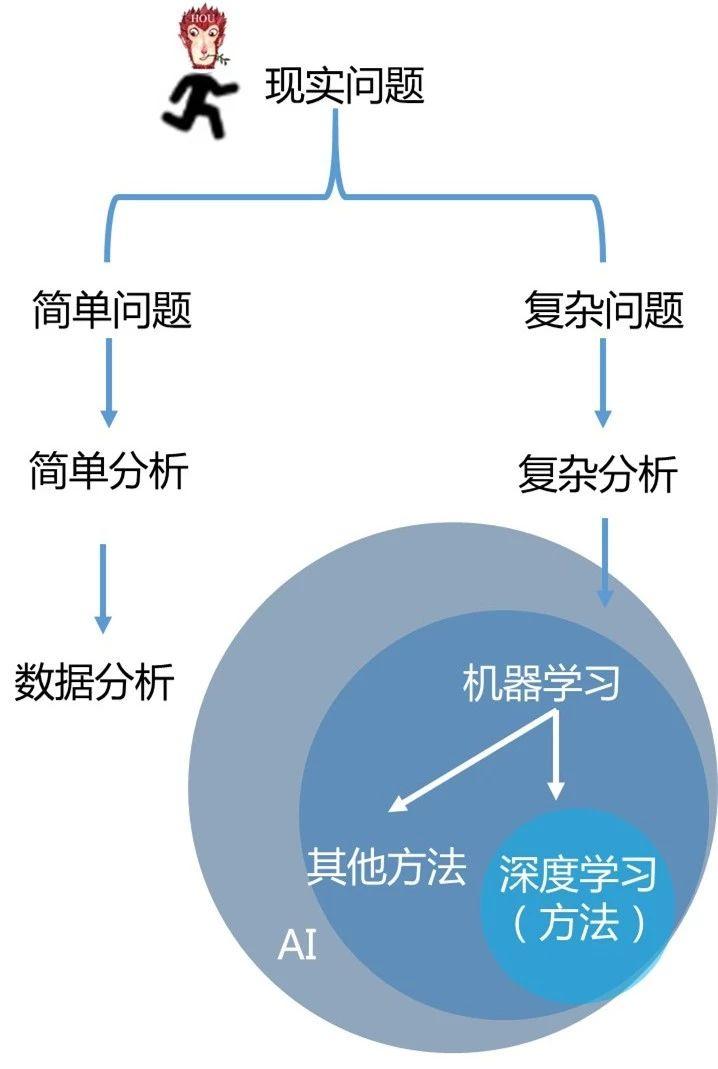
数据分析,机器学习,深度学习,人工智能的关系我画了这张图


我来解释下这张图。
一切技术的出现都是为了解决现实问题,而现实问题分为简单问题和复杂问题。简单问题,需要简单分析,我们使用数据分析。复杂问题,需要复杂分析,我们使用机器学习。
1、什么是简单问题?
比如公司领导想知道每周的销售情况,这种就是简单问题。简单问题可以用数据分析来处理,通过分析数据来分析出有用的信息。
最简单的,你用excel分析一家淘宝店铺的销售数据,每周公司会让你出一份周报一份发现了最近几个月销量下降,然后根据分析产生销量下降的原因是什么,找到原因后制定对应的策略来提高销量。
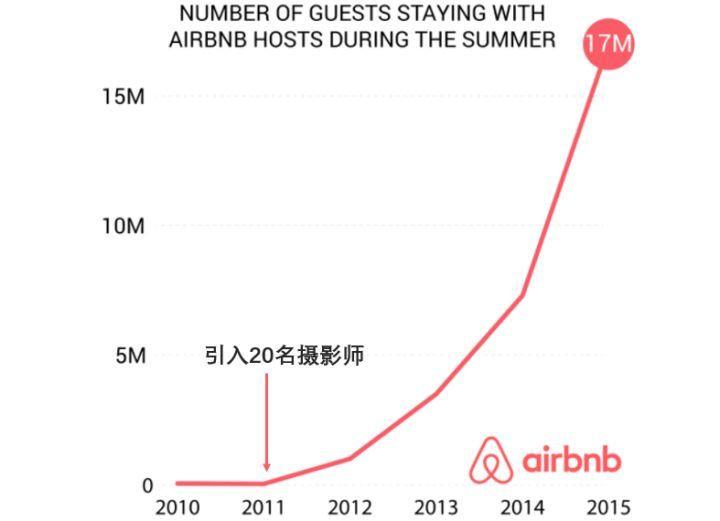
我们来看一个真实的案例。全球最大的旅行房屋租赁社区Airbnb曾在2011年纠结于新用户增长的缓慢,有一天,他们的数据分析团队发现房源照片的精美程度,跟房源的预定人数成很大的正相关。
于是,他们提出一种假设,即“附有专业摄影照片的房源要更抢手,因此房主肯定会愿意申请Airbnb提供的此项服务”。
他们迅速上线了一个提供专业摄影照片服务的版本,然后跟原版本做A/B Test,发现同一个房源,使用专业摄影服务的比不使用的多了2-3倍的订单量。
2011年后期,Airbnb雇用了20名专业摄影师,以帮助平台上的房主拍摄房屋照片,几乎在同一时间段,Airbnb的订单量曲线有了一个陡峭的增长。

2、什么是复杂问题?
比如我们天天使用的淘宝,它会根据你的历史购物习惯(数据),来给推荐你可能感兴趣的商品。淘宝是如何做到的呢?对于这种复杂问题,淘宝背后使用的就是机器学习。
我再举个例子,今日头条是如何靠机器学习逆袭成为新闻客户端老大的。
2010年前后,门户时代崛起的网易、搜狐、腾讯三巨头向移动端转型,几乎垄断了当时的新闻客户端市场。而仅仅2年后,今日头条,使用“机器学习”这把屠龙刀向用户个人性化推荐用户感兴趣的新闻,一举打破巨头垄断,成为新闻客户端老大。虽然,后来腾讯和网易为了对抗头条,推出了类似的产品的天天快报和网易号,但因起步晚和算法不成熟,都失败了。
下面图片是我在知乎一个问题下回答的传播分析报告
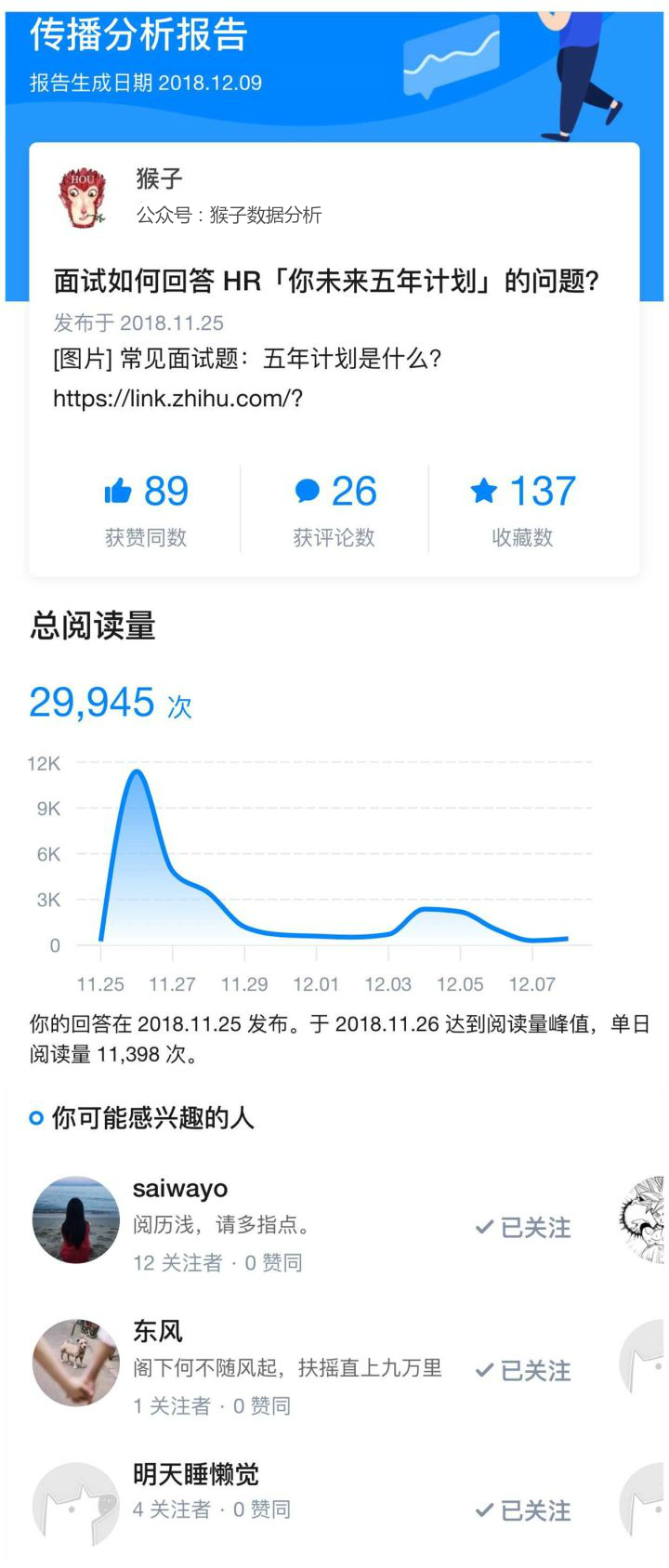

在这份报告中,像点赞数、评论数、收藏数、总阅读量这样的分析就是简单分析。像“你可能感兴趣的人”这样的分析,就是复杂分析,需要通过机器学习算法来找到,类似于豆瓣上给你推荐感兴趣的电影、淘宝上给你推荐感兴趣的商品。
3、什么是深度学习?
机器学习分很多方法(算法),不同的方法解决不同的问题。深度学习是机器学习中的一个分支方法。
深度学习在图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大量的人力做相关的研究和开发。我说个例子,你肯定听说过。那就是2016年谷歌旗下DeepMind公司开发的阿尔法围棋(AlphaGo)战胜人类顶尖围棋选手。阿尔法围棋的主要工作原理就是“深度学习”。


4、什么是人工智能?
人工智能,它的范围很广,广义上的人工智能泛指通过计算机(机器)实现人的头脑思维,使机器像人一样去决策。
机器学习是实现人工智能的一种技术。所以我把人工智,机器学习,深度学习放到不同的圆圈里,他们三者是包含的关系:
现在,你已经清楚了数据分析、机器学习、深度学习这些概念的关系了。当我们从解决现实问题的角度来看,很多概念会清楚。处理不同的问题,使用不同的方法。
5、数据分析与人工智能的关系?
你可能会问了:“上图中没看出数据分析和人工智能有什么关系呀,是不是学习数据分析没什么用?那我是不是一开始就学习机器学习了,这样可以直接进人工智能时代,享受时代红利了?”
这么想是不对的。
机器学习是很多学科的知识融合,而数据分析是机器学习的基础。只有学会了数据分析处理数据的方法,你才能看懂机器学习方面的知识。这就好比,你想上初中(机器学习),必须先读完小学(数据分析)才可以。
所以,我在下面图片中画了两条黄色的线,表示数据分析的两个方向,如果你喜欢深入技术,学会了数据分析,你才能打好基础,去学习机器学习。如果你喜欢商业方面的内容,可以往人工智能业务方向发展。
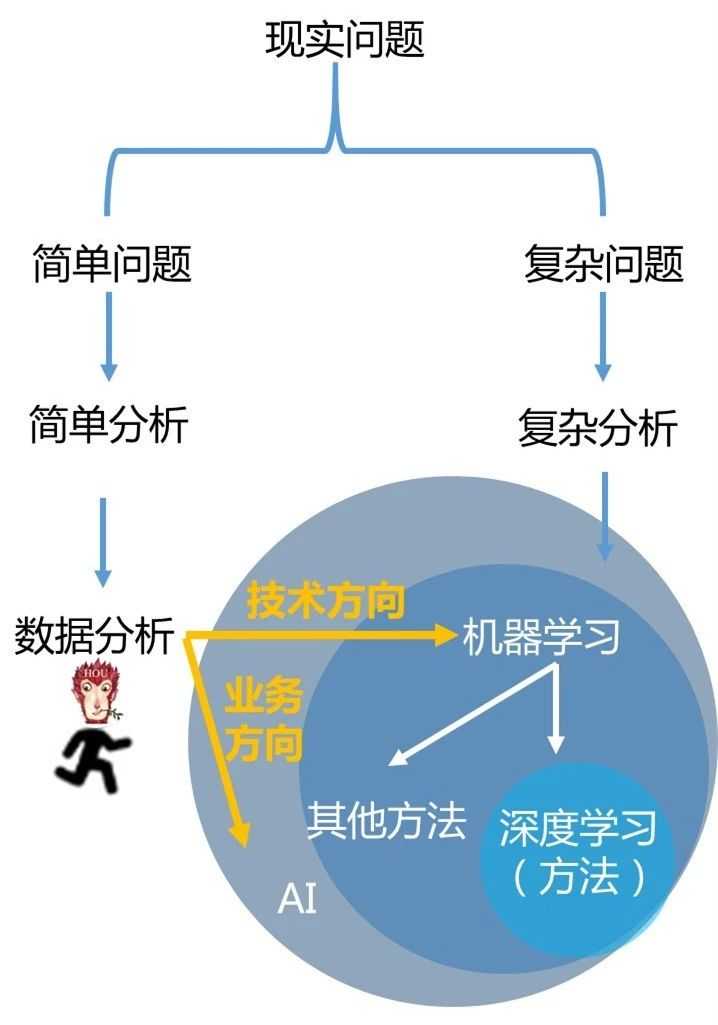

职业社交网站领英在《2018新兴工作岗位报告》中说,2018年,15个新兴职位里有6个与人工智能相关,这说明,与人工智能相关的技能开始渗透到各个行业,而不仅仅是技术行业。
领英把人工智能技能定义为:开发和有效使用人工智能工具和技术的技能。这是领英上增长最快的一个技能,从全球来看,2015年到2017年这个技能增长了190%。
之前很多人本来就是零基础,却买来一堆机器学习的课程和书来学习,最后看的是晕头转向,觉得自己不适合。
其实,这是走错了路。如果你是零基础,想进入人工智能这个相关的职业,要先从数据分析开始学起。
6、总结
1)人工智能是指使机器像人一样去决策
2)机器学习是实现人工智能的一种技术
3)机器学习分很多方法(算法),不同的方法解决不同的问题。深度学习是机器学习中的一个分支方法。
4)数据分析可以帮助你从零进入人工智能时代。如果你喜欢深入技术,学会了数据分析,你才能打好基础,去学习机器学习。如果你喜欢商业方面的内容,可以往人工智能业务方向发展。
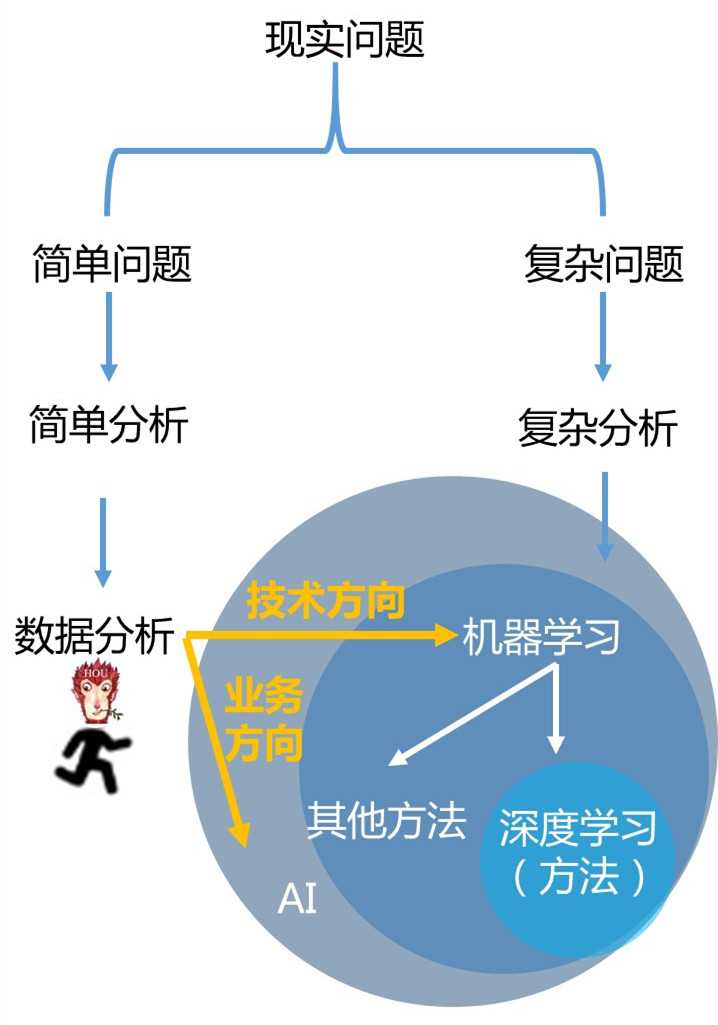
5)下面这张图是它们之间的关系


人工智能:一种现代方法

谢邀。
机器学习可以算是一门预测科学。给定某些已知特征,然后用来预测一些未知目标。未知数可以是结构化(比如数字),也可以是非结构化的(比如字符串响应)。
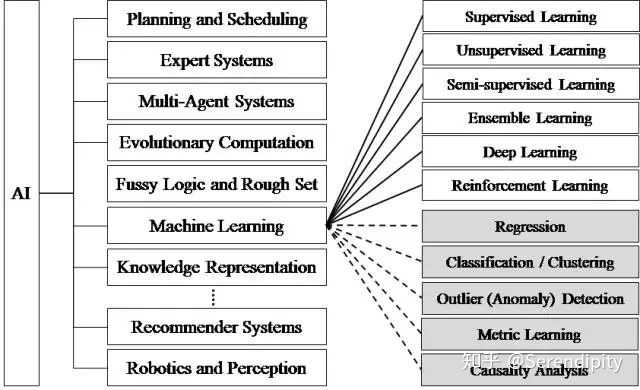
其本身是属于人工智能的六个组成学科之一(自然语言处理、知识表示形式、自动推理、机器学习、计算机视觉、机器人技术)
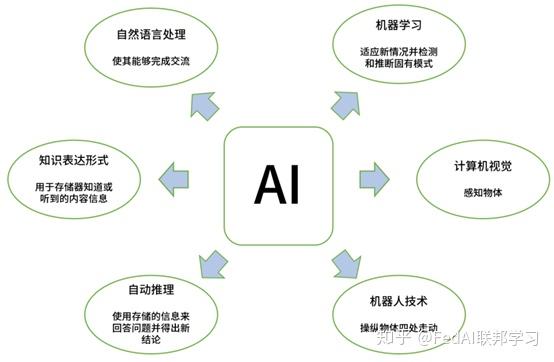

这样介绍可能有些空泛,下边我们讲个故事,来讲述下机器学习和AI的关系,顺便也提一下深度学习。
我们假设在未来的某一年,机器人已经融入人类生活各方面。
这天,你打完球回家,打算洗个澡好好休息下,而你的母亲却让你去市场买一斤苹果回来。你很累了,并不想动弹,于是打算告诉你的专属机器人,训练它帮你去买苹果。
机器学习要做什么?
现在我们代入场景,你派出的机器人已经到达市场了,那里有苹果、橘子等各种水果,机器人就需要靠机器学习进行区分了。你可以训练机器人识别大小(重量、体积)、颜色(比如0表示红色,1表示橙色),从而让机器人“识别”出哪个是苹果,完成购买。
机器学习作为一组学习算法,在目前是构建AI的主流方法(甚至被称为“已知唯一途径”)。
深度学习能做什么?
深度学习是机器学习的子类型,能够进一步训练模型,但需要比机器学习更多的数据及属性标签。
比如,你的母亲只想吃红富士苹果,而从一堆各种苹果里检测出哪个是红富士,就需要使用到深度学习的技术。
完整的AI会做什么?
继续代入场景,机器人买了一斤红富士苹果,现在它需要意识到自己已经完成了工作,并且需要在不损坏苹果的前提下返回家中。此外,回家之后它还需要把苹果交给你而不是直接给你母亲,这样子才能让你完成二次鉴定,确保无误。
真正意义上的AI意味着模仿人类的智慧,学习只是其中的一部分,因此仅仅靠机器学习是无法称作AI的,这也就是我们开头介绍的,它只是AI的组成学科之一,AI的实现还需要其他几门协同作战。
最后,为大家献上这张图,作为总结:

以上,有用记得点个赞同 ↓↓↓ 感谢!

今天我们说到的人工智能,其实就是机器学习里面的神经网络和深度学习。接下来讲述机器如何学习人类掌握明知识和暗知识,在这之后,你会对机器学习有一个清晰的认知。
机器学习明知识
计算机科学家最早的想法是把自己的明知识,包括能够表达出来的常识和经验放到一个巨大的数据库里,再把常用的判断规则写成计算机程序。这就是在 20 世纪 70 年代兴起并在 20 世纪 80 年代达到高潮的「知识工程」和「专家系统」。比如一个自动驾驶的「专家系统」就会告诉汽车,「如果红灯亮,就停车,如果转弯时遇到直行,就避让」,依靠事先编好的一条条程序完成自动驾驶。结果你可能想到了,人们无法穷尽所有的路况和场景,这种「专家系统」遇到复杂情况时根本不会处理,因为人没教过。「专家系统」遇到的另一个问题是假设了人类所有的知识都是明知识,完全没有意识到默知识的存在。一个典型的例子是 20 世纪 80 年代中国的「中医专家系统」。当时计算机专家找到一些知名的老中医,通过访谈记录下他们的「望闻问切」方法和诊断经验,然后编成程序输入到计算机中。在中医眼中每一个病人都是独特的。当他看到一个病人时会根据经验做出一个整体的综合判断。这些经验连老中医自己都说不清道不明,是典型的默知识。所以中医诊断绝不是把舌苔的颜色划分成几种,把脉象分成几十种,然后用查表方式就可以做判断的。「专家系统」既不能给机器输入足够的明知识,更无法把默知识准确地表达出来输入给机器。所以,「专家系统」和「知识工程」在 20 世纪 80 年代之后都偃旗息鼓了。
要想把一个领域内的所有经验和规则全部写出来不仅耗费时间,而且需要集合许多人。即使如此,那些谁也没有经历过的情况还是无法覆盖。电脑的信息处理速度比人脑快得多,那么能不能把大量的各种场景下产生的数据提供给机器,让机器自己去学习呢?这就是现在风行一时的「机器学习」。
今天的机器可以自己学习两大类明知识:用逻辑表达的判断规则和用概率表达的事物间的相关性。
符号学派——机器自己摸索出决策逻辑
前面说过,理性主义认为事物间都有因果关系,基于因果关系,通过逻辑论证推理就能得到新知识。在机器学习中这一派被称为符号学派,因为他们认为从逻辑关系中寻找的新知识都可以归结为对符号的演算和操作,就像几何定理的推理一样。这种知识通常可以用一个逻辑决策树来表示。决策树是一个根据事物属性对事物分类的树形结构。比如冬天医院门诊人满为患,测完体温,主任医生先问「哪里不舒服」,病人说「头疼,咳嗽」,主任医生再听呼吸。感冒、流感、肺炎都可能是这些症状的原因,现在要根据这些症状判断病人到底得了什么病,这种从结果反着找到因果链条的过程就叫「逆向演绎」。这时候主任医生用的就是一个决策树:体温低于 38.5℃,咳嗽,头痛,可能是普通感冒,回去多喝白开水!体温高于 38.5℃,还剧烈咳嗽呼吸困难,可能是肺炎,咳嗽不厉害就可能是流感。实际情形当然要比这复杂。但原理就是根据观察的症状逐项排除,通过分类找到病因。
这时候门诊新来了实习医生小丽,要在最短时间内学会主任医生的诊断方法。主任医生忙得根本没时间教她,就扔给她一沓过去病人的病历和诊断结果,自己琢磨去!小丽看着几十个病人的各项指标和诊断结果,不知道从哪里下手。这时候刚学了决策树的主治医生小张路过说:我来帮你。咱先随便猜一个主任的判断逻辑,比如先看是否咳嗽,再看是否发烧。把这些病例用这个逻辑推演一遍,如果逻辑的判断结果和主任的诊断结果吻合,咱就算猜中了。如果不吻合,咱就换个逻辑,无非是换些判断准则,比如你可能一开始把体温标准定在了 37.5℃,结果把很多普通感冒给判断成流感了。

如何定义机器学习?
何谓 “机器学习”,学界尚未有统一的定义。但有两个定义特别值得了解:一个来自卡内基梅隆大学的Tom Mitchell教授,一个来自Goodfellow、Bengio 和 Courville合著的经典“花书”《深度学习》。
Tom Mitchell:根据优化过程抽象定义机器学习
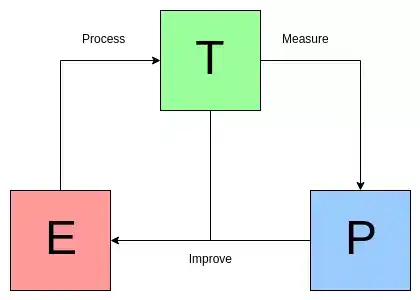
第一个定义,来自著名的计算机科学家、机器学习研究者,卡内基梅隆大学的 Tom Mitchell 教授。
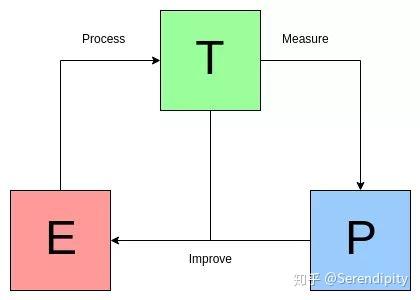
对于某类任务 T 和性能度量 P,如果一个计算机程序在 T 上以 P 衡量的性能随着经验 E 而自我完善,那么我们称这个计算机程序在从经验 E 中学习。[1]
Mitchell 的这个定义在机器学习领域是众所周知的,并且经受了时间的考验。这句话首次出现在他 1997 年出版的 Machine Learning 一书中。
在 Goodfellow, Bengio & Courville 最近出版的权威著作《深度学习》(Deep Learning) 的第 5 章中,这段引文也占据了突出位置,成为该书对学习算法的解释的出发点。
下图是 Mitchell 定义的图示:

“花书”《深度学习》:论计算在机器学习中的重要性
说到 Goodfellow、Bengio 和 Courville,就不得不提他们合著的《深度学习》,这本书对机器学习是这样定义的:
机器学习本质上属于应用统计学,更多地关注如何用计算机统计地估计复杂函数,不太关注为这些函数提供置信区间。[2]
Mitchell 对机器学习的定义在应用中不再适用;它侧重于优化过程的具体组成部分,这些组成部分通常与机器学习有关,但它没有规定应该如何在实践中接近它。
《深度学习》中对机器学习的定义在本质上要规范得多,它指出计算能力得到了利用 (实际上强调了对计算能力的使用),而传统的统计概念置信区间则不再强调。
机器学习有哪些算法?
机器学习算法可以分为三个大类 —— 监督学习、无监督学习和强化学习。
- 监督学习,对训练有标签的数据有用,但是对于其他没有标签的数据,则需要预估。
- 无监督学习,用于对无标签的数据集(数据没有预处理)的处理,需要发掘其内在关系的时候。
- 强化学习,介于两者之间,虽然没有精准的标签或者错误信息,但是对于每个可预测的步骤或者行为,会有某种形式的反馈。
下面介绍监督学习和无监督学习的十大常用算法:
监督学习
1. 决策树 (Decision Trees)
决策树是一个决策支持工具,它用树形的图或者模型表示决策及其可能的后果,包括随机事件的影响、资源消耗、以及用途。请看下图,随意感受一下决策树长这样的:
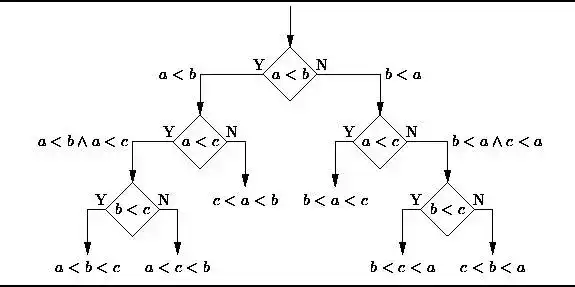

从商业角度看,决策树就是用最少的 Yes/No 问题,尽可能地做出一个正确的决策。它让我们通过一种结构化、系统化的方式解决问题,得到一个有逻辑的结论。
2. 朴素贝叶斯分类 (Naive Bayes Classification)
朴素贝叶斯分类器是一类简单概率分类器,它基于把贝叶斯定理运用在特征之间关系的强独立性假设上。下图是贝叶斯公式 ——P (A|B) 表示后验概率,P (B|A) 表示似然度,P (A) 表示类别的先验概率 (class prior probability),P (B) 表示做出预测的先验概率 (predictor prior probability)。
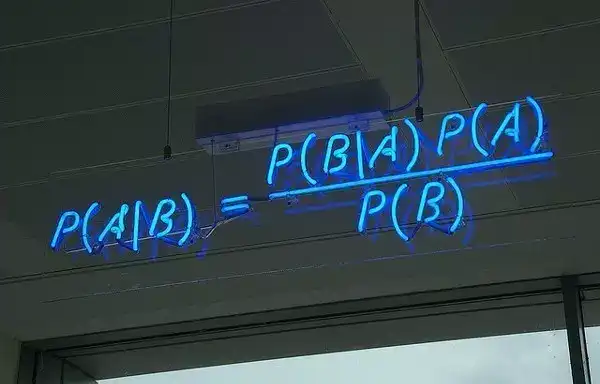

现实生活中的应用例子:
- 一封电子邮件是否是垃圾邮件
- 一篇文章应该分到科技、政治,还是体育类
- 一段文字表达的是积极的情绪还是消极的情绪?
- 人脸识别
3. 普通最小二乘回归 (Ordinary Least Squares Regression)
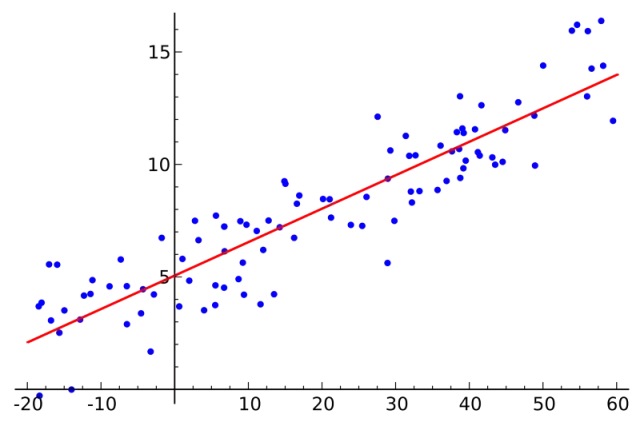

如果你学过统计学,你可能听过线性回归。至少最小二乘是一种进行线性回归的方法。你可以认为线性回归就是让一条直线用最适合的姿势穿过一组点。有很多方法可以这样做,普通最小二乘法就像这样 —— 你可以画一条线,测量每个点到这条线的距离,然后加起来。最好的线应该是所有距离加起来最小的那根。
线性法表示建模线性模型,而最小二乘法可以最小化该线性模型的误差。
4. 逻辑回归 (Logistic Regression)
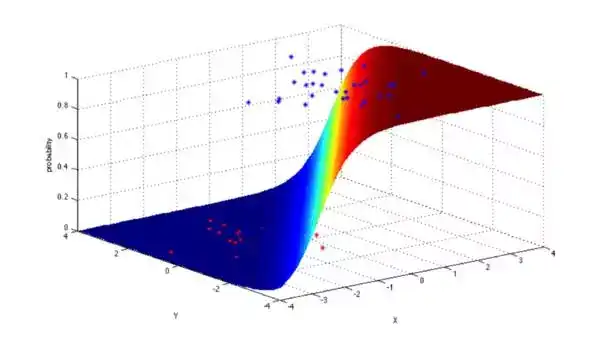

逻辑回归是一种非常强大的统计方法,可以把有一个或者多个解释变量的数据,建立为二项式类型的模型,通过用累积逻辑分布的逻辑函数估计概率,测量分类因变量和一个或多个独立变量之间的关系。
通常,回归在现实生活中的用途如下:
- 信用评估
- 测量市场营销的成功度
- 预测某个产品的收益
- 特定的某天是否会发生地震
5. 支持向量机 (Support Vector Machines)


SVM 是一种二分算法。假设在 N 维空间,有一组点,包含两种类型,SVM 生成 a (N-1) 维的超平面,把这些点分成两组。比如你有一些点在纸上面,这些点是线性分离的。SVM 会找到一个直线,把这些点分成两类,并且会尽可能远离这些点。
从规模看来,SVM(包括适当调整过的)解决的一些特大的问题有:广告、人类基因剪接位点识别、基于图片的性别检测、大规模图片分类…
6. 集成方法 (Ensemble Methods)
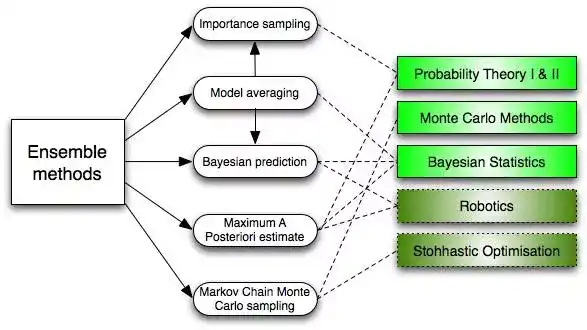

集成方法吸纳了很多算法,构建一个分类器集合,然后给它们的预测带权重的进行投票,从而进行分类。最初的集成方法是贝叶斯平均法 (Bayesian averaging),但是最近的算法集还包括了纠错输出编码 (error-correcting output coding) ,bagging 和 boosting
那么集成方法如何工作的?为什么它们比单独的模型更好?
- 它们均衡了偏差:就像如果你均衡了大量的倾向民主党的投票和大量倾向共和党的投票,你总会得到一个不那么偏颇的结果。
- 它们降低了方差:集合大量模型的参考结果,噪音会小于单个模型的单个结果。在金融上,这叫投资分散原则 (diversification)—— 一个混搭很多种股票的投资组合,比单独的股票更少变故。
- 它们不太可能过度拟合:如果你有单独的模型不是完全拟合,你结合每个简单方法建模,就不会发生过度拟合 (over-fitting)
无监督学习
7. 聚类算法 (Clustering Algorithms)
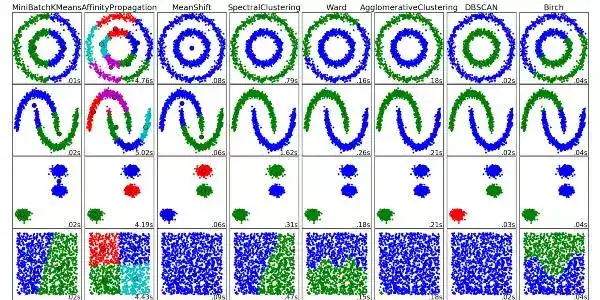

聚类就是把一组对象分组化的任务,使得在同一组的对象比起其它组的对象,它们彼此更加相似。
每种聚类算法都不同,下面是其中一些:
- 基于图心(Centroid)的算法
- 基于连接的算法
- 基于密集度的算法
- 概率论
- 降维
- 神经网络 / 深度学习
8. 主成分分析 (Principal Component Analysis)
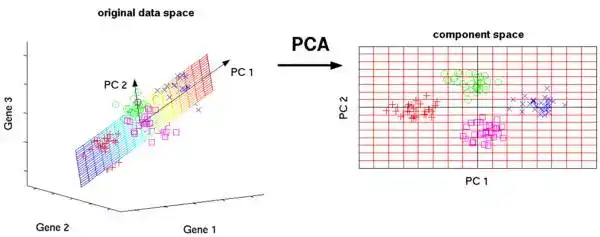

PCA 是一种统计过程,它通过正交变换把一组可能相关联的变量观察,转换成一组线性非相关的变量的值,这些非相关的变量就是主成分。
PCA 的应用包括压缩、简化数据使之易于学习,可视化。需要注意的是,当决定是否用 PCA 的时候,领域知识特别重要。它不适用于噪音多的数据(所有成分的方差要很高才行)
9. 奇异值分解 (Singular Value Decomposition)
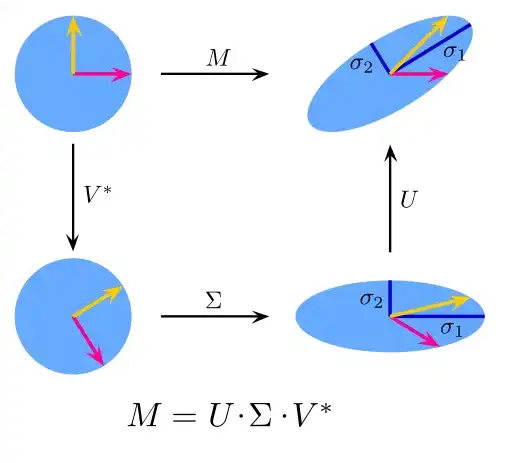

线性代数中,SVD 是对一个特别复杂的矩阵做因式分解。比如一个 m*n 的矩阵 M,存在一个分解如 M = UΣV,其中 U 和 V 是酉矩阵,Σ 是一个对角矩阵。
PCA 其实是种简单的 SVD。在计算机图形领域,第一个脸部识别算法就用了 PCA 和 SVD,用特征脸 (eigenfaces) 的线性结合表达脸部图像,然后降维,用简单的方法把脸部和人匹配起来。尽管如今的方法更加复杂,依然有很多是依靠类似这样的技术。
10. 独立成分分析 (Independent Component Analysis)
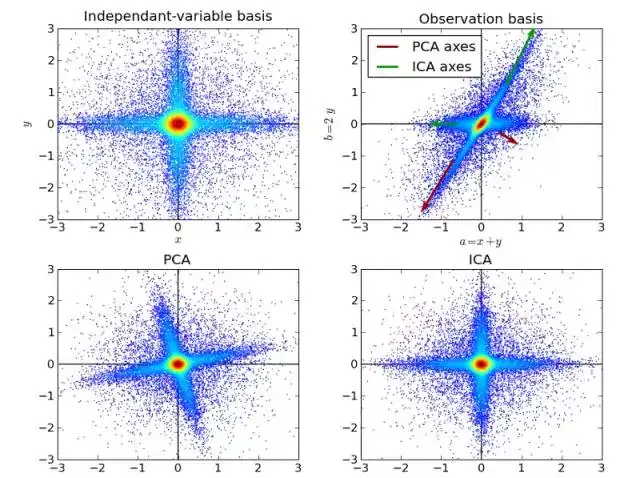

ICA 是一种统计技术。它发掘随机变量、测量数据或者信号的集合中隐含的因素。ICA 定义了一种通用模型,用于观测到的多变量数据,通常是一个巨大的样本数据库。在这一模型中,假设数据变量是一些未知的、潜在的变量的线性组合,而组合方式也是未知的。同时假设,潜在的变量是非高斯分布且相互独立的,我们称之为观测数据的独立成分 (Independent components)。
ICA 与 PCA 有一定关联,但是一种更加有用的技术,在经典方法完全失效的时候,可以发现数据源中的潜在因素。它的应用包括数字图片,文件数据库,经济指数和心理测量。
参考链接:
[1] 【技术必备】解读十大机器学习算法及其应用
[2] 机器学习的本质是什么?

深度学习是女朋友,机器学习是丈母娘,人工智能是命运。
===
已有答案说得非常好了,但是对于普通用户来讲还是不够直观,我用我们的“看相术找男朋友”来类比一下(阐述深度学习与机器学习的区别),首先深度学习是机器学习的子类,所以深度学习的特点其实机器学习都有,但深度学习更加突出“深(Deep)”。
好了,现在有一个人类放到你面前,机器学习(丈母娘)怎么做呢?
1)嗯,有鼻子有眼,我看行;
2)嗯,有房也有车,我看行;
3)嗯,父母还双亡,我看行;
闺女,就这个吧。机器学习就是程咬金,三板斧,就下结论。


女朋友经过了老娘的首肯,那就先处着吧,但她想得可就多多了,她开始深度学习了:
1)谁没鼻子没眼睛啊?是个人就能做我男朋友吗?哼!加一层解析出来!我得看看他的三庭五眼,嗯,天庭饱满,地阔方圆;
2)嗯,再加一层,我得看看他的八字和我的相不相合,哎哟喂,我水命,他木命,慕我的名而来,哈哈!
3)嗯,再加一层,我得看看他的星座,哎哟喂,我摩羯座,他金牛座,你是上天安排来给我脱单的吗,哈哈!
4)嗯,再加一层,我得看看他的属相,哎哟喂,他属狗啊,听话,忠诚,小奶~,哈哈!

5)嗯,再加一层,我得看看他的眉毛,我去,眉间搭桥,不赌就嫖,滚!
6)嗯,再加一层,我得看看他的痣,哎哟喂,一痣痣下,当官最大,好呢!

6.2)嗯,这层多看几颗痣,哎呀,有长命百岁痣,不错,至少不用守寡啊,他送我走比我送他走舒服得多!哎哟喂,你个龟孙儿,竟然有好色痣!我一口盐汽水喷死你!

深度学习(女朋友)要做这么多层次,多参数的运算,自然要耗费很长时间,
女朋友的考察期通常比丈母娘的考察期长得多得多,原因也就是因为要“深度运算深度学习”!
终于女朋友运算了3个月,了解了这人的方方面面,觉得还ko以!
对着这人说:
“我们重新认识一下吧,你叫什么名字?”
“我中文名叫:李查得 · 太深,你叫我Richard就好”
两人最终喜结连理,洞房花烛的时候,突闻一声惊叫:
“你TM是个女的?”
“你也没加这一层运算啦?怎么,你们地球人女的不能结婚吗?”
“你是哪里人?”
“我来自氪星”
“你TM真是我的克星!人工智能,人工智能,我踢你丫的人工智能!”拿起拖鞋扔下了床头柜的Apple HomePod,却传来Siri的声音:
“这就是命”


“那我们还在一起吗?要是不行的话,我要回去找我表哥啦。”
“你有表哥?你有表哥?我TM考察了半年的参数其实是你表哥?你们干嘛穿一样的衣服?就不能淘bao搞一套不一样的吗?
”我们没有身份证,没办法实名认证,所以没有淘bao账号,再说了,他穿的XXXXL号,我穿的是L号,哪里一样啦?“
”滚~~~~~~~“



机器学习是人工智能的核心技术,是学习人工智能必不可少的环节。机器学习中有很多算法,能够解决很多以前难以企的问题,机器学习中涉及到的算法有不少,下面小编就给大家普及一下这些算法。
一、线性回归
一般来说,线性回归是统计学和机器学习中最知名和最易理解的算法之一。这一算法中我们可以用来预测建模,而预测建模主要关注最小化模型误差或者尽可能作出最准确的预测,以可解释性为代价。我们将借用、重用包括统计学在内的很多不同领域的算法,并将其用于这些目的。当然我们可以使用不同的技术从数据中学习线性回归模型,例如用于普通最小二乘法和梯度下降优化的线性代数解。就目前而言,线性回归已经存在了200多年,并得到了广泛研究。使用这种技术的一些经验是尽可能去除非常相似(相关)的变量,并去除噪音。这是一种快速、简单的技术。
二、Logistic 回归
它是解决二分类问题的首选方法。Logistic 回归与线性回归相似,目标都是找到每个输入变量的权重,即系数值。与线性回归不同的是,Logistic 回归对输出的预测使用被称为 logistic 函数的非线性函数进行变换。logistic 函数看起来像一个大的S,并且可以将任何值转换到0到1的区间内。这非常实用,因为我们可以规定logistic函数的输出值是0和1并预测类别值。像线性回归一样,Logistic 回归在删除与输出变量无关的属性以及非常相似的属性时效果更好。它是一个快速的学习模型,并且对于二分类问题非常有效。
三、线性判别分析(LDA)
在前面我们介绍的Logistic 回归是一种分类算法,传统上,它仅限于只有两类的分类问题。而LDA的表示非常简单直接。它由数据的统计属性构成,对每个类别进行计算。单个输入变量的 LDA包括两个,第一就是每个类别的平均值,第二就是所有类别的方差。而在线性判别分析,进行预测的方法是计算每个类别的判别值并对具备最大值的类别进行预测。该技术假设数据呈高斯分布,因此最好预先从数据中删除异常值。这是处理分类预测建模问题的一种简单而强大的方法。
四、决策树
决策树是预测建模机器学习的一种重要算法。决策树模型的表示是一个二叉树。这是算法和数据结构中的二叉树,没什么特别的。每个节点代表一个单独的输入变量x和该变量上的一个分割点。而决策树的叶节点包含一个用于预测的输出变量y。通过遍历该树的分割点,直到到达一个叶节点并输出该节点的类别值就可以作出预测。当然决策树的有点就是决策树学习速度和预测速度都很快。它们还可以解决大量问题,并且不需要对数据做特别准备。
五、朴素贝叶斯
其实朴素贝叶斯是一个简单但是很强大的预测建模算法。而这个模型由两种概率组成,这两种概率都可以直接从训练数据中计算出来。第一种就是每个类别的概率,第二种就是给定每个 x 的值,每个类别的条件概率。一旦计算出来,概率模型可用于使用贝叶斯定理对新数据进行预测。当我们的数据是实值时,通常假设一个高斯分布,这样我们可以简单的估计这些概率。而朴素贝叶斯之所以是朴素的,是因为它假设每个输入变量是独立的。这是一个强大的假设,真实的数据并非如此,但是,该技术在大量复杂问题上非常有用。所以说,朴素贝叶斯是一个十分实用的功能。
六、K近邻算法
K近邻算法简称KNN算法,KNN 算法非常简单且有效。KNN的模型表示是整个训练数据集。KNN算法在整个训练集中搜索K个最相似实例(近邻)并汇总这K个实例的输出变量,以预测新数据点。对于回归问题,这可能是平均输出变量,对于分类问题,这可能是众数类别值。而其中的诀窍在于如何确定数据实例间的相似性。如果属性的度量单位相同,那么最简单的技术是使用欧几里得距离,我们可以根据每个输入变量之间的差值直接计算出来其数值。当然,KNN需要大量内存或空间来存储所有数据,但是只有在需要预测时才执行计算。我们还可以随时更新和管理训练实例,以保持预测的准确性。
七、Boosting 和 AdaBoost
首先,Boosting 是一种集成技术,它试图集成一些弱分类器来创建一个强分类器。这通过从训练数据中构建一个模型,然后创建第二个模型来尝试纠正第一个模型的错误来完成。一直添加模型直到能够完美预测训练集,或添加的模型数量已经达到最大数量。而AdaBoost 是第一个为二分类开发的真正成功的 boosting 算法。这是理解 boosting 的最佳起点。现代 boosting 方法建立在 AdaBoost 之上,最显著的是随机梯度提升。当然,AdaBoost 与短决策树一起使用。在第一个决策树创建之后,利用每个训练实例上树的性能来衡量下一个决策树应该对每个训练实例付出多少注意力。难以预测的训练数据被分配更多权重,而容易预测的数据分配的权重较少。依次创建模型,每一个模型在训练实例上更新权重,影响序列中下一个决策树的学习。在所有决策树建立之后,对新数据进行预测,并且通过每个决策树在训练数据上的精确度评估其性能。所以说,由于在纠正算法错误上投入了太多注意力,所以具备已删除异常值的干净数据十分重要。
八、学习向量量化算法(简称 LVQ)
学习向量量化也是机器学习其中的一个算法。可能大家不知道的是,K近邻算法的一个缺点是我们需要遍历整个训练数据集。学习向量量化算法(简称 LVQ)是一种人工神经网络算法,它允许你选择训练实例的数量,并精确地学习这些实例应该是什么样的。而学习向量量化的表示是码本向量的集合。这些是在开始时随机选择的,并逐渐调整以在学习算法的多次迭代中最好地总结训练数据集。在学习之后,码本向量可用于预测。最相似的近邻通过计算每个码本向量和新数据实例之间的距离找到。然后返回最佳匹配单元的类别值或作为预测。如果大家重新调整数据,使其具有相同的范围,就可以获得最佳结果。当然,如果大家发现KNN在大家数据集上达到很好的结果,请尝试用LVQ减少存储整个训练数据集的内存要求。
严格意义上说,人工智能和机器学习没有直接关系,只不过是机器学习的方法被大量的应用于解决人工智能的问题而已。目前机器学习是人工智能的一种实现方式,也是最重要的实现方式。

大数据和人工智能的浪潮正在席卷全球,众多热门词汇蜂拥而至:大数据(big data)、机器学习(Machine Learning)、数据挖掘(Data Ming)、深度学习(Deep Learning)、强化学习(Reinforcement Learning)、云计算(Cloud Computing)、人工智能(Artificial Intelligence)、数据库(Databases)等。不少人对这些高频词语的含义及其背后的关系总是似懂非懂、一知半解。
为了帮助大家能更好地理解大数据,在此使用简单的语言来解释这些词汇的含义,理清它们之间的关系。
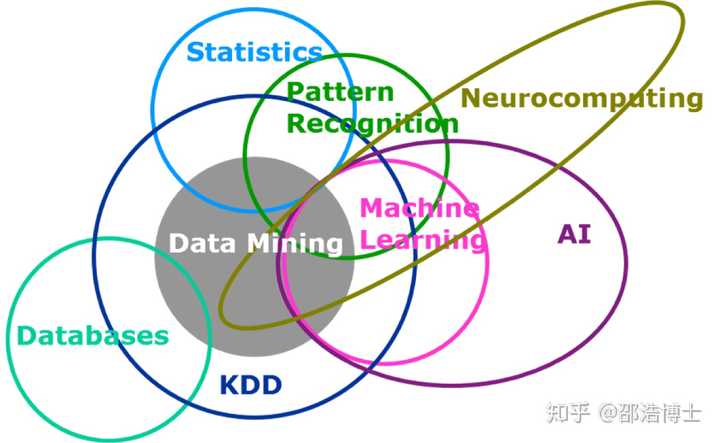
人工智能、机器学习、深度学习和强化学习
首先来看一下人工智能、机器学习和深度学习之间的关系。如图一所示,我们可以大致认为深度学习是机器学习中的一种学习方法,而机器学习则可以被认为是人工智能的一个分支。


人工智能
人工智能的一种实用的定义即为:人工智能是对计算机系统如何能够履行那些只有依靠人类智慧才能完成的任务的理论研究。例如,视觉感知、语音识别、在不确定条件下做出决策、学习和语言翻译等。
人工智能分为弱人工智能和强人工智能,前者让机器具备观察和感知的能力,可以做到一定程度的理解和推理;而强人工智能期待让机器获得自适应能力,解决一下之前没有遇到过的问题。电影里的人工智能多半是描绘的强人工智能,而这部分目前在显示世界中难以实现。
机器学习
机器学习指的是计算机系统无需遵照显示的程序指令,而只是依靠暴露在数据中来提升自身性能的能力。机器学习关注的是“如何构建能够根据经验自动改进的计算机程序”。比如,给予机器学习系统一个关于交易时间、商家、地点、价格及交易是否正当等信用卡交易信息数据库,系统就会学习到可用来预测的信用卡欺诈的模式。机器学习本质上是跨学科的,他采用了计算机科学、统计学和人工智能等领域的技术。
机器学习的应用范围非常广泛,针对那些产生庞大数据的活动,它几乎拥有改进一切性能的潜力。先如今,机器学习已经成为认知技术中最炙手可热的研究领域之一。
深度学习
深度学习在2006年被提出,是相对比较新的概念。深度学习是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术。它的基本特点,是试图模仿大脑的神经元之间传递、处理信息的模式。显然,“深度学习”是与机器学习中的“神经网络”是强相关的,“神经网络”也是其主要的算法和手段;或者,我们可以将“深度学习”称之为“改良版的神经网络”算法。
强化学习
强化学习为一个代理(Agent)在一个环境里设计一系列动作(Actions)以获得最优的未来长期回报(Reward)。走迷宫常被用来作为解释强化学习的例子。因为学习方法复杂,早年间强化学习只能解决一些非常简单(状态空间小、动作选择少)的问题。直到深度学习的出现,使得我们可以用深度神经网络去逼近一个近似的价值和策略函数,强化学习才取得很大的进展(如在AlphaGo里的价值判断网络),人们称其为深度强化学习(Deep Reinforcement Learning)。与其说是强化学习的进展,不如说是在强化学习的框架里,深度学习贡献了巨大的力量。
数据挖掘、人工智能、大数据和云计算
如图二所示,数据挖掘是从数据中发掘知识的过程,在这个过程中人工智能和数据库技术可以作为挖掘工具,数据可以被看作是土壤,云平台可以看作是承载数据和挖掘算法的基础设施。
大数据
大数据(big data),或称巨量资料,通常可以被定义为大小超出常规软件工具抓取,管理和处理能力的数据集。大数据是一个不断变化的目标;大数据具有Vloume(量大)、Velocity(速度快)、Variety(多样性)、Value(价值)四个显著特点;大数据不是指一个体量很大的单一数据,其关键在于多源数据融合,这是大数据的战略制高点,不是单单在“数据”前加个“大”字那么简单。
数据挖掘
数据挖掘(Data mining),又译为资料勘探、数据采矿,是从数据中发掘知识的过程。数据挖掘的处理过程一般包括数据预处理(ETL、数据清洗、数据集成等),数据仓库(可以是DBMS、大型数据仓库以及分布式存储系统)与OLAP,使用各种算法(主要是机器学习的算法)进行挖掘以及最后的评估工作。
数据挖掘与机器学习之间的关系如下:数据挖掘是一个过程,在此过程中,机器学习算法被用作工具来提取数据集中保存的潜在有价值的数据。

云计算
云计算平台一般是由第三方IT公司建立的涵盖基础设施、计算资源和平台操作系统的集成体。云平台解决了传统公司各自搭建机器集群所产生的建设周期长、升级换代慢、维护成本高的痛点,让这些公司可以从搭建计算平台的繁重任务中解脱出来而专注于自己的业务。
云平台用户可以高效、灵活的调整自己的资源配置,第三方公司根据用户使用的资源来收取相应的费用。打一个通俗的比喻,就好比不用每家每户都弄一个发电机,而是集中建一个发电厂,每家只需要插上插头就可以用电,根据用电量的多少来收费。用户不用关系发电厂建在哪里、如何发电,也不用担心如何维护发电厂本身的运转与安全。
多源数据的融合给数据管理、数据挖掘、机器学习和人工智能带来了很多新兴课题。当数据挖掘被用来挖掘和融合多源数据中蕴含的知识时,数据挖掘就跟大数据有了完美的结合。如果数据挖掘还在挖掘单一数据,那就是传统的数据挖掘或者是早年间研究的“海量数据挖掘”。作为数据挖掘的工具,分布式机器学习的重点是解决海量数据挖掘的问题,而不是解决多源数据融合的问题。要想融合多源数据,我们就需要在机器学习中设计新的多源数据融合算法,并为云平台设计特别的管理和索引方法。
参考文章:
数据挖掘与机器学习释义 | 博客 | 探码科技【官网】
《The Data Science Puzzle,explained》
《Data Mining vs. Machine Learning: What’s The Difference?》
《Five minutes to understand the vocabulary of artificial intelligence you have to know》

人工智能表示能够让机器具有人的智力的技术,这项技术能够让机器能够像人一样感知、思考、决策。人工智能不是一个具体的内容,它是一个比较宽泛的技术领域,包括自然语言理解、计算机视觉、推荐系统、语音识别等等,同时人工智能是一个涵盖数学、编程、计算机、认知科学的交叉性学科。
机器学习可以理解为人工智能的一部分,机器学习是指通过观察环境,通过与环境进行交互,从中学习到信息。机器学习分为训练和测试两个步骤,定义一个模型,在训练集上训练得到训练模型,然后可以在测试数据上进行测试得到测试结果。训练分为监督学习和无监督学习两种。
现阶段关于机器学习比较正式的一个定义是:有来自卡内基梅隆大学的Tom 提出,一个好的学习问题定义如下,一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值P,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。


拿下棋来举例,经验E 就是程序上万次的自我练习的经验而任务T就是下棋。性能度量值 P呢?就是它在与一些新的对手比赛时,赢得比赛的概率。


结论:机器学习是人工智能的一种实现方法。
机器学习,最初的粗糙定义,就是让机器学习,就是不明确的编程,而是让机器从数据中学习到规律。
我们来看一下传统的编程是什么:
输入:数据+规则
输出:答案
那么我们看一下机器学习是什么:
输入:数据+答案
输出:规则
机器学习,适用于那些没有明确规则,或不好写规则的领域。比如,分辨猫和狗,一张图片,里面的动物是猫还是狗?按照传统编程的方法,是很难写这个规则的,一个一个像素点如何运算?如何设置条件判断?那么用机器学习的办法,就是我把很多猫的图片和狗的图片送给机器,并且告诉机器图片上的是猫还是狗,让机器自己输出如何判断猫和狗的规则,这个过程,就是机器学习。等到机器把规则输出后,就可以用这个规则,对新来的图片进行猫狗的分类了。
那么,一个比较严格的机器学习的定义如下:
对于一个任务T,我们有关于这个任务的经验E,衡量机器对这个任务的表现P,如果随着E的增加,P也增加,那么我们就说这事一个对于任务T的机器学习。
比如拦截垃圾邮件,成功分类出垃圾邮件就是任务T,过去人手工分类出来的垃圾邮件和非垃圾邮件就是经验E,机器对垃圾邮件分类的正确率就是P,如果给机器的已经分类好的垃圾邮件和非垃圾邮件数据越多,机器对新邮件的分类正确率P越高,那么就说这是一个垃圾邮件分类的机器学习。
那么机器如何去学习的呢?其实是把经验E中蕴含的规则用多参数的函数给拟合出来,而这个拟合过程在数学上就是一个最优化问题,通过最优化算确定拟合函数的参数的过程,就是机器学习中的“训练”。
因此,对于一个机器学习任务,我们首先要给机器足够的数据,然后对机器进行训练,训练完成后,要对机器进行测试,测试的时候要用机器没有见过的数据来测试,从而看机器学得好不好。如果不好,就要重新训练,如果学得好,达到了毕业标准,那么训练好的机器就可以走上工作岗位了。就好像一个学生,要先教他,让他学习,等他学完了还要考试,考试合格才可以去工作。
这样看起来,训练学生和训练机器是不是差不多,而且他们能做的事情也差不多。学生学画画,学会了可以成为画家,机器也可以学画画,学会了可以作画卖钱,卖的比毕加索的画还贵呢。学生可以学习下围棋,机器也可以学习下围棋,而且机器下围棋能下的比人类中最厉害的棋手还厉害。这就实现了人工智能(AI)。
实现人工智能的方法不只有机器学习,不过现在机器学习最火。


将机器学习模型量产化的方式有多种,具体实现途径取决于特定的用例。 本文以客户流失预测的用例为例,阐述了机器学习模型量产化的具体实现:当有人调用客户服务时,在系统服务中便可以查找到一个静态统计值,但是如果对于特定的事件,系统则需要获得一些额外的值,模型需要利用这些额外的值重新运行。
通常,有多种方法将模型训练成产品:
- 训练:一次性训练、批量训练和实时训练/在线训练.
- 服务:批训练、实时训练 (数据库触发器、Pub/Sub、Web服务、inApp)
每种方法都有各自的优劣,需要折中考虑。
一次性训练
模型在量产化之前,无需进行连续的多次训练,通常情况下,数据科学家对模型点对点训练之后,即可使之量产化,等到模型的性能下降,再对它进行更新。

从Jupyter到Prod
通常,数据科学家会在 Jupyter Notebooks环境中组建原型和机器学习,实际上 Jupyter Notebooks是 repl上的高级GUI,可以在这个环境中同时保存代码和命令行输出。
采用这种方法,完全可以将一个经过特别训练的模型从Jupyter中的某个代码推向量产。多种类型的库和其他笔记本环境有助于连接数据科学家工作台和量产化之间的联系。
模型格式
Pickle将python对象转换为比特流,存储到磁盘后,可以重新加载。它提供了一种很好的格式来存储机器学习模型,亦可在python中构建其应用程序。
ONNX为开放式神经网络交换格式,是一种开放格式,支持跨库、跨语言存储和移植预测模型。大多数深度学习库都支持它,同时,sklearn有一个扩展库来将模型转换为ONNX格式。
PMML或预测模型标记语言,是预测模型的另一种交换格式。与ONNX一样,sklearn还有另一个扩展库,用于将模型转换为PMML格式。然而,它的缺点是只支持某些类型的预测模型,PMML从1997年开始出现,大量的应用程序均采用这种格式。例如:像SAP这样的应用程序能够利用PMML标准的某些版本,对于CRM应用程序(如PEGA)也是如此。
POJO和MOJO是H2O.ai的两种导出格式,旨在为Java应用程序提供一个易于嵌入的模型。然而,这两种导出格式指定在H2O平台使用。
训练
对一次性训练的模型,可以由数据科学家对模型进行训练和微调,也可以通过AutoML库进行训练。通过一个容易复制的设置,可将量产化推进到下一个阶段,即:批训练。
批训练
即便模型量产化过程中进行批训练并非完全必要,但通过批训练可连续刷新模型的版本。
批训练受益于AutoML框架,通过AutoML能够自动执行一系列动作,例如:特征处理、特征选择、模型选择和参数优化。AutoML新近的表现一直为最勤奋的数据科学家所用。

LinkedIn帖子
利用它们可以进行更为全面的模型训练,而不是做预训练:简单地重新训练模型的权重。
有多种不同的技术来支持连续的批训练,例如,可以通过多种混合 airflow来管理不同的工作流,可以提供像 tpot这样的AutoM L库,不同的云服务提供商为 AutoML 提供的解决方案,并把这些解决方案放到数据工作流中。Azure 将机器学习预测和模型训练与他们的数据工厂集成到了一起。
实时训练
通过“在线机器学习”模型可以实现实时训练,支持这种训练方法的算法包括:K-均值(通过小批处理)、线性回归和Logistic回归(利用随机梯度下降)以及朴素贝叶斯分类器。
Spark中包含 StreamingLinear算法/StreamingLinearRegressionWithSGD算法来执行这些操作,Skinlear具有SGDRegressor和SGD分类器,可实现增量训练。在sklearn中,增量训练通过partial_fit方法完成,如下所示:
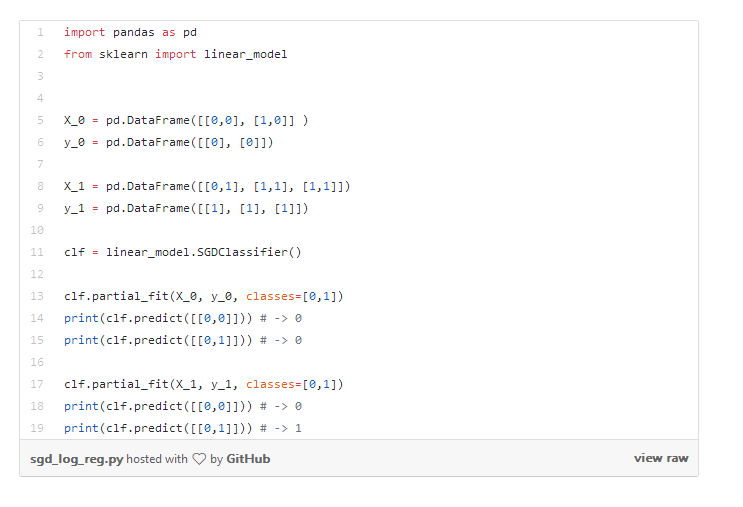

在部署这种类型的模型时,需要有严格的操作支持和监控,因为模型对新的数据和噪声很敏感,所以需要动态地监控模型的性能。在离线训练中,可以过滤掉高位的点值,并对输入数据进行校正。当需要根据新的数据流不断更新模型训练时,难度系数会高出许多。
在线模型训练的另一个挑战是,过往历史信息得不到衰减。 这意味着,如果数据集的结构有新的变化,则需要重新对模型训练,这在模型生命周期管理中将是一个很大的挑战。
批量预测与实时预测的比较
当选择是设置批量预测还是设置实时预测时,必须了解实时预测的重要性。当有重大事件发生时,可能会获得新的分数,例如当客户呼叫联络中心时,客户流失评分又会是多少。在实时预测时,需要对这些因素进行加权,以克服由于进行实时预测而产生的复杂性和成本影响。
载荷的影响
在进行实时预测时,需要有一种处理高峰负荷的方法。需要根据所采用的途径以及使用的预测如何结束,来选择一种实时方法,可能还需要有具有额外计算能力的超级机器,以便在某个SLA中提供预测。这与批量预测的处理方法形成了对比,在批量预测中,可以根据可用容量将预测计算分散到一整天。
架构的影响
在实时预测时,运营责任会更高一些,需要对系统是如何工作进行监测,出现问题时有告警,并考虑到故障转移责任。 对于批量预测,运营责任要低得多,只需要需要对告警进行一些必要的监测,需要了解产生问题的直接原因的几率要低得多。
成本的影响
实时预测也受成本的影响,追求更大的计算能力,无法在全天分散载荷,这些因素可能会迫使你购买更高计算能力硬件设备。根据所采用的实现途径的特殊需求,还可能需要投入额外的成本,需要更强大的计算能力才能满足SLA。此外,在选择实时预测时,可能会有更高的架构要求。这里有一个附加的说明,即预测方式的选择取决于应用程序,对于特定的场景,实时预测的成本最终可能会比批量预测的成本更低。
评估的影响
实时预测的预测性能评估比批量预测的预测性能评估更具挑战性。例如,当在短时间内遇到一连串的突发行为时,如何评估性能,会不会为特定的客户产生多个预测结果?实时预测模型的评估和调试要复杂得多,它还需要一个日志收集机制,既允许收集不同的预测结果和特征,也可以生成分数以供进一步评估。
批量预测集成
批量预测依赖于两个不同的信息:一个是预测模型,另一个是提供给模型的特征。在大多数批处理预测体系结构中,ETL既可以从特定的数据存储(特征存储)中获取预先计算的特征,也可以跨多个数据集执行某种类型的转换,以向预测模型提供输入。然后,预测模型迭代数据集中的所有行,输出不同的分值。
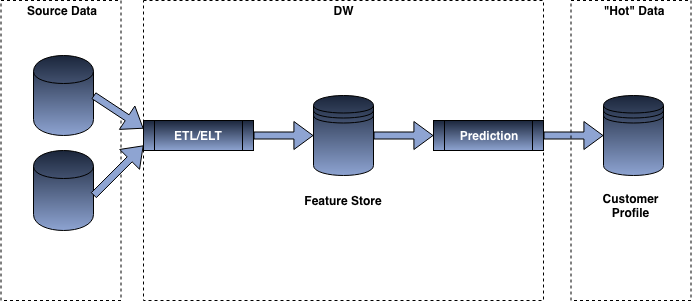

用于批量预测的示例流模型
一旦所有的预测都被计算出来,便可以将分数“提供服务”给想要消耗信息的不同系统。这可以根据想要使用分数的不同用例的需求,通过不同的方式来实现,例如,如果想在前端应用程序上使用分数,则很可能将数据推送到“缓存”或NoSQL数据库:比如Redis,这样可以提供毫秒的响应;而对于某些用例,比如创建电子邮件,可能只是依赖CSV SFTP导出或将数据加载到更传统的RDBMS。
实时预测集成
将模型进行实时应用的量产化需要3个基本组件:客户/用户配置文件、一组触发器和预测模型。


配置文件:客户配置文件包含和客户相关的所有属性,以及给出预测所必需的不同属性(例如:计数器)。对于客户级预测,为了减少从多个地方提取信息的延迟,以及简化机器学习模型的量产化过程,配置文件是必须的。在大多数情况下,为了更有效地获取数据,需要相似的数据存储类型。
触发器:触发器是引导进程启动的事件,它们可以用于客户流失的预测,例如调用客户服务中心、检查订单历史记录中的信息等。
模型: 模型需要经过预先训练,通常导出到前面提到的 3 种格式之一 (pickle、 ONNX 或 PMML) ,以便可以很容易地将其移植到量产中。
有许多不同的方法可以将模型应用于评分目的的产品中去:
- 取决于数据库集成:诸多数据库供应商为在数据库中绑定高级分析用例做出了重大努力,既可以直接集成Python或R代码,也可以导入PMML模型。
- 利用Pub/Sub模型:预测模型本质上是对数据流的输入执行某些操作,例如:提取客户配置信息等。
- Webservice:围绕模型预测设置API封装器,并将其部署为Web服务。根据Web服务的设置方式,它可能执行或不执行驱动模型所需的数据操作。
- inApp:也可以将模型直接部署到本地或Web应用程序中,并让模型在本地或外部数据源上运行。
数据库集成
如果数据库的总体大小不大 (用户配置文件<1M),并且更新频率也不大,那么将一些实时更新过程直接集成到数据库中会很有意义。
Postgres允许将Python代码作为函数或称为PL/Python的存储过程来运行。该实现可以访问PYTHONPATH的所有库,还可以使用Pandas和SKLearning等库来运行某些操作。
还可以与Postgres的触发器机制相结合,以执行数据库的运行并更新客户流失分数。例如,如果在投诉表中输入了一个新条目,那么让模型实时重新运行便很有价值。
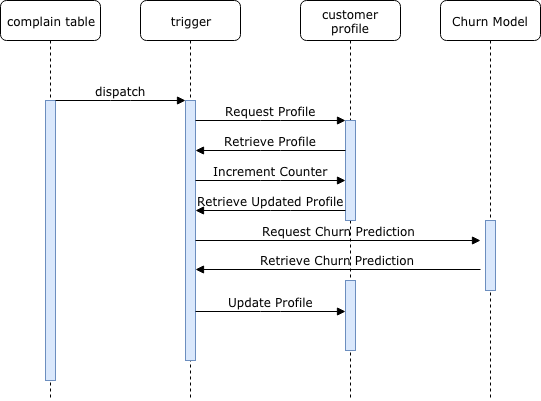

流程
流程以如下方式设置:
新事件: 当在投诉表中插入新行时,将生成事件触发器。
触发器: 触发器功能将更新该客户在客户配置文件表中提出的投诉数量,并为客户更新记录。
预测请求:它将通过PL/Python重新运行客户流失模型并检索预测结果。
用户配置文件的更新:根据更新后的预测结果重新更新客户配置文件。然后,当检查客户配置文件是否已经用更新后的客户流失预测值时,就会生成下游流。
技术
Different databases are able to support the running of多种数据库支持Python脚本的运行,如前所述, Postgres集成有本地Python, MSSQL Server也可以通过其“机器学习服务(在数据库中)”运行R/Python脚本,诸如Teradata等其他数据库可以通过外部脚本命令运行R/Python脚本。Oracle通过其数据挖掘扩展支持PMML模型。
Pub/Sub
通过pub/sub模型实现实时预测,可以通过节流正确地处理负载。对于工程师而言,这也意味着可以通过一个单独的“日志”提要来输入事件数据,不同的应用程序均可以订阅这个提要。
设置示例:


页面视图事件被触发到特定的事件主题,在该主题中,两个应用程序订阅一个页视图计数器和一个预测。这两个应用程序都从主题中筛选出特定的相关事件,并在该主题中使用不同的消息。页面查看计数器为仪表板提供数据,而预测应用程序则负责更新客户配置文件。


流程:
事件消息在发生时被推送到pub/sub主题,预测应用程序会轮询新消息的主题。当预测应用程序检索到新消息时,它将请求并检索客户配置文件,并使用消息和配置文件信息进行预测,预测结果最终推回客户配置文件以供进一步使用。
还可以设置一个稍微不同的流程:数据首先被一个“富集应用程序”使用,该应用程序将配置文件信息添加到消息中,然后将其推回一个新主题,最终由预测应用程序使用,推送到客户配置文件上。
技术:
您会发现,在数据生态系统中支持这种用例的典型的开源组合是Kafka和SPark流的组合,但是云上可能有不同的设置。值得注意的是:Google发布的pub-sub /数据流(BEAM)提供了一个很好的替代方案,在Azure上,Azure-Service总线或Eventub和Azure函数的组合可以作为一种很好的方式来利用消息生成这些预测。
网络服务Web Service
还可以将模型作为Web服务实现到产品中。将预测模型实现为web服务对于工程团队尤为有用,这些团队需要处理Web、桌面和移动等多个不同的接口。
可以有多种方式设置Web服务的接口:
- 提供标识符,然后让web服务提取所需的信息,计算预测值,然后返回其值
- 或者通过接受有效载荷,将其转换为数据帧,进行预测并返回其值。
当发生大量交互,并且使用本地缓存与后端系统的同步,或者当需要在不同的粒度上进行预测时,比如:在进行基于会话的预测时,通常建议使用第二种方法。
使用本地存储的系统往往具有还原功能,其作用是计算客户配置文件的内容,因此,它提供了基于本地数据的客户配置文件的近似值。
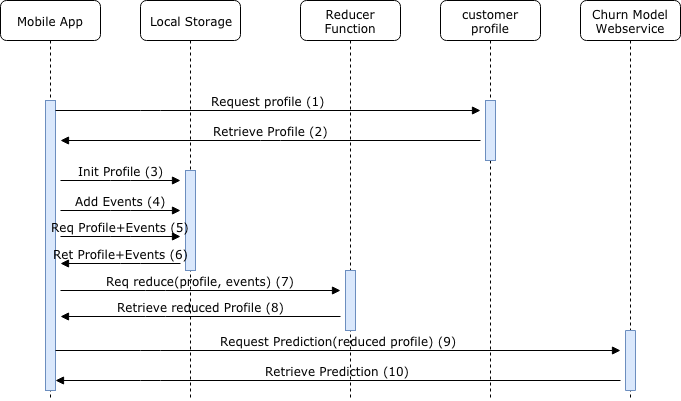

流程
使用移动应用程序处理预测的流程可分为4个阶段进行描述。
应用程序初始化(1至3)阶段:应用程序初始化,向客户配置文件发出请求,检索其初始值,在本地存储中初始化配置文件。
应用程序(4)阶段:应用程序将与应用程序发生的不同事件存储到本地存储区的数组中。
预测准备阶段(5-8):如果应用程序想要检索一个新的客户流失预测,为此它需要将提供给Web服务(Web-service)的信息准备好。首先,它对本地存储进行初始请求,以检索客户配置文件的值及其存储的事件数组。检索完成后,将这些值作为参数它传递给还原器函数,还原器函数输出一个更新后的客户配置文件,并将本地事件合并到这个客户配置文件中。
Web服务预测阶段(9至10):应用程序向客户流失预测的web-service发出请求,将第8步骤中的有效载荷提供给更新后的客户配置文件。然后,web-service可以使用载荷提供的信息生成预测并将其值输出给应用程序。
技术
有很多技术可以用来支持web-service预测:
函数
AWS Lambda函数、GoogleCloud函数和MicrosoftAzure函数(尽管目前只支持Beta版Python)提供了一个易于设置的界面,可以轻松地部署可伸缩的Web服务。
例如,在Azure上,可以通过如下函数实现web-service预测:

容器
除了函数之外的另一种选择是通过docker容器(AmazonECS、Azure容器实例或Google Kubernetes引擎)部署一个Flask或Django应用程序。例如,Azure通过其“AzureMachineLearning服务”提供了一种简单的方法来设置预测容器。
笔记簿
不同的笔记薄提供商,如Databricks和dataiku,都致力于简化其环境中的模型部署。它们具有将webservice设置到本地环境或部署到外部系统(如Azure ML服务、Kubernetes引擎等)的功能。
应用程序内部
在某些情况下,当存在因为法律和隐私的要求,不允许数据被存储在应用程序外部时,或者存在诸如必须上传大量文件的约束时,往往会在应用程序内部调用模型。
Android-MLKit或Caffe2类似的工具允许在本地应用程序中调用模型,而Tensorflow.js和ONNXJS允许直接在浏览器中或在JavaScript的应用程序中运行模型。
需要综合考虑的几点
除了模型的部署方法外,部署模型到量产时需要考虑以下重要因素。
模型的复杂度
模型本身的复杂程度,是应首先要考虑的因素。像线性回归和Logistic回归这样的模型非常容易部署,通常不会占用太多的存储空间。使用更为复杂的模型,如神经网络或复杂集成决策树,将花费更多的时间用于计算,在冷启动时加载到内存中的时间会更长一些,而且运行成本也会更高。
数据来源
需要着重考虑的是用于量产化的数据源与用于训练的数据源之间可能存在的差异。虽然用于训练的数据必须与生产中实际使用数据内容同步,但是重新计算每个值以使其完全同步是不切实际的。
实验框架
建立一个实验框架,用于客观度量不同模型性能的A/B测试,并确保有足够的跟踪,以准确地调试和评估模型的性能。
小结
选择如何将预测模型部署到生产中是一件相当复杂的事情,可以有多种不同的方法来处理预测模型的生命周期管理,也可以用不同的格式来存储它们,从多种方法中选取恰当的方法来部署模型,包含非常宽泛的技术含量。
深入理解特定的用例、团队的技术和分析成熟度、整体组织结构及其交互,有助于找到将预测模型部署到生产中的正确方法。

来一张经典的图:

源自 "Looking Backwards, Looking Forwards: SAS, Data Mining, and Machine Learning."Subconscious Musings. N.p.,n.d. Web. 2014.
简单来讲,人工智能包括机器学习、心理学、哲学、认知科学、生物学、信息学等各大学科;而机器学习则包括深度学习。

小编提供一些数据 行行查 | 行业研究数据库 供参考:
人工智能(AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,用来生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。对于人工智能的智能程度,分为弱人工智能(ANI)、强人工智能(AGI)和超强人工智能(ASI)。弱人工智能 是指专注于且只能解决单个特定领域问题的人工智能。强人工智能 是指能够胜任人类所有工作的人工智能。超强人工智能是指在科学创造力、智能和社交能力等每一个方面都比最强人类大脑聪明的人工智能。人工智能具有算力、算法、数据三大要素,其中基础层提供算力支持,通用技术平台解决算法问题,场景化应用挖掘数据价值。


机器学习是人工智能的一个子集,人工智能的范畴还包括自然语言处理、语音识别等方面。机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习于1959年提出,指研究和构建一种特殊算法(非某一个特定的算法,包括深度学习),能够让计算机自己在数据中学习从而进行预测,实现算法进化,从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
机器学习任务主要包括监督学习、无监督学习、概率图模型和强化学习。监督学习的训练中数据是有标签的,即每一个输入变量都有对应的输出变量。模型旨在通过建立输入变量和输出变量之间的关系,来预测输出变量。可以根据输出变量的类型对监督学习进行划分。如果输出变量是定量的,那就是回归问题;如果输出变量是定性的,那就是分类问题。无监督学习中,数据集并没有对应的标签,可粗略划分为聚类和降维。概率图模型以Bayes学派为主。强化学习是让模型以“试错”的方式在一定的环境中学习,通过与环境交互获得对应的奖励,目标是使得到的奖励最大化,例如交易策略的学习。


可点击下方 行行查 链接查看相关行业研究报告
欢迎评论、点赞、收藏和转发! 有任何喜欢的行业和话题也可以私信我们。