大数据分析中,有哪些常见的大数据分析模型?
89 个回答

常见数据分析模型较多,列举其中常见的八种供楼主参考:
1、行为事件分析
行为事件分析法来研究某行为事件的发生对企业组织价值的影响以及影响程度。企业借此来追踪或记录的用户行为或业务过程,如用户注册、浏览产品详情页、成功投资、提现等,通过研究与事件发生关联的所有因素来挖掘用户行为事件背后的原因、交互影响等。
在日常工作中,运营、市场、产品、数据分析师根据实际工作情况而关注不同的事件指标。如最近三个月来自哪个渠道的用户注册量最高?变化趋势如何?各时段的人均充值金额是分别多少?上周来自北京发生过购买行为的独立用户数,按照年龄段的分布情况?每天的独立 Session 数是多少?诸如此类的指标查看的过程中,行为事件分析起到重要作用。
行为事件分析法具有强大的筛选、分组和聚合能力,逻辑清晰且使用简单,已被广泛应用。行为事件分析法一般经过事件定义与选择、下钻分析、解释与结论等环节。
2、漏斗分析模型
漏斗分析是一套流程分析,它能够科学反映用户行为状态以及从起点到终点各阶段用户转化率情况的重要分析模型。
漏斗分析模型已经广泛应用于流量监控、产品目标转化等日常数据运营工作中。例如在一款产品服务平台中,直播用户从激活APP开始到花费,一般的用户购物路径为激活APP、注册账号、进入直播间、互动行为、礼物花费五大阶段,漏斗能够展现出各个阶段的转化率,通过漏斗各环节相关数据的比较,能够直观地发现和说明问题所在,从而找到优化方向。对于业务流程相对规范、周期较长、环节较多的流程分析,能够直观地发现和说明问题所在。
3、 留存分析模型
留存分析是一种用来分析用户参与情况/活跃程度的分析模型,考察进行初始行为的用户中,有多少人会进行后续行为。这是用来衡量产品对用户价值高低的重要方法。留存分析可以帮助回答以下问题:
一个新客户在未来的一段时间内是否完成了您期许用户完成的行为?如支付订单等;某个社交产品改进了新注册用户的引导流程,期待改善用户注册后的参与程度,如何验证?想判断某项产品改动是否奏效,如新增了一个邀请好友的功能,观察是否有人因新增功能而多使用产品几个月?关于留存分析,我写过详细的介绍文章,供您参考: 解析常见的数据分析模型——留存分析。
4、分布分析模型
分布分析是用户在特定指标下的频次、总额等的归类展现。它可以展现出单用户对产品的依赖程度,分析客户在不同地区、不同时段所购买的不同类型的产品数量、购买频次等,帮助运营人员了解当前的客户状态,以及客户的运转情况。如订单金额(100 以下区间、100 元 - 200元区间、200 元以上区间等)、购买次数(5 次以下、5 - 10次、10 以上)等用户的分布情况。
分布分析模型的功能与价值:科学的分布分析模型支持按时间、次数、事件指标进行用户条件筛选及数据统计。为不同角色的人员统计用户在一天/周/月中,有多少个自然时间段(小时/天)进行了某项操作、进行某项操作的次数、进行事件指标。
5、点击分析模型
即应用一种特殊高亮的颜色形式,显示页面或页面组(结构相同的页面,如商品详情页、官网博客等)区域中不同元素点击密度的图示。包括元素被点击的次数、占比、发生点击的用户列表、按钮的当前与历史内容等因素。
点击图是点击分析方法的效果呈现。点击分析具有分析过程高效、灵活、易用,效果直观的特点。点击分析采用可视化的设计思想与架构,简洁直观的操作方式,直观呈现访客热衷的区域,帮助运营人员或管理者评估网页的设计的科学性。
6、用户行为路径分析模型
用户路径分析,顾名思义,用户在APP或网站中的访问行为路径。为了衡量网站优化的效果或营销推广的效果,以及了解用户行为偏好,时常要对访问路径的转换数据进行分析。
以电商为例,买家从登录网站/APP到支付成功要经过首页浏览、搜索商品、加入购物车、提交订单、支付订单等过程。而在用户真实的选购过程是一个交缠反复的过程,例如提交订单后,用户可能会返回首页继续搜索商品,也可能去取消订单,每一个路径背后都有不同的动机。与其他分析模型配合进行深入分析后,能为找到快速用户动机,从而引领用户走向最优路径或者期望中的路径。
7、用户分群分析模型
用户分群即用户信息标签化,通过用户的历史行为路径、行为特征、偏好等属性,将具有相同属性的用户划分为一个群体,并进行后续分析。我们通过漏斗分析可以看到,用户在不同阶段所表现出的行为是不同的,譬如新用户的关注点在哪里?已购用户什么情况下会再次付费?因为群体特征不同,行为会有很大差别,因此可以根据历史数据将用户进行划分,进而再次观察该群体的具体行为。这就是用户分群的原理。
8、属性分析模型
顾名思义,根据用户自身属性对用户进行分类与统计分析,比如查看用户数量在注册时间上的变化趋势、查看用户按省份的分布情况。用户属性会涉及到用户信息,如姓名、年龄、家庭、婚姻状况、性别、最高教育程度等自然信息;也有产品相关属性,如用户常驻省市、用户等级、用户首次访问渠道来源等。
属性分析模型的价值是什么?一座房子的面积无法全面衡量其价值大小,而房子的位置、风格、是否学区、交通环境更是相关的属性。同样,用户各维度属性都是进行全面衡量用户画像的不可或缺的内容。
属性分析主要价值在:丰富用户画像维度,让用户行为洞察粒度更细致。科学的属性分析方法,可以对于所有类型的属性都可以将“去重数”作为分析指标,对于数值类型的属性可以将“总和”“均值”“最大值”“最小值”作为分析指标;可以添加多个维度,没有维度时无法展示图形,数字类型的维度可以自定义区间,方便进行更加精细化的分析。
注意:点击每个分析模型的标题,可跳转至详解。也可进入个人主页,有视频讲解和资料赠送。

泻药!之前我吐血整理数据分析师需要掌握的35个分析模型,包括分析企业机会、优劣、挑战的SWOT模型;分析企业管理及执行分析的5W2H模型;用户价值分析的RFM模型等,让你快速上道。 链接在此 内容很丰富,请认真看。
今天基于题主的互联网产品,我来详细介绍几个会频繁使用的分析模型。看完就会用啦
一、消费者行为分析:AIDA模型
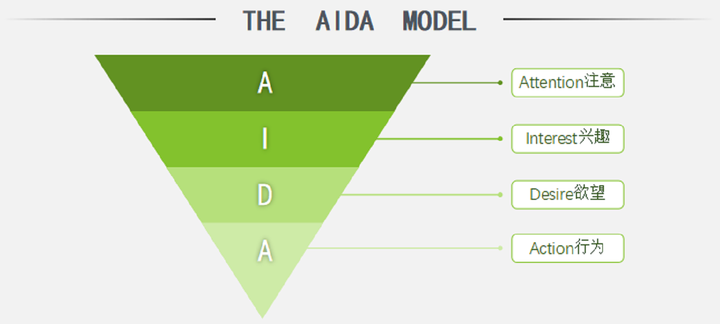

AIDA是4个英文单词的首字母,分别指Attention注意、Interest兴趣、Desire欲望、Action行为。模型的意思是,当你希望用户购买你的产品或服务时,你应该先吸引他的注意力,再引起他的兴趣,然后勾起他的欲望,最终促成他的行动。
比如说,拼多多的广告,就用一支非常洗脑的广告神曲引起了你的注意,然后用“3亿人都在用”这样的广告词勾起你的兴趣,继而又用便宜的价格激发你购买的欲望,最后用一些限时拼单等等有紧迫感的活动,促进你下单。
二、用户增长:AARRR模型
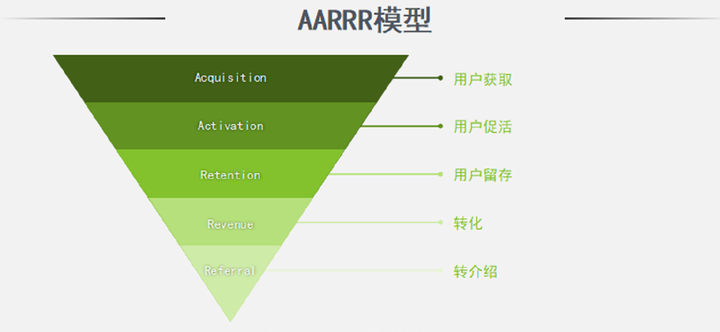

近年来,在互联网领域异常火爆的模型,又被称为海盗模型。AARRR,实际上是5个英文单词的首字母,分别代表了Acquisition用户获取、Activation促活、Retention用户留存、Revenue转化、Referral转介绍这5个步骤。


以淘宝来举例,说明这个模型。你通过各种广告得知了淘宝,并下载注册了淘宝账号,这个呢就叫用户获取。注册之后,淘宝会通过推送通知消息、短信等,来不断刺激你登录,这就叫用户促活,主要目的就是希望你不要注册了就再也不为。然后淘宝还会通过各种内容,比如直播、会员等形式,来增强你和淘宝的粘性,这个叫用户留存。接着,它还会根据算法,推荐你喜欢的商品,或者推送优惠信息,促使你下单,这个叫转化。最后,淘宝还通过推出分享等功能,来激发你把平台上的商品转发出去,以带来新用户,这个叫做转介绍。

三、营销广告投放模型
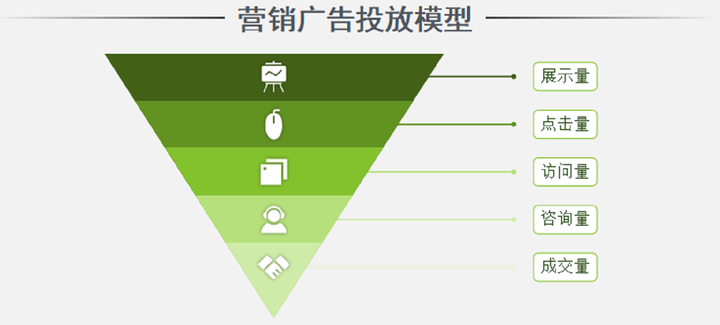

过去在广告营销界流传着这样一句话:“我知道花在广告上的钱,有一半是浪费的,问题是,我不知道是哪一半。”
这种情况,在如今这个时代,已经越来越少了。每一个推广渠道,都能看见曝光量、用户点击量、用户注册量,甚至购买量等等。市场人员可以通过各个渠道的数据追踪和分析,及时优化渠道的选择和广告内容。根据这个营销漏斗定位问题,要么优化产品的落地页、要么增强目标投放人群筛选的精准度等,把广告花在优质的、有效的渠道上。
数据分析方法论的作用:
- 理顺分析思路,确保数据分析结构体系化
- 把问题分解成相关联的部分,并显示他们的关系
- 为后续数据分析的开展指引方向
- 确保分析结果的有效性和正确性
当然,最后还是要说,模型只是前人总结出的方式方法,对于我们实际工作中解决问题有引导作用,但是不可否认,具体问题还要具体分析,针对不同的情况需要进行不同的改进,希望成为一个数据专家,最重要的一点还是多实践!实践才是真理!
关于亿信华辰
亿信华辰是中国专业的智能数据产品与服务提供商,一直致力于为政企用户提供从数据采集、存储、治理、分析到智能应用的智能数据全生命周期管理方案,帮助企业实现数据驱动、数据智能,已积累了8000多家用户的服务和客户成功经验,为客户提供数据分析平台、数据治理系统搭建等专业的产品咨询、实施和技术支持服务。


欢迎关注 @亿信华辰 ,让数据驱动进步~

数据分析模型比较多,这里介绍互联网平台最常用、也最实用的 9 大模型
(一)事件分析模型
事件指的是用户操作产品的一个行为,即用户在产品内做了什么事情,转义成描述性语言就是“操作+对象”。事件分析是对用户行为事件的指标进行统计、维度细分、筛选等分析操作。

事件分析能解决什么问题:
- 产品和运营同学如何才能对网站每天的 PV、UV、DAU 等总体数据有一个直观的把握,包括它们的数值以及趋势?
- 面对复杂的数据,单从数字来看,不仅效率低下,而且难以直观的发现数据背后所展现的趋势,应该怎么办?
- 当做了第三方付费渠道推广后,运营同学如何才能有效比较不同渠道带来的流量?
知有福利:更多电子书 点击领取
GrowingIO 电子书下载中心-数据分析-增长黑客
(二)分布分析模型
产品优化和运营是一个动态的过程,我们需要不断监测数据,调整产品设计或运营方法,然后继续监测效果。
分布分析功能,主要用来了解不同区间事件发生频次,不同事件计算变量加和,以及不同页面浏览时长等区间的用户数量分布。


主要使用场景1:频次分布
Alice是某个电商产品经理,比较关注"用户浏览商品详情页"的以下几个场景:
- 希望了解最近一周浏览商品详情页的用户,例如1-5次, 6-10次 ... 不同区间的用户量分布有多少;
- 希望知道最近一段时间内,每日用户浏览商品详情页人均数量、最大值、最小值、中位数(50%浏览商品详情页的用户浏览小于等于多少页)、25分位(25%浏览商品详情页的用户浏览小于等于多少页)、75分位(75%浏览商品详情页的用户浏览小于等于多少页)的趋势;
- 希望对比渠道来源A\B\C三个主要广告渠道带来的用户,浏览商品详情页1-5次;6-10次等等不同区间的用户量分布分别有多少;
- 希望对比"高消费"和"低消费"的两个用户群体浏览商品详情页1-5次, 6-10次, ... , 不同区间的用户量分布分别有多少。
(三)用户分群模型
用户分群,就是通过一定的规则找到对应的用户群体。 常用的方法包括:
- 找到做过某些事情的人群:比如过去 7 天完成过 3 次购物车计算
- 有某些特定属性的人群:比如年龄在 25 岁以下的男性
- 在转化过程中流失的人群:比如提交了订单但没有付款
您可以根据自己要解决的业务问题,来定义关注的用户群体,还可以在 GrowingIO 平台中通过将分群套用在事件分析、漏斗分析与留存分析等分析工具中进一步分析;或者通过运营手段对这部分人群进行运营。
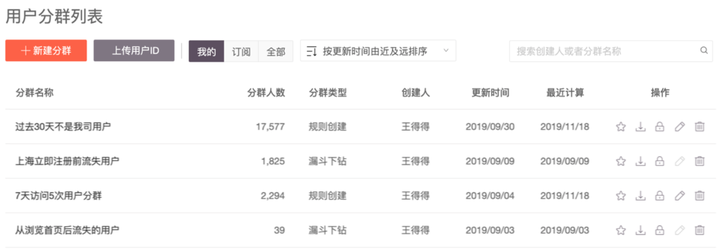

比如在考虑注册转化率的时候,需要区分移动端和 Web 端,以及美国用户和中国用户等不同场景。这样可以在渠道策略和运营策略上,有针对性地进行优化。
(四)漏斗分析模型
漏斗分析是一套流程式的数据分析模型,通过将用户行为起始的各个行为节点作为分析模型节点,来衡量每个节点的转化效果,是转化分析的重要工具。
通过漏斗分析可以从先到后的顺序还原某一用户的路径,分析每一个转化节点的转化数据;
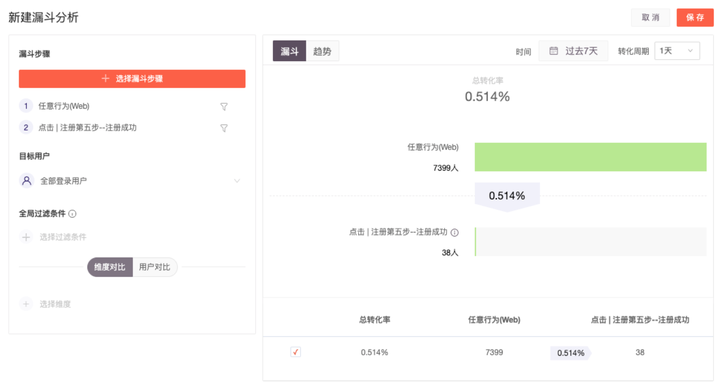

所有互联网产品、数据分析都离不开漏斗,无论是注册转化漏斗,还是电商下单的漏斗,需要关注的有两点。第一是关注哪一步流失最多,第二是关注流失的人都有哪些行为。
关注注册流程的每一个步骤,可以有效定位高损耗节点。
(五)用户行为轨迹分析
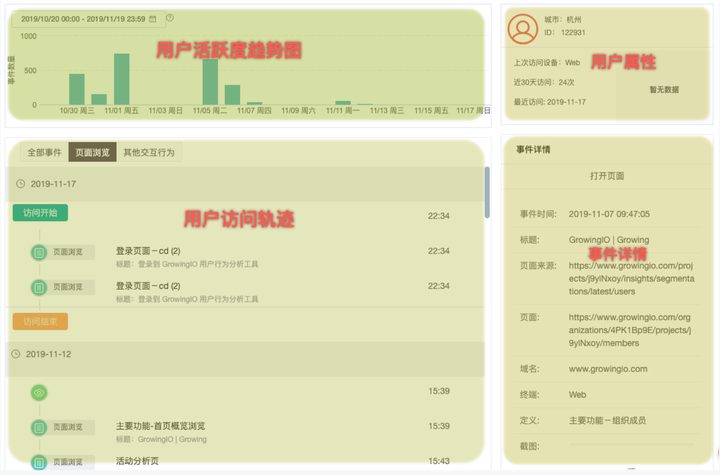

行为轨迹是进行全量用户行为的还原。只看 PV、UV 这类数据,无法全面理解用户如何使用你的产品。了解用户的行为轨迹,有助于运营团队关注具体的用户体验,发现具体问题,根据用户使用习惯设计产品,投放内容。
(六)留存分析模型
留存,顾名思义,就是用户在你的产品中留下来、持续使用的意思。
留存为什么重要?留存是 AARRR 模型中重要的环节之一,只有做好了留存,才能保障新用户在注册后不会白白流失。有时候我们光看日活(DAU),会觉得数据不错,但有可能是因为近期有密集的推广拉新活动,注入了大量的新用户,但是留下来的用户不一定在增长,可能在减少,只不过被新用户数掩盖了所以看不出来。这就好像一个不断漏水的篮子,如果不去修补底下的裂缝,而只顾着往里倒水,是很难获得持续的增长的。
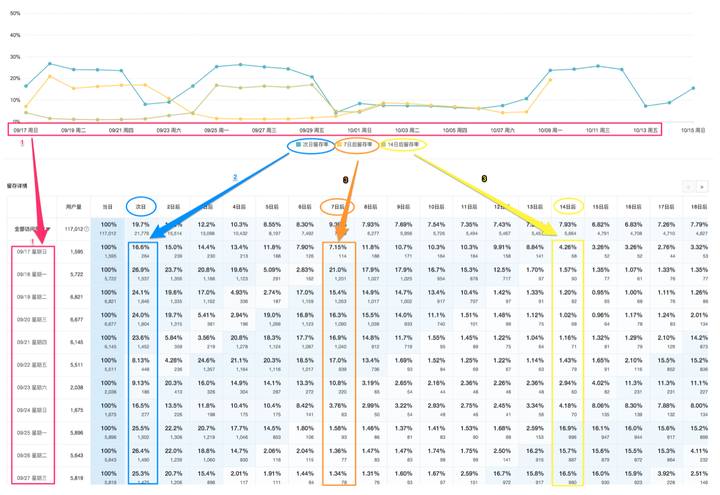

一般我们讲的留存率,是指「目标用户」在一段时间内「回到网站/App 中完成某个行为」的比例。常见的指标有次日留存率、七日留存率、次周留存率等。比如:某个时间获取的「新用户」 的 「次日留存率」常用来度量拉新效果。
(七)热图分析
热图是以网站页面中的元素的点击率(元素点击次数/当前页面 PV)为基础的数据的图形表示。通过聚合用户行为,热图可以让人一目了然地了解人们如何与网站页面进行交互,这有助于识别用户行为趋势并优化进一步流程。 您的网站存在以便人们可以实现特定的目标,如查找信息、注册服务、购买产品等。当人们进入您的网站但很难找到或使用他们正在寻找的东西时,他们会感到沮丧,最糟糕的情况是,他们离开你的网站不再回来。
为了让用户在访问中停留下来并进行下一步动作,也许您在关心这些问题:
- 用户是否点击了我们希望互动的内容?
- 有没有重要按钮或元素被大量点击,却被放到了不起眼的地方?
- 用户感兴趣的内容是否和我们预想的一样?
- 不同的运营位、不同的内容对用户的吸引分别是怎样的?
- 具体元素的点击数据如何?
- 不同渠道的访问者对于页面的关注点具备哪些差异和特征?
- 从重要元素的点击来看,哪个渠道质量更好?
- 「未转化」的用户与「转化」用户之间的热图表现差异如何?
热图提供了一种清晰直观的方式来帮助您解答这些问题。


(八)温度-健康度模型
通过客户的“温度-健康度模型”实现用户分群。下图的横坐标“健康指数”代表用户的活跃度;纵坐标的“温度指数”代表用户转化的可能性。
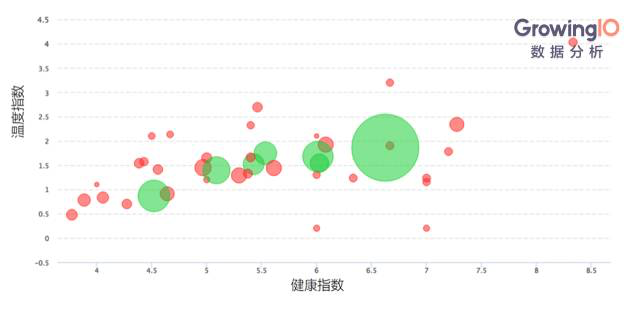

该模型一般用户企业级 SaaS 企业中的客户成功部门。有了该模型,我们就可以对不同分群的用户进行差异化的运营策略。左上角的用户活跃度不高,但是付费转化的可能性很高;我们需要对用户加强培训,提高其使用频率。右下角的用户非常活跃,但是付费的可能性很低,值得我们深入思考背后的原因。
(九)归因分析模型
归因分析要解决的问题就是广告效果的产生,其功劳应该如何合理的分配给哪些渠道。常见的归因分析方法有:线性归因、首次归因、末次归因、基于位置归因、时间衰减归因等。
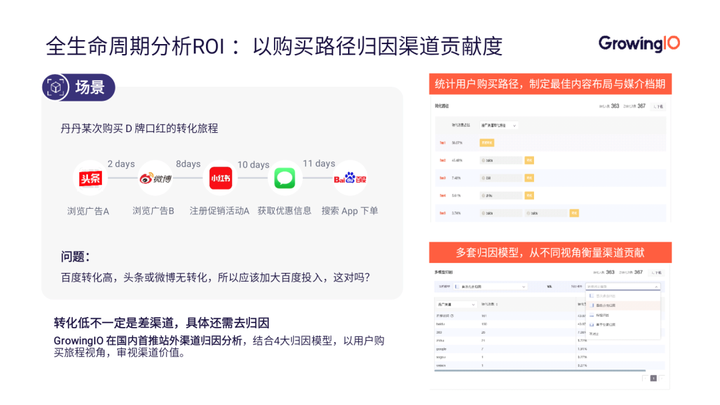

我们可以根据自己业务的实际情况,选择归因模型。
假设一个丹丹购买口红的场景,在依次浏览了头条、微博上的广告后,她参加了小红书上的注册促销活动,又收到了优惠券,于是在百度上搜索 App,完成下单购买。
如果按照 ROI 分析的逻辑,我们会把所有的权重算在百度这一渠道上,这是典型的以偏概全。
知友福利: 点击免费试用 GrowingIO,体验快速自定义生成各种数据分析模型



目录
- 评价类模型
- 预测类模型
- 分类模型
- 优化模型
一、评价类模型
评价类模型一般包括权重计算和进行综合评价对比,分析前搜集原始数据,然后对数据进行预处理,比如标准化,正向化逆向化等等,一般评价类模型,需要将计算权重的模型和进行综合评价的模型相结合分析,比如熵权topsis法等,计算权重包括主观方法和客观方法,各自有各自的优缺点,但在分析中往往二者相结合进行分析对比更为准确,一般最终目的得到综合评价结果。具体如下:
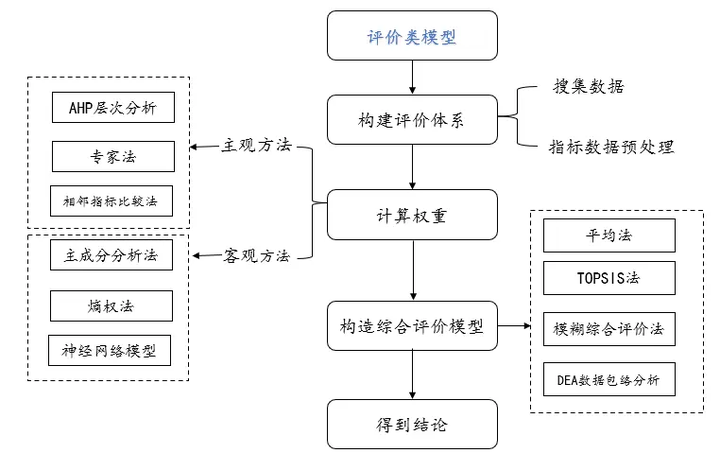

一、权重方法(主观)
主观赋权法是指基于决策者的知识经验或偏好,按重要性程度对各指标进行比较,赋值和计算得出其权重的方法。一般包括层析分析、优序图法、德尔菲法以及环比评分法。
1、层次分析法
层次分析法简称AHP法,其原理是将与决策总是有关的元素分解成目标、准则、方案等层次,在此基础上进行定性和定量分析的决策方法。
AHP法的分析一般有4个步骤:

Step1:分析系统汇总各因素之间的关系,建立系统的层次结构;
Step2:对同一层次的各元素针对上一层次中某一准则的重要性进行两两比较,构造判断矩阵;
Step3:进行专家打分一致性检验(检验通过,结果才会被认可);
Step4:根据矩阵计算得分,得到权重结果;
层次分析法的操作为:
SPSSAU【综合评价】→AHP层次分析;


2、优序图法
优序图法也是主观求权重的一种方法,比如将n个比较因素行、列分别写在n*n的表格中。表格对角线划斜线,其它空余表格进行两两比较,重要的指标写“1”,反之,则写“0”,若写“0.5”则表示同等重要。计算权重时的计算公式如下:
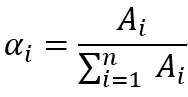
上式中 \alpha_i 为第 i个指标的权重,A_i 为第 i个指标的总得分,n 为指标的个数。
优序图法操作:
SPSSAU【问卷研究】→优序图法;

其一般分析步骤:
第一:计算出各分析项的平均值,接着利用平均值大小进行两两对比;
第二:平均值相对更大时计为1分,相对更小时计为0分,平均值完全相等时计为0.5分;
第三:平均值越大意味着重要性越高(请确保是此类数据),权重也会越高。
其一般结果形式如下:
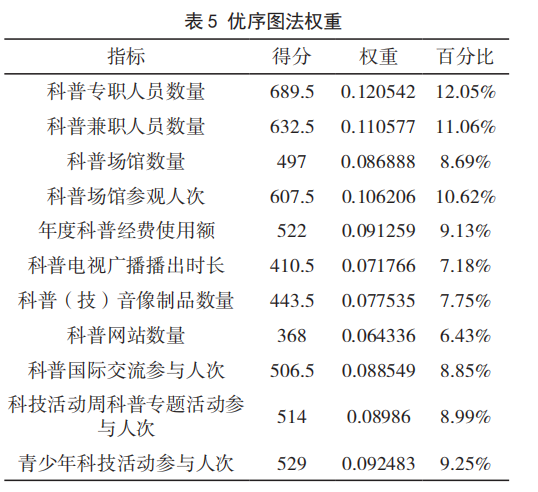

3、德尔菲法
德尔菲专家咨询法是在专家会议法的基础上发展而来的,以函件的形式向专家组征询意见,通过数次的信息交流与反馈修正,逐步使各个专家的意见趋于一致,以获得较高准确率的集体判断结果,德尔菲专家咨询法的可操作性和实用性较强,但是容易受到主观性的影响,所以需要选取对研究领域熟悉且具备一定权威性的专家直观重要,有研究表明,德尔菲专家人数不能低于13名,以15~50名合适。
4、环比评分法
环比评分法简称DARE法,是一种对评价指标进行对比求相对权重的赋权方法,通过对比随机排列的影响指标进行连环对比,专家根据经验知识评定指标间的相对重要程度,来确定指标的权重。
是一种通过各因素相对重要性系数来评价和选择创新方案的方法,此方法根据相邻指标的重要性进行对比打分,并作为暂定重要性系数,而后对暂定重要性系数进行修正,修正重要性系数是暂定重要性系数的倍数关系,最后将各修正重要性系数除以全部修正重要性系数之和,即得各项指标的权重。
此方法的好处是不用过度关注庞大的指标体系,只需对比相邻指标的重要程度。
二、权重方法(客观)
客观赋权法是指基于各方案评价指标值的客观数据差异来确定权重的方法。
1、熵值法
熵值法又称熵权法,是最常用的客观求权重法之一,此类方法利用数据熵值信息即信息量大小进行权重计算,适用于数据之间有波动,同时将数据波动作为一种信息的情况,熵值法借鉴化学熵和信息熵的定义,通过定义各指标的熵值,将评估中各待评估单元信息进行量化和综合,得出各指标比较客观的权重。在数据中,离散程度越大,说明该指标对综合评价的影响越大,在信息论中,信息量越大,不确定性就越小,同时熵也就越小,反之信息量越小,不确定性就越大,熵就越大。
熵值法的数据格式:
熵值法用于指标的权重情况。1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。


熵值法的操作:
SPSSAU【综合评价】→熵值法;


2、CRITIC法
CRITIC权重法基于评价指标的波动性和指标间的冲突性来综合衡量指标的客观权重,在考虑指标变异性大小的同时兼顾指标之间的相关性,完全利用数据自身的客观属性进行科学评价。
- 波动性是指同一个指标各个评价方案之间取值差距的大小,以标准差的形式来表现,标准差越大,说明波动越大,即各方案之间的取值差距越大,权证会越高。
- 指标间的冲突性用相关系数表示,若两个指标之间具有较强的正相关性,说明其冲突性越小,权重会越低
3、主成分和因子法
主成分分析和因子分析计算权重利用了数据的信息浓缩原理,利用方差解释率进行权重计算。主成分分析法是一种多元分析法,它从所研究的全部指标中,通过探讨相关的内部依赖结构,将有关主要信息集中在几个主成分上,因子分析法是对每个指标计算共性因子的累积贡献率来计算权重,累积贡献率越大,说明该指标对共性因子的作用越大,所得到的权重就越大。
- 将原始数据标准化,消除量纲的影响
假设进行主成分分析的指标变量有m个:x1、x2、…、xm,其中有n个评价对象,第i个评价对象的第j个指标的取值为xij,将各指标值转化成标准化指标xij; - 建立变量之间的相关系数矩阵R
- 计算相关系数矩阵R的特征值与特征向量
- 提取主成分并计算权重
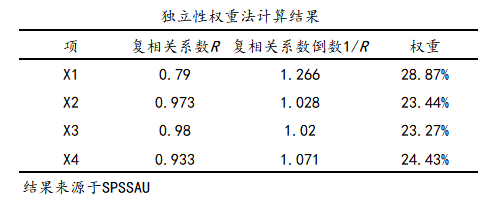
4、独立性权重
独立性权重既能考察数据样本内部的差异性,也能考察各指标之间横向相关性的考量,独立性权重法其实是利用指标间的相关系数来确定指标权重的一种赋权方法,一般来说,某一指标与其它指标的相关系数越大说明信息交叉越严重,在综合评价中的作用就越小,其权重就越小,反之,权重就越大。其数据格式如下:
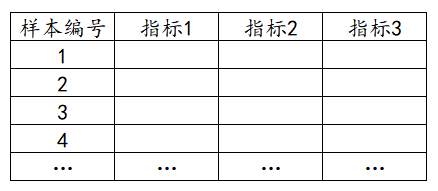

1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,分析时并不需要使用。
SPSSAU操作:

一般结果格式:

5、信息量权重
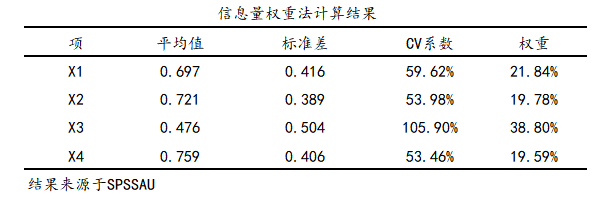
信息量权重赋权法(也是变异系数法)是依据各项指标观测值所提供的信息大小来确定权重,指标数据的离散程度越大(也就是变异系数),该指标对综合评价的影响越大。其权重越大,反之权重越小。其数据格式如下:
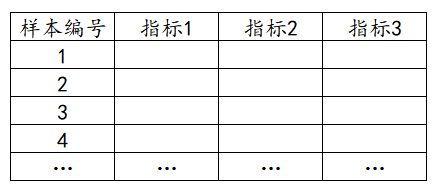

1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,分析时并不需要使用。
SPSSAU操作:

一般结果格式为:

三、综合评价方法
综合评价是指对多属性体系结构描述的对象做出全局性,整体性的评价,在日常生活中,人们做出正确的决策之前往往要对其左右权衡,
1、TOPSIS
该模型原理为在标准化原始矩阵中,找出最好指标和最劣质的指标,分别计算各评价对象与最优指标和最劣指标间的距离,获得各评价对象与最优指标的相对接近程度,以此作为评价优劣的依据。
2、灰色关联法
灰色关联分析作为一种技术方法,是分析系统中各因素关联程度的方法。灰色关联评价系统就是根据所给出的评价标准或比较序列,通过计算参考序列与各评价标准或比较序列的关联度大小,判断该参考序列与哪级比较序列的接近程度来评定该参考序列的等级。
其数据格式如下:
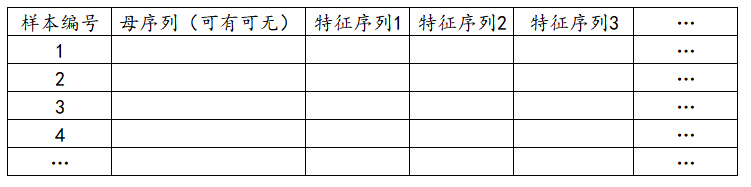

灰色关联法研究数据之间的关联程度,即特征序列与母序列的关联性情况。母序列单独使用一列标识(可选),每个特征序列都使用1列标识。第一列通常是样本编号,比如年份、编号等,分析时并不需要使用。
其操作如下:
SPSSAU【综合评价】→灰色关联法;

其分析步骤如下:
第一步:确定母序列和特征序列,且准备好数据格式;
第二步:针对数据进行无量纲化处理(通常情况下需要);
第三步:求解母序列和特征序列之间的灰色关联系数值;
第四步:求解关联度值;
第五步:对关联度值进行排序,得出结论。
其一般结果如下:


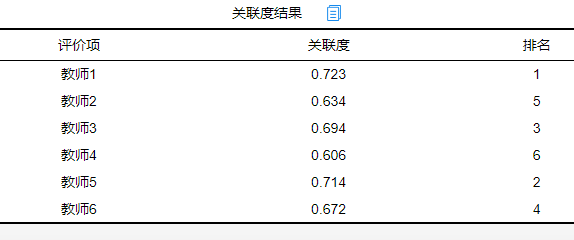

一般会提供关联系数结果以及关联度结果。
3、模糊综合评价
模糊综合评价是基于模糊数据的一种评价方法,其利用模糊数学的隶属度理论,对受若干制约因素的评价对象进行评价,在一定程度上将定性评价变为定量评价。
其数据格式是:
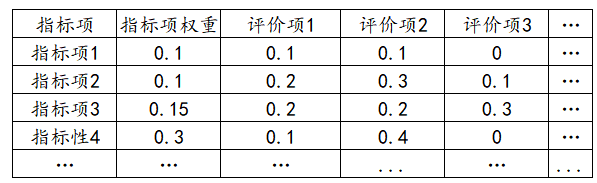

模糊综合评价研究指标项综合来看,应该属于那个评价项。1列放1个评价项(比如不满意、比较不满意、满意、非常满意之类的评价项)。
如果说各个指标项有着自己的权重,那么就需要单独用一列表示‘指标项权重值’,‘指标项权重’是可选项,如果没有此数据,默认各个指标的权重完全一致。指标项不放入分析框内,为什么有指标项,为了便于查看对应的权重。
其操作是:
Spssau综合评价→模糊综合评价;

其分析流程一般为:
分析流程一般有三步:
第一步:确定评价指标和评语集;
第二步:确定权重向量矩阵A和构造权重判断矩阵R;
第三步:计算权重并进行决策评价;
4、数据包络(DEA)
数据包络分析简称DEA,被广泛用于投入产出效率测算问题。DEA是对效率进行评价的非参数方法,它不需要考虑指标量纲与相对权重,也不需要确定决策单元各投入产出之间的显式函数关系,可避免寻求相同度量因素所带来的困难,排除主观因素影响,简化问题,DEA分析方法更适合复杂的效率研究。
使用DEA进行分析,需先确定决策单元(DMU),也就是在分析中将投入转化为相应产出的运营实体,然后根据一定原则选择并设定模型类型与投入及产出指标,即可用该方法来判断各个单元投入与产出的合理性、有效性。
DEA常用的模型有CCR、BBC模型。CCR模型在固定规模报酬假设下衡量综合效率,BCC模型在变动规模报酬假设下衡量纯技术和规模效率。


数据包络DEA操作如下:


5、秩和比法
秩和比法也叫RSR法,其基本原理是在m个评价对象,n个指标的矩阵中,经过秩转换消除单位影响,获得无量纲统计量RSR,并对RSR值排序、分档或统计分析。RSR取值区间位于0-1,RSR值越大表明综合评级越优,秩和比的计算公式为:
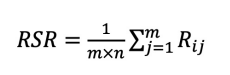
然后,将RSR值从小到大进行排序,确定RSR值的分布频数和平均秩次,计算出向下累计频率。进而计算p值。
一般分析结果:


结果一般会提供档次、百分位临界值、probit临界值、RSR临界值以及对应的改档名词等登。
二、预测模型
预测模型一般包括回归预测模型、时间序列预测模型,灰色预测法、马尔科夫预测、机器学习(神经网络、决策树)等。一般预测模型的流程如下:

时间序列模型
时间序列模型是一种根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。它一般采用曲线拟合和参数估计方法,如非线性最小二乘法,来对时间序列数据进行拟合,从而建立相应的数学模型。适合中长期预测。
参考资料:
SPSSAU:必看!时间序列分析!
灰色预测法
灰色预测模型为小样本预测模型,适合短期预测,其利用微分方程来充分挖掘数据的本质,建模所需信息少,精度较高,运算简便,易于检验,也不用考虑分布规律或变化趋势等。
参考资料:
SPSSAU:超级干货:一文读懂灰色预测模型
马尔科夫预测
马尔科夫预测是一种基于马尔科夫链的预测方法,主要用于预测随机过程未来的状态。这种方法假设一个系统的下一个状态只与前一个状态有关,而与之前的状态无关。
参考资料:
SPSSAU:马尔可夫预测应该如何做?
其它:
SPSSAU:指数平滑指标怎么看?
SPSSAU:手把手教你支持向量机模型 SVM
建议选择预测模型时也建立分析流程,比如进行时间序列预测:

三、分类模型
分类模型一般可以解决国赛数学建模的小问,一般常用的方法有聚类分析、判别分析以及机器学习(决策树、神经网络等)等。聚类分析前提不明确数据对象应该分为几类,常用的计算有欧式距离、pearson相关系数、夹角余弦法等,判别分析一般是分析前就明确观察对象应该分为几类,一般在分析中可以将二者结合进行分析以及还有机器学习可以进行分类。
四、优化模型
一般可以利用优化模型得到最优目标,比如在经济问题、生产问题、投入产出等等,人们总希望用最小的投入得到最大的产出,一般分析的流程如下:
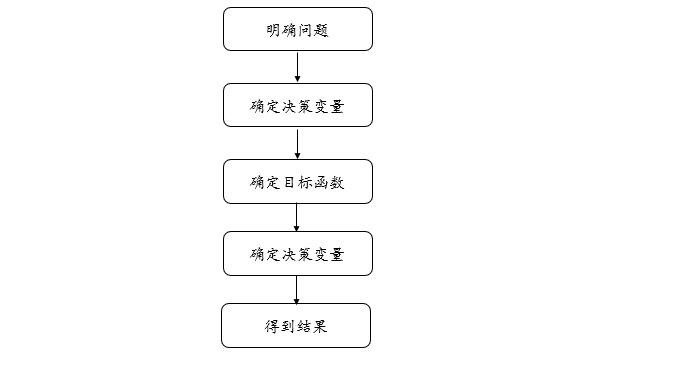

其中决策变量一般有0-1规划或者整数规划,通过目标函数和约束条件,确定优化模型的类型,一般有动态规划,线性规划,非线性规划以及多目标规划。
- 动态规划
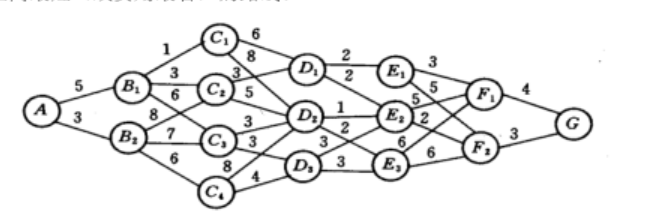
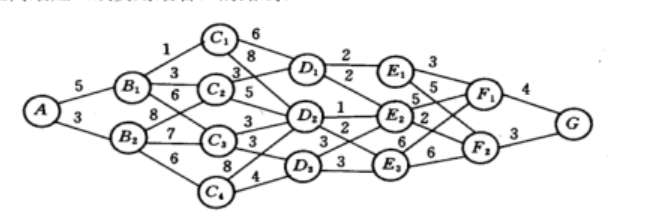
以时间划分阶段的动态优化模型。可以解决最小路径问题、生产规划问题、资源配置问题。虽然动态规划用于求解以时间划分阶段的动态过程的优化问题,但是如果对于线性规划、非线性规划引入时间因素,也可以把他视为多阶段决策过程。最小路径模型图类似如下:
- 线性规划
目标函数和约束条件均为线性。线性规划的目标函数可以是求最大值,也可以是求最小值,约束条件的不等号可以是小于号也可以是大于号。其标准形式如下:

其中c和x为n维列向量,A、Aeq为适当维数的矩阵,b、beq为适当维数的列向量。
- 非线性规划
目标函数和约束条件均不是线性,非线性规划比线性规划偏难,线性规划与非线性规划的区别为:如果线性规划的最优解存在,其最优解只能在其可行域的边界上达到(特别是可行域的顶点上达到);而非线性规划的最优解(如果最优解存在)则可能在其可行域的任意一点达到。
- 多目标规划
目标函数不唯一,此种算法主要是解决线性规划的局限性,线性规划只能解决最大值、最小值问题,有些问题需要衡量多目标规划,一般需要将此种需要转化为单目标模型,所以需要有加权系数,表述不同目标之间的重要程度对比。
- 整数规划
决策变量取值为整数。整数规划最优解一般不能按照实数最优解简单取整而获得,所以一般求解方法有分枝定界法、割平面法、隐枚举法(一般解决0-1整数规划问题)、蒙特卡罗法(可以求解各类型规划)。

数据模型可以从数据和业务两个角度做区分。
一、数据模型
数据角度的模型一般指的是统计或数据挖掘、机器学习、人工智能等类型的模型,是纯粹从科学角度出发定义的。
1. 降维
在面对海量数据或大数据进行数据挖掘时,通常会面临“维度灾难”,原因是数据集的维度可以不断增加直至无穷多,但计算机的处理能力和速度却是有限的;另外,数据集的大量维度之间可能存在共线性的关系,这会直接导致学习模型的健壮性不够,甚至很多时候算法结果会失效。因此,我们需要降低维度数量并降低维度间共线性影响。
数据降维也被成为数据归约或数据约减,其目的是减少参与数据计算和建模维度的数量。数据降维的思路有两类:一类是基于特征选择的降维,一类是是基于维度转换的降维。
2. 回归
回归是研究自变量x对因变量y影响的一种数据分析方法。最简单的回归模型是一元线性回归(只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示),可以表示为Y=β0+β1x+ε,其中Y为因变量,x为自变量,β1为影响系数,β0为截距,ε为随机误差。
回归分析按照自变量的个数分为一元回归模型和多元回归模型;按照影响是否线性分为线性回归和非线性回归。
3. 聚类
聚类是数据挖掘和计算中的基本任务,聚类是将大量数据集中具有“相似”特征的数据点划分为统一类别,并最终生成多个类的方法。聚类分析的基本思想是“物以类聚、人以群分”,因此大量的数据集中必然存在相似的数据点,基于这个假设就可以将数据区分出来,并发现每个数据集(分类)的特征。
4. 分类
分类算法通过对已知类别训练集的计算和分析,从中发现类别规则,以此预测新数据的类别的一类算法。分类算法是解决分类问题的方法,是数据挖掘、机器学习和模式识别中一个重要的研究领域。
5. 关联
关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则,它是从大量数据中发现多种数据之间关系的一种方法,另外,它还可以基于时间序列对多种数据间的关系进行挖掘。关联分析的典型案例是“啤酒和尿布”的捆绑销售,即买了尿布的用户还会一起买啤酒。
6. 时间序列
时间序列是用来研究数据随时间变化趋势而变化的一类算法,它是一种常用的回归预测方法。它的原理是事物的连续性,所谓连续性是指客观事物的发展具有合乎规律的连续性,事物发展是按照它本身固有的规律进行的。在一定条件下,只要规律赖以发生作用的条件不产生质的变化,则事物的基本发展趋势在未来就还会延续下去。
7. 异常检测
大多数数据挖掘或数据工作中,异常值都会在数据的预处理过程中被认为是“噪音”而剔除,以避免其对总体数据评估和分析挖掘的影响。但某些情况下,如果数据工作的目标就是围绕异常值,那么这些异常值会成为数据工作的焦点。
数据集中的异常数据通常被成为异常点、离群点或孤立点等,典型特征是这些数据的特征或规则与大多数数据不一致,呈现出“异常”的特点,而检测这些数据的方法被称为异常检测。
8. 协同过滤
协同过滤(Collaborative Filtering,CF))是利用集体智慧的一个典型方法,常被用于分辨特定对象(通常是人)可能感兴趣的项目(项目可能是商品、资讯、书籍、音乐、帖子等),这些感兴趣的内容来源于其他类似人群的兴趣和爱好,然后被作为推荐内容推荐给特定对象。
9. 主题模型
主题模型(Topic Model),是提炼出文字中隐含主题的一种建模方法。在统计学中,主题就是词汇表或特定词语的词语概率分布模型。所谓主题,是文字(文章、话语、句子)所表达的中心思想或核心概念。
10. 路径、漏斗、归因模型
路径分析、漏斗分析、归因分析和热力图分析原本是网站数据分析的常用分析方法,但随着认知计算、机器学习、深度学习等方法的应用,原本很难衡量的线下用户行为正在被识别、分析、关联、打通,使得这些方法也可以应用到线下客户行为和转化分析。
二、业务模型
业务模型指的是针对某个业务场景而定义的,用于解决问题的一些模型,这些模型跟上面模型的区别在于场景化的应用。
1.会员数据化运营分析模型
会员细分模型、会员价值度模型、会员活跃度模型、会员流失预测模型、会员特征分析模型和营销响应预测模型
2.商品数据化运营分析模型
商品价格敏感度模型、新产品市场定位模型、销售预测模型、商品关联销售模型、异常订单检测模型、商品规划的最优组合
3.流量数据化运营分析模型
流量波动检测、渠道特征聚类、广告整合传播模型、流量预测模型。
4.内容数据化运营分析模型
情感分析模型、搜索优化模型、文章关键字模型、主题模型、垃圾信息检测模型。

刚搞完了一份《十大数据分析模型详解》的白皮书,里面介绍了常见的十大数据分析模型,等不及的朋友可以直接下载电子书保存:
篇幅原因,在这里只做简述,电子书里有列举一些场景实例,供大家参考。
基于多维事件模型,会形成一些常见的数据分析方法。在用户行为领域,对这些数据分析方法的科学应用进行理论推导, 能够相对完整地揭示用户行为的内在规律。基于此帮助企业实现多维交叉分析,让企业建立快速反应、适应变化的敏捷商 业智能决策。
1. 事件分析
事件分析法是用来研究用户的某个、某些行为事件本身特征的方法,企业借此来追踪、记录用户行为或业务过程。事件分 析是所有分析模型中最基础的一种,它是指对具体的行为事件,进行指标加工的一种分析方法,常见的指标计算规则为行 为事件发生的人数、次数、人均次数,以及针对行为事件的属性特征进行特殊运算,如去重、求和、求均值等。以互联网 金融行业常见的用户投资为例,通过对“投资成功”的事件分析 ,可统计每日成交的投资产品订单数、投资总额,并且可 以研究投资总额的趋势、周期 , 及时洞察数据中的异常点。通过研究与事件发生关联的所有因素来挖掘用户行为事件背后 的特点、趋势及异常等现象。
2. 漏斗分析
在实际的业务分析中,事件分析主要是基于事件本身做分析,在实际的业务中,还存在一类常见的分析诉求,即将某个业 务场景中关联的事件,根据发生的先后顺序进行组织,从而系统性了解用户的转化效率。这样的分析模型,就是我们常用 的漏斗分析。
对比事件分析来说,漏斗分析其实是一套流程分析,它不但可以整体性的反映用户在一定时间周期内,浏览网站或者 APP 中从起点到终点的转化率,而且还可以分析浏览过程中每一次跳转所产生的留存和流失,这样就能够直观地发现异常数据, 从而通过分析根因找到问题所在,最后通过优化该环节来达到提升转化率的目标。
漏斗分析模型已经广泛应用于渠道来源分析、新用户激活、核心主流程优化、搜索功能优化等日常数据运营工作中。例如 在一款直播平台软件中,直播用户从激活 APP 开始到打赏主播,用户核心路径为激活 APP、注册账号、浏览列表页、进入 直播间、产生互动行为和完成主播打赏。如果整体转化率偏低,那么使用漏斗分析能够展现出各个环节的转化率,通过漏 斗各环节相关数据的对比分析,可以直观地发现问题所在,从而找到优化方向。
这里需要注意的是,我们跟踪整个漏斗的转化过程,是以用户为单位将步骤串联起来,并不是只把每个步骤的发生次数做 一个简单的计数,因为使用漏斗的目标之一是将潜在客户转化为目标用户,核心是对用户的分析。另外进入到后续步骤中 的用户,一定是完成了所有前序步骤。例如漏斗一共有五步,如果有用户完成了第一步、第三步和第五步,跳过了漏斗模 型中的第二步和第四步,也不能算作一次转化。
其次要选择合适的时间窗口。如果没有时间窗口的话,那么用户有可能一天完成漏斗流程,也有可能一个月完成漏斗流程, 没有时间的限制,漏斗的作用也要大打折扣了。至于具体什么时间合适要根据业务来判断。如我们要看当天秒杀活动的转化, 那么窗口期建议设置为一天,太长就没办法算作是活动的转化 ;但对于证券开户流程,不但要准备多种材料,还需要经过 审核。如果开户漏斗的窗口期设置太短,可能审核都很难完成。
3. 用户路径分析
现在的 APP 或者网站功能丰富、页面路径多样,用户访问时如同参观画展,一千个哈姆雷特可能会有一千种参观方式。但 对于网站来说,自然会有希望用户完成的核心路径。那么怎么来判断用户访问是否偏离了核心路径呢?这时候就需要使用 用户路径分析模型了。
用户行为路径分析,顾名思义,是根据用户在 APP 或网站中的访问行为,分析用户在各模块中跳转规律与特点,挖掘出用 户的群体特征,进而实现业务指标:如提升核心模块的到达率、APP 产品设计的优化改版、流失用户去向分析等。在使用 路径分析时,需要注意以下 2 个要点:
第一,从目标场景出发,来思考选取合适的起始事件或结束事件,比如限定起始事件看结尾事件,或者限制结束事件看起始事件。
如果你很明确的知道用户的切入点,那么这时候需要选择固定的起始事件,如果有明确的结果,那么这时候需要倒推时, 看有什么事件影响了这个结果,这时候就需要选择固定的结束事件。例如当产品同学需要验证流量分发是否满足预期时, 可以选择起始事件为目标事件;另外我们从漏斗分析中找出的“流失用户”也可以通过设置初始事件来观察用户的去向。 而如果我们要考虑一些重要行为的来源有哪些的话,那么就可以选择目标事件为结束事件,来看前序事件有哪些。
第二,根据需求选择相关事件来分析,切忌选择全部。
其实看用户行为路径的时候我们已经有了相对明确的问题,那么这时候需要把与问题无关的一些事件刨除,即使被刨除的 这些事件有可能发生。因为这些不是观察的重点,而且会影响我们最终的判断,我们需要做的是聚焦在相关事件即可。另外, 由于点击事件与页面浏览往往是相伴而生的,一般情况下可根据分析情况选择其一即可,这样可以在更少的步骤内,更高 效的发现路径的规律。
4. 留存分析
随着流量红利的进一步收缩,存量市场的博弈更加显著,老用户的经营对于企业生存来说显得至关重要。另一方面,高昂 的获客成本让不少互联网创业者们陷入新客获取难的窘境,花费极高成本所获取的客户,可能仅打开一次 APP 或完成一次 交易后就迅速流失,导致前期的营销投入打了水漂。
在这样的大背景下,用户的留存问题成了许多企业和业务的亟待解决的共性问题。客户当前的留存情况如何衡量,如何增 加客户黏性,延长每一个客户的生命周期。针对此类问题我们将通过留存分析模型一探究竟。
留存分析是一种用来分析用户参与情况和粘性的分析模型,考察发生了初始行为的用户中,有多少人会在后续的几天里面 发生后续行为。这是用来衡量产品对用户价值高低的重要方法。留存分析可以帮助我们回答一些问题,比如某一天进来的 新用户群体,在未来的一段时间内每天分别有多少人完成目标转化行为 ?某个社交产品改进了新注册用户的引导流程,改 善前后新用户的留存是否有改善 ?想判断某项产品改动是否奏效,如新增了一个邀请好友的功能,观察是否有人因新增功 能而延长使用产品时间 ?
5. Session 分析
如果把网站或 APP 比喻成一个商场,那互联网用户的行为就如同逛街的顾客,他们在产品中的访问通常和逛商场一样是一 系列连续行为。对于网站或者 APP 而言,用户一系列行为是一次访问,也就是一个 Session。Session 分析法是用来分析 把用户单点发生的行为串联起来形成一个整体的前提下,Session 整体或者 Session 中某个特定事件的访问特征。常见的 指标分为 Session 整体的次数、人数、时长、深度、跳出率等,以及 Session 中某个特定事件的次数、人数、时长、退出率等。
以用户在某个在线教育网站的访问为例,用户在一次访问中,诸如“用户平均会来几次”、“每次平均逛了几个页面”、“每次来平均待多久”、“某个具体页面用户平均停留多长时间”这样的问题都需要通过 Session 分析解决。通过 Session 分析, 可统计用户在网站或者 APP 中的整体访问深度、以及某些特殊节点的访问情况,从而在产品或者运营层面输入优化策略。
6. 热力分析
热力分析,即应用一种特殊高亮的颜色、数据标注等,显示页面或页面组(结构相同的页面,如商品详情页、官网博客等) 区域中不同元素点击密度、触达率、停留分布等特征。热力分析法主要用来分析用户在页面上的点击、触达深度等情况, 并以直观的效果展示给使用者 , 它是互联网行业常用的一种分析模型,比较直观的表现了用户在产品页面上的浏览偏好, 有力的说明了用户和网页的交互情况。
常见的热点分析的展示形式,有点击图、触达率图、热图等。以点击图为例,该方法将页面进行渲染,从而直观的展示出 页面元素被点击的次数、占比、发生点击的用户列表、到达网页某个位置的用户比例等。
热力分析具有分析过程高效、灵活、易用和效果直观的特点。采用可视化的设计思想与架构,以简洁直观的操作方式,呈 现访客热衷的区域,帮助运营人员或产品人员评估网页设计的科学性。
7. 归因分析
在 PC 互联网时代,一个网站吸引新用户的主要方式之一就是投放线上广告。而同样一篇广告可以投放至多个渠道,一个 用户也可能在不同渠道商多次看到广告才发生购买。这时候用户虽然是最后一次看到广告才发生点击,但前面的几次曝光 可能给用户留下了印象,建立了心理认知,因此对用户的本次点击亦有贡献。那么如何将用户点击行为的“贡献”合理地 分配到每一个渠道呢?这便是渠道归因要解决的问题。通过渠道归因来衡量渠道的效果,反过来可以指导业务人员在渠道 投放时合理分配投入。
随着移动互联网的兴起,业务的形态越来越复杂,站内归因(也常被称作“坑位归因”)的需求日趋增多。以自营电商为 例:同样的一个商品,可能会在站内多处“坑位”产生曝光,比如:首页 Banner 的特卖活动页、商品详情页的相关推荐、 购物车页面下方的推荐列表中。运营人员会需要知道这些“坑位”对商品最终成单产生的“贡献”分别是多大,从而指导 站内的商品运营工作,例如将主推的商品推至成单贡献度高的坑位中,给予更多的曝光从而带来更多的转化。
对于归因分析而言,一个很重要的命题即是,针对当前的场景和目标,怎么把“贡献”合理分配到每一个坑位上。下面我 们就以站内归因为例,普及一下几种常见的归因分析计算思路。假设一个用户一天内使用 APP 的行为顺序如下:
首先,启动 APP,进入首页,先行搜索,在搜索结果列表页看到了商品 A,浏览了商品 A 的详情,觉得不错,但是并未购买, 退出 APP。然后,再次启动 APP,看到首页顶部 Banner,点击进入活动分会场,浏览过程中再次看到商品 A,点击再次 查看商品 A 详情。接着,直接退出到了首页,底部推荐列表中推荐了一篇商品 A 的用户评论,点击进入,再次查看商品 A 的详细信息。最后,下定决心,购买了商品 A。
以上过程是一个非常典型的用户购买决策路径,在整个过程中用户一共三次浏览到了商品 A 的详情页,均通过不同的入口 发生访问。如果将这个用户的成单转化的功劳分配到对应的 3 个坑位上,实际上这类问题其实并没有标准答案。
8. 间隔分析
间隔,指的是用户行为与行为之间的间隔时长。在以往的数据分析过程中,我们通常会关注用户的整体使用时长,因为时 长一定程度上代表了用户对于 APP 的黏性。用户越愿意花时间,代表用户对 APP 的依赖程度越高。而在间隔分析的场景下, 时长则代表着其他的业务含义。
例如:
1. 新用户进入注册页面,到完成注册的间隔时长,侧面反映注册流程的顺畅程度。 2. 用户发生两次充值之间的间隔时长,反应用户的充值周期。
在一些场景下,通过对间隔时长分布的观察,可以得到对产品或者用户的洞察,从而指导我们发生下一步的业务动作。例如, 通过对用户开始注册和注册成功两个行为之间的时长分布,我们可以获知用户完成注册普遍所需要花费的时长,当某天注 册成功率没有发生明显波动,而时长的分布整体变长时,我们则需要检查注册验证码的短信通道是否畅通、后台注册接口 是否正常等等。
9. 分布分析
分布分析是用户在特定指标下的频次、总额等特征的结构化分段展现。分布分析是了解数据分布表现的主要方法,往往能 通过对数据结构的分层分析,判断极端数值的占比、对整体数据的影响,同时了解数据分布的集中度,以及主要的数据分 布的区间段是什么。从事件在不同维度中的分布来观察,我们可以了解该事件除了累计数量和频次这些简单指标之外,洞察数据在分布特征上的特点,便于了解业务的健康度、分层结构等信息。
常见的分布模型一般包含以下类型:事件频率、一天内的时间分布、消费金额的区分等。同时,在设计分布区间时,还需 要支持客户自定义区间,这样用户才可以找到最适合的区间分布。总体来说,分布分析价值主要体现在以下几个方面:
第一,挖掘用户分布规律,优化产品策略。
对同一指标下有关数据进行统计与分析,帮助企业从中挖掘用户访问规律,企业可以将规律与实际产品策略相结合,进一 步修正和重新制定产品策略。同时还可以分析某个功能的使用情况,来判断用户对某个功能的使用率。如果某些功能的使 用率偏低,那么我们就可以进行产品端或运营端优化。
第二,除去极值影响,数据更接近整体真实表现。
分布分析的另外一个价值点就在于,对于某些因为极大值或者极小值而影响大部分用户数据表现的情况来说,我们可以快 速发现最大值和最小值的分布次数,而其他大部分用户都分布在一个相对聚集的区间,从而判断大部分用户的分布情况。
第三,快速识别核心用户群体,资源配置有的放矢。
可以通过分布分析来找出某些核心功能的深度使用者,这些都是企业的核心用户。核心用户群体是对企业价值贡献最大的 用户群体,是企业最大的利润来源。在此基础上,企业可以通过优化资源配置,以最小成本实现企业利润最大化。
10. 属性分析
仅知道一幢房子的面积无法全面衡量其价值大小,因为房子的地理位置、装修风格、是否学区、配套设施都是重要的影响 因素。对于企业来说,在分析行为事件特点的同时,也需要对触发事件的用户本身来分析研究。这就是我们常说的用户属 性分析。
属性分析通过对用户各类特征进行标示,从而了解用户的属性,或者属性交叉的分布结构,进而可以对用户进行分层标记, 以便进行后续的产品、运营动作。属性分析可对基础属性、社会关系、行为特征、业务表现特征等进行结构分析。基础属 性包含姓名、年龄、家庭、婚姻状况、性别、最高教育程度等;社会相关包含已婚未婚、有无小孩等属性;行为特征包含 注册时间、用户首次访问渠道来源等;而业务相关属性则是从业务数据中提取,如业务为健身相关,那么可能会包含体脂率等。
属性分析的价值主要体现在丰富用户画像维度,让用户行为洞察粒度更细。在事件——用户的数据模型中,用户一直处于 从属角色。很大原因是我们对于用户属性分析还不够深。如果我们有足够的用户属性的话,那么这些用户即使没有触发事件, 我们也可以通过属性来推断出一些可能会出现的场景,然后用相关的运营或产品动作来验证。
那么既然属性这么重要,属性可以怎么采集呢?一般来说包含以下几种来源:一是用户直接填写,我们在很多场景都会填 写自己的地址、兴趣爱好、出生年月等,这些都可以生成属性。二是可以通过已有特征推断,比如说用户填写的地址有办 公楼标签,那么我们可以认为他是商务人士等。三是通过身边的人来推测,这个和协同过滤比较类似,用户 B 和用户 A 行 为相似,所以可以把用户 A 的属性标签打到用户 B 的身上。
全文电子书,欢迎点赞关注,共同讨论~

我觉得有必要先简单普及一下模型的概念,以及模型的分类,毕竟题主问的是数据分析中的数据模型,不是有的答案中提到的分析模型,不是程序模型、不是逻辑模型~
模型是指对于某个实际问题或客观事物、规律进行抽象后的一种形式化表达方式。任何模型都有三个部分组成:目标、变量和关系。其实都比较容易理解:
目标:这个模型是干嘛用的,要解决什么问题
变量:自变量、因变量、中介变量(可自行百度),总之就是,明确变量,改变变量,即可直接呈现结果,实现目标。
关系:可以理解为对目标和变量进行组织。
回到问题,现在最常用的数据分析模型有以下几种,部分模型有人已经提到了,但可能还不是很深刻, 而且这些模型,其实也在不断的优化,并且又有了一些新特性。
1、事件模型:
用户在产品上的行为(所有和代码的交互)都是会被记录的,怎么标记是事件模型的核心,他是漏斗模型、自定义留存模型、权行为路径分析模型的基础哦~
过去:同样都是事件模型,过去只记事件,100个商品有100个详情页面,可能就得记录100个事件,
现在:我们采用的是事件、属性、值的采集方式。把100个事件结构化以后变成了1个。用户进入商品详情页是一个事件,进入哪个商品的详情页用属性和值来标记了。事件、属性的名称可以自定义,值是变量。
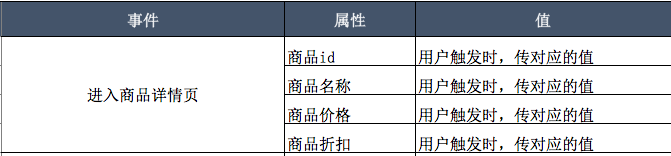

当把用户行为抽象成事件之后就是分析的事儿了,对应一些可视化分析模型,比如事件的对比、属性值分布,计算某一行为触发的人数、次数、人均次数、活跃比等并用折现图、柱形图进行表达。
2、漏斗分析模型
漏斗是最最最常用也是最经典的模型~他可以理解为一组转化的最终转化率,是由一组事件计算出来的。
在漏斗分析中,很多人最多的疑问是“漏斗统计的每一步是人数还是次数?”“漏斗有没有转化时间限定?”,答案是以人数为统计口径且有转化时间限定。详细的可以看诸葛io机构号之前的回复: https://www.zhihu.com/question/30678731/answer/263115879
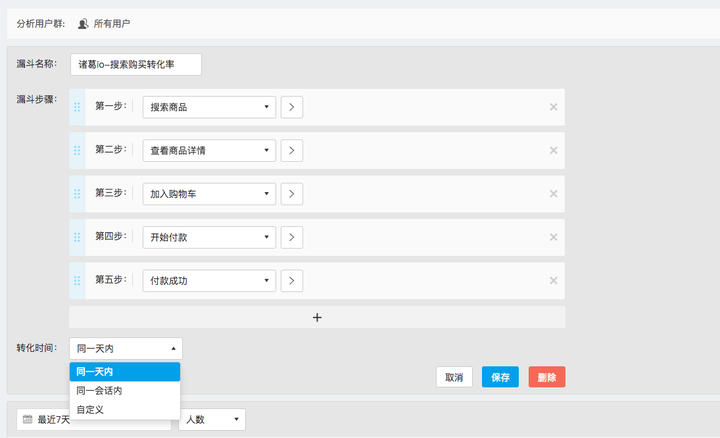

3、热图分析模型
热图的目标是能更直观的分析用户在页面上的焦点,不需要定义事件,不需要去对比事件,直接在页面上通过颜色深浅还原用户的聚焦位置并形成对比。
过去:分析全量人群的热力表现
现在:分析特定人群;群组之间进行对比


4、自定义留存分析模型:
自定义功能是目前留存分析的新姿势。留存被认为是比较高级的一个指标。无论用户在应用内做了什么,他打开了访问了就是一个回访用户,但不同产品对留存的用户有了不同的定义,阅读类产品定义为用户查看了文章算是今天的一个留存用户,电商定义为用户看了商品详情算是今天的一个留存用户,所以有了自定义留存。根据自己的业务特性,灵活分析不同留存判断条件下的用户回访情况:
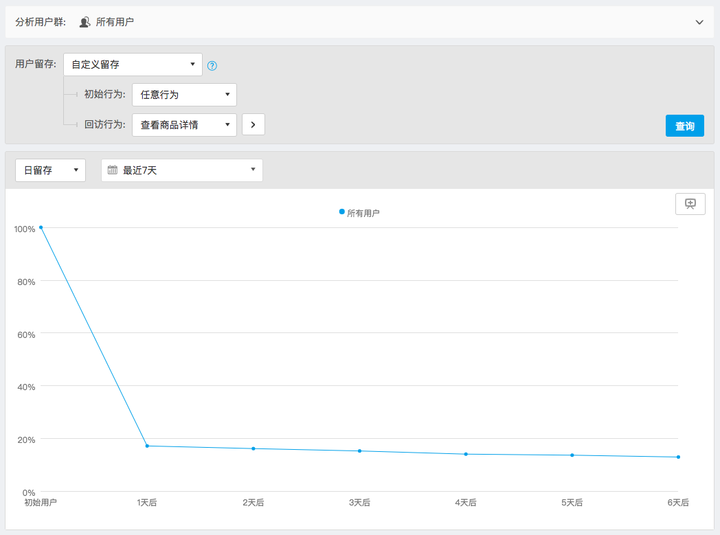

除了以上四个比较经典并且不断在优化的模型,在用户行为数据分析中,其实已经有一些比较好用的分析模型了,毕竟分析这件事,未来会越来越简单、越来越可视化、智能化:
4、粘性分析模型
粘性是总被提到的,但是很少有个准确的定义并进行量化分析。如下图:
计算一段时间内,以周、月为单位看用户不同的访问天数所占的百分比。下图表示,一周访问大于等于3天的有48.6%
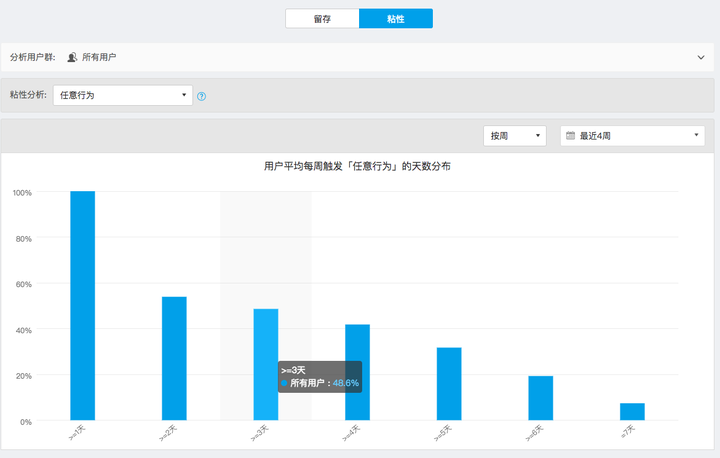

5、新增后
虽然定义为维度更准确,但从某种意义上,还是可以定义为一种分析模型,因为他太好用,不得不提一下:
计算用户触发某行为的时间和用户新增的时间,然后定义为“新增后”,比如,你可以快速找到新增后1天内就付款、新增后30天才付款的用户,背后其实是对用户价值的快速衡量;还可以基于此条件,不断去分群,比如用户完成一次购买是发生在新增后的7天,30天,还是一个月,快速找到用户购买的决策周期。
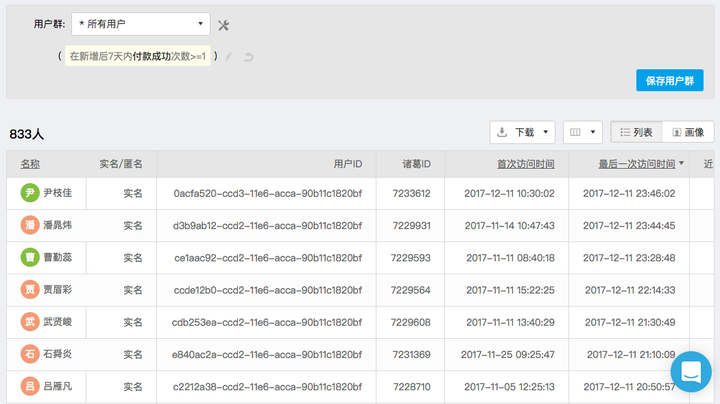

6、全行为路径分析模型
用户在产品中的行为其实是个黑盒子,权行为路径是用全局视野看用户的行为轨迹,很多时候你会有意想不到的收获,在可视化的过程中有两个模型,一个是树形图、一个是太阳图。


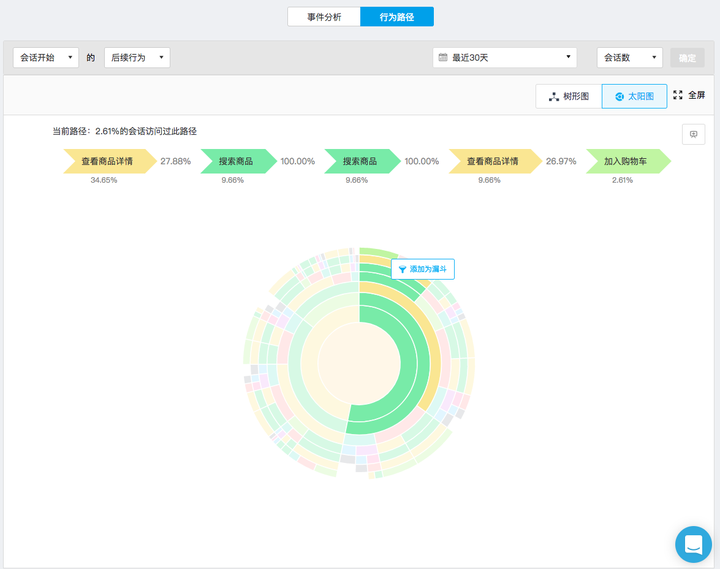

7、用户分群模型
用户分群其实是最常做的,但是如何把群组划分这一操作变得更便捷和高效,其实在诸葛,我们进一步优化了这一模型,也足以满足很多场景下的用户分群需求:
维度:新增于、活跃于、触发过什么行为、用户属性满足什么条件
时间:绝对时间和相对时间
关系:并且、或者


这七个其实就能解决和分析很多问题了,剩下的其实就是对数据进行灵活的组织,比如,所有模型都可以交易用户群,而这其中,事件模型其实非常经典,之前服务客户发现,没个三次五次的讲很多人理解起来还是很困难,但是一旦理解,你会对行为数据的采集分析非常通透,因为漏斗、全行为路径、自定义留存、粘性模型都是基于事件模型进行的计算和可视化。
以上~

我看有一些回答都只是简单的罗列了下,没有说明这些模型怎么用,我来补充一下:
7个常见的大数据分析模型:
- 事件分析
- 留存分析
- 漏斗分析
- 路径分析
- session分析
- 分布分析
- 归因分析
01 事件分析
干啥的:研究某行为事件的发生对企业组织价值的影响以及影响程度。
怎么用:追踪或记录的用户行为或业务过程,如用户注册、浏览产品详情页、成功投资、提现等,通过研究与事件发生关联的所有因素来挖掘用户行为事件背后的原因、交互影响等。
应用场景举例:
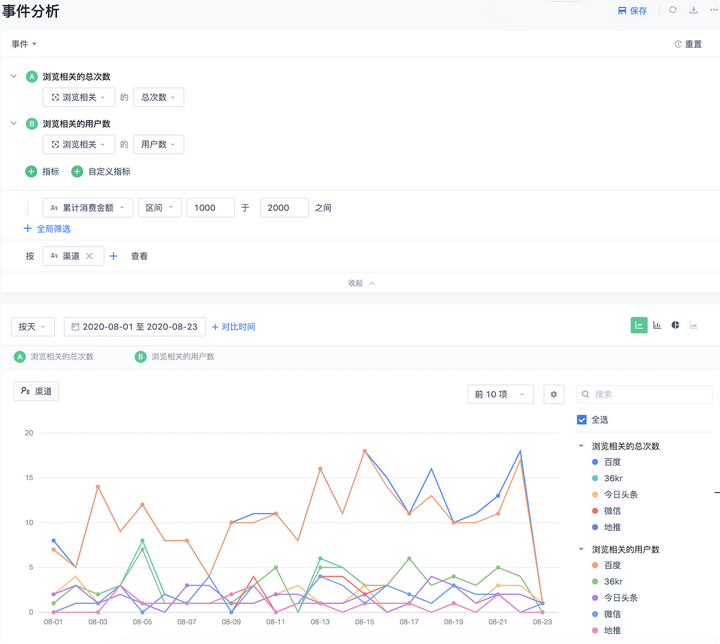
问题:运营人员发现,某渠道某天的PV数据异常高,需要排查原因?分为以下步骤:
- 定义事件:将事件定义为PV值,通过筛选条件限定渠道
- 多维度下钻分析:将PV值按照日期、地理位置、机型、操作系统、IP等不同维度进行分析
- 通过多维度展示结果,给出PV数据的解释,是虚假流量?(全部来自某IP),数值异常高?(某天数据上涨)

02 留存分析模型
干啥的:分析用户参与情况/活跃程度,考察进行初始行为的用户中有多少人会进行后续行为。这是用来衡量产品对用户价值高低的重要方法。
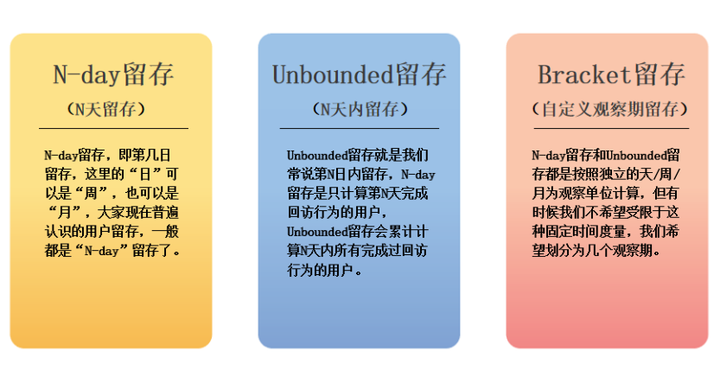
怎么用:留存分析分三种,N-day留存、unbounded留存、bracket留存。

应用场景举例:
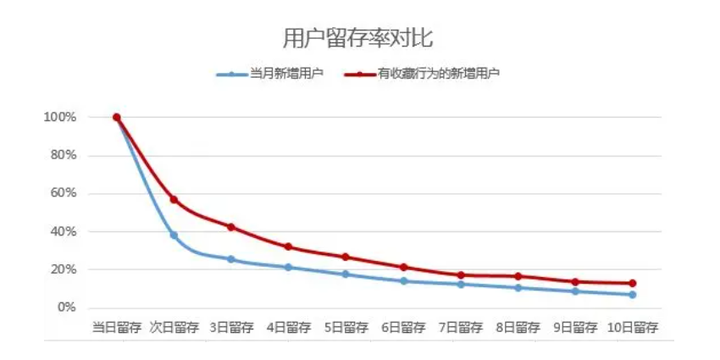
问题:最近的新增客户很多,想看用户留存的情况如何?可分为以下几个步骤:
- 根据新用户注册/下载的时间进行同期分组(月/周/日)
- 观察用户发生投资的 7 日留存、14 日留存或 30 日留存(可自由选择)
- 比较不同的同期群,观察每天留存率的变化趋势了。

03 漏斗分析模型
干啥的:反映用户行为状态以及从起点到终点各阶段用户转化率情况
怎么用:通过观察不同属性的用户群体各环节转化率,各流程步骤转化率的差异对比,了解转化率最高的用户群体,分析漏斗合理性,并针对转化率异常环节进行调整。
典型场景举例:
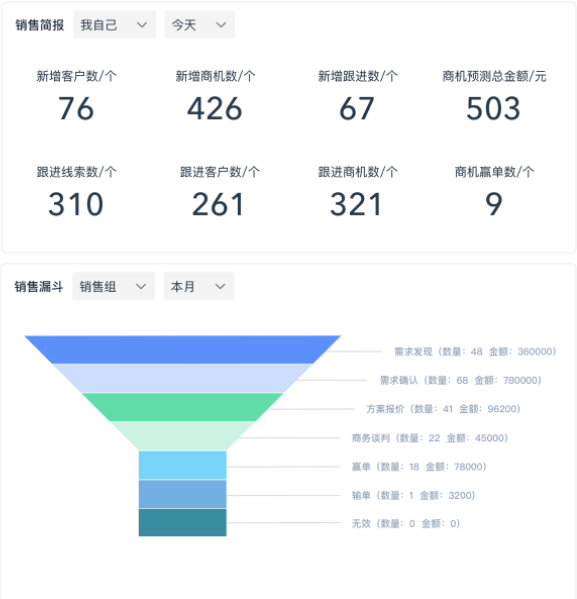
问题:销售人员想要了解从需求发现到赢单的各个环节的转化情况?可参考以下步骤:
- 从需求发现这一环节开始,按照需求设计销售漏斗图
- 根据销售漏斗图的各个环节进行跟进和数据录入
- 自动生产数据分析表,观测客户各阶段转化率
详细参考: CRM客户管理

04 路径分析模型
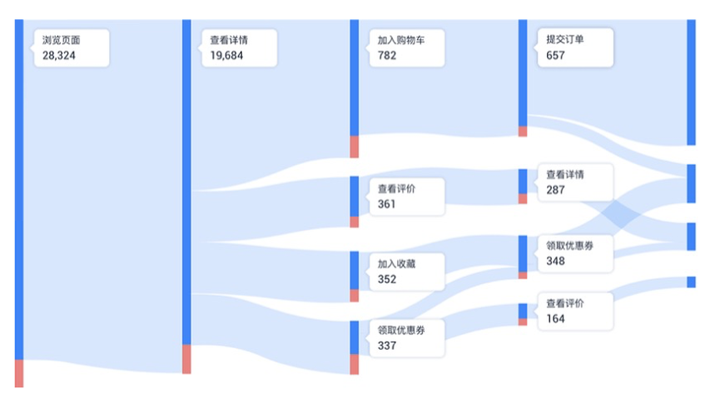
干啥的:互联网产品特有的一类数据分析方法,提升产品核心模块的到达率、提取出特定用户群体的主流路径与刻画用户浏览特征。
怎么用:根据每位用户在APP或网站中的行为事件,分析用户在APP或网站中各个模块的流转规律与特点,挖掘用户的访问或浏览模式,进而实现一些特定的业务用途。
路径分析主要为解决以下问题:
- 用户主要是从哪条路径最终形成支付转化的?
- 用户离开预想的路径后,实际走向是什么?
- 不同特征的用户行为路径有什么差异?

05 session分析模型
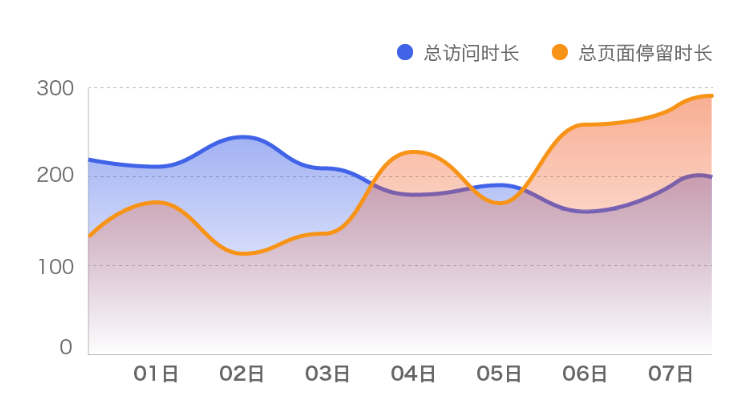
干啥的:对指定的时间段内,用户在网站/H5/小程序/APP上发生的一系列用户行为的集合进行指标分析。
Session 的关键点是:多长时间内用户做了什么事。
怎么用:包括访问次数、人均访问次数、总访问时长、单次访问时长、单次访问深度、跳出次数、跳出率、退出次数、退出率、人均访问时长、总页面停留时长、平均页面停留时长等。
两个公式:
- 平均访问时长=所有用户的session市场之和/Session数
- 平均交互深度=session内事件之和/session数

06 分布分析模型
干啥的:通过对质量的变动分布状态的分析中发现问题,了解生产工序是否正常,废品是否发生等情况。其工具是直方图,故又称直方图法。
怎么用:提供「维度指标化」之后进行数据分解,将原有维度按照一定的数值区间进行维度划分,进而分析每个维度区间的分布情况。
举个例子:
把特别依赖的用户单独筛选出来,建一个用户运营的专项项目,去运营用户。也可以把那些付款金额大的用户,去做一些运营活动。
下图就可以看出人数和交易客单的分布情况:


07 归因分析模型
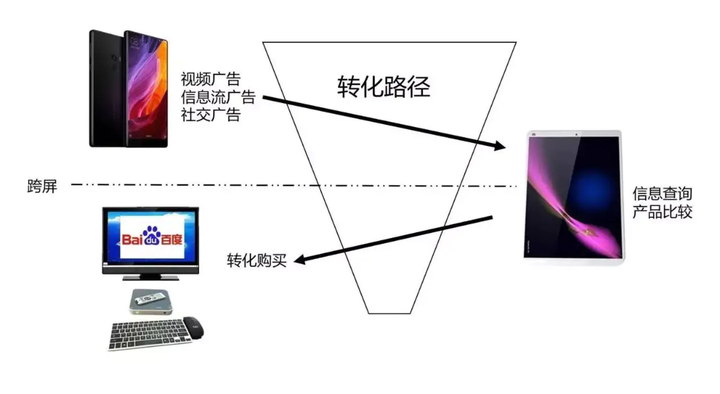
干啥的:归因分析要解决的问题就是广告效果的产生,其功劳应该如何合理的分配给哪些渠道。
怎么用:衡量和评估站内的用户触点对总体转化目标达成所做出的贡献,可以非常直接的量化每个运营位和触点的转化效果和价值贡献。
举个例子:
小陈同学在手机上看到了朋友圈广告发布了最新的苹果手机,午休的时候刷抖音看到了有网红在评测评,下班在地铁上刷朋友圈的时候发现已经有小伙伴收到手机在晒图了,于是喝了一杯江小白壮壮胆回家跟老婆申请经费,最后老婆批准了让他去京东买,有保障。那么请问,朋友圈广告、抖音、好友朋友圈、京东各个渠道对这次成交分别贡献了多少价值?

以上。篇幅原因说的很浅,不足之处欢迎大家评论区指正。


前言:
写这一篇文章的目的是去魅,数据分析的分析方法是一个伪命题,但是这个伪命题符合初学者的逻辑。认为万事万物皆有打包好的方法,只需要按部就班的学习即可。所以网上所看到的流传比较广的分析方法,主要还是为了迎合用户的喜好,而不是满足工作的需求。
在我们业务分析分享的文章里,你会认识到业务知识细节、策略能力和协同推进能力是工作的核心竞争力,对于大部分岗位来说都是如此。而对于数据分析师这样的分工来说,【利用统计学知识寻找合理统计指标】、【用合适的数学模型挖掘数据价值】以及【提高数据流通和解读的效率】是我们的本职工作。
至于分析方法,我更偏向于称之为分析习惯。这些习惯并不是数据分析独有的,你们从网上看到的那些分析方法也是如此,有些类似写好的函数,有些类似分析的习惯,只有把他们和工作真正的结合才能发挥效果。网络上对于这些方法只给出定义,实则对工作没有半点用途。
那么,我们就尝试从网上的分析方法,提炼并延展出和工作有关的内容,希望引起大家进一步的思考:
其中部分重点内容之前已经写过更详细的部分,本文更多是总结和提炼,篇幅不会太长,但是后面会从这些总结出发延伸更多的明细场景:
渭河数据分析社区-零基础入门+数据分析思维+经验分享
正文:
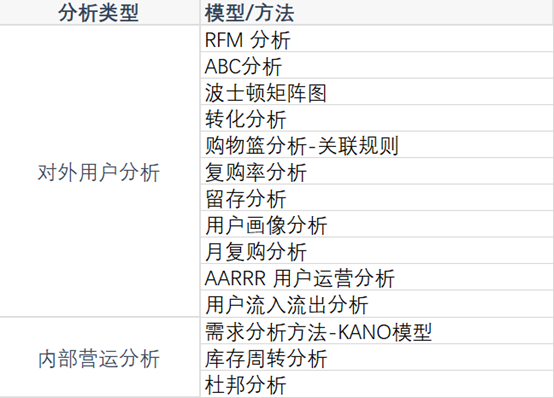
当你搜索数据分析方法的时候,通常是说有35种,包括:
1.RFM分析;2.帕累托分析;3.波士顿矩阵;4.漏斗转化分析;5.购物篮分析;6.复购率分析;7.留存分析;8.热图分析;9.AARRR海盗模型;10:用户流入流出分析;11.用户画像;12.需求分析方法;13.库存周转分析;14.杜邦分析;15.盈亏平衡分析;16.同期群分析;17.比率分析;18.零基预算法;19.净现值法;20:SWOT分析;21.PEST分析;22.BSC平衡记分卡;23.波力五特模型;24.PDCA;25.GE矩阵;26.STP分析;27.4Ps营销组合;28.安索夫矩阵;29.推销方格理论;30.哈夫模型;31.KPI;32.360绩效考核;33.六西格玛;34.SPIN销售法;35.盖普洛Q12测评法
上面写的那些东西,看起来头麻,我也没排版。
因为没有用。
说他们没有用不是说这是假的,这些知识点都曾经存在于互联网上,甚至也真实的作用在企业内。
但说他们没有用的原因主要是两个:
1.他们和数据分析没有关系
2.他们无法适应当下的变化
颠覆这些数据分析方法的其实就是数据分析本身,如果参照着这条路走入数据分析,和开历史倒车没有太大区别。
所以我们并不是要否定他们,而是要站在他们的基础上,基于新的变化回答新的问题,甚至给出新的解法。
我们先从熟悉的开始:
一、RFM模型
定义:RFM模型是一种用于分析客户价值和客户行为的方法,主要用于营销和销售策略中。RFM代表三个维度:Recency(最近一次消费),Frequency(消费频率),Monetary(消费金额)。通过这三个维度,企业能够区分不同的客户群体,进而针对性地制定营销策略。


上面是定义,但是我们要提出一个问题:一个企业真的能通过着三个维度来制定营销策略吗?
那拼多多和阿里争的是什么,谁的R设计的比较好?
RFM模型抽象出来,本职上是不断细分用户人群的过程。就像切割蛋糕的手法,通常的就是切三刀分成三块,但是新时代互联网的蛋糕里还有坚果,有奶油层,有草莓。就像我们在业务分享里面提出的,很多分析方法已经受产品功能制约了,没有必要按照老的策略来划分层级。
我们需要从里面了解的是什么呢?
1.RFM的核心是不断精细化用户,从而调配资源给到不同的用户群。
那基于公司内实际的指标和业务,我们是不是不止能产出三个指标,而是多个?并且这些指标最终的目的是要和策略绑定在一起,高净值用户用不同的方式,低净值用户用不同的方式。同理,对于我们分享的共享出行的业务,是否骑行卡用户用不同的方式,骑行卡用户里面月骑行n次的用不同的方式,早高峰骑行的用户用不同的方式?
对于游戏业务来说更通俗易懂,是否对大R用客服去触达,对大部分中小用户用运营活动去触达?对于中小用户来说,是否对长期用户做会员,是否对短期用户做优惠券?
2.指标阈值设定的逻辑是业务+统计学
rfm的输出是高净值和低净值的概念,这个是业务。用通俗的大白话解释是更值钱的用户和不值钱的用户,但是每个业务判断值钱与不值钱是有区别的。例如在共享出行领域,用户每一单天然就花不了三四块钱,我们还要把这些一年花几百块钱骑车的人定义为高净值用户并提供服务吗?他不可能再骑行了,这是个有上限的业务。
那我们应该怎么定义,是否适合从用户留存的角度定义所谓的高价值?有或者说没有高价值,我们更关心大部分小客户的利益呢?
而当指标出来了之后,高价值和高频率这两个指标适合用来划分用户吗?不适合。因为对于单价稳定且小的行业,例如共享出行,休闲游戏,一些日用品消费,高价值一定代表高频率。但是你要是放在航空公司就不一样了,高频率的未必高消费,可能买廉价航空。高消费的未必高频率,可能是跨国出行。
所以在指标的选择上,也要去基于统计学的理念去选择指标和阈值,什么样的指标能把蛋糕分开,什么样的阈值能把人群分开,都是在实际的工作中才能有答案的。
二、帕累托分析
定义:帕累托模型,也称为80/20原则,是一个经济学概念,它指出在许多情况下,大约80%的效果由20%的原因产生。在数据分析领域,这个原则常用于识别最重要的因素,比如最有价值的客户群体、最盈利的产品等。
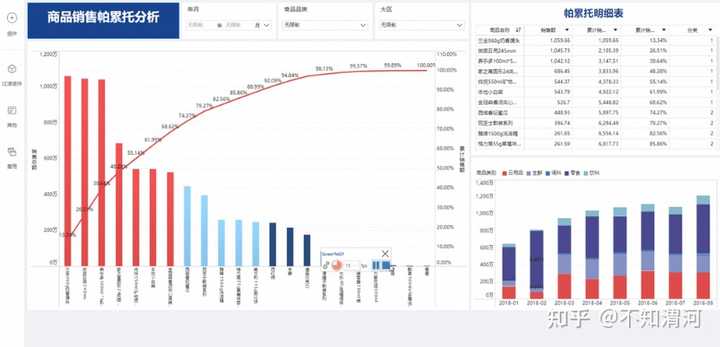

这个就和数据分析完全无关了,因为从两个角度看:1.认为大部分结果由少部分原因引起,这和数据分析没有关系,是社会运行规律;2.20%的产品可能带来80%的收入,这个规则在不同业务是完全不一样的。
在互联网行业,累计分布只有很小的应用场景(当然,有时候推动一些关键点时他也不可或缺)。你会发现在内容行业,可能0.1%的内容贡献了99.9%的阅读量,在点进内容后,可能前1%的评论贡献了99%的曝光,那么帕累托分析的意义在哪里?
答案是,只有当分布已经切割成符合你预期的数据时,帕累托分布才有可视化的意义。例如:在限定某一个价格相近,用户群体相近,时间趋势相似,且用的可能不是绝对数而是相对数的时候(例如不是用购买产品的人的数量,而是不同购买转化率人群的购买总金额的关系),帕累托只是加工的最后一步。
所以对于这个所谓的分析方法,花两三分钟了解就够了,因为重点的工作是在:你到底怎么找到一个符合二八分布的答案。
三、波士顿矩阵
定义:波士顿矩阵(Boston Matrix),又称为BCG矩阵,是一种用于企业战略规划的工具,主要用来帮助公司根据市场增长率和市场占有率对其产品组合进行分类和评估。它将产品或业务单位划分为四个类别:明星、问题儿童、现金牛和瘦狗。
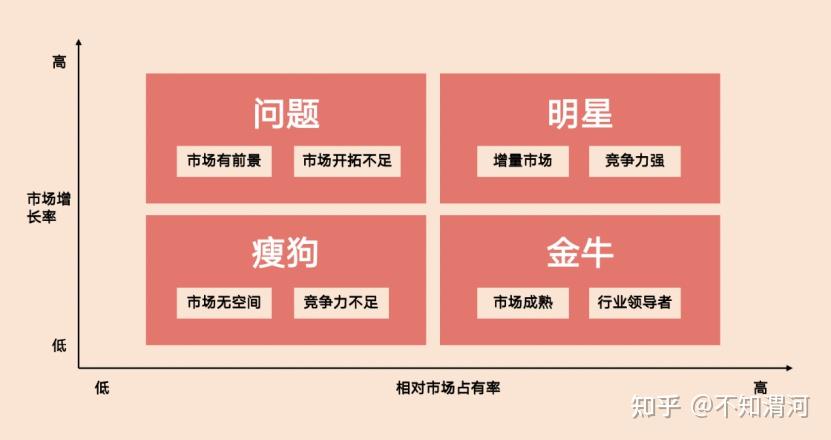

这个和数据分析关系不大,更多是一个归类的想法。输出了大量的知识后,把你的客户进行分类。这种分类其实和RFM是相似的,但是它在大数据出来之前就已经有了,更多是为战略服务。
因为你会发现,市场占有率,增长率这些指标不是数据分析师能取到的。波士顿矩阵里面的很多输入,并非是企业的内部数据。这对于数据分析师来说,其实更像是另一条路——我如何在不依赖内部数据的情况作出判断,或者说,别人怎么做的。
另一方面我们要学习的是,为什么市场增长率和占有率可以作为两个评估的指标。通俗点解读,高增长的一定高占有吗?高占有的一定高增长吗?这在大部分传统企业的场景中是符合的,因为高增长大概率不是大体量,不是大体量自然不是高占有,市占和增长确实是不可兼得。
但是在内容行业比如短视频行业呢,最火的字节跳动能够在20年月活用户已经接近3亿的情况下,在22年跃迁到和微信qq差不多体量的产品,如果只看短视频行业,在20年的时候市占已经很高了,依靠什么去做增长呢?可能只有张一鸣知道了。
所以在真实的商业内部,一方面我们要理解这些分析方法的本质,知道他的适用性和局限性;第二个是我们永远要跳出每一个方法看问题,这些分析方法每一个都是很小的一个点,但是透过他们,我们可能可以用别的指标做相似的分析。例如,内容行业里面的每个赛道的创作者是不是也遵循这个规律?那我可以不可以给这些作者运用这个理念,例如给他们做分赛道的四象限和标签,然后展示给他们,就像再给他们做商业建议一样运用这个矩阵?
这些都是可以更灵活使用这些分析方法的方式。
四:漏斗转化分析
漏斗转化分析也并不重要,更像是一个分析习惯。转化这件事情其实就是比率类指标,用户从新增到激活,从激活到付费,从付费到长期付费,然后到流失,就是一层一层的漏斗。
这好理解,但是在我们分享业务细节里以后你会发现互联网没有漏斗
是踏马的麻花球。


漏斗分析的本质是发现转化率有异常的地方的原因,当漏斗本身比较固定的时候,分析他们轻而易举,就像是检查一辆自行车哪里有问题一样。但是在互联网产品内,新业务,新功能,老板日新月异的新想法,会让这个漏斗根本无法分析。
这对于学习了漏斗分析且真的想用在工作中的人来说,是一个极大的打击,因为根本没有漏斗。
每个互联网产品很复杂,如果你拿放大镜看,产品里可能会有一些漏斗,比如用户从A页面进来,到b页面,到c页面,然后退出。但是在例如淘宝这样的产品中,用户进入B页面的来源可能有十几种,进入A页面的来源也可能有十几种,如果某一条链路数据有波动,看起来是一个问题,但是量级太小又不太可能被解决。如果只看大漏斗,从A-B的数据下降了,中间又有很多小问题混淆视线。
最后的结果是,无论你输出这条漏斗上的什么指标变动了,可能都无法提出策略。方法永远无法落地。
但是回到这个分析的本质上来,一个是抓住变动,一个是抓住原因。
在数据分析师中,这两个问题都用统计学的知识来解决。
变动的问题:漏斗A到B低了,是什么指标低了,有多低,低的程度怎么判断?我们需要对比和分组,结合时间序列来进行说明。
归因的问题:可以用模型来解决,也可以用业务知识来解决。回到了我们之前提到的,先演绎再归纳。模型可以根据历史数据看出问题,但是发现不了最新的问题,业务知识可以弥补这一部分,尤其是在变化很快的业务内。
五、购物篮分析
定义:购物篮分析(Market Basket Analysis)是一种用于发现在购物过程中商品之间的关联规则的数据分析方法。这种分析经常应用于零售行业,帮助识别哪些商品常常一起被购买。这可以指导产品布局、存货管理、交叉销售策略等。
这块属于数据挖掘的初级课程了,作为课程来学习他问题不大,帮助我们了解数据挖掘技术和统计学的结合,例如用概率论原理来对大数据集进行计算。
购物篮分析的核心:
- 关联规则:寻找商品之间购买的关联性。
- 支持度(Support):两种商品一起出现的频率。
- 置信度(Confidence):一种商品被购买时,另一种商品也被购买的条件概率。
- 提升度(Lift):表示在一个商品被购买的条件下,另一个商品被购买的概率增加了多少。
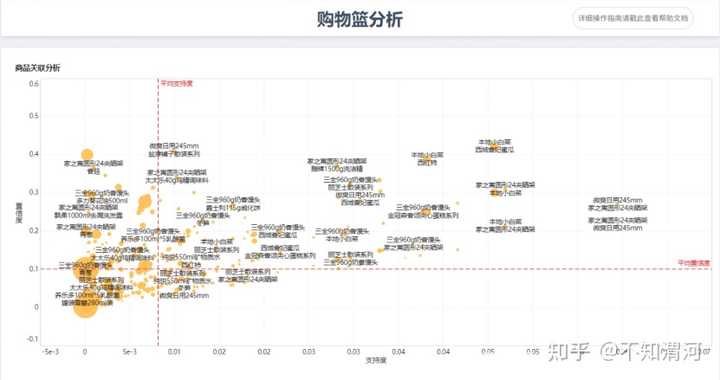

但是在实际的业务中,例如你真的要去考虑两个商品是不是要放一起这件事情来说,或者在互联网产品中,两个推荐位是不是要放一起,我们是否要用这种关联关系去解决呢?
答案是通常是两个部门在做这个事情,因为业务变得复杂,所以分工变得更细了。
一个部门是业务部门,用业务和简单的数据相关性判断是否这两件事情有关联,然后用业务经验来进行归因。这种归因没有太多数学依据更多依靠经验,但是效率高,能解决大部分问题。这个时候数据分析师可能只是简单的输出相关性矩阵,时序曲线的拟合等。
而另一个复杂的归因可能需要上数据科学和建模工具,来做更复杂且原因更明确的归因。但是在大多数小业务中用不上这一点,不过如果后面有相关专家来更新这一块业务知识会更好~
补充一下相关的脚本,由ai辅助完成:
# 导入必要的库
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
# 示例数据
data = [['牛奶', '面包'], ['面包', '啤酒'], ['牛奶', '面包', '啤酒'], ['面包']]
# 数据转换
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 应用Apriori算法
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# 关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
六、复购率分析&Cohort Analysis
复购率分析应该和同期群分析放在一起讲,因为这两个东西虽然方法有一点点区别,但是可视化效果和应用场景是相似的。
复购率分析关注的是客户在首次购买后再次购买的比率;群组分析是将客户分为特定的群组(或批次),这些群组基于共同的特征或经历(如同一时间段内成为客户)。
例如一个场景,连续包月&月卡
用户购买联系包月卡或者月卡,尤其是营收依赖这种长期复购的行业,用户的留存率和月卡的复购率通常是一件事情。相当于原因一致:用户购买月卡的结果是留存,重复购买的结果是长期留存,长期留存的结果是如果发现用户不留存,大概率又通过这种月卡复购的方式来解决问题。
例如:
复购率分析

同期群分析
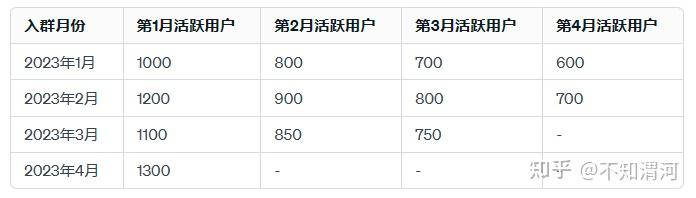

事实上你会发现这两个分析得到的结论非常少。复购本身只能代表一个行为,当付费产品和付费原因比较单一的时候,他还算有用。但是如果这里的复购率发现下降了,能直接引导策略吗?未必,又回到上面的问题,真的降了吗?降了的原因是什么?知道原因了能解决吗?能解决问题的指标应该是什么?
对于我来说,更多的把上面的分析归类到描述性分析的环节,只能分析表面。借着这种分析我们可能发现一两个知识点,方便我们了解或者监控业务大方向,但是依靠他们出具策略,可能要把用户尽可能的细分。例如新客的同期群分析,新客且首日付费的同期群分析,才会得到一些新的答案。
同期群分析相关的sql逻辑(主要难点是时间函数):
-- 创建用户首次活动月份的表
CREATE TABLE user_first_activity_month AS
SELECT
user_id,
MIN(MONTH(activity_date)) AS first_activity_month
FROM
user_activity_bzwh321
GROUP BY
user_id;
-- 同期群分析
SELECT
ufam.first_activity_month,
MONTH(ua.activity_date) AS activity_month,
COUNT(DISTINCT ua.user_id) AS active_users
FROM
user_activity_bzwh321 ua
JOIN
user_first_activity_month ufam ON ua.user_id = ufam.user_id
GROUP BY
ufam.first_activity_month,
MONTH(ua.activity_date)
ORDER BY
ufam.first_activity_month,
MONTH(ua.activity_date);
七、留存分析
没什么好讲的,和上面的复购差不多,要是你真知道留存用户怎么解决,年薪两百万都少了。
大多数对留存的分析只能是表面挠痒痒,以后完全不想看见这种命题过大的分析方式
八、热图分析
热图分析很多时候用在地图上,例如你看到高德地图可能会有一些人群聚集的热区,这种“通过颜色变化来表现数据强度”的变化方式就是热图。
尤其是运用在一些数据量较大,存在渐变,但是有明确的,通过看数字没办法一目了然的情况下,会通过热图的部分展示出来。
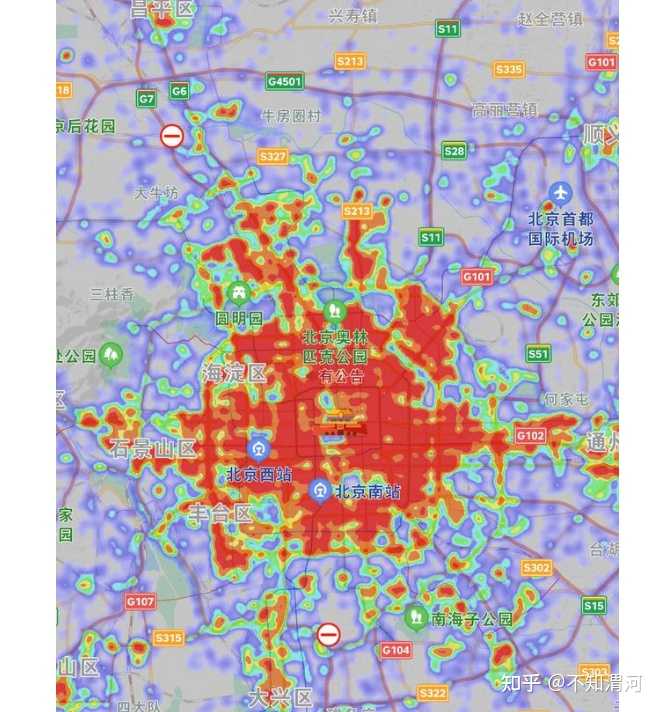

如果把这幅图变成矩阵数据,你会发现理解起来变复杂了。比如在多个方格内,可能是70%,71%,72%,一点点的过渡到80%。细小的渐变会增加分析的难度,但是你也可以通过切割分组来达到类似的效果,只是热力图相对比较高效一点。
但是至于热力图能产生多少价值,取决于你选择的指标本身,而不是热力不热力,热不热本身没那么重要,重要的是你知道什么指标投影到地图上能够产生业务分析的价值。
九、AARRR海盗模型
定义:AARRR模型是一种常用于互联网企业和初创公司的用户行为分析框架。它代表了五个关键阶段:获取(Acquisition)、激活(Activation)、留存(Retention)、收入(Revenue)、推荐(Referral)。这个模型帮助企业专注于转化用户行为,提高用户价值。
这是一个比较老的用户增长模型了,如果仅仅看这个模型你会发现和漏斗分析很像。而在我们说漏斗分析我们提到过一个复杂的变化,就是用户的路径没那么明确了。
我举一个例子,在短视频的业务里,尤其是抖音和小红书这样的产品,用户可以既是用户本身,也可能是内容的提供者。内容的消费者和创作者的界限变得模糊了,尤其是当产品已经存活多年的情况下,谁能说的清楚有多少人是单纯的创作者或者是单纯的消费者呢?
尤其是在没有直接付费的情况下,社区、内容消费者、内容创作者、商业化、商业化商家这些角色的关系是什么?
在互联网末期,用户的获取和激活可能不是大问题。来源变得固定,产品功能也很难变化,用户进来自然知道该怎么用,那么留存和收入就是大问题。
所以这个模型开始变得有些形式化,按照这个模型去分析反而变得模板化。
通常来说,每个分析师可能专注解决其中一个问题,例如收入或者留存。解决收入的背收入指标,解决留存的背留存指标。
但是如果还有机会接触全局视角,我们通常的做法是,挖掘收入和留存中潜在的系统性风险,例如产品目前的数据是否能够达成总的核心目标,如果无法达成,在业务上存在的可能是什么?
例如在共享出行领域,业务目标同时是订单和收入,要维持收入,我们可能希望增加单次付费骑行的比例,要维持订单,我们可能增加连续包月卡的比例。
有点变得依赖财务模型去解决业务问题,只有沉到具体的命题时,比如连续包月的购买率怎么提升上,才依赖数据分析的结果。
所以对于海盗模型来说,他的重点在于产品初期,或者是整个市场初期需要的一些支持,但是在目前大多数产品下,海盗的思想变得不再适用,反而更多从整体和系统的视角出发,在目标上提出新的方向,在风险上做更多监控,这样的思维更符合当下的用人需求

整理了八大数据模型,希望对你有所帮助。
一、用户模型
“不仅要知道用户当下在想什么,更要知道用户背后在想什么,以及用户正在经历着什么。”
传统用户模型构建方式:
- 用户模型:基于对用户的访谈和观察等研究结果建立,严谨可靠但费时;
- 临时用户模型:基于行业专家或市场调查数据对用户的理解建立,快速但容易有偏颇。(缺乏时间,资源的情况下)
为了节省时间,降低风险,产品团队往往尽快将产品推向用户,快速试错,在这种场景下如何构造用户模型?
整理和收集已经获得的任何可认知用户的经验和数据,将这些信息映射成为用户的描述信息(属性)或用户的行为信息,并存储起来形成用户档案;
实时关注自身数据的波动,及时采取行动;
记录用户的行为数据而不是单纯地为用户打标签;
360°覆盖用户全生命周期的用户档案。
用户的每一步成长都通过行为记录下来,基于用户所在生命周期的不同阶段,针对新用户、流失用户、活跃用户、沉默用户分别采取有针对性的拉新、转化、留存等运营策略。

二、事件模型
1. 事件是什么
就是用户在产品上的行为,它是用户行为的一个专业描述,用户在产品上的所有获得的程序反馈都可以抽象为事件,由开发人员通过埋点进行采集。
通俗讲就是:将一段代码放入对应的页面/按钮,用户进入页面/点击按钮的本质是在加载背后的代码,同时再加载事件采集代码,这样就被SDK所记录下来了。
2. 事件的采集
- 事件:用户在产品上的行为
- 属性:描述事件的维度
- 值:属性的内容
- 采集时机:用户点击(click)、网页加载完成、服务器判断返回等。在设计埋点需求文档时,采集时机的说明尤为重要,也是保证数据准确性的核心。
- 举个例子:在采集过程中如果没有明确时机,当用户点击了注册按钮,由于用户输入了错误的注册信息实际没有注册成功,可能仍然会进行记录,这样在统计注册成功事件的时候就不是准确的。
而正确的采集时机描述应该是“服务器返回注册成功的判断”。(日本官网采集的就是返回激活成功或者失败页面)
3. 事件的分析
- 人数:某一事件(行为)有多少人触发了;
- 次数:某一事件(行为)触发了多少次;
- 人均次数:某一事件(行为)平均触发多少次;
- 活跃比:在一个时间区间内,触发某一事件的人数占当前时间段内所有活跃人数的比。
4. 事件的管理
当事件很多时,可以对事件进行分门别类地管理。同时,可以从产品业务角度将重要的用户行为标注出来,以便可以在分析时方便、快捷地查找常用、重要的事件。
三、漏斗模型
漏斗模型帮助你分析一个多步骤过程中每一步的转化与流失情况。
举例来说,用户下载产品的完整流程可能包含以下步骤:


我们可以将如上流程设置为一个漏斗,分析整体的转化情况,以及每一步具体的转化率和转化中位时间。
我们需要将按照流程操作的用户进行各个转化层级上的监控,寻找每个层级的可优化点;对没有按照流程操作的用户绘制他们的转化路径,找到可提升用户体验,缩短路径的空间。
更好的利用漏斗模型:
细化每一个环节,展示到点击之间?点击到下载之间?下载到安装之间?安装到体验之间?
拥有埋点意识和全局观念,才能够有效采集,为每个环节的漏斗优化做出决策依据,推动各个部门优化
四、热图分析模型
1. 什么是热图分析模型
反映用户在网页上的关注点在哪里,尤其对于官网首页来说,信息密度极高,用户究竟是如何点击,如何浏览的效果图。
按计算维度划分,热图可以分为点击热图和浏览热图:
1)点击热图
追踪的是鼠标的点击情况,进行人数、次数统计并基于百分比进行热力分布,点击热图又分为两种,一种是鼠标的所有点击,一种是页面可点击元素的点击。前者可以追踪页面上所有可点击和不可点击位置的被点击情况,后者只追踪页面上可点击元素的点击情况。
2)浏览热图
也称注意力热图,记录的是用户在不同页面或同一页面不同位置停留时间的百分比计算,基于停留时长。
2. 热图分析模型中的新特性
1)面向特定人群的分析与人群对比
比如理财产品,投资用户和未投资用户关注点肯定不同。
2)聚焦分析
点击率= 点击次数/当前页面的浏览次数
聚焦率=点击次数/当前页面的点击总次数
3. 应用场景
落地页效果分析
首页流量追踪
关键页体验衡量(产品体验和下载页面)
自定义留存分析模型
五、自定义留存分析模型
1. 留存定义和公式
1)定义:满足某个条件的用户,在某个时间点有没有进行回访行为
2)公式:若满足某个条件的用户数为n,在某个时间点进行回访行为的用户数为m,那么该时间点的留存率就是m/n
2. 三种留存方式
1)N-day留存:即第几日留存,只计算第N天完成回访行为的用户
2)Unbounded留存(N天内留存):留存会累计计算N天内所有完成过回访行为的用户。
3)Bracket留存 (自定义观察期留存):N-day留存和Unbounded留存都是按照独立的天/周/月为观察单位计算,但有时候我们不希望受限于这种固定时间度量,我们希望划分为几个观察期:
第一个观察期:次日
第二个观察期:第3日-第7日
第三个观察期:第8日-第14日
第四个观察期:第15日到第30日
3. 自定义留存
上述三种留存方式,都是对时间的限定,对留存的定义都是用户打开了APP或进入了网站。
自定义留存是基于业务场景下的留存情况,比如阅读类产品会把看过至少一篇文章的用户定义为真正的留存用户,电商类产品会把至少查看过一次商品详情定义为有效留存。
1)初始行为
初始与回访是相对的概念。
2)回访行为
与初始行为的设定是并且关系。用户的初始行为可以理解为上一次行为,回访行为即理解为下一次行为。
对初始行为和回访行为的设定本质上是在进一步筛选用户群,在滴滴的一次增长分享会曾提到过“抢了红包的用户后来打了车的日留存”,即初始行为是抢了红包,回访行为是打了车。
“抢了红包的用户打了车的3日留存”——即初始行为是抢了红包,回访行为是打车,看这部分人的第三天留存。
六、粘性分析
1. 定义
对活跃用户使用产品的习惯的分析,例如一个月使用了几天,使用大于一天,大于七天的用户有多少。
例如某些产品上线了新功能,用户使用需要签到,可以由此分析出用户的使用习惯,评估新功能的吸引力和健康度。
2. 作用
使用留存分析,了解产品和功能黏住用户的能力如何,用户喜欢哪个功能,不同用户在同一功能在适用上的差异,有助于科学评估产品,制定留存策略
3. 举例
股票APP,已投资用户和未投资的用户触发功能【查看股票市场】的次数。
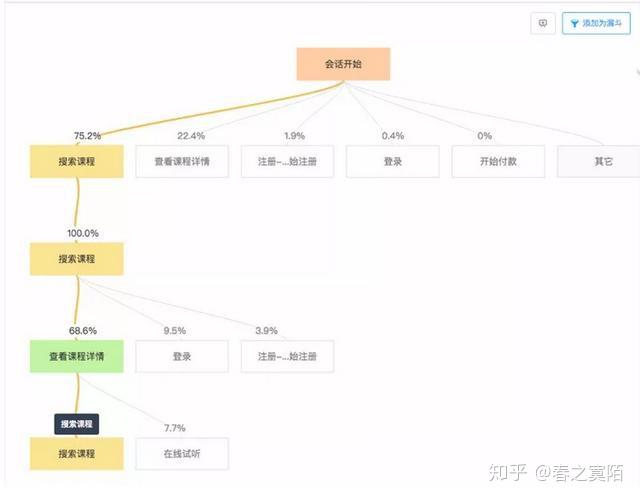
七、全行为路径分析
行为路径分析分为:漏斗分析和全行为路径分析。
- 1)与漏斗分析模型不同,漏斗分析模型是分析既定的行为转化,例如电商产品,分析从查看产品详情到最终支付每一步的转化率。
- 2)而全行为路径分析是对用户在APP或网站的每个模块的流转情况,挖掘用户的访问模式,从而优化产品或网站
一般可用树形图表现,如下图,一个线上培训网站,用户大都会打开搜索课程,所以需要优化搜索课程。
而在第一次搜索课程后,用户并没有搜索到想要的课程,又进行了第二次搜索,因此可以将用户搜索频率高的关键词设置成可点击元素,链接到用户使用频率高的相关课程,引导用户点击得到想要的结果。

八、用户分群模型
分群是对某一特征用户的划分和归组,而分层,更多的是对全量用户的一个管理手段,细分用户的方法其实我们一直在用,比如我们熟悉的RFM模型:
1. RFM模型是从用户的业务数据中提取了三个特征维度:
- 1)最近一次消费时间(Recency)
- 2)消费频率 (Frequency)
- 3)消费金额 (Monetary)
通过这三个维度将用户有效地细分为8个具有不同用户价值及应对策略的群体,如下图所示:


2. 另外四个用户分群的维度
- 1)用户属性:用户客观的属性,描述用户真实人口属性的标签,比如:年龄、性别、城市、浏览器版本、系统版本、操作版本、渠道来源等就是用户属性
- 2)活跃时间
- 3)做过,没做过
- 4)新增于:何时新增用户较多
内容来源:人人都是产品经理官网
想要提升产品运营知识,可以来 @起点学院 听公开课,700位老师不定期的开设各种直播课程


谢邀~
对于一些业务层面的人来说,数据分析这件事其实真的很简单,我们总结了下,常用的分析模型大概有8种, 分别是用户模型、事件模型、漏斗分析模型、热图分析模型、自定义留存分析模型、粘性分析模型、全行为路径分析模型、用户分群模型。
如果能对这几个模型有深刻的认识,数据分析(包括近几年比较热的用户行为数据分析)这点事你就彻底通了。最近,我们在重新写这些模型的逻辑、应用场景、使用方法以及增加的一些新特性。目前更新到了第三个,每周二更新。首发公众号:zhugeio1。
快速入口:
还有一个,下周二发更新~
敬请期待~
客户: 东易日盛 | 向上金服 | 光明随心订 | TutorABC | 麦子学院
指标: 病毒传播系数 | 复购率 | 粘性 | 漏斗 | 太阳图 | KPI
行业: 新零售 | 在线教育 | 科技金融 | 共享单车 | 装修 | 内容社区
产品: 改版评估 | 埋点需求文档 |
运营: 用户运营 | 跨应用市场追踪 | 推送策略 | 运营阶段
市场: 推广三要素 | 智能触达 | 精准推送
其他: 行为数据基础篇 | 客户成功 | 采集模型 | 广告监测
关于我们:
诸葛io定位于为企业提供基于用户行为数据的采集、分析和营销的整体解决方案。是国内领先的数据智能服务商 www.zhugeio.com
目前我们正在为互金/教育/新零售/保险/汽车等行业提供大数据整体解决方案并提供咨询服务。服务客户有:光明随心订、食行生鲜;人人贷、阳光保险、众安保险、平安;宝马、奥迪、大众、NEVS;饿了么;东易日盛等

数据分析是一种思维,一种通过各种方法收集用户的数据、了解用户需求,然后改进个人决策的不断迭代的一种思维。我们经常会遇到各种数据分析场景。
产品上线前,老板会说:做一个数据分析!评估下产品效果!
产品上线中,功能表现的不理想,老板会说:数据表现的不太好,做个数据分析看看原因是什么?
产品上线后,功能表现的好,老板会说:做的不错,做个数据报告总结汇报一下。
我emo了。。。。。。。。

不过数据分析思维也是有模板、有模型可学习,有套路可言的。特别是在学习初期,我们说学习数据分析,基本也就是针对每一个模型去学习了。我想这应该就是题主想要的更具体的数据分析方法论了吧。
数据分析模型大致有这几种:

在讲模型之前,介绍一个数据分析工具FineBI,和Tableau类似,你下面看见的所有数据分析模型都内置于FineBI这个工具中。
虽然是企业级工具,但是对于个人一直是free的,如果你还在用excel或者很复杂的代码来分析数据的话,可以试试BI工具:
下面简单介绍一些这些方法、模型。
1. AARRR 用户运营分析
AARRR 模型又叫海盗模型,是用户运营过程中常用的一种模型,解释了实现用户增长的 5 个指标:获客、激活、留存、收益、传播。从获客到传播推荐,整个 AARRR 模型形成了用户全生命周期的闭环模式,不断扩大用户规模,实现持续增长。
举个例子,我们以某买菜 APP 的这 5 个发展过程进行分析。
1)获客
获客即拉新,即让用户知道了解认识到有这样一个 APP 并来试用。通常情况下会有多个渠道增加产品的曝光,但如何选出最优渠道,使用最少的预算获得最好的拉新效果呢,第一个要做的就是渠道分析。
通常情况下渠道分析有两个维度:获客数量和获客质量。这里我们以平均打开 APP 的浏览时间作为获客质量评价标准。


结论:可以看到线下活动推广的数量与质量都是最优,可以加大线下活动的投入,在超市或菜市场附件做线下活动是最优选项。
2)激活
激活并不直接对等注册成功。激活要做的是活跃客户,更应该考虑的是用户对于产品核心功能的使用情况。 例如:短视频软件需要新用户观看到一定时长、聊天软件需要新用户完成一次对话才算激活。那么在买菜 APP 中,我们认为购买过一次的用户为激活用户。 对各月份的用户新增情况进行分析。


结论:10 月份激活率下降,需要分析具体原因。同时辅助进行新客活动,并做精细化运营,在首页进行个性化推荐产品吸引用户。
3)留存
用户激活之后,不留存的话最终也都将流失,徒劳一场。 所以用户的留存统计也很重要。我们需要计算激活用户的一周留存率/两周留存率/30天留存率。
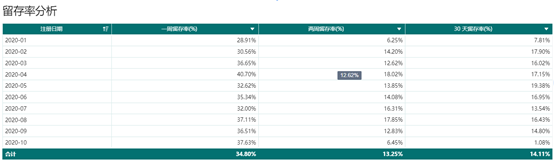

结论:用户留存率有较大空间提高,需要分析流失原因,进一步提高产品体验,挽留已有客户。
4)收益
当用户激活后成为了你的一名用户,需要考虑的就是如何获取收入,实现盈利。买菜软件的盈利与很多指标有关,这里我们暂且以提高用户的购买活跃度作为提高收入的的一个主要方式。 我们将用户分为三个大类:低活跃用户,普通用户,会员用户。使用漏斗图展示。


结论:低活跃用户数量庞大,很有潜力。活跃低活跃的用户,保持会员用户。
5)传播
当产品有了一定规模的用户之后,就需要考虑激发用户间的自发传播。自传播的数据指标是K因子(推荐系数): K = (每个用户向他的朋友们发出的邀请的数量)* (接收到邀请的人转化为新用户的转化率) K值的高低,直接体现自传播结果水平,当K值大于1时,将激发自传播巨大的力量,K值越大,力量越强。而若K值小于1,那么传播水平会逐步减弱,直至消失。


结论:该 APP k值已经大于 1 ,拥有了自传播的力量。可以进一步通过“邀请获红包”等运营活动进一步提高k值,加快传播速度。
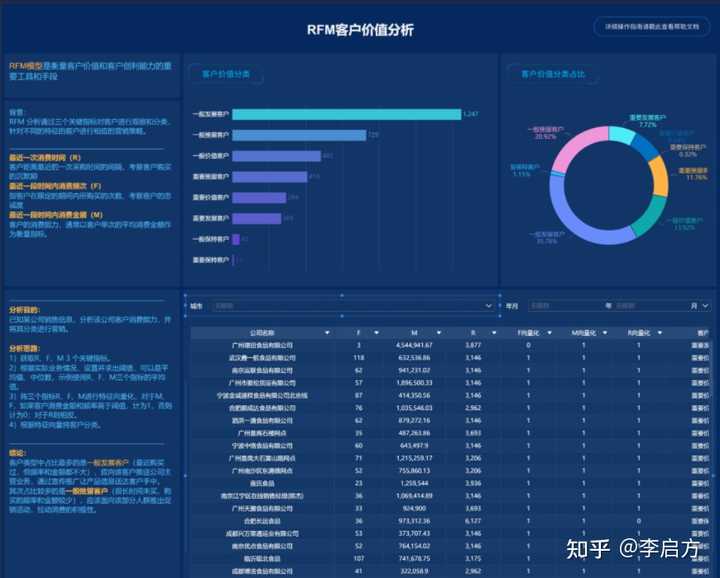
2. RFM模型
RFM 用于对用户进行分类,并判断每类细分用户的价值。
- 最近一次消费时间(R):客户距离最近的一次采购时间的间隔。
- 最近一段时间内消费频次(F):指客户在限定的期间内所购买的次数。
- 最近一段时间内消费金额(M):客户的消费能力,通常以客户单次的平均消费金额作为衡量指标。
这三个关键指标判断客户价值并对客户进行观察和分类,针对不同的特征的客户进行相应的营销策略。


3. 帕累托分析(ABC分析)
帕累托分析又叫 ABC 分析,分类的核心思想:少数项目贡献了大部分价值。以款式和销售量为例:A 款式数量占总体 10% ,却贡献了 80% 的销售额。
把产品或业务分为A、B、 C三类,用于分清业务的重点和非重点,反映出每类产品的价值对库存、销售、成本等总价值的影响,从而实现差异化策略和管理。


4. 波士顿矩阵
波士顿矩阵通过销售增长率(反映市场引力的指标)和市场占有率(反映企业实力的指标)来分析决定企业的产品结构。
波士顿矩阵将产品类型分为四种,如下图所示:


5. 转化分析
转化漏斗模型,是分析用户使用某项业务时,经过一系列步骤转化效果的方法。
转化分析可以分析多种业务场景下转化和流失的情况,不仅找出产品潜在问题的位置,还可以定位每个环节流失用户,进而定向营销促转化。


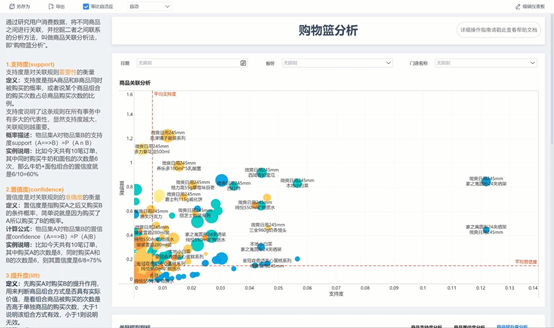
6. 购物篮分析-关联规则
大家应该都听过这样一个经典案例:超市里经常会把婴儿的尿不湿和啤酒放在一起售卖,原因是经过数据分析发现,买尿不湿的家长以父亲居多,如果他们在买尿不湿的同时看到了啤酒,将有很大的概率购买,从而提高啤酒的销售量。

这种通过研究用户消费数据,将不同商品之间进行关联,并挖掘二者之间联系的分析方法,就叫做商品关联分析法,即「购物篮分析」
通过「支持度」、「置信度」、「提升度」三个指标判断商品见的关联。

7. 复购率分析
复购率是指最近一段时间购买次数,用于说明用户的忠诚度,反向则说明商品或服务的用户黏性。
根据购买用户数和复购率时间趋势图,将复购率与用户总数叠加在一起可以看出用户黏性的健康度,最佳状态是复购率不随着用户数量的变化而变化,普遍保持着上升的趋势。
因为随着公司的发展,为公司长期创造价值的用户一定是这些老用户。
用户复购率计算公式:某段时间内购买两次及以上的用户数/有购买行为的总用户数
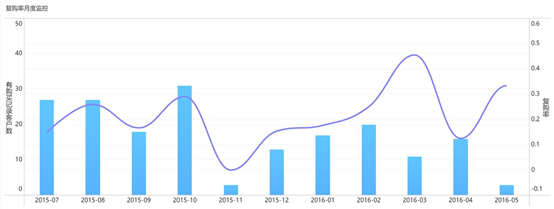

8. 留存分析
留存分析是一种用来分析用户参与情况/活跃程度的分析模型,考查看进行初始行为后的用户中, 经过一段时间后仍然存在客户行为(如登录、消费)。
计算公式:某一段时间内(时间段a)的新增用户在若干天后的另一段时间(时间段b)的留存数量 / (时间段a)的新增用户总量
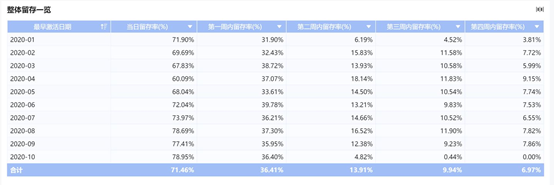

比如,计算用户从激活某产品开始,在当日、一周内、两周内、三周内进行登录使用操作用户数占总登录人数的比率。
当日留存率:当日激活并登录用户数/所有登录用户数
一周留存率:初次激活日为维度,计算「激活_登录时间差」为 1-7 的登录用户数/所有登录用户数
两周留存率:初次激活日为维度,计算「激活_登录时间差」为8-14的登录用户数/所有登录用户数
.....
9. 库存周转分析
库存周转率是企业在一定时期销货成本与平均存货余额的比率,用于反映库存周转快慢程度。周转率越高表明存货周转速度越快,从成本到商品销售到资金回流的周期越短,销售情况越好。
库存周转天数是企业从取得存货开始,至消耗、销售为止所经历的天数。周转天数越少,说明存货变现速度越快,销售状况越良好。
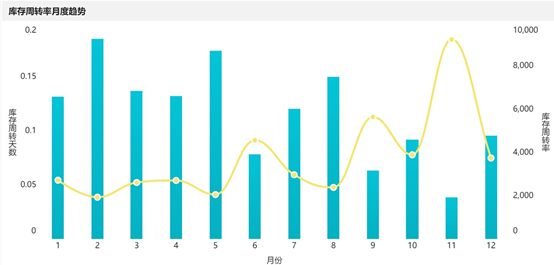

通过计算公式实现:
| 计算内容 | 公式 |
| 平均存货余额 | (期初存货金额+期末存货金额)/2期初存货金额:上期账户结转至本期账户的余额,在数额上等于上期期末金额期末存货金额=期初金额+本期增加发生额-本期减少发生额 |
| 销货成本 | 单件销货成本*销售件数 |
| 库存周转率 | 销货成本/平均存货余额 |
| 库存周转天数 | 360/库存周转率 |
9. 杜邦分析
杜邦分析法利用几种主要的财务比率之间的关系来综合地分析企业的财务状况,用来评价公司盈利能力和股东权益回报水平,从财务角度评价企业绩效。
其基本思想是将企业净资产收益率逐级分解为多项财务比率乘积,这样有助于深入分析比较企业经营业绩。


计算公式为:净资产收益率=销售净利润率*资产周转率*权益乘数
净资产收益率受三类因素影响:
| 指标 | 说明 |
| 销售净利润率=净利润/销售收入 | 表明企业的盈利能力 |
| 资产周转率=销售收入/总资产 | 表明企业的营运能力 |
| 权益乘数=总资产/净资产(权益)=1/(1-资产负债率) | 财务杠杆:用权益乘数衡量,表明企业的资本结构 |
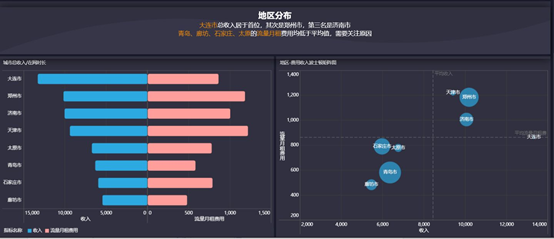
10. 用户画像分析
用户画像就是与该用户相关联的数据的可视化的展现;一句话来总结就是:用户信息标签化。
通过对用户人口属性:用户的年龄、性别、所在的省份和城市、教育程度、婚姻情况、生育情况、工作所在的行业和职业等和行为特征:活跃度、忠诚度等指标进行分析,从而帮助企业对用户进行精准营销、辅助业务决策。



11. 同环比分析
同比发展速度主要是为了消除季节变动的影响,用以说明本期发展水平与去年同期发展水平对比的相对发展速度。
环比表示连续2个统计周期(比如连续两月)内的量的变化比。
计算公式为,
同比:(本期销售额-去年同期销售额)/去年同期销售额
环比:(本期销售额-上个周期销售额)/上个周期销售额
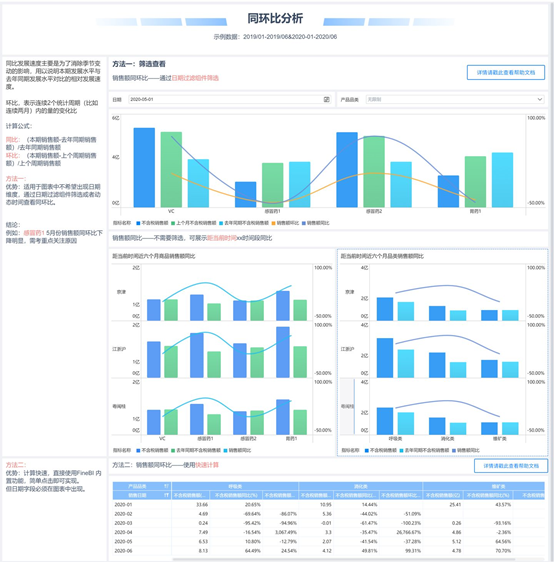

以上图表和数据分析模型均由数据分析工具FineBI所作
数据分析模型教程: 常用数据分析模型与方法- FineBI帮助文档 FineBI帮助文档
先说这么多吧,赞够再更新。
最后分享一些资源:

我有点不明白,在这个回答下面说一大堆理论的意义在哪里?
题主的需求,或者说这个问题潜在关注者的需求是,想知道如何实际应用数据分析模型,给自己的产品带来提升,其次才是知识上的增加。
搞清楚了各位,我先给大家介绍一下模型,然后再来谈谈实际应用方法吧。
AARRR模型
AARRR模型是做数据分析最基础的模型之一了,所谓的AARRR就是指获取、激活、留存、变现和传播。
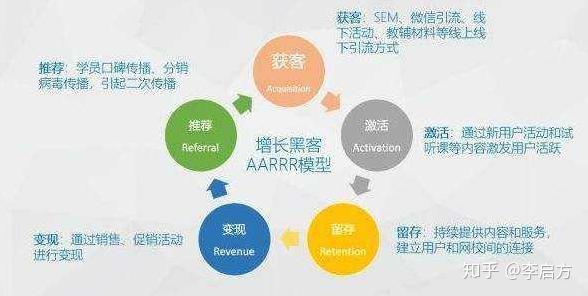

其中,获取就是指获取用户线索,我们可以分析SEO、SEM等分析网站的获取情况;
激活就是指提高用户的活跃程度,主要是通过促销、内容说服等方式让用户成为最有价值的活跃用户;
留存就是把上面的活跃客户沉淀下来,划归到自己的流量池中,比如常见的社区UCG、O2O服务留存等方式,我们可以通过日留存率、周留存率、月留存率等指标监控应用的用户流失情况,并采取相应的手段在用户流失之前,激励这些用户继续使用应用。
变现其实就是获取收入,我们可以通过监控成交率等指标进行分析;
传播是社交网络时代独有的分析方向,只有做到自传播的病毒式才能使自己的用户群群体不断扩大;
5W2H模型
5W2H,即为什么(Why)、什么事(What)、谁(Who)、什么时候(When)、什么地方(Where)、如何做(How)、什么价格(How much),主要用于用户行为分析、业务问题专题分析、营销活动等。
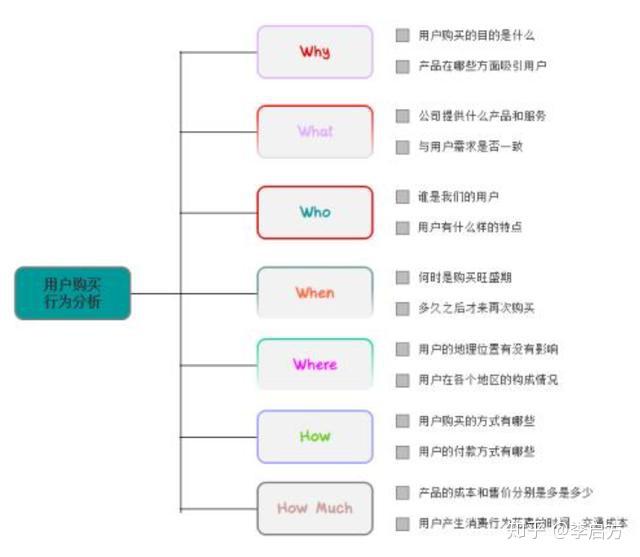

这个模型非常地使用,我们就以用户购买行为为例:
Why:用户为什么要买?产品的吸引点在哪里?
What:用户买的是什么?也就是产品提供的功能是什么?
Who:购买产品的用户是什么群体?这个群体的特点是什么?
When:用户的购买频次是多少?
Where:产品在哪里最受欢迎?在哪个平台卖出去?
How:用户通过什么方式、渠道购买?
How much:用户购买的成本是多少?
篇幅原因,这里就不多说了,完整版在这里:
接下来谈谈让你能挣到钱的数据分析模型,以及如何应用。
帕累托分析模型、四象限模型、RFM模型,都是数据分析中堪称经典的客户模型。下面我会一一介绍它们的应用场景,这在用户运营、市场营销、客户管理等领域常常会用到。
在分析之前,选个好用的工具
像帕累托这种经典模型,其实用excel是很容易做出来的,哪怕是数据分析门外汉也能轻松做出来简易的帕累托模型。
但是毕竟我们是数据分析师,要知道我们的数据维度是相当大的,Excel是肯定不能满足我们的需求。这时候,我们的工具也需要进化了,一般来说我现在都是用专业的BI工具进行数据分析。
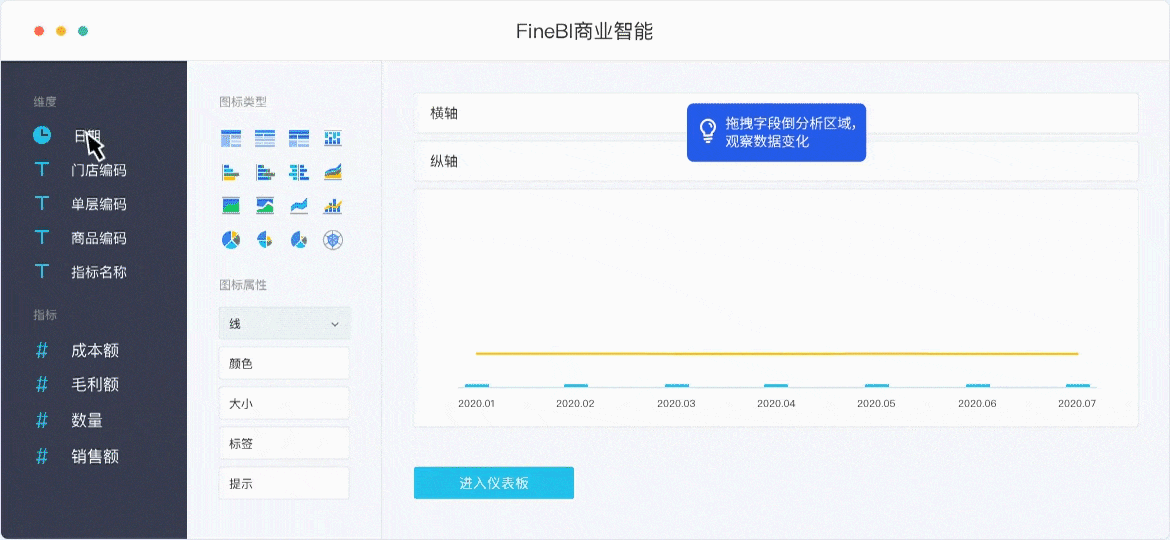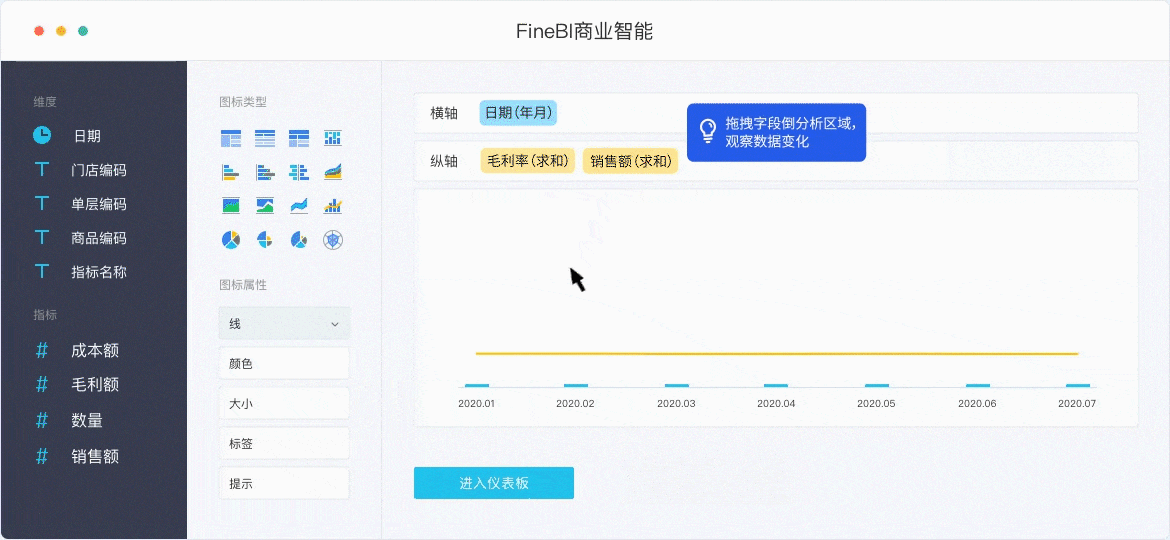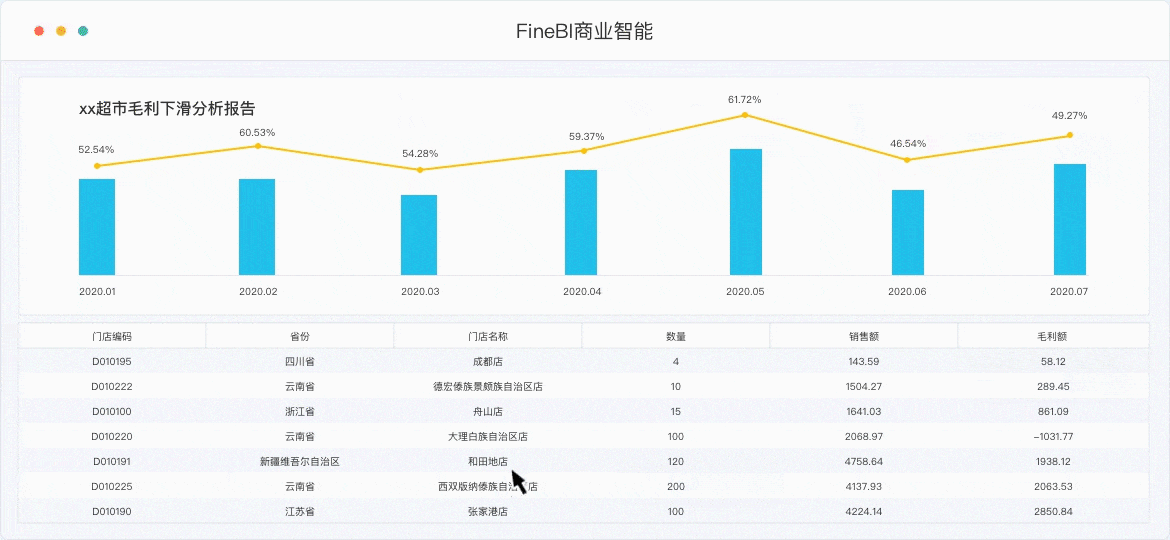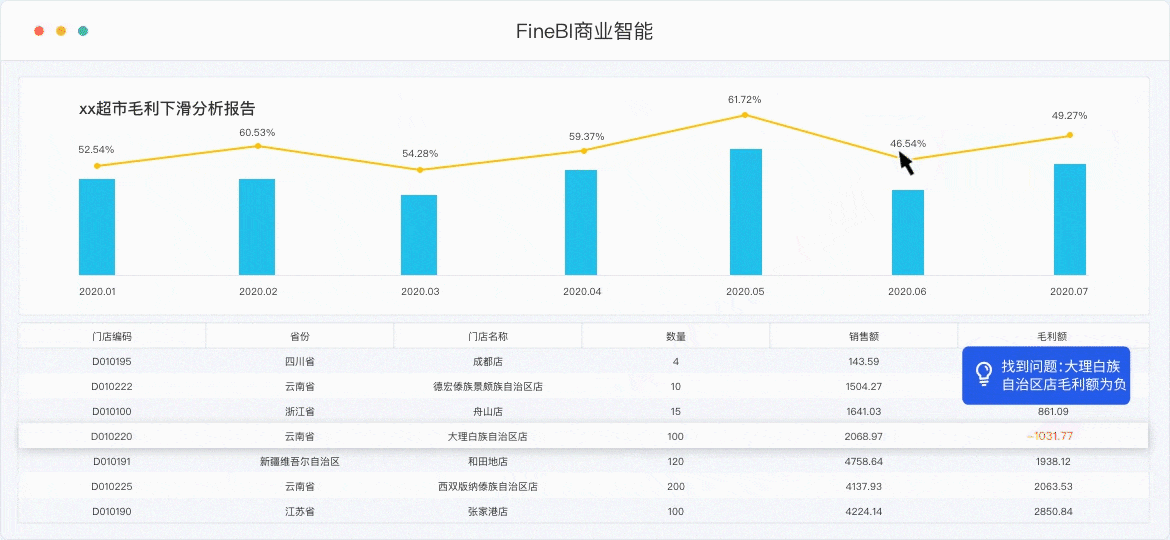

目前市场上的BI工具十分繁多,但是性能也参差不齐,这里我就以国产BI工具的优秀代表 FineBI为例。其实关于FineBI,之前也给大家介绍过很多遍,作为一款自助式的数据分析软件,它的特点就是操作简单上手快,即使是不懂SQL不懂代码的业务人员,花上一天学习,也能上手操作数据,做分析,出可视化。
具体大家可以去官网下载,学习参考他的帮助文档,我做的图有点老了,新版的很好看。
话不多说,直接开始正题。

一、帕累托模型:判断最重要的客户
帕累托原则,又称二八原则,是关于效率与分配的判断方法。帕累托法则是指在任何大系统中,约80%的结果是由该系统中约20%的变量产生的。应用在企业中,就是80%的利润来自于20%的项目或重要客户。
模型的解释:
当一个企业80%利润来自于20%的客户总数时,这个企业客户群体是健康且趋于稳固的。
当一个企业80%利润来自大于20%的客户总数时,企业需要增加大客户的数量。
当一个企业80%利润来自小于20%的客户群时,企业的基础客户群需要拓展与增加。
模型的实际使用:
如下图某商场品牌商的销售额。一共10家客户,5家客户(50%)提供了80%的销售额,这就说明需要增加大品牌客户数量。
(这个例子客户数量较少,不是非常恰当,大家理解意思即可)
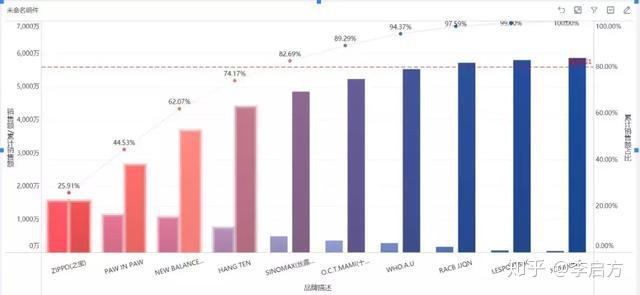

带来大量销售额的客户必须认真对待和维护,如果客户数量大,尤其需要列出重点客户重点跟进,把有限的精力放在创造利润大的客户上。
操作步骤:
首先是基于统计表,使用FineBI中的计算指标功能,简单地写一个计算指标,求销售金额合计,将销售额按照商品进行汇总。

把【商品名称】字段拖动到横轴,【销售总额】拖动纵轴,再按照由大到小降序排列。

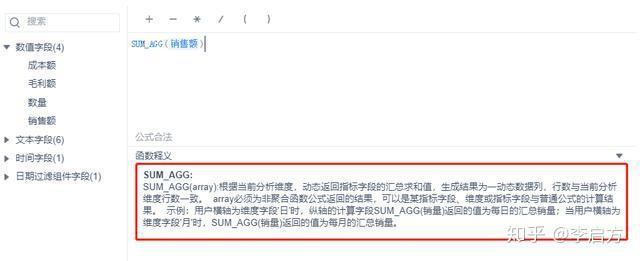
然后求累计销售额,它的计算公式是:
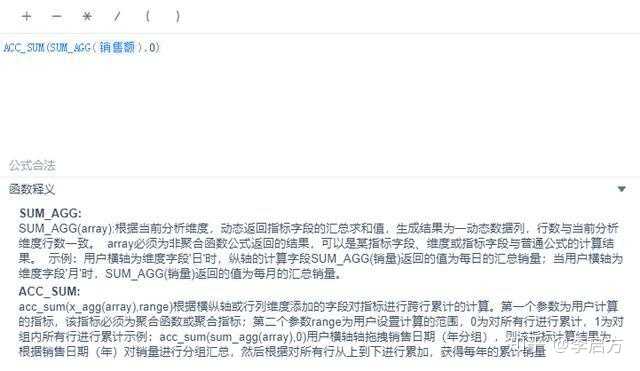

接下来要做的就是使用TOTAL函数计算出所有维度相加的销售总额,之后使用一个简单的除法,算出每个商品的累计销售额占比,之后将他们累加

之后想要做ABC分类其实就是基于不同的累计金额百分比70%,20%,10%做判断区分。比如写一个计算指标ABC

至此,把建立好的度量值拖动到纵轴中即可制成ABC分类表。
最后,制作一张帕累托分析图,它其实就是一张折线与柱形图。只再利用指标的排序功能按照销售额由大到小降序排列。
二、使用四象限法判断哪些是我们最大的客户
四象限最初是一个时间管理模型,按照紧急、不紧急、重要、不重要排列组合分成四个象限,以此便于对时间进行有效的管理。
模型解释:运用在客户分析中,也就是利用销售额和利润这两个重要指标分为四个象限,对我们的客户进行分组。
具体措施如下:
- 销售额高和利润都高的客户:重点对待
- 销售额高但是利润少的客户:一般保持
- 销售额低但是利润高的客户:重点发展
- 销售额和利润双低的客户:需要查明原因
模型的实际使用:
如图所示,每个销售大区与每个销售年份下的客户分布。
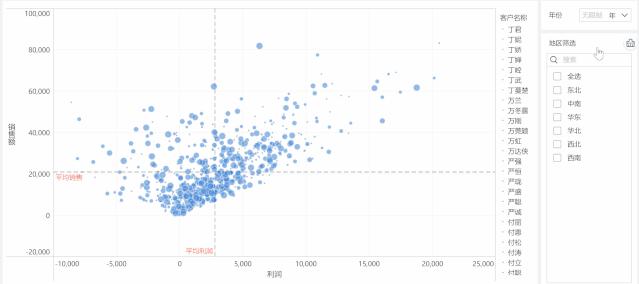
通过筛选数据,我们得到我们想要的客户信息。
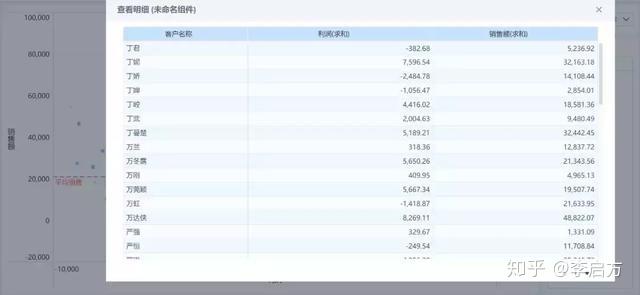

三、使用RFM模型判断客户价值
RFM分析是客户关系分析中一种简单实用客户分析方法,他将最近一次消费、消费频率、消费金额这三个要素构成了数据分析最好的指标,衡量客户价值和客户创利能力。RFM分析也就是通过这个三个指标对客户进行观察和分类,针对不同的特征的客户进行相应的营销策略。
R——最后交易距离当前天数(Recency)
F——累计交易次数(Frequency)
M——累计交易金额(Monetary)
在这三个制约条件下,我们把M值大,也就是贡献金额最大的客户作为“重要客户”,其余则为“一般客户"和”流失客户“。基于此,我们产生了8种不同的客户类型。
模型的解释:
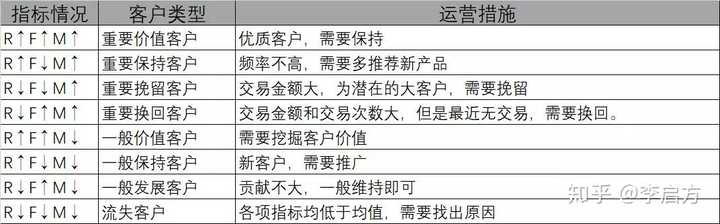

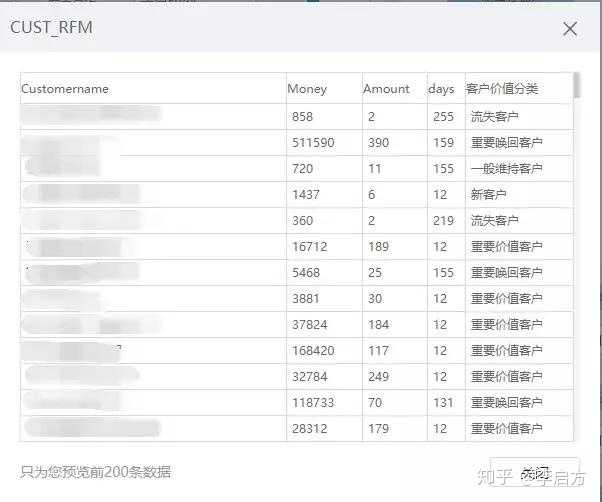
模型的实际应用:
RFM模型主要按照特定的要求将客户筛选出来。

以下是我建立的一个客户筛选可视化模板,可以整体看看客户的情况。

最后,以上模型也可应用在别的业务场景下。比如帕累托模型衍生出的ABC分类法,可用于产品分析。比如将70%,20%,10%的销售额比重把产品分为ABC三类,然后把重点的管理资源放在A,把较少的资源分配给C或者砍掉部分C商品,以达到资源管理的最优状态。

所以,模型的学习关键在于理解原理,以后各项分析都融汇贯通。
PS: FineBI的个人免费版奉上!
最后分享一些BI建设、数据分析相关的优质资料:
相关阅读:
用户分析有哪些经典的模型和方法,如何系统地学习用户分析?
李启方:如何建立销售行业的数据分析模型?
李启方:数据分析中最久负盛名的模型——安索夫矩阵

我会从以下几个问题出发详细聊聊分析方法:
1.什么是分析方法?
2.最常用的 10 种分析方法
3.通过一个案例做到举一反三
一、什么是分析方法?
没有数据分析思路的人经常会有以下 3 种症状。
症状一:没有数据分析意识。
症状表现:经常会说「我觉得」「我感觉」「我认为」。


这类人一切工作靠拍脑袋决定,而不是靠数据分析来支持决策。这就导致:
写了 100 篇文章也不知道什么类型的文章用户会喜欢;
推广了 10 个付费渠道,却不知道钱花得有没有效果;
上线了无数个产品功能,却不知道什么功能对用户更有价值。
他们靠感觉来做事情,而不是用数据分析来做决策。这也是为什么他们浑浑噩噩工作了多年以后,却依然徘徊在基础岗位。
症状二:统计式的数据分析。
症状表现:做了很多图表,却发现不了业务中存在的问题。


这类人每天也按时上班,也用数据做了很多图表,但是只是统计、分析之前已经知道的现象。例如分析结论只是「这个月销售有所下降」,却不会深入分析现象背后发生的原因,从而也得不出什么具有价值的结论。
他们最害怕老板问这样的问题:为什么这个数据会下降?采取什么措施可以解决问题?
症状三:只会使用工具的数据分析。
症状表现:这类人平时学了很多工具(Excel、SQL 或者 Python 等),谈起使用工具的技巧头头是道,但是面对问题,还是不会分析。
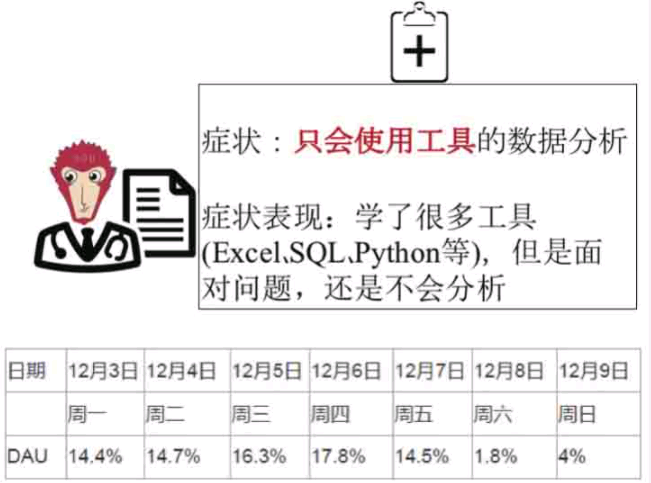

例如面试或者工作里经常遇到这样的问题:
上图表格是一家公司 App 的一周日活跃率,老板交给你以下任务:
(1)从数据中你看到了什么问题?你觉得背后的原因是什么?
(2)提出一个有效的运营改进计划。
你可能有这样的感觉:
面对问题,没有思路,怎么办呢?
面对一堆数据,我该如何下手去分析呢?
这些症状是大部分运营人员、产品经理和数据分析相关从业人员的真实日常写照。
那究竟什么是数据分析思路呢?
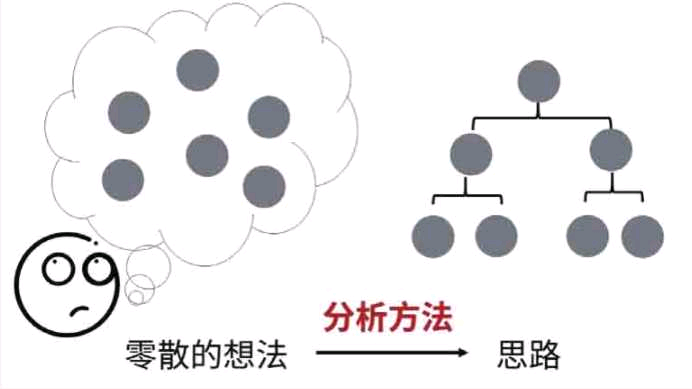
到底什么是数据分析思维?
面对问题,通常的想法是零散的,没有一点思路。如果能将零散的想法整理成有条理的思路,从而快速解决问题,那该多好呀!
有什么方法可以将零散的想法整理成有条理的分析思路呢?这些方法就是分析方法。掌握了分析方法就可以具备这种能力。
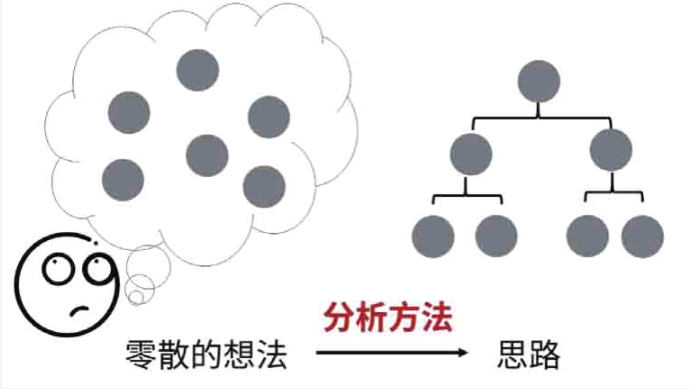

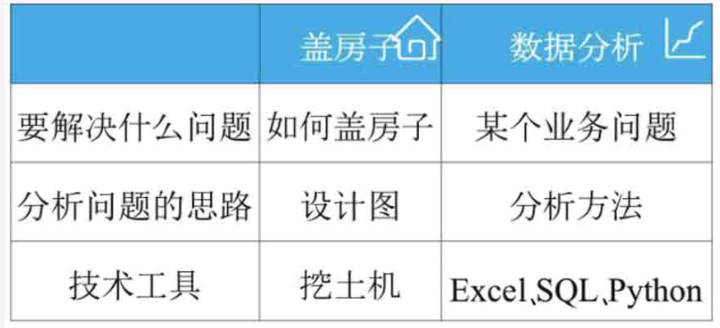
将分析方法和盖房子做个类比(图 2-5),分析方法就好比在盖房子前画的设计图,用来指导如何盖房子,是分析问题的思路。数据分析的技术工具好比盖房子中 的挖土机等工具。在设计图的指导下才知道如何使用挖土机来盖好房子。同样,在分析方法的指导下你才能知道如何使用工具(Excel、SQL 或者 Python 等)去分析数据,解决业务问题。

如果想零经验转行数据分析,首先需要做到两点:掌握入门工具 Excel+具备基本的数据分析思维。不建议自己去找一堆资料抱着啃,因为这样既没体系又不保证效果。入门其实找个免费课听听,了解下基本情况就差不多了。
这里推荐知乎知学堂的训练营:既有 Excel 透视图表等数据分析基础功能实操带练,还有数据分析工作流+基础分析模型逻辑架构精讲,配合免费课程资料+真实案例拆解,轻松上手数据分析入门!有需要的点击链接即可:
二.最常用的 10 种分析方法
前面我们知道了,具备数据分析思路的本质是掌握常用的分析方法。所以,问题倒也变的简单了,只要你掌握常用的分析方法,数据分析思路自然就有了。
常用的分析方法有哪些?
根据业务场景中分析目的的不同,可以选择对应的分析方法。我把常用的分析方法整理到下表了,你直接拿着用就可以了。
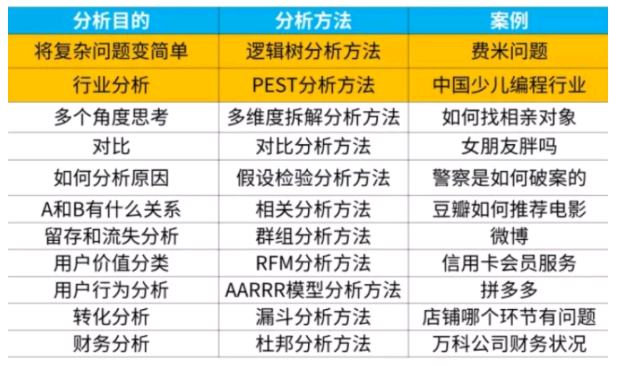

如果你的分析目的是想将复杂问题变得简单,就可以使用 逻辑树分析方法,例如经典的费米问题就可以用这个分析方法。
如果你的分析目的是做行业分析,那么就可以用 PEST 分析方法,例如你想要研究 中国少儿编程行业。
如果你想从多个角度去思考问题,那么就可以用多维度拆解分析方法,例如找相亲对象,需要从多个角度去分析是否合适。
如果你想进行对比分析,就要用到对比分析方法,例如你朋友问自己胖吗,就是在对比。
如果你想找到问题发生的原因,那么就要用到假设检验分析方法,其实破案剧里警察就是用这个方法来破案的。
如果你想知道 A 和 B 有什么关系,就要用到相关分析方法,例如豆瓣在我们喜欢的电影下面推荐和这部分电影相关的电影。
如果你想对用户留存和流失分析,就要用到 群组分析方法,例如微博用户留存分析。
如果你想对用户按价值分类,那么就要用到 RFM 分析方法,例如信用卡的会员服务,就是对用户按价值分类,对不同用户使用不同的营销策略,从而做到精细化运营。
如果你想分析用户的行为或者做产品运营,就要用到 AARRR 模型分析方法,例如对拼多多的用户进行分析。
如果你想分析用户的转化,就要用到 漏斗分析方法,例如店铺本周销量下降,想知道是中间哪个业务环节出了问题。
这几个分析方法是最常用的,掌握它们,可以帮助解决大部分问题。后文会分别讲解各个分析方法,最后再通过几个案例来看如何在实际的问题中灵活使用这些分析方法。
在工作或者面试中,会经常听到分析思维、分析思路、分析方法。这三个词语有什么关系呢?其实简单来说,它们都是指分析方法。因为分析方法是将零散的想法整理成有条理的分析思路。有了分析思路,你就具备了分析思维。
三.通过一个案例做到举一反三
应用数据分析思路解决问题,可以使用我总结的以下步骤:
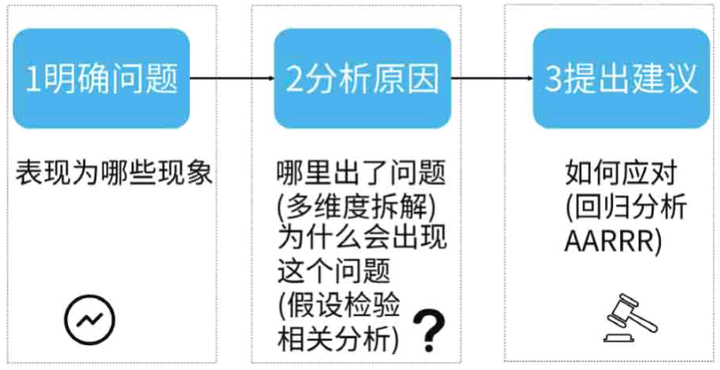

第 1 步:明确问题。
通过观察现象,把问题定义清楚,这是数据分析的第 1 步。只有明确了问题,才能围绕这个问题展开后面的分析。如果一开始问题就定义错了,那再怎么分析,也是白费时间。
第 2 步:分析原因。
这一步是分析问题发生的原因,可以通过下面两个问题把原因搞清楚:①哪里出了问题?②为什么会出现这个问题?具体分析步骤如下:
(1)使用「多维度拆解分析方法」对问题进行拆解,将一个复杂问题细化成各个子问题;
(2)对拆解的每个部分,使用「假设检验分析方法」找到哪里出了问题。分析的过程可以用「 对比分析方法」等多个分析方法来辅助完成;
(3)在找到哪里出了问题以后,可以多问自己「为什么出现了这个问题」,然后使用「相关分析方法」进行深入分析。
第 3 步:提出建议。
找到原因就完事了吗?还不行,要找到对应的办法才是分析的终点。所以,找到原因以后,还要针对原因给出建议,或者提出可以实施的解决方案。在决策这一步,常用的分析方法是回归分析或者 AARRR 分析。需要注意的是:
(1)做决策的选项不能太多。太多的选项不仅会增加决策的成本,还会让人迷失,无从下手。相对简单的问题,需要 4 个选项左右;相对复杂的问题,需要 4~7 个选项;
(2)决策要是可以落地的具体措施,这样决策者才能根据措施,合理安排资源,把措施变成行动。
光说不练,那是假把式。下面我们通过一个案例实际应用下,你就融会贯通啦。


【案例】
某 App 3 月 10 日-3 月 12 几天的整体充值收入提升非常明显(大于 50%),但是,在整体充值中,占 80% 以上的功能充值的收入下降明显(大于 50%)。这期间可能发生了什么?
1.如何解读本组数据,写出你对该问题的分析步骤
2.根据上述分析,提出你对该问题的几种猜测
3.如果猜测都是需要解决的问题,请提出你的解决方案,并设计可行性的实验
【分析思路】
根据前面说的「 数据分析解决问题的步骤」来解决业务问题。
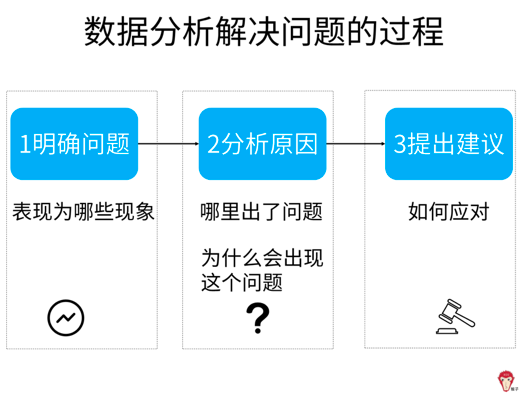

一、明确问题
1.明确据来源和准确性
从时间、地点、数据来源这 3 个维度来展开确定数据的来源和准确性。
时间:3.10-3.12 的时间范围内出现问题
地点: 全国地区
数据来源:与相关人员沟通后,数据准确无问题
2.业务指标理解
充值收入=付费人数*平均单价
因为问题中还提到收入上升、下降的问题,所以,我们要清楚这是在和谁比。本案例是与之前的收入相比较得出的结论。
我们观察数据发现,整体数据与部分数据呈现出完全相反的结论,也就是题目中所说的,整体充值收入提升了,但是占 80% 以上的功能充值的收入下降了。
这让我们想起了在「 多维度拆解分析方法」中讲过的辛普森悖论(考查数据整体和数据不同部分会得到完全相反的结论 ),这是因为只看数据整体无法注意到数据内部各个部分构成要素的差异,忽略差异,导致无法观察到差异的影响。
如何分析这样的问题呢?
可以运用多维度拆解分析方法,把整体拆解成部分,然后查看内部的差异。那么,从哪些方面进行拆解呢?
可以从指标构成维度进行拆解,整体充值=占收入 80% 以上的功能充值(记为原核心充值)+占收入 20% 以下的功能充值(记为其他充值)
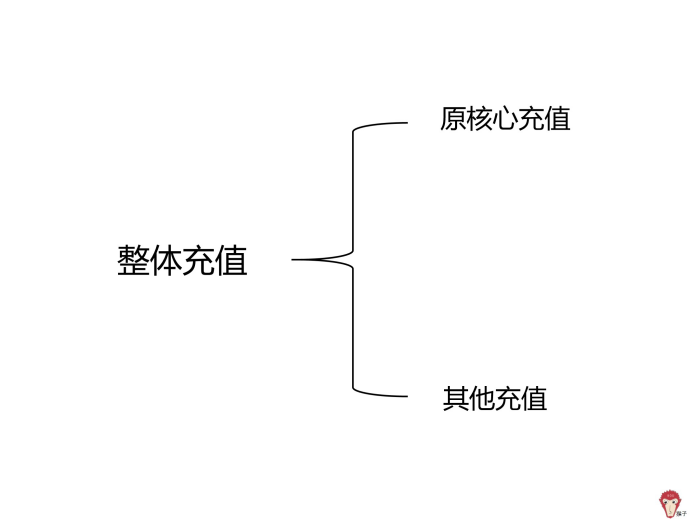

整体充值收入提升,其中原核心充值收入下降,根据上图的拆解可以得出,其他充值收入是上升的。
所以,现在的问题明确为:为什么原核心充值收入下降?
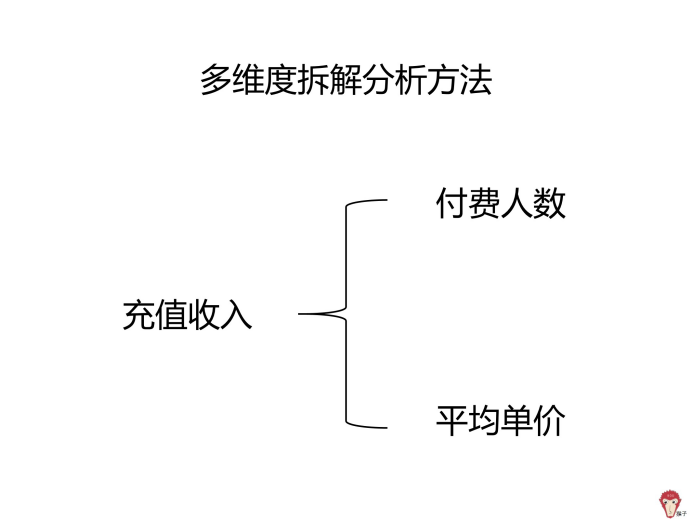
二、分析原因
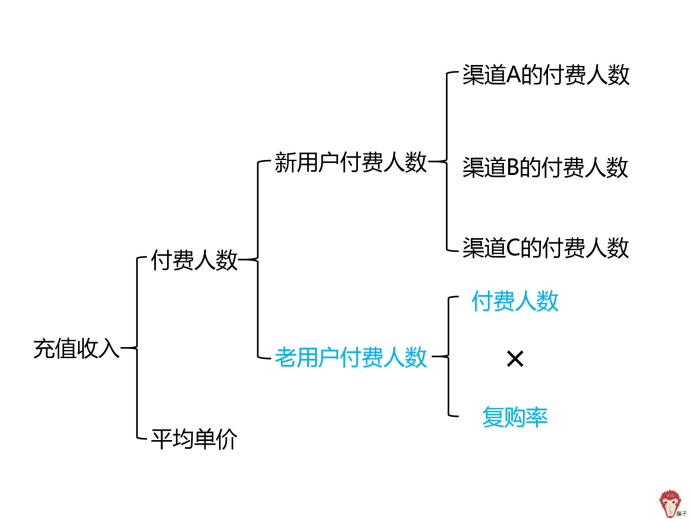
当需要分析问题出现的原因时,可以使用多维度拆解分析方法对「充值收入」这个指标进行拆解。
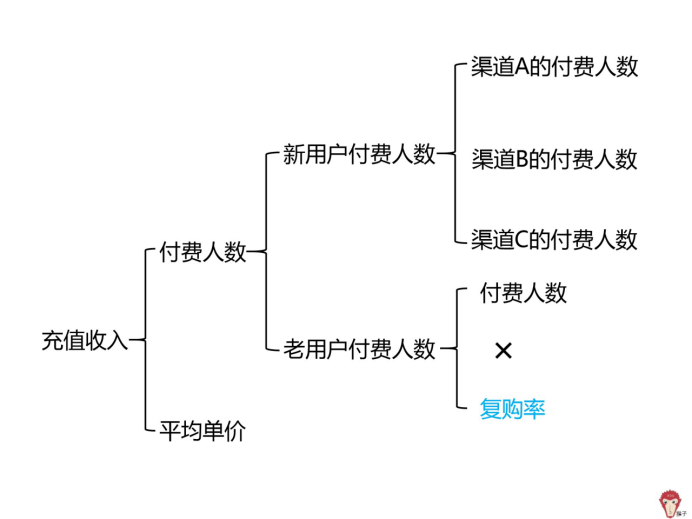
充值收入=付费人数*平均单价。因此,可以拆分为付费人数」和「平均单价」。

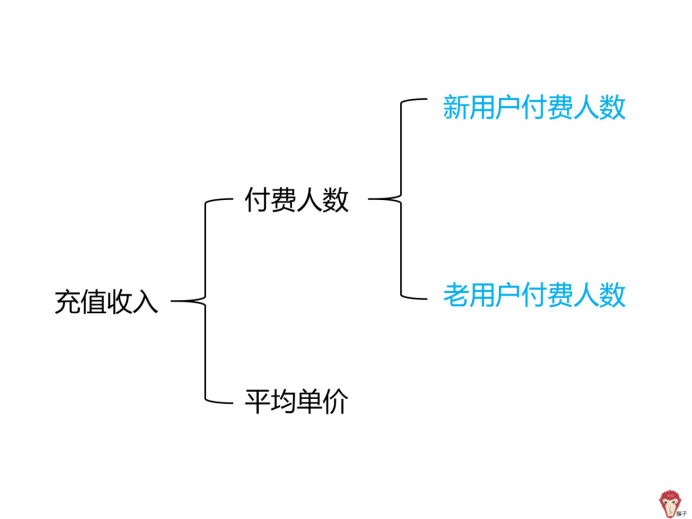
现在还是无法找出「哪里出了问题。所以,我们从「用户是否首次购买」维度,把「 付费人数「继续拆解为「新用户付费人数」和「老用户付费人数」。
其中,「新用户付费人数 」是首次在该 APP 充值的用户有多少人,「老用户付费人数」是之前在该 APP 充值过,再次进行充值的用户人数。

新用户付费人数按渠道维度,又可继续拆解为渠道 A 的付费人数、渠道 B 的付费人数、渠道 C 的付费人数。
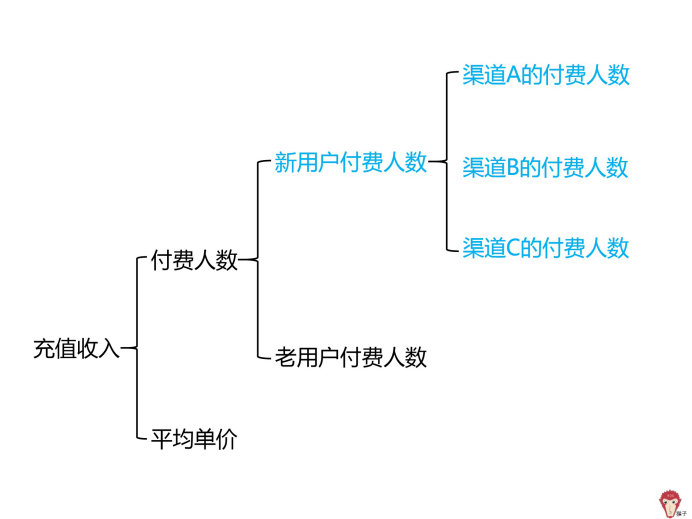

我们将「老用户付费人数」继续拆解为「再次充值」的老用户和「不再充值」的老用户。我们可以使用复购率来进行衡量,老用户付费人数=付费人数 * 复购率

接下来我们用假设检验方法对「多维度拆解分析方法」里面的每个部分进行验证。
1.提出假设:问题出在平均单价
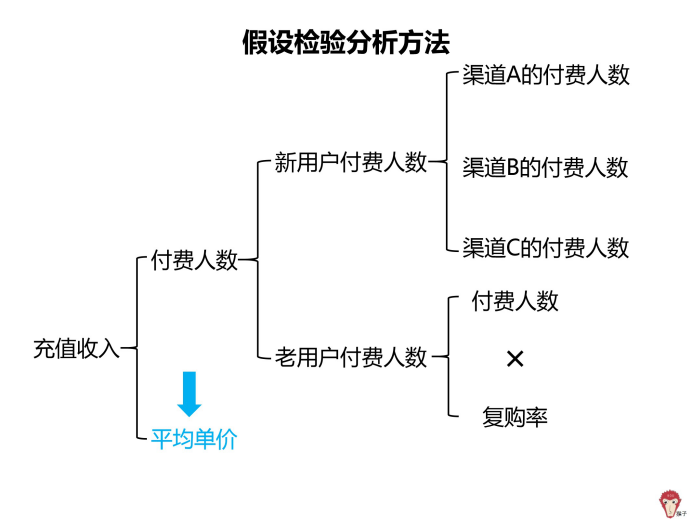

假设 1:A 的平均单价下降,导致充值下降
2.提出假设:问题出在付费人数
这时需要对付费人数的组成部分进一步分析,也就是新用户付费人数和老用户付费人数。
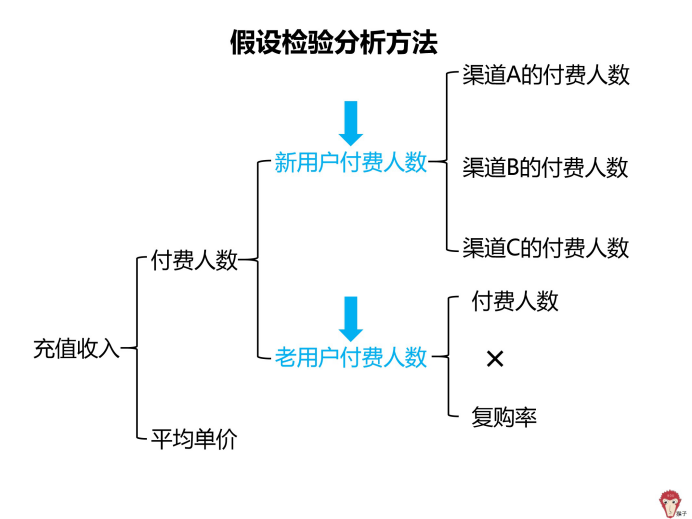

假设新用户付费人数出了问题。可以拆解为渠道 A 的付费人数、渠道 B 的付费人数、渠道 C 的付费人数。
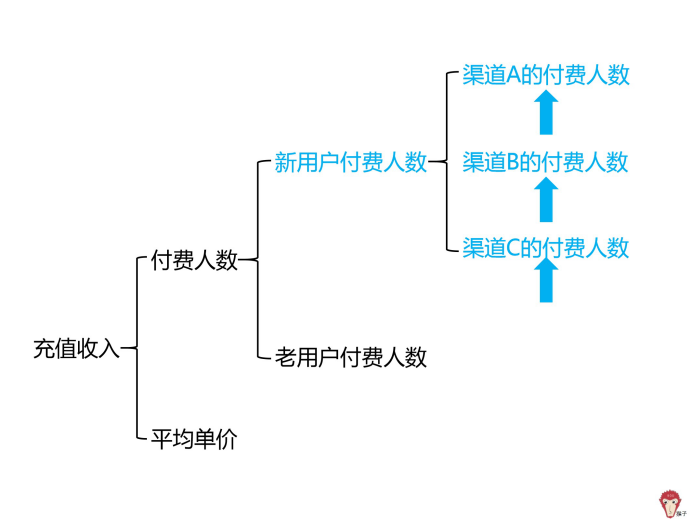

假设 2:渠道 A 或 B 或 C 的付费人数减少
3.提出假设:老付费用户人数出了问题
付费人数前面已经分析过了,所以问题主要在「复购率」上,有可能是复购率降低。那么复购率为什么会下降呢?

为了找到复购率低的原因,我们梳理产品的业务流程,方便从业务流程提出假设。
用户在该 App 充值的业务流程是:
第 1 步,查看功能介绍,选择功能充值
第 2 步,进行支付
第 3 步,使用原核心功能
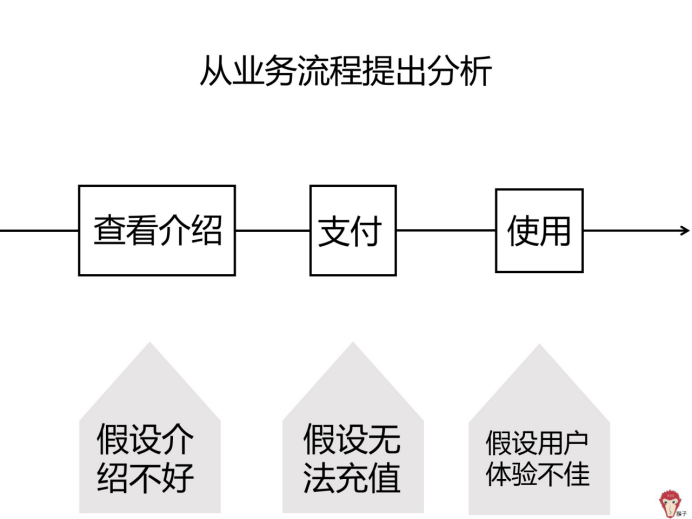
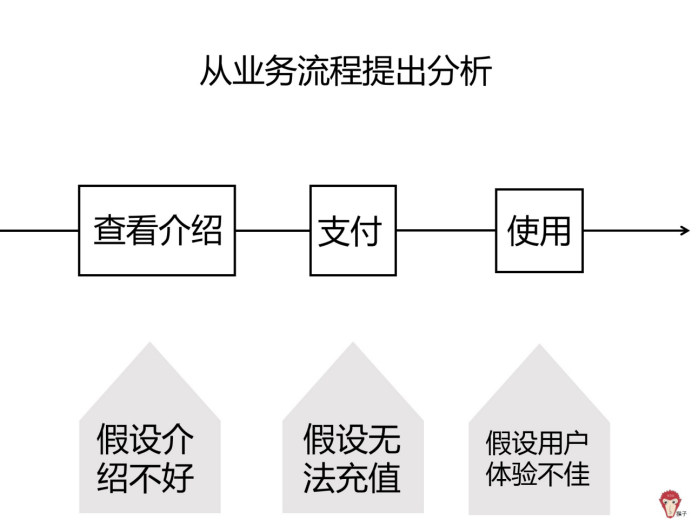
第 1 步,我们可以提出假设 3:假设功能介绍不好,不吸引人
第 2 步,我们可以提出假设 4:假设部分用户无法充值
第 3 步,我们可以提出假设 5:用户使用体验不佳
4.收集证据
前面已经提出了假设,到这一步就可以收集证据,来验证假设。
我们可以和之前的数据进行对比分析,比如通过问卷调研或者电话访谈用户,来看「原核心功能充值」哪里出现了问题。
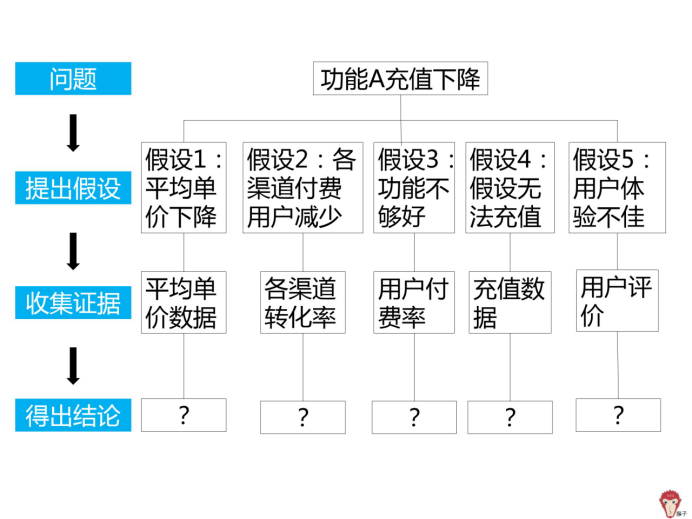

假设以上猜测都有问题。
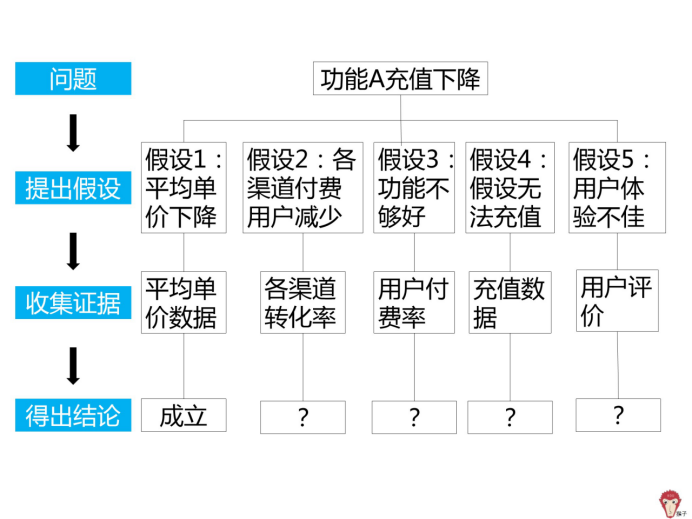
先来看假设 1:平均单价下降
对比之前的单价数据,发现 3.10-3.12 有促销活动,平均单价确实出现下降。所以得出结论假设 1 成立。

再来看第 2 个假设:各渠道付费用户减少
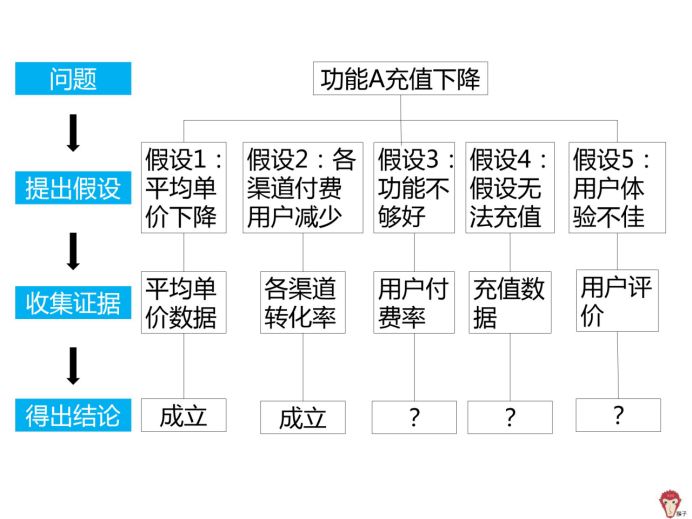
查看日新增用户数、渠道曝光率和渠道转化率等数据,发现各渠道用户减少,付费用户也减少,所以得出结论假设 2 成立。

再来看第 3 个假设:功能介绍不吸引人
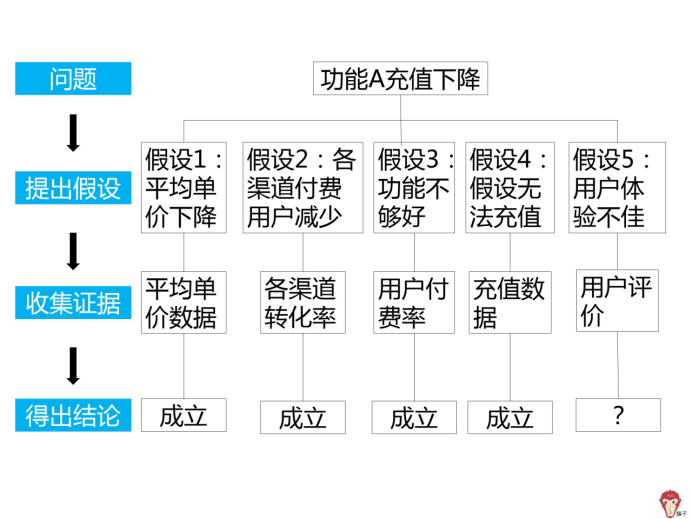
通过对比查看功能介绍的数据和点击支付的数据,发现支付转化率不高。所以得出结论假设 3 成立。


再来看第 4 个假设:部分用户无法充值
查看用户反馈,请技术人员测试支付过程,发现支付过程有问题。所以得出结论假设 4 成立。

再来看第 5 个假设:用户使用体验不佳
与产品部门交流,发现产品近期有改动,新功能改动取代了原核心功能需求。所以得出结论假设 5 成立。
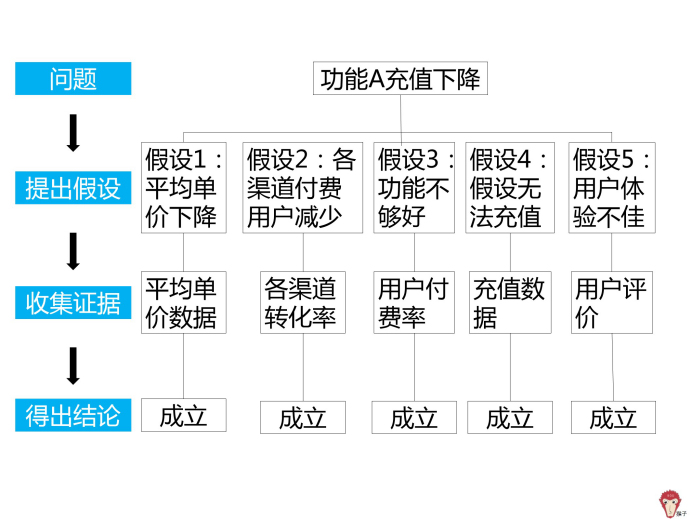

我们总结下,原核心功能收入大幅下降,是因为:
1)平均单价下降
2)各渠道付费用户减少
3)功能介绍不吸引人
4)部分用户无法充值
5)用户使用体验不佳
三、提出建议
原因 1:因为促销活动,平均单价下降。等待促销完成即可。
原因 2:是各渠道付费用户减少。可以调整渠道,获取产品对标的精准用户。
原因 3:功能介绍不吸引人。重新设计介绍页面,更贴合用户需求。
原因 4:部分用户无法充值。请技术人员进行修复。
原因 5:用户使用体验不佳。对部分用户推更新版本,建立对照组,进行 AB 测试。
四、总结
1.什么是数据分析思路?
数据分析思路的本质是掌握常用的分析方法。

2.如何具有数据分析思路?
掌握下面 10 种常用的分析方法。


3.用数据分析解决问题的 3 步骤


第 1 步:明确问题。明确数据来源和准确性,理解业务指标,把问题定义清楚。
第 2 步:分析问题。分析问题发生的原因,使用「多维度拆解分析方法」拆解问题,把复杂问题简单化;使用「假设检验分析方法」找出哪里出了问题;使用「相关分析方法」解决为什么出现这个问题。
第 3 步:提出建议。针对原因给出建议,或者提出可以实施的解决方案, 常用回归分析方法或 AARRR 分析方法。
当然,这些方法+案例只是 3 天的数据分析视频课的一小部分,篇幅有限,完整版建议直接看课程视频:不仅有常用数据分析模型精讲,还拆解数据分析工作流+基础数据工具实操带练。还有更多大厂一线业务案例实战演练+配套免费资料,如果这么多干货分析消化起来困难,想走捷径,快速上手数据分析入门,建议点击链接参加:
本文作者:猴子

数据角度的模型一般指的是统计或数据挖掘、机器学习、人工智能等类型的模型,基本是纯粹从科学角度出发定义的,本文介绍10种常用的数据模型供参考。
1. 降维
在面对海量数据或大数据进行数据挖掘时,通常会面临“维度灾难”,原因是数据集的维度可以不断增加直至无穷多,但计算机的处理能力和速度却是有限的;另外,数据集的大量维度之间可能存在共线性的关系,这会直接导致学习模型的健壮性不够,甚至很多时候算法结果会失效。因此,我们需要降低维度数量并降低维度间共线性影响。
数据降维也被成为数据归约或数据约减,其目的是减少参与数据计算和建模维度的数量。数据降维的思路有两类:一类是基于特征选择的降维,一类是是基于维度转换的降维。
2. 回归
回归是研究自变量x对因变量y影响的一种数据分析方法。最简单的回归模型是一元线性回归(只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示),可以表示为Y=β0+β1x+ε,其中Y为因变量,x为自变量,β1为影响系数,β0为截距,ε为随机误差。
回归分析按照自变量的个数分为一元回归模型和多元回归模型;按照影响是否线性分为线性回归和非线性回归。
3. 聚类
聚类是数据挖掘和计算中的基本任务,聚类是将大量数据集中具有“相似”特征的数据点划分为统一类别,并最终生成多个类的方法。聚类分析的基本思想是“物以类聚、人以群分”,因此大量的数据集中必然存在相似的数据点,基于这个假设就可以将数据区分出来,并发现每个数据集(分类)的特征。
4. 分类
分类算法通过对已知类别训练集的计算和分析,从中发现类别规则,以此预测新数据的类别的一类算法。分类算法是解决分类问题的方法,是数据挖掘、机器学习和模式识别中一个重要的研究领域。
5. 关联
关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则,它是从大量数据中发现多种数据之间关系的一种方法,另外,它还可以基于时间序列对多种数据间的关系进行挖掘。关联分析的典型案例是“啤酒和尿布”的捆绑销售,即买了尿布的用户还会一起买啤酒。
6. 时间序列
时间序列是用来研究数据随时间变化趋势而变化的一类算法,它是一种常用的回归预测方法。它的原理是事物的连续性,所谓连续性是指客观事物的发展具有合乎规律的连续性,事物发展是按照它本身固有的规律进行的。在一定条件下,只要规律赖以发生作用的条件不产生质的变化,则事物的基本发展趋势在未来就还会延续下去。
7. 异常检测
大多数数据挖掘或数据工作中,异常值都会在数据的预处理过程中被认为是“噪音”而剔除,以避免其对总体数据评估和分析挖掘的影响。但某些情况下,如果数据工作的目标就是围绕异常值,那么这些异常值会成为数据工作的焦点。
数据集中的异常数据通常被成为异常点、离群点或孤立点等,典型特征是这些数据的特征或规则与大多数数据不一致,呈现出“异常”的特点,而检测这些数据的方法被称为异常检测。
8. 协同过滤
协同过滤(Collaborative Filtering,CF))是利用集体智慧的一个典型方法,常被用于分辨特定对象(通常是人)可能感兴趣的项目(项目可能是商品、资讯、书籍、音乐、帖子等),这些感兴趣的内容来源于其他类似人群的兴趣和爱好,然后被作为推荐内容推荐给特定对象。
9. 主题模型
主题模型(Topic Model),是提炼出文字中隐含主题的一种建模方法。在统计学中,主题就是词汇表或特定词语的词语概率分布模型。所谓主题,是文字(文章、话语、句子)所表达的中心思想或核心概念。
10. 路径、漏斗、归因模型
路径分析、漏斗分析、归因分析和热力图分析原本是网站数据分析的常用分析方法,但随着认知计算、机器学习、深度学习等方法的应用,原本很难衡量的线下用户行为正在被识别、分析、关联、打通,使得这些方法也可以应用到线下客户行为和转化分析。