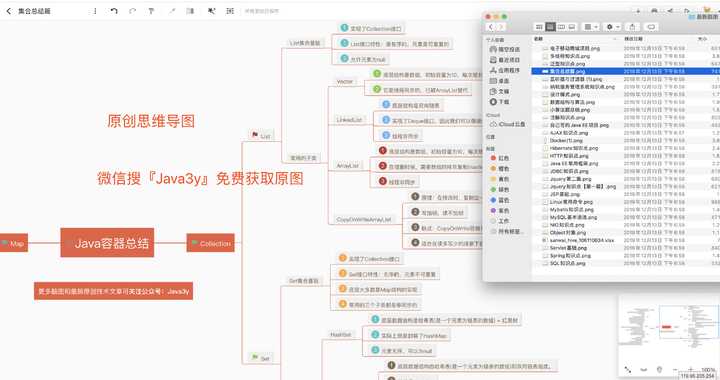
JAVA开发前后端分离博客需要什么技能?
6 个回答

SpringBoot+Spring Data JPA 作为自己的项目还是挺方便的。
如果没接触过JavaWeb,还是得先学一下Servlet。下面我贴出SpringBoot+SpringData JPA的简单搭建教程,希望对题主有帮助。
一、从零搭建环境
本次我使用的是IDEA编辑器来搭建SpringBoot和Spring Data JPA环境
首先,我们在IDEA新建项目的时候,选择Spring Initializr,然后next就行了。

然后填写一些项目的资料(其实这些资料也无关紧要,自己看着填就好了),随后点击next


随后在勾选的时候,我就随手勾选了个LomBok(其他的没勾选,反正后面我们可以在pom文件下配置嘛)。可以看出,本次SpringBoot的版本为2.1.3。
- 注:如果不太了解LomBok的同学,建议去搜一下。这是一个非常好用的插件,有了它我们可以不用写繁琐的set/get方法。记得:使用lomBok还需要在IDEA下安装插件


然后IDEA就会帮我们创建出Maven管理下SpringBoot的项目啦,此时一般我们会指定自己的下载好的Maven,重写它的settings.xml文件


然后Maven就一直在下载相关的依赖啊,必要的插件啊(我等了差不多10分钟吧,这个时间可以去倒杯Java喝喝.haha),等Maven下载完之后,我们的项目就成了下面那个样子了(注:原生的是application.properties文件的,我改了一下后缀,我比较喜欢yml格式的):

二、完善pom文件
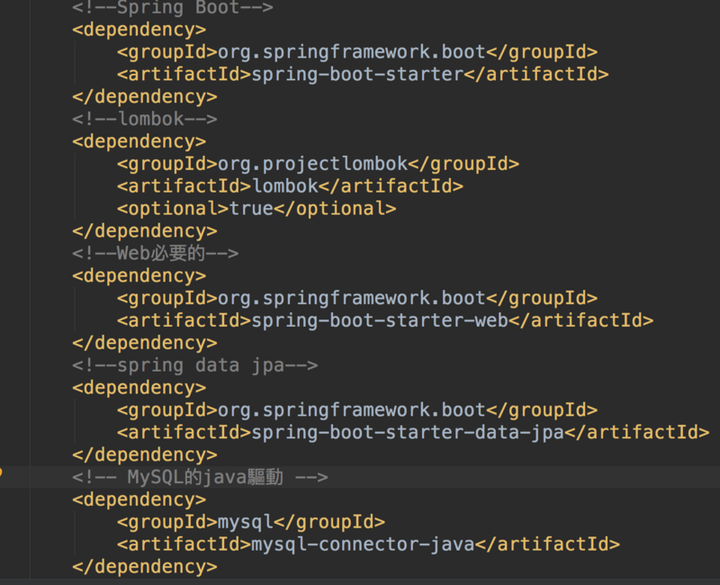
现在pom文件只有SpringBoot和LomBok的依赖,想要完成CURD的功能,我们需要用到Spring Web模块、Spring Data JPA以及MySQL驱动依赖,所以我们得在pom文件下加入这些依赖:
<!--Web必要的-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--spring data jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- MySQL的java驅動 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>pom文件的完整依赖图如下:

三、配置yml文件
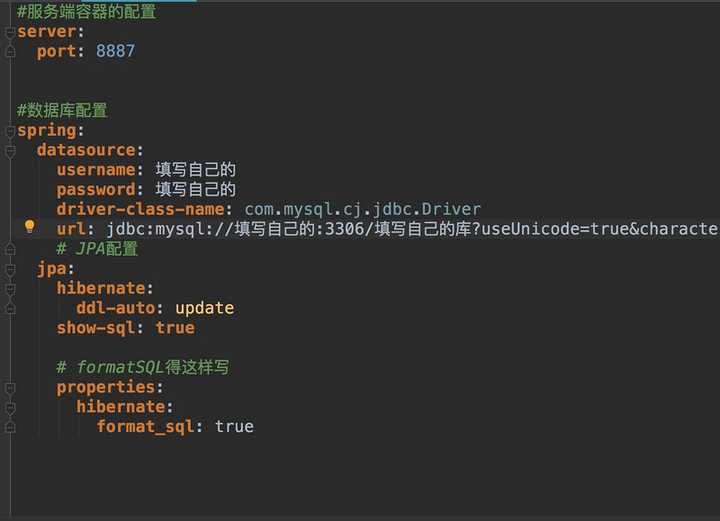
既然我们用到了SpringData JPA和MySQL,我们得为其进行配置最基础的信息。比如说数据库的用户名和密码,相对应的库,以及SpringData JAP的策略。
#服务端容器的配置
server:
port: 8887
#数据库配置
spring:
datasource:
username: 填写自己的
password: 填写自己的
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://填写自己的机器:3306/填写自己的库?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
# JPA配置
jpa:
hibernate:
ddl-auto: update
show-sql: true
# formatSQL得这样写
properties:
hibernate:
format_sql: trueyml文件完整图如下:

数据库的信息填写成自己的就行了。
四、写一个User实体
我毕业设计其中就有对用户的管理,我们用户实体设计如下(大家的当然可以跟我的不一样了,我这只是样例):
package com.zhongfucheng.example.demo.domain;
import lombok.Data;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;
import java.util.Date;
/**
* 存储用户的信息
*
* @author ozc
* @version 1.0
*/
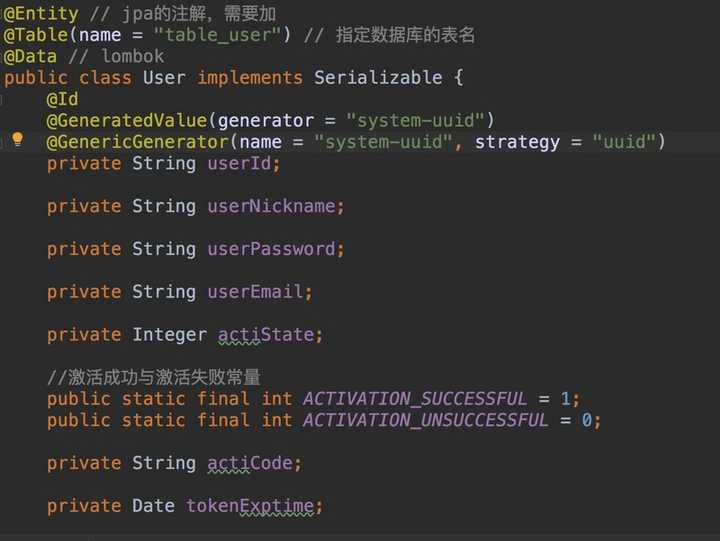
@Entity // jpa的注解,需要加
@Table(name = "table_user") // 指定数据库的表名
@Data // lombok
public class User implements Serializable {
@Id
@GeneratedValue(generator = "system-uuid")
@GenericGenerator(name = "system-uuid", strategy = "uuid")
private String userId;
private String userNickname;
private String userPassword;
private String userEmail;
private Integer actiState;
//激活成功与激活失败常量
public static final int ACTIVATION_SUCCESSFUL = 1;
public static final int ACTIVATION_UNSUCCESSFUL = 0;
private String actiCode;
private Date tokenExptime;
}再补充一句:因为我们有了LomBok的Data注解,并且在IDEA已经下好的LomBok的插件,所以我们可以不用写set、get方法。
User实体图如下:

五、写一个UserRepository
UserRepository是dao层的东西了,相当于UserDao/UserMapper,只是叫法不一样而已。比如在Struts2喜欢将名字取成xxxAction,而在SpringMVC喜欢将名字取成xxxxController。
一般地,我们将UserRepository继承JpaRepository就可以有对应的增删改查方法:
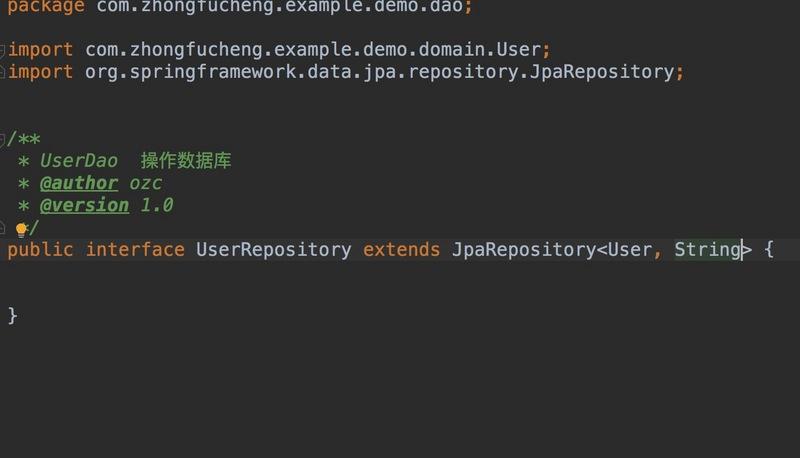
import com.zhongfucheng.example.demo.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
/**
* UserDao 操作数据库
* @author ozc
* @version 1.0
*/
public interface UserRepository extends JpaRepository<User, String> {
}UserRepository图如下:

ok,我们的UserRepository已经写好了,至于为啥我们传入<User, String>,点进去看一下就明白了:


六、写一个UserService
我们就查user表所有的记录出来就好了,代码如下:
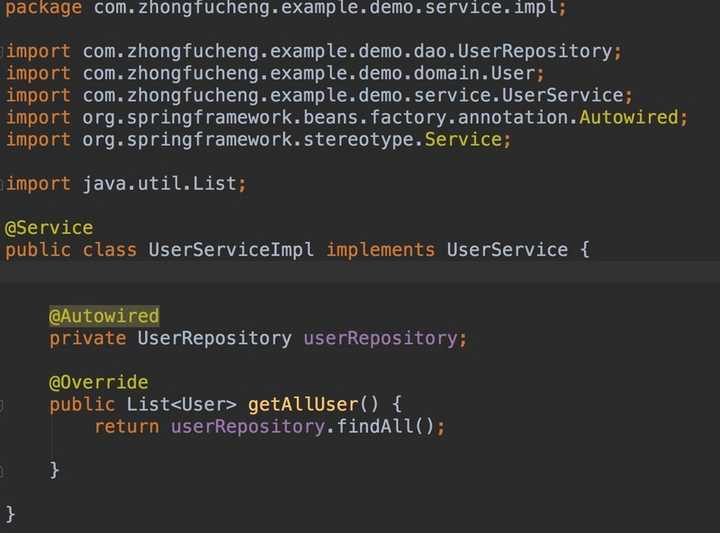
// 接口
public interface UserService {
List<User> getAllUser();
}
// 实现
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository userRepository;
@Override
public List<User> getAllUser() {
return userRepository.findAll();
}
}UserService图如下:

为啥会有findAll()方法?因为我们的UserRepository 继承了JpaRepository
七、写一个UserController
UserController调用一下service的方法,看是否能返回成功,如果能返回成功,那说明我们的环境已经是ok的了。
UserController代码如下:
@RestController
public class UserController {
@Autowired
private UserService userService;
/**
* 得到所有用户
*/
@GetMapping(value = "/user", produces = {"application/json;charset=UTF-8"})
public void getAllUser () {
List<User> allUser = userService.getAllUser();
for (User user : allUser) {
System.out.println(user);
}
}
}Controller代码图如下:


八、测试一下看是否能返回数据
进入DemoApplication,右键,启动我们的SpringBoot项目:
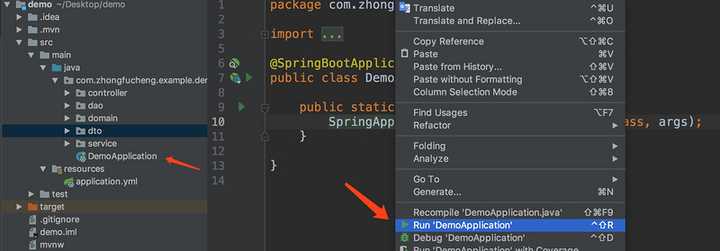

在浏览器输入我们的url:http://localhost:8887/user。然后我们从后台查看,打印出查询的SQL语句,已经后台已经打印表已有的记录。
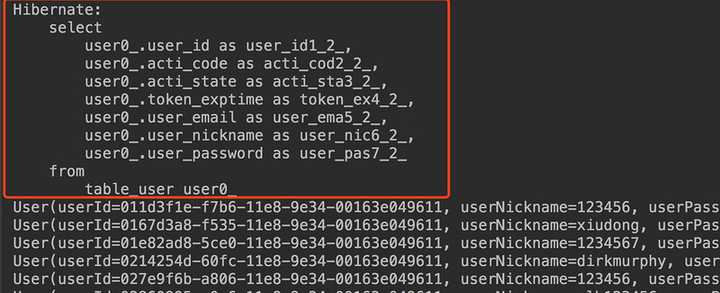

一、搭建管理系统
1.1. 搭建页面
在上一篇的最后,我们可以通过http://localhost:8887/user接口拿到我们User表所有的记录了。我们现在希望把记录塞到一个管理页面上(展示起来)。
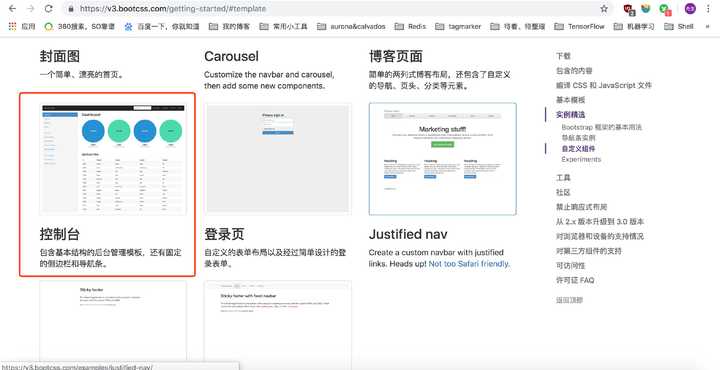
作为一个后端,我HTML+CSS实在是丑陋,于是我就去找了一份BootStrap的模板。首先,我进到bootStrap的官网,找到基本模板这一块:


我们在里边可以看到挺多的模板的,这里选择一个控制台页面:

于是,就把这份模板下载下来,在本地中运行起来试试看。官方给出的链接是下载整一份文档,我们找到想要的页面即可:
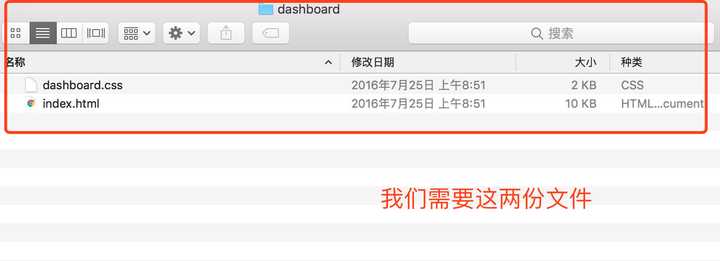

于是我们将这两份文件单独粘贴在我们的项目中,发现这HTML文件需要bootstrap.css、bootstrap.js、jquery的依赖(原来用的是相对路径,其实我们就是看看相对路径的文件在我们这有没有,如果没有,那就是我们需要的)。这里我们在CDN中找找,导入链接就行了。
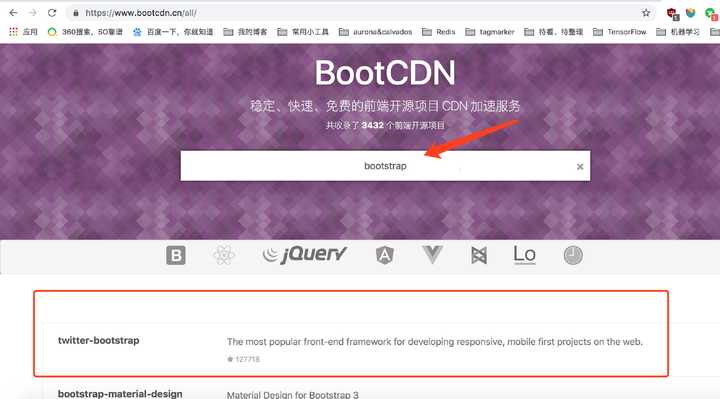

于是我们就将所缺的依赖替换成BootCDN的依赖,最重要的几个依赖如下:
<link href="https://cdn.bootcss.com/twitter-bootstrap/3.4.0/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.bootcss.com/jquery/1.12.4/jquery.min.js"></script>
<script src="https://cdn.bootcss.com/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script>如无意外的话,我们也能在项目中正常打开页面。
1.1.2 把数据塞到页面上
把数据塞到页面上,有两种方案:要么就后端返回json给前端进行解析,要么就使用模板引擎。而我为了便捷,是不想写JS代码的。所以,我使用freemarker这个模板引擎。
- 为什么这么多模板引擎,我选择这个?因为我只会这个!
在SpringBoot下使用freemarker也是非常简单,首先,我们需要加入pom文件依赖:
<!--freemarker-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>随后,在application.yml文件中,加入freemarker的配置:
# freemarker配置
freemarker:
suffix: .ftl
request-context-attribute: request
expose-session-attributes: true
content-type: text/html
check-template-location: true
charset: UTF-8
cache: false
template-loader-path: classpath:/templates这里我简单解释一下:freemarker的文件后缀名为.ftl,程序从/templates路径下加载我们的文件。
于是乎,我将本来是.html的文件修改成.ftl文件,并放在templates目录下:
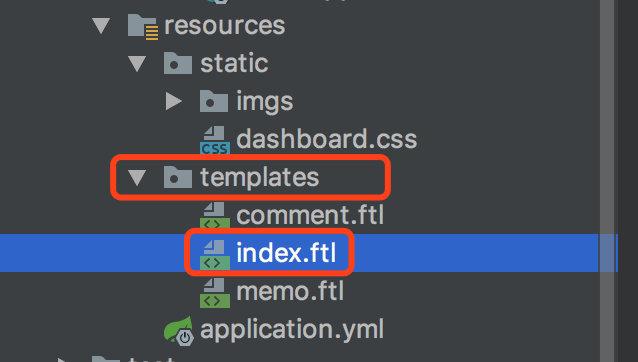

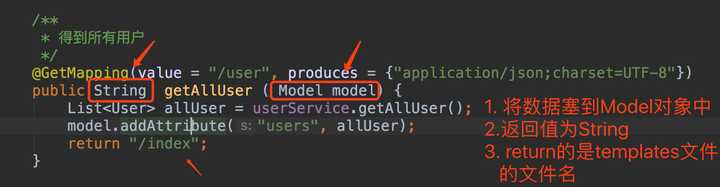
接下来将我们Controller得到的数据,塞到Model对象中:
/**
* 得到所有用户
*/
@GetMapping(value = "/user", produces = {"application/json;charset=UTF-8"})
public String getAllUser ( Model model) {
List<User> allUser = userService.getAllUser();
model.addAttribute("users", allUser);
return "/index";
}图片如下:

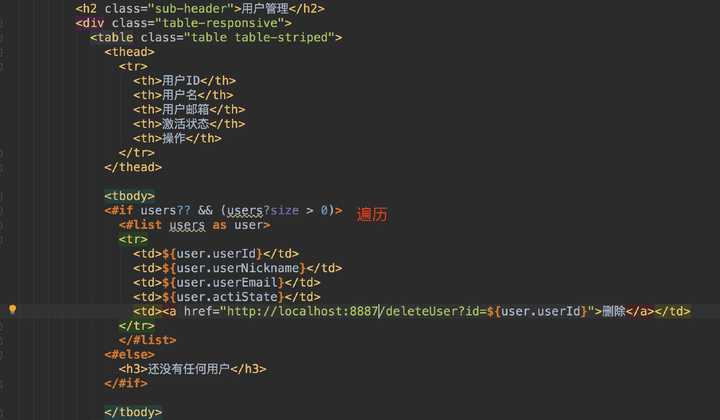
在ftl文件中,我们只要判断数据是否存在,如果存在则在表格中遍历出数据就行了:
<#if users?? && (users?size > 0)>
<#list users as user>
<tr>
<td>${user.userId}</td>
<td>${user.userNickname}</td>
<td>${user.userEmail}</td>
<td>${user.actiState}</td>
<td><a href="http://localhost:8887/deleteUser?id=${user.userId}">删除</a></td>
</tr>
</#list>
<#else>
<h3>还没有任何用户</h3>
</#if>图片如下:

删除的Controller代码如下:
/**
* 根据ID删除某个用户
*/
@GetMapping(value = "/deleteUser", produces = {"application/json;charset=UTF-8"})
public String deleteUserById (String id,Model model) {
userService.deleteUserById(id);
return getAllUser(model);
}我们再找几张自己喜欢的图片,简单删除一些不必要模块,替换成我们想要的文字,就可以得到以下的效果了:


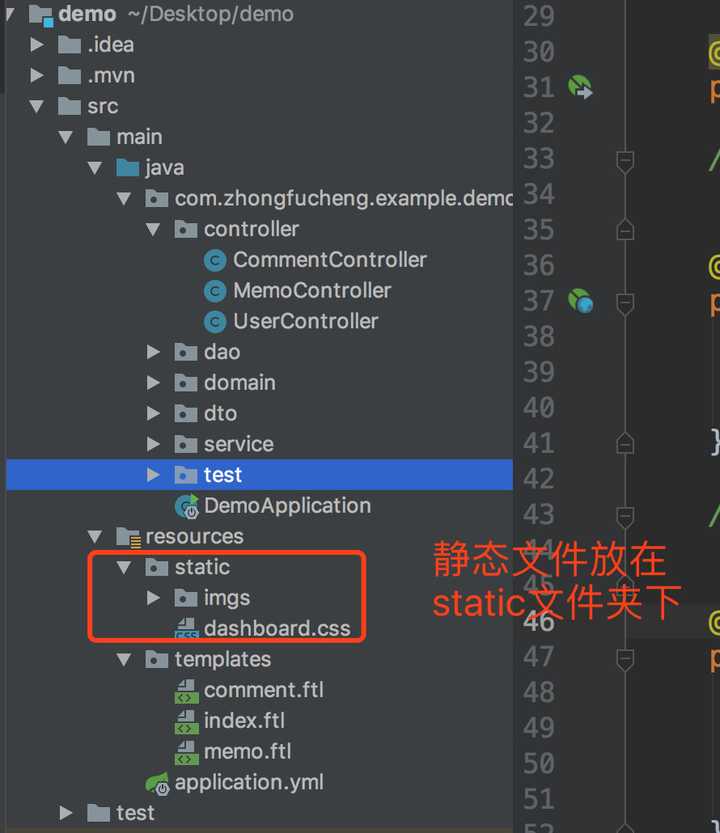
至于图片上的评论管理、备忘录管理的做法都如上,我只是把文件再复制一次而已(期中没有写任何的JS代码,懒)。
在编写的期中,要值得注意的是:静态的文件一般我们会放在static文件夹中。
项目的目录结构如下:

---------------------------------白嫖党注意

涵盖Java后端所有知识点的开源项目(已有6K star): https://github.com/ZhongFuCheng3y/3y
如果大家想要实时关注我更新的文章以及分享的干货的话,微信搜索Java3y
PDF文档的内容均为手打,有任何的不懂都可以直接来问我(公众号有我的联系方式)。


收藏等于白嫖,点赞才是真情!
收藏等于白嫖,点赞才是真情!
收藏等于白嫖,点赞才是真情!

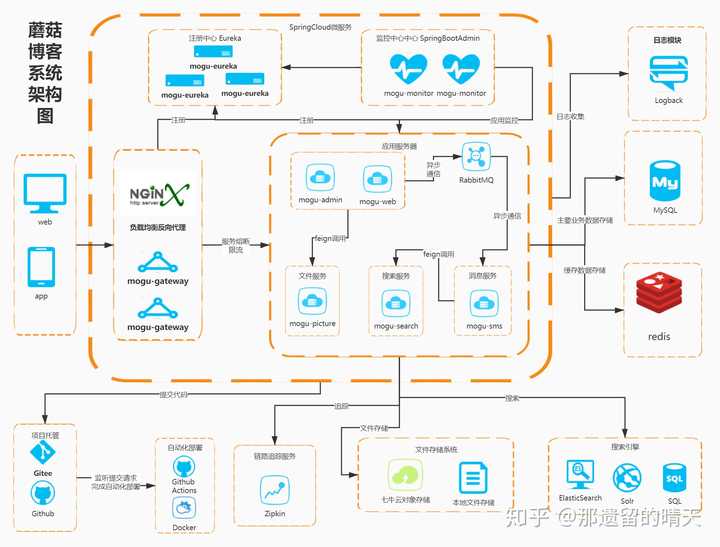
不请自来~,刚看到你的标题是开发前后端分离博客,那么说明你是比较想学习目前主流的技术栈,所以我觉得我自己做的博客项目可能比较符合你的口味,因为这个项目也是我最开始打算用来练手的,当时我只会写一些简单的SSM小项目,后面看着前后端分离,以及Spring Cloud 的微服务比较火,就想着自己动手做一个项目,然后把目前比较流行的技术运用上去,以此来提高自己的编程能力,所以蘑菇博客就诞生了~
蘑菇博客,一个基于微服务架构的前后端分离博客系统。前台使用Vue + Element , 后端使用spring boot + spring cloud + mybatis-plus进行开发,使用 Jwt + Spring Security做登录验证和权限校验,使用ElasticSearch和Solr作为全文检索服务,使用Github Actions完成博客的持续集成,文件支持上传七牛云。
开源地址: https://gitee.com/moxi159753/mogu_blog_v2 , 如果你感兴趣的话,欢迎一起学习~
项目特点
- 友好的代码结构及注释,便于阅读及二次开发
- 实现前后端分离,通过Json进行数据交互,前端再也不用关注后端技术
- 页面交互使用Vue2.x,极大的提高了开发效率。
- 引入swagger文档支持,方便编写API接口文档。
- 引入RabbitMQ 消息队列,用于邮件发送、更新Redis和Solr
- 引入JustAuth第三方登录开源库,支持Gitee、Github账号登录。
- 引入ElasticSearch 和 Sol r作为全文检索服务,并支持可插拔配置
- 引入Github Actions工作流,完成蘑菇博客的持续集成、持续部署。
- 引入七牛云对象存储,同时支持本地文件存储
- 引入RBAC权限管理设计,灵活的权限控制,按钮级别的细粒度权限控制,满足绝大部分的权限需求
- 引入Zipkin链路追踪,聚合各业务系统调用延迟数据,可以一眼看出延迟高的服务
- 采用自定义参数校验注解,轻松实现后端参数校验
- 采用AOP+自定义注解+Redis实现限制IP接口访问次数
- 采用自研的评论模块,实现评论邮件通知
项目架构图

项目使用的技术
后端:
- SpringBoot MVC框架
- SpringCloud 微服务框架
- MyBatis-Plus ORM框架
- Swagger-UI 文档生产工具
- Kibana 分析和可视化平台
- Elasticsearch 搜索引擎
- Solr 搜索引擎
- RabbitMQ 消息队列
- Redis 分布式缓存
- Docker 容器化部署
- Druid 数据库连接池
- 七牛云 七牛云 - 对象储存
- JWT JWT登录支持
- SLF4J 日志框架
- Lombok 简化对象封装工具
- Nginx HTTP和反向代理web服务器
- JustAuth 第三方登录的工具
- HutoolJava 工具包类库
- 阿里大于 短信发送平台
- Github Actions 自动化部署
- Zipkin 链路追踪
前端:
- Vue.js 前端框架
- Vue-router 路由框架
- Vuex 全局状态管理框架
- Nuxt.js 创建服务端渲染 (SSR) 应用
- Element 前端ui框架
- Axios 前端HTTP框架
- Echarts 图表框架
- CKEditor 富文本编辑器
- Highlight.js 代码语法高亮插件
- Tui-editor Markdown编辑器
- vue-cropper 图片裁剪组件
- uploadvue 图片剪裁上传组件


首先要明白前后分离,通俗的讲就是将前端展示和后端业务分离开来。
那么需要的技术就多了,
举几个我自己开发涉及到的技术或者工具
前端:nodejs、vue
后端:springboot、mybatis、redis、nginx、mysql
如果并发大需要做微服务,涉及就更多了。。。

首先,如果不怕配置麻烦,就用Spring framework,如果怕就用Spring boot;然后是持久层,任意的数据库,关系型/非关系型,看需求,操作数据库可以使用Jdbc/jpa/spring data/mybatis之类的;最后需要什么可以自己去实现或者找对应的解决方案框架,如分离出session,可以自己重写httpsession或者使用spring data session。

我说说我网站的开发过程吧
1.0
刚学完javaweb就使用servlet写了几个接口,然后写一个简单的页面当做首页,博客的排班使用UEditor富文本编辑器。
后来学了点vue就有了2.0了
2.0
使用vue重构了页面,不得不说vue的开发效率是真的高,有了之前的接口数据对接起来就很方便了
3.0
学了spring和springboot
这是一次完完全全的重构了,从数据库设计到整个页面的风格和功能都进行一次翻新,文章的排版也使用markdowm格式,维护起来也非常方便

