Python爬企查查网站数据的爬虫代码如何写?
11 个回答

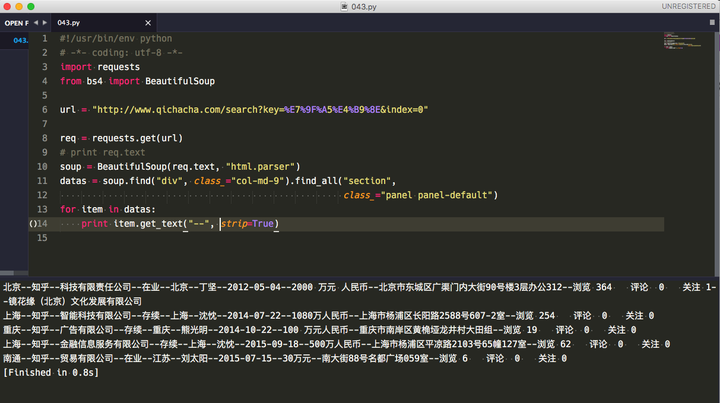
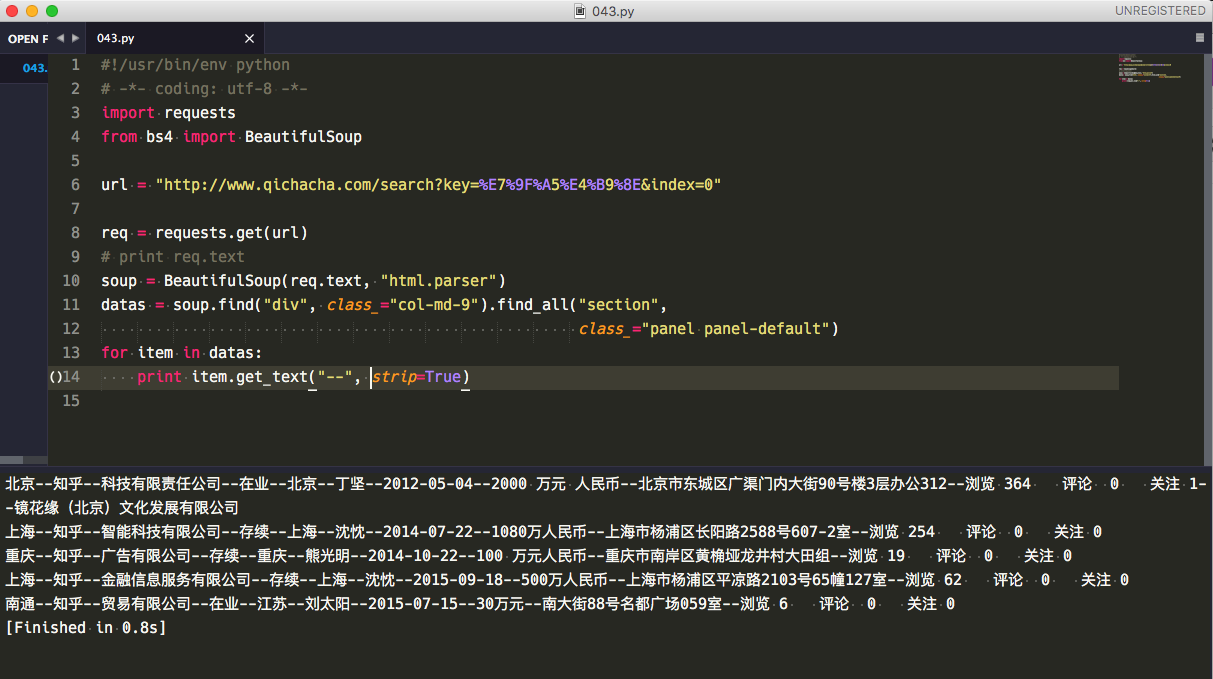
用这个链接做例子
"
http://www.qichacha.com/search?key=%E7%9F%A5%E4%B9%8E&index=0"

知乎达人们喜欢给渔,想要鱼请去威客类的网站发布付费任务。
在这里想免费钓鱼感觉很不好。

世界上最大的谎言就是你不行 ----《垫底辣妹》
1. 需要用到的库
import importlib #提供import语句
import sys
import time #提供延时功能
import xlrd #excel文件读取
import os #系统操作库 用于打开chrome
import xlwt #excel文件写入
from xlutils.copy import copy #excel文件复制
from selenium.webdriver.common.by import By #用于获取网页中的相关元素、标签
from selenium import webdriver
importlib.reload(sys) #避免utf-8等编码问题的出现2. 本地打开浏览器,需要手动登录。(selenium库)
#伪装成浏览器,防止被识破
option = webdriver.ChromeOptions()
option.add_argument('--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"') #请求头
driver = webdriver.Chrome(options=option) #打开chrome浏览器
#打开企查查登录页面
driver.get('https://www.qichacha.com/user_login')
time.sleep(20) #等待20s以用于完成手动登录操作
#手动登录操作3. 从excel文件中读取数据(xlrd库)
#从excel获取查询企业单位
worksheet = xlrd.open_workbook(r'爬虫结果.xlsx') #打开已有企业名称的文件
sheet1 = worksheet.sheet_by_name("企业信息")#取工作表名称为“企业信息”的工作表
rows = sheet1.nrows # 获取行数
inc_list = [] #用列表来装企业名称
for i in range(0,rows) :
data = sheet1.cell_value(i, 0) # 取第1列数据
inc_list.append(data)
print(inc_list)
inc_len = len(inc_list) #获取总共读取到的列表元素个数4. 模拟爬虫(利用模拟手动操作浏览器来实现)
1. XPATH的寻找方式


2. 开始搜索
#开始爬虫
for i in range(inc_len):
txt = inc_list[i]
time.sleep(1)
if (i==0): #如果是第一次 则直接向搜索框注入内容,不用清除搜索框中的内容。
#向搜索框注入文字
driver.find_element(By.ID,'searchKey').send_keys(txt) #这里的ID可以用开发者界面在搜索框那找到
#单击搜索按钮
srh_btn = driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/section[1]/div/div/div/div[1]/div/div/span/button') #这里的XPATH直接复制过来替换掉就可以
srh_btn.click()
time.sleep(2)
else:
#清楚搜索框内容
driver.find_element(By.ID,'searchKey').clear()
# 向搜索框注入下一个企业地址
driver.find_element(By.ID,'searchKey').send_keys(txt)
#找到并点击搜索按钮
srh_btn=driver.find_element(By.XPATH,'/html/body/div[1]/div[1]/div/div[1]/div/div/div/div/span/button')
srh_btn.click()3. 开始获取信息
Credit_List = [] #用来装社会信用代码的空列表
try:
#直接找到装在社会信用代码的标签
credit_code= driver.find_element(By.XPATH,'/html/body/div[1]/div[2]/div[2]/div[3]/div/div[2]/div/table/tr[1]/td[3]/div/div[3]/div[1]/span[4]/span').text
#字符化,防止后续出现编码问题
credit_code = str(credit_code)
print(credit_code,"社会码") #每找到一条,则打印一条在终端上。
Credit_List.append(credit_code) #添加到列表
except:
credit_code='没有找到社会码,可能是企业名称非全称导致筛选信息模糊...'
Credit_List.append(credit_code) #没找到也要添加到列表里面去,实现与企业一一对应
print("没有找到社会码,可能是企业名称非全称导致筛选信息模糊...")4. 保存数据(openpyxl库)
#读取到的数据存入excel中
import openpyxl as pl
wb = pl.load_workbook(r'爬虫结果.xlsx') #打开工作簿
ws = wb.active #读取第一张工作表
i = 0
while i < len(Credit_List):
ws.cell(row=i+1, column=2,value=Credit_List[i]) #将信用代码的列表中的每个数据写入到excel中,cell(row=1,column=1,values = 10) 表示A1单元格内容是10.
print(f'{Credit_List[i]}信用码正在存入{ws.cell(i+1, 1).value}中') #cell(1,1).value表示单元格A1的值
i = i + 1
wb.save(r'爬虫结果.xlsx') #保存文件,这一步必须需要,否则文件没保存等于白搞。
print("Already get things done ,please check the file now!") #可以自行编辑程序完成之后的输出内容。
Node语言是网络爬虫中的一种语言,广泛的被用于大数据抓取的行业,说起数据抓取,就不得不提爬虫ip,很多企业在获取大数据往往会被爬虫ip限制,解决爬虫ip是实现大批量爬取数据的提前。那么在Node语言下如何使用爬虫ip?下面几个代码示例值得大家看看。
nodejs http
const http = require("http");
const url = require("url");
const targetURL = url.parse("http://jshk.com.cn");
const proxyIp = "219.151.125.106";
const proxyPort = "31615";
const authKey = "895314XY";
const password = "24D6YB309ZCB";
const base64 = new Buffer.from(authKey + ":" + password).toString("base64");
const options = {
host: proxyIp,
port: proxyPort,
path: targetURL,
method: "GET",
headers: {
"Host": urlParsed.hostname,
"Proxy-Authorization" : "Basic " + base64
}
};
http.request(options, function (resp) {
console.log("response status code: " + resp.statusCode);
resp.pipe(process.stdout);
}).on("error", function (err) {
console.log("request failed: " + err);
}).end();nodejs request
const request = require("request");
const targetUrl = "http://jshk.com.cn";
const proxyIp = "219.151.125.106";
const proxyPort = 31615;
const authKey = "895314XY";
const password = "24D6YB309ZCB";
const proxyUrl = "http://" + authKey + ":" + password + "@" + proxyIp + ":" + proxyPort;
const req = request.defaults({'proxy': proxyUrl});
const options = {
url : targetUrl,
headers: {}
};
req.get(options, function (err, resp, body) {
if (err) {
return console.log(err);
}
console.log("response status code: " + resp.statusCode);
console.log("response body: " + body);
}).on("error", function (err) {
console.log("request failed: " + err);
});nodejs superagent
const request = require("superagent");
require("superagent-proxy")(request);
const targetUrl = "http://jshk.com.cn";
const proxyIp = "219.151.125.106";
const proxyPort = 31615;
const authKey = "895314XY";
const password = "24D6YB309ZCB";
const proxyUrl = "http://" + authKey + ":" + password + "@" + proxyIp + ":" + proxyPort;
request.get(targetUrl).proxy(proxyUrl).end(function onResponse(err, resp) {
if (err) {
return console.log(err);
}
console.log("response status code: " + resp.statusCode);
console.log("response body: " + resp.text);
});nodejs axios
const axios = require('axios');
const targetUrl = "http://jshk.com.cn";
const proxyIp = "219.151.125.106";
const proxyPort = 31615;
const authKey = "895314XY";
const password = "24D6YB309ZCB";
var proxy = {
host: proxyIp,
port: proxyPort,
auth: {
username: authKey,
password: password
}
};
axios.get(targetUrl, {proxy:proxy}).then(function (response) {
console.log("response body: " + response.data);
}).catch(function (error) {
console.log("request failed: " + error);
}).finally(function () {
console.log("request finished.")
});
参考代码:


今天受一老师朋友所托,帮其看了下企查查高级搜索页请求的哈希校验,页面地址:
aHR0cHM6Ly93d3cucWNjLmNvbS93ZWIvc2VhcmNoL2FkdmFuY2U=先随便交互触发两个请求看看构造,以 Node.js fetch 格式显示如下:
fetch("https://www.qcc.com/api/search/searchCount", {
headers: {
b3e1a8edd33330140573: "e4b1fd60aa53b5a7686492e38b0e7d52b7b2a44db8fa85ba73c2d1b9093bcb9e61a20c5a01fbf931709dbaee324fc524806f2c26fa1dbc435d0c56547c7eeeb5",
"x-pid": "aa22357a6b17df78bc1b6e1ea32cb8b7",
cookie: "QCCSESSID=3f5f0d761ed9eee3f696bd9d2a; qcc_did=82697083-6a9e-4ab7-9059-d7df6f670e61; UM_distinctid=18474def4aaadc-08393462a90e57-18525635-1ea000-18474def4abc1b; acw_tc=db90651616696334990788317ef781a882b454ed444237917218746ed5; CNZZDATA1254842228=241614328-1668405992-https%253A%252F%252Fwww.baidu.com%252F%7C1669631222",
},
body: "{\"count\":true,\"filter\":\"{\\\"i\\\":[\\\"A\\\"]}\"}",
method: "POST"
});
fetch("https://www.qcc.com/api/search/searchCount", {
headers: {
d6c819c35478cea0a8d9: "67ef5dc179bae97c4543bf419a3965081119e12b36a04b8063ad22438b61f241212b92d1c3830cd7217b92a56cc2aee123fd6370d2db1a7b98a476b27f9596f0",
"x-pid": "aa22357a6b17df78bc1b6e1ea32cb8b7",
cookie: "QCCSESSID=3f5f0d761ed9eee3f696bd9d2a; qcc_did=82697083-6a9e-4ab7-9059-d7df6f670e61; UM_distinctid=18474def4aaadc-08393462a90e57-18525635-1ea000-18474def4abc1b; acw_tc=db90651616696334990788317ef781a882b454ed444237917218746ed5; CNZZDATA1254842228=241614328-1668405992-https%253A%252F%252Fwww.baidu.com%252F%7C1669631222",
},
body: "{\"count\":true,\"filter\":\"{\\\"i\\\":[\\\"A\\\"],\\\"r\\\":[{\\\"pr\\\":\\\"CQ\\\"}]}\"}",
method: "POST"
});
可以发现随着请求变化的数据仅有 headers 里的一对键值,且后台也仅对该变动键值做校验。由于其看起来很像 Hash,索性就叫 hashKey:hashValue。
通过网络请求调用堆栈并没有发现相关的赋值代码,于是便想从代码搜索入手。例如此场景在 js 中的赋值语句通常为 headers[key] = value,搜索 headers[ 即可。
遂查看其网页源代码,发现 JavaScript 脚本文件都集中在路径 // http://qcc-static.qichacha.com/qcc/pc-web/prod-22.11.515/ 中,搜索后发现此处最为可疑:
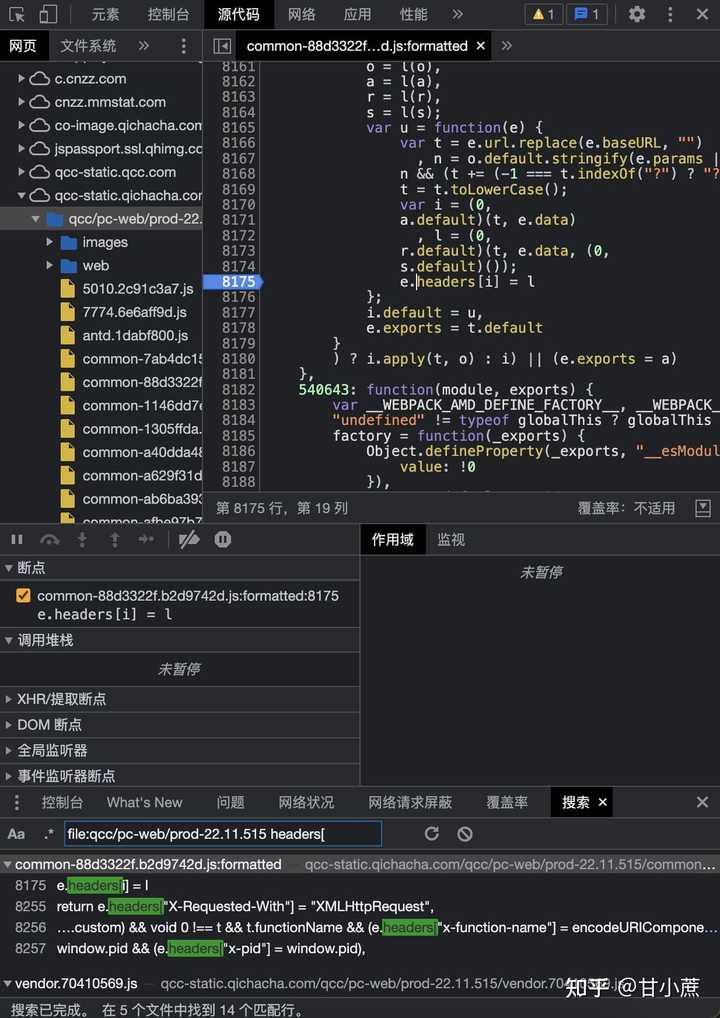

在此断点调试看一下:
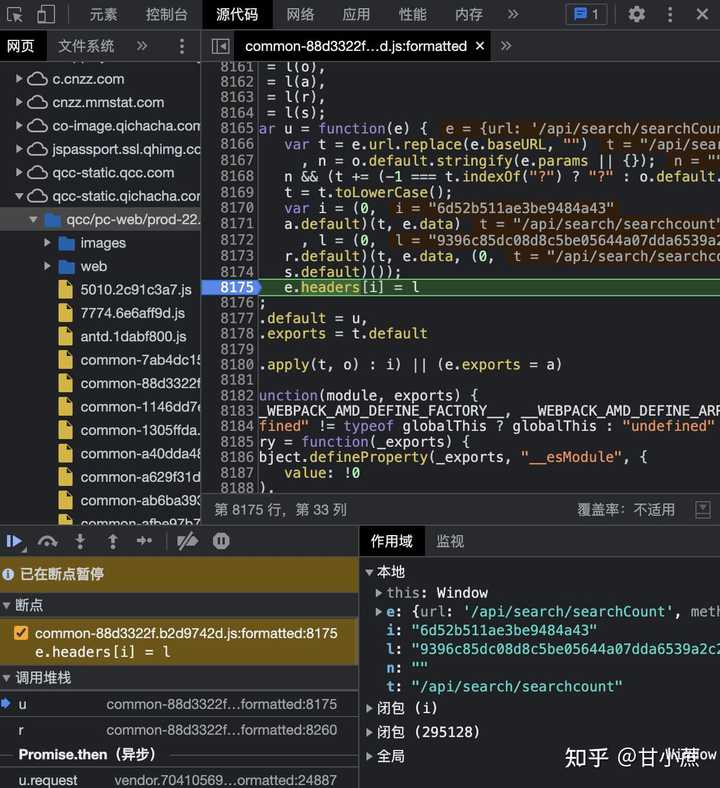

很明显可以发现,其临时变量 i 就是 hashKey,l 则是 hashValue:
// 源代码
var i = (0,a.default)(t, e.data),
l = (0,r.default)(t, e.data, (0,s.default)());
e.headers[i] = l;
// 其中
t = '/api/search/searchcount';
e.data = {
count: true,
filter: "{\"i\":[\"A\"],\"r\":[{\"pr\":\"GD\"},{\"pr\":\"CQ\"}]}"
};
(0,s.default)() = window.tid;
由此,我们只需要查看 a.default 与 r.default 的函数即可知道其哈希值的生成方法。
首先是生成 hashKey 的函数 a.default,通过多次断点,发现其调用堆栈如下:
// 第一层 a.default
function() {
// t=请求URL,e=请求对象,n=请求对象json
var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {}
, t = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase()
, n = JSON.stringify(e).toLowerCase();
// o.default 加密函数在最后提到
return (0, o.default)(t + n, (0, a.default)(t))
.toLowerCase().substr(8, 20)
};
// 传入加密的两个字符分别为
// t + n = /api/search/searchcount{"count":true,"filter":"{\"i\":[\"a\"],\"r\":[{\"pr\":\"gd\"},{\"pr\":\"cq\"}]}"}
// (0, a.default)(t) = iLAgiklLN8QiklLN8Q86Lv4iLAgiklLN8QiklLN8Q86Lv4
// 第二层 a.default
function() {
for (var e = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), t = e + e, n = "", i = 0; i < t.length; ++i) {
var a = t[i].charCodeAt() % o.default.n;
// 并非最后的加密函数 o.default
n += o.default.codes[a]
}
return n
};
// return "iLAgiklLN8QiklLN8Q86Lv4iLAgiklLN8QiklLN8Q86Lv4"
// 第二层 a.default 中的 o.default
o.default = {
"n": 20,
"codes": {
"0": "W",
"1": "l",
"2": "k",
"3": "B",
"4": "Q",
"5": "g",
"6": "f",
"7": "i",
"8": "i",
"9": "r",
"10": "v",
"11": "6",
"12": "A",
"13": "K",
"14": "N",
"15": "k",
"16": "4",
"17": "L",
"18": "1",
"19": "8"
}
};
其次是 r.default:
// 第一层 r.default
function() {
// n=请求URL,e=请求对象,t=tid,i=请求对象json
var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {}
, t = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : ""
, n = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase()
, i = JSON.stringify(e).toLowerCase();
// o.default 加密函数在最后提到
// a.default 即为刚提到的第二层函数
return (0, o.default)(n + "pathString" + i + t, (0, a.default)(n))
};
// 传入加密的两个字符分别为
// /api/search/searchcountpathString{"count":true,"filter":"{\"i\":[\"a\"],\"r\":[{\"pr\":\"gd\"},{\"pr\":\"cq\"}]}"}8b4ebc1e4a1b8c21235f34bf9db8f1a8
// iLAgiklLN8QiklLN8Q86Lv4iLAgiklLN8QiklLN8Q86Lv4
// 则 return 返回值为
// 9396c85dc08d8c5be05644a07dda6539a2c2ec4b742f0b412eb58d71b3d41574e01a1d2b0982861253aa9a14aa08bafb59dd615ea3c36a9716a203620c5bfec1
其中,两个函数都调用了同一个 o.default,其堆栈如下:
// 第一层 o.default
function(e, t) {
return (0, o.default)(e, t).toString()
};
// 第二层 o.default
return function(e, n) {
// h 对象就是一个库,使用的 HMAC SHA512 加密算法
// input:[e],key:[n]
// 在线加密:https://www.idcd.com/tool/encrypt/hmac
return new h.HMAC.init(t,n).finalize(e)
}
至此,顺带做个 python 的解构版本: GitHub 地址
# by Ganxiaozhe (hi@gxzv.com)
# 2022-11-29
# https://gxzv.com/blog/qcc_headers_hash/
#
import json
import hashlib
import hmac
# 在这里填写请求数据
req_url = '/api/search/searchcount'
req_data = {
'count': True,
'filter': "{\"i\":[\"A\"],\"r\":[{\"pr\":\"GD\"},{\"pr\":\"CQ\"}]}"
}
win_tid = '8b4ebc1e4a1b8c21235f34bf9db8f1a8'
def seeds_generator(s):
seeds = {
"0": "W",
"1": "l",
"2": "k",
"3": "B",
"4": "Q",
"5": "g",
"6": "f",
"7": "i",
"8": "i",
"9": "r",
"10": "v",
"11": "6",
"12": "A",
"13": "K",
"14": "N",
"15": "k",
"16": "4",
"17": "L",
"18": "1",
"19": "8"
}
seeds_n = 20
if not s:
s = "/"
s = s.lower()
s = s + s
res = ''
for i in s:
res += seeds[str(ord(i) % seeds_n)]
return res
def a_default(url:str='/', data:object={}):
url = url.lower()
dataJson = json.dumps(data, ensure_ascii=False, separators=(',', ':')).lower()
hash = hmac.new(
bytes(seeds_generator(url), encoding='utf-8'),
bytes(url+dataJson, encoding='utf-8'),
hashlib.sha512
).hexdigest()
return hash.lower()[8:28]
def r_default(url:str='/', data:object={}, tid:str=''):
url = url.lower()
dataJson = json.dumps(data, ensure_ascii=False, separators=(',', ':')).lower()
payload = url+'pathString'+dataJson+tid
key = seeds_generator(url)
hash = hmac.new(
bytes(key, encoding='utf-8'),
bytes(payload, encoding='utf-8'),
hashlib.sha512
).hexdigest()
return hash.lower()
# 输出
print('key: ' + a_default(req_url, req_data))
print('val: ' + r_default(req_url, req_data, win_tid))绕过登陆这个是个难题。如果对钱不是很在意,我建议你用多个号 轮流抓。一单发现被封 自动换下一个。或者找好节奏,请求一次,换一个id,ip,然后轮回。。。目前我还没找到其它办法。

那二级跳转页面怎么抓取。
我需要全国工商信息,有破解的,和我私信,谢谢!

同问,有能顺利爬取数据的吗。请告知一声

基本环境配置
版本:Python3
系统:Windows
相关模块:pandas、csv
爬取目标网站
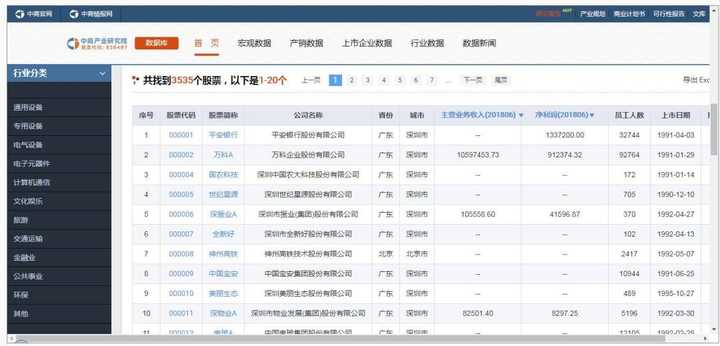

实现代码
import pandas as pd
import csv
for i in range(1,178): # 爬取全部页
tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i)))[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)3000+ 上市公司的信息,安安静静地躺在 Excel 中:


有了上面的信心后,我开始继续完善代码,因为 5 行代码太单薄,功能也太简单,大致从以下几个方面进行了完善:
增加异常处理
由于爬取上百页的网页,中途很可能由于各种问题导致爬取失败,所以增加了 try except 、if 等语句,来处理可能出现的异常,让代码更健壮。
增加代码灵活性
初版代码由于固定了 URL 参数,所以只能爬取固定的内容,但是人的想法是多变的,一会儿想爬这个一会儿可能又需要那个,所以可以通过修改 URL 请求参数,来增加代码灵活性,从而爬取更灵活的数据。
修改存储方式
初版代码我选择了存储到 Excel 这种最为熟悉简单的方式,人是一种惰性动物,很难离开自己的舒适区。但是为了学习新知识,所以我选择将数据存储到 MySQL 中,以便练习 MySQL 的使用。
加快爬取速度
初版代码使用了最简单的单进程爬取方式,爬取速度比较慢,考虑到网页数量比较大,所以修改为了多进程的爬取方式。
经过以上这几点的完善,代码量从原先的 5 行增加到了下面的几十行:
import requests
import pandas as pd
from bs4 import BeautifulSoup
from lxml import etree
import time
import pymysql
from sqlalchemy import create_engine
from urllib.parse import urlencode # 编码 URL 字符串
start_time = time.time() #计算程序运行时间
def get_one_page(i):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
paras = {
'reportTime': '2017-12-31',
#可以改报告日期,比如2018-6-30获得的就是该季度的信息
'pageNum': i #页码
}
url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('爬取失败')
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
content = soup.select('#myTable04')[0] #[0]将返回的list改为bs4类型
tbl = pd.read_html(content.prettify(),header = 0)[0]
# prettify()优化代码,[0]从pd.read_html返回的list中提取出DataFrame
tbl.rename(columns = {'序号':'serial_number', '股票代码':'stock_code', '股票简称':'stock_abbre', '公司名称':'company_name', '省份':'province', '城市':'city', '主营业务收入(201712)':'main_bussiness_income', '净利润(201712)':'net_profit', '员工人数':'employees', '上市日期':'listing_date', '招股书':'zhaogushu', '公司财报':'financial_report', '行业分类':'industry_classification', '产品类型':'industry_type', '主营业务':'main_business'},inplace = True)
return tbl
def generate_mysql():
conn = pymysql.connect(
host='localhost',
user='root',
password='******',
port=3306,
charset = 'utf8',
db = 'wade')
cursor = conn.cursor()
sql = 'CREATE TABLE IF NOT EXISTS listed_company (serial_number INT(20) NOT NULL,stock_code INT(20) ,stock_abbre VARCHAR(20) ,company_name VARCHAR(20) ,province VARCHAR(20) ,city VARCHAR(20) ,main_bussiness_income VARCHAR(20) ,net_profit VARCHAR(20) ,employees INT(20) ,listing_date DATETIME(0) ,zhaogushu VARCHAR(20) ,financial_report VARCHAR(20) , industry_classification VARCHAR(20) ,industry_type VARCHAR(100) ,main_business VARCHAR(200) ,PRIMARY KEY (serial_number))'
cursor.execute(sql)
conn.close()
def write_to_sql(tbl, db = 'wade'):
engine = create_engine('mysql+pymysql://root:******@localhost:3306/{0}?charset=utf8'.format(db))
try:
tbl.to_sql('listed_company2',con = engine,if_exists='append',index=False)
# append表示在原有表基础上增加,但该表要有表头
except Exception as e:
print(e)
def main(page):
generate_mysql()
for i in range(1,page):
html = get_one_page(i)
tbl = parse_one_page(html)
write_to_sql(tbl)
# # 单进程
if __name__ == '__main__':
main(178)
endtime = time.time()-start_time
print('程序运行了%.2f秒' %endtime)
# 多进程
from multiprocessing import Pool
if __name__ == '__main__':
pool = Pool(4)
pool.map(main, [i for i in range(1,178)]) #共有178页
endtime = time.time()-start_time
print('程序运行了%.2f秒' %(time.time()-start_time))结语
这个过程觉得很自然,因为每次修改都是针对一个小点,一点点去学,搞懂后添加进来,而如果让你上来就直接写出这几十行的代码,你很可能就放弃了。
所以,你可以看到,入门爬虫是有套路的,最重要的是给自己信心。
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值。