已知词频率如何画词云图?
10 个回答

一、概述


当看到这种图的时候,你一定会在猜这个是怎么做出来的,然后有什么用?
词云图是用来展示文本中词语的频率及权重分布的一种可视化方式,其中出现频率较高的词语会以较大的字体大小显示,而权重较低的词语则会以较小的字体大小显示。
二、 数据集
2.1 安装和加载包
wordcloud2 可以根据不同的词语权重自定义字体大小、颜色和布局模式,并且支持更加灵活的配置选项,使得生成的词云图更加精美和逼真。自带数据集demoFreqC
install.packages("wordcloud2") # 安装包
library(wordcloud2) # 加载包2.2 数据集展示
加载数据集
data(demoFreqC)
head(demoFreqC)数据集展示
V2 V1
1 数据 2304
3 统计 1413
4 用户 855
5 模型 846
7 分析 773
8 数据分析 750三、使用方法
3.1 简单词云图
wordcloud2(demoFreqC)

3.2 参数介绍
wordcloud2(data, size = 1, minSize = 0, gridSize = 0,
fontFamily = 'Segoe UI', fontWeight = 'bold',
color = 'random-dark', backgroundColor = "white",
minRotation = -pi/4, maxRotation = pi/4, shuffle = TRUE,
rotateRatio = 0.4, shape = 'circle', ellipticity = 0.65,
widgetsize = NULL, figPath = NULL, hoverFunction = NULL)
参数
data 包含每列中的单词和频率的数据框
size 字体大小,默认值为 1。尺寸越大意味着单词越大。
minSize 字幕的字符串
gridSize 网格的大小(以像素为单位),用于标记画布的可用性 网格大小越大,单词之间的差距越大。
fontFamily 要使用的字体。
fontWeight 要使用的字体粗细,例如普通、粗体或 600
color 可以使用文本的颜色,关键字“随机暗”和“随机光”。 此参数中也支持颜色矢量
backgroundColor 背景的颜色。
minRotation 如果单词应旋转,则最小旋转 (以 rad 为单位)文本应旋转。
maxRotation 如果单词应旋转,则文本应旋转的最大旋转(以 rad 为单位)。 将两个值设置为相等,以使所有文本保持一个角度。
shuffle 随机播放要绘制的点,以便每次相同的列表和设置的结果都会有所不同。
rotateRatio 单词旋转的概率。将数字设置为 1 以始终旋转。
shape 要绘制的“云”的形状。可以是存在的关键字。可用的礼物是“圆圈” (默认),“心形”(苹果形或心形曲线,最著名的极性方程), “菱形”(正方形的别名)、“三角形”、“三角形”、“五边形”和“星形”。
ellipticity 形状词云2的“平坦度”程度.js应该画出来。
widgetsize 小部件的大小
figPath 用作蒙版的图形的路径。
hoverFunction 光标进入或离开占用区域时调用的回调 一句话。一个字符串的 java 脚本函数。- 修改字体大小
wordcloud2(demoFreqC, size = 2)

如果不设置size,则默认为1,现在设置成了2,词云图字明显变大。
- 调整形状
wordcloud2(demoFreqC, shape = 'cardioid',size=1.5)

默认为'circle', 其他形状有:
'cardioid'(心形,也是最受欢迎的形状)'diamond'(钻石形状)
'triangle-forward'(朝前的三角形)'triangle'(三角形)
'pentagon'(五边形)'star'(星形)
- 修改背景色
wordcloud2(demoFreqC, size = 1.5,shape="pentagon",
color = "random-dark", backgroundColor = "darkgrey")

- 图的颜色使用color调整,可用值有
'random-dark'和'random-light'两种,也支持其他颜色调整。 - 背景的颜色使用backgroundColor参数调整。
- 旋转角度
wordcloud2(demoFreqC,
size = 1.5,
shape = "star",
minRotation = 30, maxRotation = 45,
rotateRatio = 1)

5. 主题设置
wordcloud2(demoFreqC,size=1.5,shape="cardioid") + WCtheme(1) + WCtheme(2) + WCtheme(3)

本文由博客一文多发平台 OpenWrite 发布!

词云图作为一种可视化技术,能够快速、直观地展示文本数据中的关键词和短语,被广泛应用于信息展示和知识发现等领域。
今天实现几个中英文之间的应用:
1.根据统计过的数据进行词云图绘制
2.绘制带有背景图的词云图
3.把指定文件夹内的所有PDF(文献)都绘制词云图,并完成Excel统计
(1)根据统计过的数据进行词云图绘制

import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取XLSX文件
file_path = '问题统计.xlsx'
data = pd.read_excel(file_path)
# 提取第一列(文字)和第二列(次数统计)数据
words = data.iloc[:, 0]
frequencies = data.iloc[:, 1]
# 构建词云图
wordcloud = WordCloud(width=800, height=800,
background_color='white',
min_font_size=10,
colormap='viridis',
font_path='C:/Windows/Fonts/SimHei.ttf') # 替换为正确的路径
# 根据词频生成词云
wordcloud.generate_from_frequencies(dict(zip(words, frequencies)))
# 显示词云图
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off") # 关闭坐标轴
plt.tight_layout(pad=0)
plt.show()


(2)绘制带有背景图的词云图
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image # 用于读取背景图
# 设置背景图路径,确保路径是正确的
background_path = 'Jay.jpg'
# 读取背景图
background = np.array(Image.open(background_path))
# 定义词云图参数
wordcloud = WordCloud(background_color='white', mask=background, contour_color='black',
contour_width=1, max_words=2000, max_font_size=60, colormap='viridis',
font_path='C:/Windows/Fonts/SimHei.ttf')
# 要生成词云的文本(你需要替换为你自己的文本)
text = """后视镜里的世界,越来越远的道别
你转身向背,侧脸还是很美
我用眼光去追,竟听见你的泪
在车窗外面徘徊,是我错失的机会
你站的方位,跟我中间隔着泪
街景一直在后退,你的崩溃在窗外零碎
我一路向北,离开有你的季节
你说你好累,已无法再爱上谁
风在山路吹,过往的画面全都是我不对
细数惭愧 我伤你几回,后视镜里的世界
越来越远的道别,你转身向背
侧脸还是很美,我用眼光去追
竟听见你的泪,在车窗外面徘徊
是我错失的机会,你站的方位
跟我中间隔着泪,街景一直在后退
你的崩溃在窗外零碎,我一路向北
离开有你的季节,你说你好累
已无法再爱上谁,风在山路吹
过往的画面全都是我不对
细数惭愧,我伤你几回
我一路向北,离开有你的季节
方向盘周围,回转着我的后悔
我加速超越,却甩不掉紧紧跟随的伤悲
细数惭愧,我伤你几回
停止狼狈,就让错纯粹"""
# 生成词云
wordcloud = wordcloud.generate(text)
# 将词云图转换为图像并显示
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
# 保存词云图到文件
wordcloud.to_file("wordcloud_with_background.png")

(3)把指定文件夹内的所有PDF(文献)都绘制词云图,并完成Excel统计
数据预处理:
对文本数据进行预处理,包括分词、去停用词、去除特殊符号等操作。这里我们使用jieba库进行中文分词,使用nltk库进行英文分词。同时,还需要将文本数据转化为小写字母,以便于统一处理。
import fitz
import os
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from openpyxl import Workbook
import nltk
from nltk.corpus import stopwords
# 下载停用词列表
nltk.download('stopwords')
# 创建存储文本和词云图的文件夹
if not os.path.exists('text'):
os.makedirs('text')
if not os.path.exists('wordclouds'):
os.makedirs('wordclouds')
# 提取PDF中的文本到txt文件,并统计词频绘制词云
def extract_text_and_generate_wordcloud(pdf_folder):
wb = Workbook()
ws = wb.active
ws.append(['File Name', 'Word', 'Frequency'])
# 获取英文停用词列表
stop_words = set(stopwords.words('english'))
for pdf_file in os.listdir(pdf_folder):
if pdf_file.endswith('.pdf'):
pdf_path = os.path.join(pdf_folder, pdf_file)
txt_file = os.path.join('text', os.path.splitext(pdf_file)[0] + '.txt')
word_freq = {}
# 提取PDF文本到txt文件
pdf_document = fitz.open(pdf_path)
text = ''
for page in pdf_document:
text += page.get_text()
with open(txt_file, 'w', encoding='utf-8') as file:
file.write(text)
pdf_document.close()
# 去除停用词
words = text.split()
cleaned_words = [word.lower() for word in words if word.isalpha() and word.lower() not in stop_words]
for word in cleaned_words:
if word in word_freq:
word_freq[word] += 1
else:
word_freq[word] = 1
for word, freq in word_freq.items():
ws.append([pdf_file, word, freq])
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(word_freq)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(f'Word Cloud for {pdf_file}')
plt.savefig(f'wordclouds/wordcloud_{pdf_file[:-4]}.png') # 保存词云图
plt.close()
wb.save('word_frequency.xlsx') # 保存统计结果到Excel文件
# 使用示例
pdf_folder_path = 'D:\python program\词云图\参考文献' # 修改为你的PDF文件夹路径
extract_text_and_generate_wordcloud(pdf_folder_path)
这样我们不仅将PDF文件的内容保存在了txt当中,还统计了每个PDF中的词频,并绘制了词云图。



强烈推荐 镝数图表!
废话不多说,直接看镝数图表词云图的制作页面:


发现了吧,镝数图表的词云图数据,正巧就是这种已经处理过的,已知关键词和词频的数据。
把我们处理好的两列数据复制粘贴,或导入进去,就可以自动渲染出词云图。
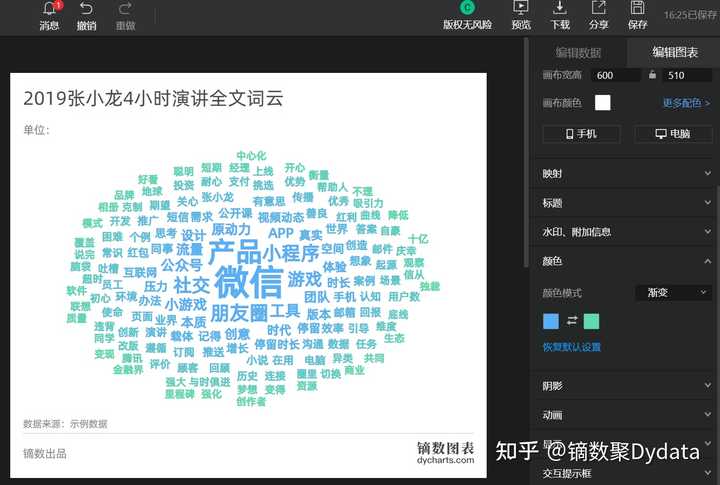

图表的颜色、标题、动画都可以自己调整。
还有我们很常用的词云形状、字体字号、排列方式,也都可以根据需要修改~


不想展示标题、出品方、数据来源这些也都可以自己关掉!


而且他的使用方法特别简单,就像前面展示的,只需要找到词云图模板,然后输入数据再调整样式就行了。
也不需要下载任何软件,网站的形式即开即用!0学习成本,非常适合小白!
强烈推荐你试一下: 镝数图表-在线动态图表工具-零代码数据大屏可视化



Only supported for TrueType fonts一直显示这个错误,用了电脑自带字体也不可以

已知词频的频率再制作词云图的话,这个操作就会简单很多啦。
你想要快捷的工具,然后根据数据得出对应的词图的话,可以试试镝数图表。选择这个的原因是因为你只要导入数据或者直接复制粘贴数据过去,他就可以1秒生成词云图。高效、方便又好看。


词云图,他就是文本数据的显示,由词汇组成像云一样的形状,所以叫词云图。他的独特之处在于可以展现大量的文本数据,权重越大的词句字号越大。
制作流程
1、在浏览器搜索【镝数图表】,然后在首页找到【图表模板】。
2、在搜索框输入【词云图】,选择后进入编辑。
3、在编辑页面选择【编辑数据】,复制粘贴或者导入自己你制作的词频和词语的数据表格。


4、选择标题、水印等修改图表里的标题文字。


5、选择【显示】,可修改字体的范围,形状和文字的排版方向。


6、还可添加修改动态呈现的方式。


7、选择合适的格式导出就可以啦。
以上就是全部的内容啦,希望对你有帮助哦。

词云图 (Word Cloud) ,又名「标签云图」,主要通过使每个字的大小与其出现频率成正比,进而显示不同单词在给定文本中的出现频率,然后将所有的字词排在一起,形成云状图案。下面,小编就结合R语言中的wordcloud2包给大家展示如何绘制词云图。
安装、加载R包
#安装R包
install.packages("wordcloud2")
#加载R包
library(wordcloud2)数据
这里我们使用示例数据:
df1<-demoFreq
df2<-demoFreqC

绘图
1、基础绘图
#基础绘图
wordcloud2(df, #数据
size=1.5,#字体大小
fontFamily = 'Segoe UI',#字体
fontWeight = 'bold',#字体粗细
color='random-light',#字体颜色设置
backgroundColor="black"#背景颜色设置
)
wordcloud2(df2, #数据
size=1.5,#字体大小
fontFamily = 'Segoe UI',#字体
fontWeight = 'bold',#字体粗细
color='random-light',#字体颜色设置
backgroundColor="black"#背景颜色设置
)
2、改变词的方向
wordcloud2(df1, size = 2, minRotation = -pi/6, maxRotation = -pi/6,#文本旋转角度范围
rotateRatio = 0.5)#文本选择概率
3、更改词云形状——可供选择形状有'star'、'circle'、'cardioid'、'diamond'、'triangle-forward'、'triangle'、'pentagon'共计7种:
注释:新版本wordcloud2包已经不支持自定义形状,大家如果需要可根据这个博主的推文进行操作: https://blog.csdn.net/tandelin/article/details/103977242
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'star')#改变形状
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'circle')#改变形状
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'cardioid')#改变形状
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'diamond')#改变形状
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'triangle-forward')#改变形状
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'triangle')#改变形状
wordcloud2(df1,size=1.5,color='random-light',backgroundColor="black",
shape = 'pentagon')#改变形状
参考: https://r-graph-gallery.com/196-the-wordcloud2-library.html

原文连接: Python基于DataFrame数据定制形态的词云图
词云图一般是文本分析的一个重要分析工具,一般会通过对目标文本分词,得到对应的词频数据信息。例如如下数据:

两列数据,一列为关键,另外一列为对应的词频。通过Pandas包读取数据,得到对应的DataFrame结构的数据。并进一步转换为对应的词典(dict)数据。如下操作:
import pandas as pd
df = pd.read_excel('数据.xlsx',sheet_name=0,engine='openpyxl') # 读取excel数据信息
data=pd.DataFrame(index=df['关键词']) # 新生成一个DF文件,index为df的index
data['权重']=0 # data生成一个值均为0的列,主要定义这一列为int格式,为下面赋值做准备
# 将df的数据复制到 data中
for i in range(0,len(df)):
data.iloc[i,0]=df.iloc[i,1]
#
data = data['权重'].sort_values(ascending = False) # 排序
data = dict(data) # 生成dict格式数据得到的dict文件格式形式:


以上就做好了基础数据的准备,接下来具体生成对应的词云图:
首先导入需要用的包:
import numpy as np
from PIL import Image # 读取图片的包
from wordcloud import WordCloud,ImageColorGenerator # 做词云图
import matplotlib.pyplot as plt # 作图由于关键词中有 中文 的词,需要设置显示字体,否则会显示乱码,设置中文字体文件位置,以备后续引用:
font_path='F:/教学类材料//SourceHanSansCN-Regular.ttf'由于希望得到的词云图是我们自定义图形,需要获取自定义图形数据信息。我们选择的图形如下:


具体图像信息:
# 读取背景图片
background_Image = np.array(Image.open("枫叶2.jpg"))
# 提取背景图片颜色
img_colors = ImageColorGenerator(background_Image)接下来利用wordcloud库进行绘制词云图:
#创建画板
plt.figure(figsize=(10,8),dpi=1000) # 创建画板 ,定义图形大小及分辨率
mask = plt.imread(r"枫叶.jpg") #自定义背景图片
# 设置词云图相关参数
wc=WordCloud(mask=mask,
font_path=font_path,
width=800,height=500,
scale=2,mode="RGBA",
background_color='white')
wc=wc.generate_from_frequencies(data) # 利用生成的dict文件制作词云图
#根据图片色设置背景色
wc.recolor(color_func=img_colors)最后,我们将生成的图形存储到我们的本地:
#存储图像
wc.to_file('词云图1.png')也可以用plt来显示和存储:
#显示图片
plt.imshow(wc,interpolation="bilinear")
plt.axis("off")
plt.savefig("词云图2.png")这样我们就得到了最终定制化的词云图:


若我们将制作词云图中的:“根据图片色设置背景色” 的代码删除或注释掉,这得到python自动上颜色的图:




Tableau
最近实习在用,完美契合你的输入

实现功能:
前一篇文章我介绍了文本分析与挖掘的第一到三步(具体可参加前三篇文章),即构建语料库、中文分词和词频统计,这篇文章将在此基础上进绘制词云图。
实现代码:
import os
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
import os.path
import codecs
import pandas
import jieba
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
#==========词料库构建===============
def Create_corpus(file):
filePaths = []
fileContents=[]
for root, dirs, files in os.walk(file):
# os.path.join()方法拼接文件名返回所有文件的路径,并储存在变量filePaths中
for name in files:
filePath=os.path.join(root, name)
filePaths.append(filePath)
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
fileContents.append(fileContent)
#codecs.open()方法打开每个文件,用文件的read()方法依次读取其中的文本,将所有文本内容依次储存到变量fileContenst中,然后close()方法关闭文件。
#创建数据框corpos,添加filePaths和fileContents两个变量作为数组
corpos = pandas.DataFrame({'filePath': filePaths,'fileContent': fileContents})
return corpos
#============中文分词===============
def Word_segmentation(corpos):
segments = []
filePaths = []
#遍历语料库的每一行数据,得到的row为一个个Series,index为key
for index, row in corpos.iterrows():
filePath = row['filePath']#获取每一个row中filePath对应的文件路径
fileContent = row['fileContent']#获取row中fileContent对应的每一个文本内容
segs = jieba.cut(fileContent)#对文本进行分词
for seg in segs:
segments.append(seg)#分词结果保存到变量segments中
filePaths.append(filePath)#对应的文件路径保存到变量filepaths中
#将分词结果及对应文件路径添加到数据框中
segmentDataFrame = pandas.DataFrame({'segment': segments,'filePath': filePaths})
return segmentDataFrame
#===============词频统计================
def Word_frequency(segmentDataFrame):
segStat = segmentDataFrame.groupby(by="segment")["segment"].agg([("计数",np.size)]).reset_index().sort_values(by=["计数"],ascending=False) #对单个词进行分组计数,重置索引,并将计数列按照倒序排序。
#移除停用词
stopwords = pandas.read_csv(r"F:\医学大数据课题\AI_SLE\AI_SLE_TWO\userdict.txt", encoding='utf8', index_col=False)
#导入停用词文件,.isin()判断某个词是否在停用词中,~表示取反,这样就过滤掉了停用词了
fSegStat = segStat[~segStat['segment'].isin(stopwords['stopword'])]
return fSegStat
# =============词云绘制==================
def Word_cloud(fSegStat):
wordcloud = WordCloud(font_path='C:\Windows\Fonts\\STKAITI.TTF', background_color="black")
# 将数据框格式的数据转换为字典格式
words = fSegStat.set_index('segment').to_dict()
# 根据词频生成词云
wordcloud.fit_words(words['计数'])
# wordcloud.fit_words() #接收一个字典,包括词及对应的词频,识别然后绘制成词云
plt.imshow(wordcloud)
plt.show()
plt.close()
return
corpos=Create_corpus("F:\医学大数据课题\AI_SLE\AI_SLE_TWO\TEST_DATA")
segmentDataFrame=Word_segmentation(corpos)
fSegStat=Word_frequency(segmentDataFrame)
Word_cloud(fSegStat)
实现效果:


喜欢记得点赞,在看,收藏,
关注V订阅号:数据杂坛,获取数据集,完整代码和效果,将持续更新!