基于矩阵分解的推荐技术

推荐系统与矩阵
推荐系统主要解决的是“人”与“物”的关系,我们可以把推荐看成一个二维矩阵,如下图所示,列为“人”,行为“物”,表中的数值为“人”对“物”喜爱程度的量化表示。推荐系统所要解决的问题就是给表格中未知的“?”填入合适的值。推荐系统最终的目标就是对于任意一个用户,预测出所有未评分物品的分值,并按分值从高到低的顺序将对应的物品推荐给用户。
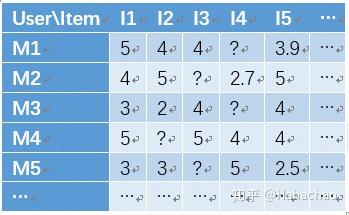
对于矩阵分解,我们首先想到的是课本上学到的特征值矩阵分解和奇异值(SVD)矩阵分解。由于特征值矩阵分解要求是方阵,这一点对于现实的推荐来说太严格了,我们来看下SVD矩阵分解。
基于SVD的矩阵分解
奇异值分解,其具体描述为:对于一个m*n的矩阵M,则一定存在一个分解M=U∑V ,其中U是m*m的正交矩阵,V是n*n的正交矩阵,Σ是m*n的对角阵。其中,对角阵Σ还有一个特殊的性质,它的所有元素都非负,且依次减小。这个减小也特别快,在很多情况下,前10%的和就占了全部元素之和的99%以上,这就是说我们可以使用最大的k个值和对应大小的U、V矩阵来近似描述原始的评分矩阵,可以说是完美契合分解评分矩阵这个需求,
我们马上能得到一个解决方案:对原始评分矩阵M做奇异值分解,得到U、V及Σ,取Σ中较大的k类作为隐含特征,则此时M(m*n)被分解成U(m*k) Σ(k*k)V(k*n),接下来就可以直接使用矩阵乘法来完成对原始评分矩阵的填充。然而梦想是美好的,现实是残酷的,SVD使用有个前提条件,需要矩阵是稠密的,也就是说不允许待分解的矩阵存在着空值,而我们推荐系统需要解决的问题就是给矩阵中的空值做填空,这就与我们的问题冲突了。
基于Funk-SVD的矩阵分解
Simon Funk就提出了Funk-SVD算法,其主要思路是将原始评分矩阵M(m*n)分解成两个矩阵P(m*k)和Q(k*n),借鉴机器学习中监督学习的训练过程,把M矩阵中已知的分值作为目标值,选择均方差为模型的判别标准,经过迭代,得到一个使得整体均方差最小的P和Q。也就是,我们使用待确定的P和Q计算出一个M’,
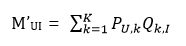
总的损失就是,
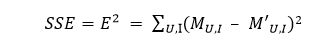
最小化上面的损失SSE,就能以完成对原始评分矩阵的分解,在这之后只需要用计算M’的方式来完成对原始评分矩阵的填充即可。
这种方法也有一个高大上的名称,叫做隐语义模型(Latent factor model,LFM),其算法意义层面的解释为通过隐含特征(latent factor)将user兴趣与item特征联系起来。
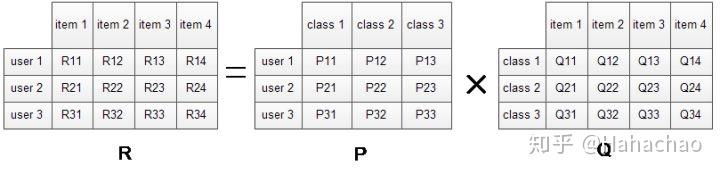

对于原始评分矩阵R,我们假定一共有三类隐含特征,于是将矩阵R(3*4)分解成用户特征矩阵P(3*3)与物品特征矩阵Q(3*4)。考察user1对item1的评分,可以认为user1对三类隐含特征class1、class2、class3的感兴趣程度分别为P11、P12、P13,而这三类隐含特征与item1相关程度则分别为Q11、Q21、Q31。可以发现用户U对物品I最终的评分就是由各个隐含特征维度下U对I感兴趣程度的和,这里U对I的感兴趣程度则是由U对当前隐含特征的感兴趣程度乘上I与当前隐含特征相关程度来表示的。于是,现在的问题就变成了如何求出使得SSE最小的矩阵P和Q。
梯度下降法(Gradient Descent)是最常采用的方法之一,其核心思想非常简单,沿梯度下降的方向逐步迭代。梯度是一个向量,表示的是一个函数在该点处沿梯度的方向变化最快,变化率最大,而梯度下降的方向就是指的负梯度方向。
具体应用到上文中的目标函数

SSE是关于P和Q的多元函数,当随机选定U和I之后,需要枚举所有的k,并且对Pu,k以及 Qk,i求偏导数。整个式子中仅有 Pu,kQk,i 这一项与之相关,通过链式法则可知
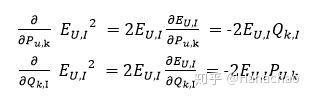
改进的Funk-SVD的矩阵分解
和其他算法一样,我们从“过拟合”和“欠拟合”两个角度来看。
(1) 正则化
Funk-SVD的求解过程也是和一般的机器学习问题一样,也会存在过拟合的问题,因此我们也为其加上正则化项。具体做法就是在损失函数后面加入一个L2正则项,即
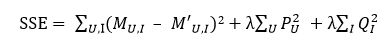
其中,λ为正则化系数,而整个求解过程依然可以使用随机梯度下降来完成。
(2) 偏置
观察式子
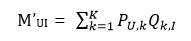
我们发现式子表明用户U对物品 I 的评分全部是由U和I之间的联系带来的,然而实际上,有很多性质是用户或者物品所独有的。比如某个用户习惯于差评,他给所有物品的得分都很低,这仅仅与用户自身有关。又比如某个物品非常完美,所有用户都会给出较高的分数,这也仅仅与物品自身有关。因此,只通过用户与物品之间的联系来预测评分是不合理的,同时也需要考虑到用户和物品自身的属性。于是,评分预测的公式也需要进行修正。不妨设整个评分矩阵的平均分为σ,用户U和物品I的偏置分别为 bu 和 bi ,那么此时的评分计算方法就变成了
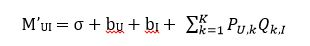
将(1)和(2)结合下,我们就可以得到如下公式:


总结
矩阵分解有如下优点:
- 能将高维的矩阵映射成两个低维矩阵的乘积,很好地解决了数据稀疏的问题;
- 具体实现和求解都很简洁,预测的精度也比较好;
- 模型的可扩展性也非常优秀,其基本思想也能广泛运用于各种场景中。
相对的,矩阵分解的缺点则有:
- 可解释性很差,其隐空间中的维度无法与现实中的概念对应起来;
- 训练速度慢,不过可以通过离线训练来弥补这个缺点;
- 实际推荐场景中往往只关心topn结果的准确性,此时考察全局的均方差显然是不准确的。
给出Funk-SVD的实现及使用示例:
import pickle
import numpy as np
import matplotlib.pyplot as plt
class Funk_SVD(object):
"""
implement Funk_SVD
"""
def __init__(self, path,USER_NUM,ITEM_NUM,FACTOR):
super(Funk_SVD, self).__init__()
self.path = path
self.USER_NUM=USER_NUM
self.ITEM_NUM=ITEM_NUM
self.FACTOR=FACTOR
self.init_model()
def load_data(self,flag='train',sep='\t',random_state=0,size=0.8):
'''
flag- train or test
sep- separator of data
random_state- seed of the random
size- rate of the train of the test
'''
np.random.seed(random_state)
with open(self.path,'r') as f:
for index,line in enumerate(f):
if index==0:
continue
rand_num=np.random.rand()
if flag=='train':
if rand_num < size:
u,i,r,t=line.strip('\r\n').split(sep)
yield (int(u)-1,int(i)-1,float(r))
else:
if rand_num >= size:
u,i,r,t=line.strip('\r\n').split(sep)
yield (int(u)-1,int(i)-1,float(r))
def init_model(self):
self.P=np.random.rand(self.USER_NUM,self.FACTOR)/(self.FACTOR**0.5)
self.Q=np.random.rand(self.ITEM_NUM,self.FACTOR)/(self.FACTOR**0.5)
def train(self,epochs=5,theta=1e-4,alpha=0.02,beta=0.02):#500
'''
train the model
epochs- num of iterations
theta- therehold of iterations
alpha- learning rate
beta- parameter of regularization term
'''
old_e=0.0
self.cost_of_epoch=[]
for epoch in range(epochs):#SGD
print("current epoch is {}".format(epoch))
current_e=0.0
train_data=self.load_data(flag='train') #reload the train data every iteration(generator)
for index,d in enumerate(train_data):
u,i,r=d
pr=np.dot(self.P[u],self.Q[i])
err=r-pr
current_e+=pow(err,2) #loss term
self.P[u]+=alpha*(err*self.Q[i]-beta*self.P[u])
self.Q[i]+=alpha*(err*self.P[u]-beta*self.Q[i])
current_e+=(beta/2)*(sum(pow(self.P[u],2))+sum(pow(self.Q[i],2))) #正则项
self.cost_of_epoch.append(current_e)
print('cost is {}'.format(current_e))
if abs(current_e - old_e) < theta:
break
old_e=current_e
alpha*=0.9
def predict_rating(self,user_id,item_id):
'''
predict rating for target user of target item
user- the number of user(user_id=xuhao-1)
item- the number of item(item_id=xuhao-1)
'''
pr=np.dot(self.P[user_id],self.Q[item_id])
return pr
def recommand_list(self,user,k=10):
'''
recommand top n for target user
for rating prediction,recommand the items which socre is higer than 4/5 of max socre
'''
user_id=user-1
user_items={}
for item_id in range(self.ITEM_NUM):
user_had_look = {}
user_had_look = self.user_had_look_in_train()
if item_id in user_had_look[user]:
continue
pr=self.predict_rating(user_id,item_id)
user_items[item_id]=pr
items=sorted(user_items.items(),key=lambda x:x[1],reverse=True)[:k]
return items
def user_had_look_in_train(self):
user_had_look = {}
train_data=self.load_data(flag='train')
for index,d in enumerate(train_data):
u,i,r=d
user_had_look.setdefault(u,{})
user_had_look[u][i] = r
return user_had_look
def test_rmse(self):
'''
test the model and return the value of rmse
'''
rmse=.0
num=0
test_data=self.load_data(flag='test')
for index,d in enumerate(test_data):
num=index+1
u,i,r=d
pr=np.dot(self.P[u],self.Q[i])
rmse+=pow((r-pr),2)
rmse=(rmse/num)**0.5
return rmse
def show(self):
'''
show figure for cost and epoch
'''
nums=range(len(self.cost_of_epoch))
plt.plot(nums,self.cost_of_epoch,label='cost value')
plt.xlabel('# of epoch')
plt.ylabel('cost')
plt.legend()
plt.show()
pass
def save_model(self):
'''
save the model to pickle,P,Q and rmse
'''
data_dict={'P':self.P,'Q':self.Q}
f=open('funk-svd.pkl','wb')
pickle.dump(data_dict,f)
pass
def read_model(self):
'''
reload the model from local disk
'''
f=open('funk-svd.pkl','rb')
model=pickle.load(f)
self.P=model['P']
self.Q=model['Q']
pass
if __name__=="__main__":
mf=Funk_SVD(‘ml-100k/u.data',943,1682,50)#path,user_num,item_num,factor
mf.train()
mf.save_model()
rmse=mf.test_rmse()
print("rmse:",rmse)
user_items=mf.recommand_list(3)
print(user_items)
文章被以下专栏收录
