爬虫实战:运用requests库和正则表达式爬取淘宝商品信息。

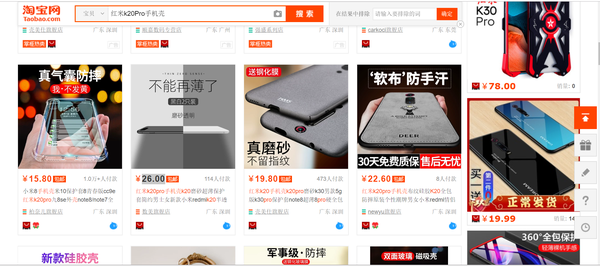
虽然现在淘宝的反爬措施比以前要强很多了,但是爬取淘宝的商品信息还是相对比较简单的,下面就让我们来爬取淘宝上“红米K20 Pro手机壳”的标题、价格、店家城市、销量。如图。


首先,必须要先登录自己的淘宝账号(爬取时必须要登陆才能获取到能爬取到页面信息的cookie,不然过不了反爬),然后在搜索页面按F12,再然后按F5刷新页面。这时,打开Network-Doc-左侧“name”下的第一条,点击Headers,里面会有cookie信息,在编写程序的时候需要将其复制下来,并用字典类型保存它们。(这里因为有cookie就不放图了)。
headers={
"uaer-agent":UserAgent().random //python的一个可以生成随机请求头的库,下文有解释
"cookie":"(自己的信息)"
}在我们爬取信息时,有时候需要爬取的信息并不止一页,所以我们要观察一下淘宝的翻页时候链接的变化。这里从第二页开始。


通过观察我们上面两个链接,我们可以发现翻页之后链接发生变化的是后半部分,在最后“s=44”变为了“s=88”,我把它们分别改为的“s=0”,发现都访问了商品的第一页。因此,我们可以得出结论:第一页的链接最后为“s=0”,每次翻页最后“s=”后的数字都会增加44,这是因为淘宝每一页的商品数就为44。所以我们可以利用这个规律完成翻页操作。
观察和准备的工作做完,我们可以开始编写代码了。首先导入我们要用到的库。
import re //正则表达式
import time
import tqdm //进度条库
import random
import requests
from fake_useragent import UserAgent //python的一个可以生成随机请求头的库,用这个库可以不用复制自己的浏览器信息然后编写第一个函数,作用是获取页面内容。
def get_htmltext(url):
text = ""
try:
headers={
"user-agent": UserAgent().random,
"cookie"://这里写自己的cookie信息
}
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
text = r.text
except:
print("获取页面失败。")
return text接下来我们要获取商品的有用信息并打印在屏幕上,这些信息在网页源代码中。所以首先我们点击右键,查看网页源代码,并且随机查找一个商品的信息,如图。

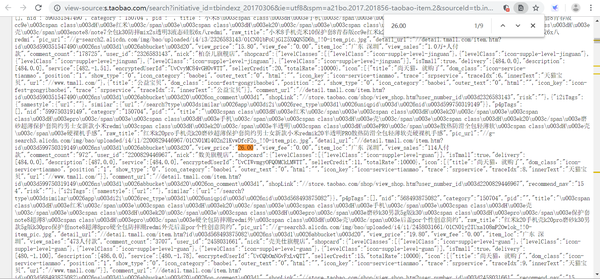

通过观察,我们可以发现商品的标题在"raw_title"之后,而价格、店家城市、销量这些信息则分别在"view_price"、"item_loc"和"view_sales"之后。得知这些信息之后我们可以继续编写代码了。
编写第二个函数,作用是获取商品的有用信息并打印。
def print_imformation(text):
resultPrice = re.findall(r'"view_price":"([\d]*[.]{1}[\d]*)"',text)
resultTitle = re.findall(r'"title":"(.*?)"', text)
resultLocal = re.findall(r'"item_loc":"(.*?)"', text)
resultSales_Volume = re.findall(r'"view_sales":"([\d].*?)"',text)
for i in range(0, len(resultTitle), 1): #find.all函数返回的是列表,用for循环来打印
print("%s:%s" % ("商品标题", resultTitle[i]))
print("%s:%s" % ("价格", resultPrice[i]))
print("%s:%s" % ("店家城市", resultLocal[i]))
print("%s:%s" % ("付款人数", resultSales_Volume[i]))
print("\n")这里使用了正则表达式,正则表达式的用法在这里就不详细赘述了。
最后编写main函数。
def main():
dep=(int)(input("输入要爬取的页数:"))
b=1 #当前页数
print("\n")
for sum in range(0,dep*44,44):
print("第%d页:\n"%(b))
url="https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=%E7%BA%A2%E7%B1%B3k20Pro%E6%89%8B%E6%9C%BA%E5%A3%B3&suggest=history_2&_input_charset=utf-8&wq=%E7%BA%A2%E7%B1%B3&suggest_query=%E7%BA%A2%E7%B1%B3&source=suggest&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s="+str(sum)
text=get_htmltext(url)
get_and_print_imformation(text)
while(b<dep):
sleeptime = random.randint(10, 15)
print("间隔%d秒后爬取下一页。\n"%sleeptime)
time.sleep(sleeptime) #使程序休眠一小段随机时间再爬取下一页,伪装成接近真人的翻页频率,避免因翻页过快被反爬检测到。
break
b=b+1完整程序如下:
import re //正则表达式
import time
import tqdm //进度条库
import random
import requests
from fake_useragent import UserAgent
def get_htmltext(url):
text = ""
try:
headers={
"user-agent": UserAgent().random,
"cookie"://这里写自己的cookie信息
}
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
text = r.text
except:
print("获取页面失败。")
return text
def print_imformation(text):
resultPrice = re.findall(r'"view_price":"([\d]*[.]{1}[\d]*)"',text)
resultTitle = re.findall(r'"title":"(.*?)"', text)
resultLocal = re.findall(r'"item_loc":"(.*?)"', text)
resultSales_Volume = re.findall(r'"view_sales":"([\d].*?)"',text)
for i in range(0, len(resultTitle), 1): #find.all函数返回的是列表,用for循环来打印
print("%s:%s" % ("商品标题", resultTitle[i]))
print("%s:%s" % ("价格", resultPrice[i]))
print("%s:%s" % ("店家城市", resultLocal[i]))
print("%s:%s" % ("付款人数", resultSales_Volume[i]))
print("\n")
def main():
dep=(int)(input("输入要爬取的页数:"))
b=1 #当前页数
print("\n")
for sum in tqdm.tqdm(range(0,dep*44,44))://具体请去查tqdm库的用法
print("第%d页:\n"%(b))
//下面这个网址可以根据自己需要更改,只需要提取到"s="之前的字段
url="https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=%E7%BA%A2%E7%B1%B3k20Pro%E6%89%8B%E6%9C%BA%E5%A3%B3&suggest=history_2&_input_charset=utf-8&wq=%E7%BA%A2%E7%B1%B3&suggest_query=%E7%BA%A2%E7%B1%B3&source=suggest&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s="+str(sum)
text=get_htmltext(url)
print_imformation(text)
while(b<dep):
sleeptime = random.randint(10, 15)
print("间隔%d秒后爬取下一页。\n"%sleeptime)
time.sleep(sleeptime) #使程序休眠一小段随机时间再爬取下一页,伪装成接近真人的翻页频率,避免因翻页过快被反爬检测到。
break
b=b+1
if __name__ == "__main__":
main()
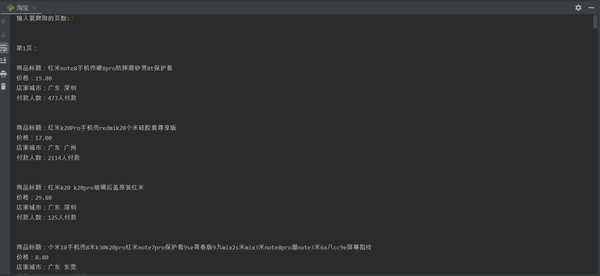
运行结果如图:

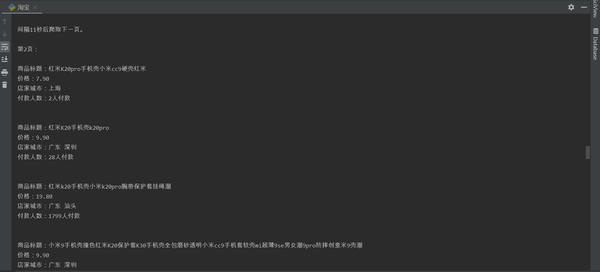

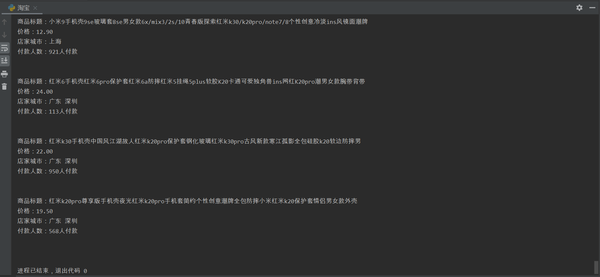

在频繁爬取之后有可能会没能在程序中获取到信息,这是因为反爬作怪封了IP,这时候打开网页搜索或换页的时候也会弹出滑块验证(如图),这时候可以过一段时间并且更换cookie再访问,也可以用代理IP解决,这里就不详细赘述了。