![[论文分享]因子优化](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[论文分享]因子优化

今天分享一篇有关于利用深度学习挖掘因子的文章。该文章是由微软研究院发表在KDD2019上的一篇文章。
文章名:
Individualized Indicator for All:Stock-wise Technical Indicator Optimization with Stock Embedding
文章链接:


1 摘要
简单说,这篇文章提出了一种指标优化的框架(Technical Trading Indicator Optimization (TTIO) framework),该框架通过学习基金经理的投资喜好优化原始技术指标/因子。
2 介绍
概括一下introduction的内容。很多技术指标/因子对不同股票影响是不同的。某一指标的数值完全相同,由于股票本身的属性,其可能出现完全不同的状态;比如银行股的市盈率普遍比其他股票低,如果科技股降到很低的市盈率会有大资金买入,但银行就不会。对于周期性股票,有些指标会呈现周期性的变化,如果以该指标分析周期性股票参考意义不大,但该指标对非周期性股就有很大参考意义,这里我暂时想不到好的例子。总之相同指标不同股票有不同的参考意义。
基于对以上的观察,作者提出了TTIO框架去优化指标。如何根据股票类型优化指标其最大的挑战在于如何有效地获得不同股票特征的表达。一种直接的方法是从经验丰富的基金经理那里人工收集此类信息。但是这种方法容易受到人类主观影响,不确定性强,其次人工成本高,因此这种方法并不可取。
为了解决这些问题,作者提出了一种通过利用不同基金经理的投资喜好去学习不同股票的表达(embedding特征)。虽然不同的基金经理风险偏好不同,但是同一基金下的不同股票都有一些相似性,可以通过这个相似性去学习不同股票的embedding特征。然后通过结合股票的embedding特征和不同指标/因子值可以优化指标值。
3 背景知识
3.1 论文中所使用的技术指标
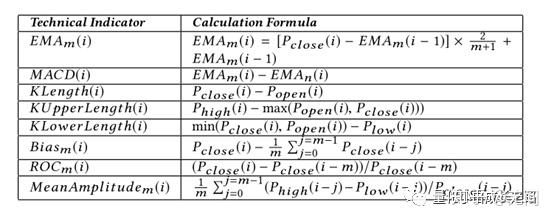

P_high 表示最高价格,其他P值类似。
各个指标的解释(简单看看就好,不重要):
Exponential Moving Average(EMA):消除价格的日常波动,越近收盘的数据权重越大。
Moving Average Convergence Divergence(MACD):通过两条EMA线之间的差计算得出的,其中一条线来自长周期(慢线),另一条线来自短周期(快线)。m和n的值通常是12和26。
K Line(KL):发现股票的趋势和波动。
与Bias有关的指标:衡量与简单移动平均线的偏差。
与ROC相关的指标:指标变化幅度。
与Amplitude有关的指标:最近一段时间内的振荡特性。
3.2 基于因子/指标的组合投资策略
由于有效的技术交易指标可以描绘市场的未来趋势,因此技术交易员通常依靠它们来构建投资组合以最大化回报。一种常用的方法是选择指标值排名前k的股票,并平均投资者前k个股票,以降低风险。k是在通过平衡投资组合的稳健性和利润调整得到的超参数。
提高投资策略稳健性的另一种方法是利用指标组合。由于不同的指标可以捕获涵盖股票不同属性(包括趋势,动量和波动性)的各种价格模式,因此单个指标有其局限性,在某些情况下可能会失效。另一方面,将多个指标组合在一起可以克服单个指标的无效来提高投资的稳健性。因此,在采用某些指标组合方法之后,可以基于新的组合指标值来管理投资组合,并以相同的权重投资前k个股票。
3.3 评价因子/指标的有效性
(1) informationcoefficient(IC):


I_t-1 为t-1时刻的因子值(indicator),R_t 为t时刻的收益(reward)。corr表示相关性计算。
(2) Rankinformation coefficient (Rank IC),计算公式如下:
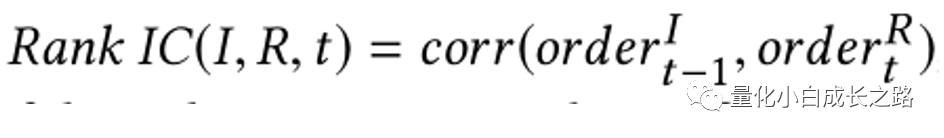

Order_I_t-1,表示在t-1时刻下不同股票在I指标下排名情况,Order_R_t,表示不同股票在t时刻的收益排名。
IC或Rank IC值介于-1到1直接,负的值越大表示越负相关,正的值越大表示越正相关。
4 方法
方法章节分为两部分:(1)股票的embedding,(2)指标的优化。第一节主要介绍了如何利用基金经理的投资喜好训练得到股票的embedding,第二节主要介绍了如何利用embedding特征优化因子/指标。
4.1 股票的embedding
4.1.1 基金经理的历史投资组合
一只基金往往会投资多支股票。如下图,左边是不同的基金,右边是不同的股票。若股票与基金相连表示该基金投资了这只股票,边的权重越大表示投资比例越高。


4.1.2 二分图(BipartiteGraph)构建
作者提取股票embedding的方法主要是利用deepwalk算法进行训练的,不懂deepwalk的朋友可以网上找一些资料,后文我会简单介绍。
训练deepwalk前首先要构造一个图。图是由顶点和边组成的,形式化可以表示为G=(V, E),V表示顶点,E表示边。作者利用基金的投资情况构建了一个二分图,形式化表示为G=(U,V,E),U和V都是顶点,E是边。二分图定义为顶点V可分割为两个互不相交的子集的图称为二分图,如下图形式。
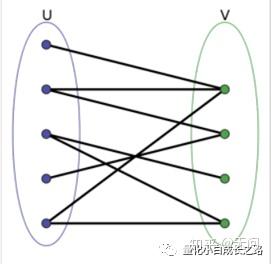
作者构建的二分图中,U表示基金,V表示股票,E就是基金投资股票的比例。
4.1.3 股票embedding的学习
Deepwalk模型的简单介绍:Deepwalk它的输入是一张图或者网络,输出为网络中顶点的向量表示。DeepWalk的核心是通过截断随机游走(truncated random walk)学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。
讲的很抽象,简单的说就是训练一个含embedding层的神经网络,输入是某节点,输出是某节点的邻居(这个邻居可以通过随机游走若干步得到,不一定是相连的)。通过这个方法训练得到的网络我们只需要取其中stock的embedding即可。
构建好基金-股票图后,需要在图上进行随机游走生成样本训练。基金-股票图上的随机游走(Random Walk on Fund-Stock Graph)形式如下。对于股票S,其游走到基金F的概率如下:
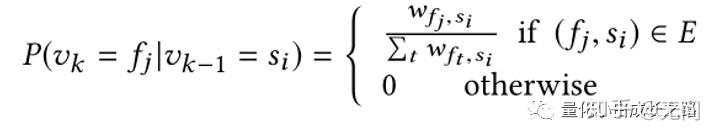

W就是该股票在基金F中的投资份额。如果某个基金投资股票S越多,股票S游走到基金F的概率就越大。
类似地,从基金F游走到股票S的概率如下:
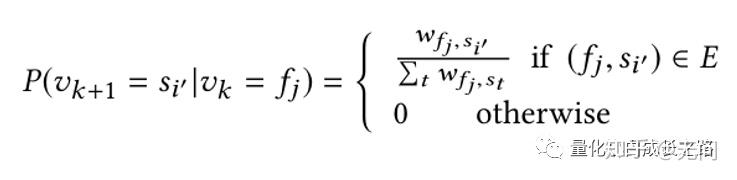

4.2 指标优化模型
股票的embedding提取出来之后就需要训练指标优化模型了。
指标优化模型由三部分组成:(1)一个re-scaling网络,其输入每个股票的embedding,输出为一些权重;(2)指标优化器,通过将原始指标乘以重新缩放的权重来生成新的指标;(3)轮换学习机制。
4.2.1 re-scaling网络
计算流程如下两个公式:
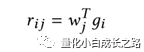
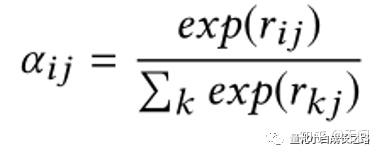
Re-scaling网络主要由上面两个式子组成,g_i表示第i支股票的embedding,w_j表示第j个指标对应的一个一维向量表示(需要学习的参数),通过计算w*g可以得到对于指标j来讲不同股票在该指标下的参考意义。上面第二个公式就是很简单的softmax形式,一个re-scaling的操作。Alpha_ij值越大说明第j只股票在第i个指标上是越有参考意义的。
4.2.2 指标优化器
下图公式所得到的结果为最终指标的优化值。I表示原始指标,I’ 表示优化后的指标值。

训练这个网络的目标函数为:
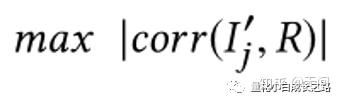
解释一下就是最大化转化后指标I和收益 R(reward) 的IC绝对值。其目的就是为了让新生成的指标和未来收益尽可能相关。
4.2.3 Rotation Learning Mechanism(轮换学习机制)
作者提出了轮换学习机制去优化指标,简单概括就是一个滚动训练的方法。每到一个新的时间点就重新利用一个历史时间窗内的数据训练模型,然后去优化指标。


5 实验结果
这边不分析实验结果了,基本就是证明了方法的有效性。
6 总结与思考
这篇文章提供了一个很好的因子挖掘思路,可以对单因子进行优化,也可以对组合因子进行优化。但是实际应用我觉得这个方法还是比较鸡肋的,实际效果也不一定好。虽然作者的实验结果挺好,但是我觉得这些实验不足以证明这个方法的有效性,作者只是在一些简单的因子上做了实验,实际情况我们往往会使用更多更复杂的因子,一旦对这些复杂因子进行优化可能就不一定有好的效果了。除此之外,当多因子效果不好时完全可以通过超参调整进行优化或添加新的因子。
但是这篇文章给了我一个启发,“万物皆可embedding!!!”,在训练深度神经网络的时候,很多情况都可以进行embedding,比如时间(周一到周五有五个类别,比如周五投资可能普遍保守一点),又比如涨幅(如果以1个点为间隔,可以有20个类别的涨幅)。
由于个人的知识储备不足,在因子模型等一些地方都没有深入的理解,如果有错误的地方,欢迎批评指正。
文章被以下专栏收录
