
零基础用爬虫爬取网页内容(详细步骤+原理)

网络上有许多用 Python 爬取网页内容的教程,但一般需要写代码,没有相应基础的人要想短时间内上手,还是有门槛的。其实绝大多数场景下,用 Web Scraper (一个 Chrome 插件)就能迅速爬到目标内容,重要的是,不用下载东西,也基本不需要代码知识。
在开始之前,有必要简单了解几个问题。
a、爬虫是什么?
自动抓取目标网站内容的工具。
b、爬虫有什么用?
提高数据采集效率。应该没有人想让自己的手指不停的重复复制粘贴的动作,机械性的事情,就应该交给工具去做。快速采集数据,也是分析数据的基础。
c、爬虫的原理是什么?
要了解这一点,需要先了解人类为什么能浏览网页。我们通过输入网址、关键字、点击链接等形式发送请求给目标计算机,然后将目标计算机的代码下载到本地,再解析/渲染成看到的页面。这就是上网的过程。
爬虫做的就是模拟这一过程,不过它对比人类动作飞快,且可以自定义抓取内容,然后存放在数据库中供浏览或下载。搜索引擎能够工作,也是类似原理。
但爬虫只是工具,要让工具工作起来,就得让爬虫理解你想要的是什么,这就是我们要做的事情。毕竟,人类的脑电波没法直接流入计算机。也可以说,爬虫的本质就是找规律。


Photo by Lauren Mancke on Unsplash
这里就以豆瓣电影 Top250 为例(很多人都拿这个练手,因为豆瓣网页规整),来看看 Web Scraper有多么好爬,以及大致怎么用。
1、在 Chrome 应用店里搜索 Web Scraper,然后点击「添加拓展程序」,这时就能在 Chrome 插件栏里看到蜘蛛网图标。
(如果日常所用浏览器不是 Chrome,强烈建议换一换,Chrome 和其他浏览器的差别,就像 Google 和其他搜索引擎的差别)

2、打开要爬的网页,比如豆瓣 Top250 的 URL 是 https://movie.douban.com/top250,然后同时按住 option+command+i 进入开发者模式(如果用的是 Windows,则是 ctrl+shift+i,不同浏览器的默认快捷键可能有不同),这时可以看到网页弹出这样一个对话框,不要怂,这只是当前网页的 HTML(一种超文本标记语言,它创建了 Web 世界的一砖一瓦)。
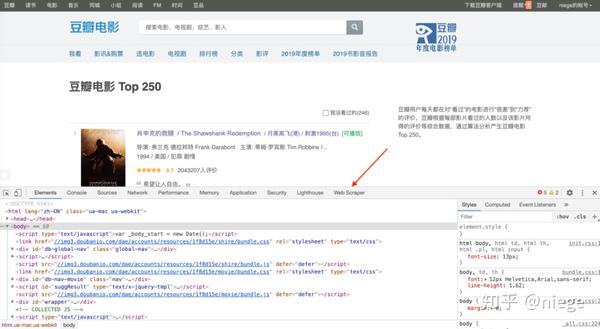

只要按照步骤 1 添加了 Web Scraper 拓展程序,那就能在箭头所示位置看到 Web Scraper,点击它,就是下图的爬虫页面。
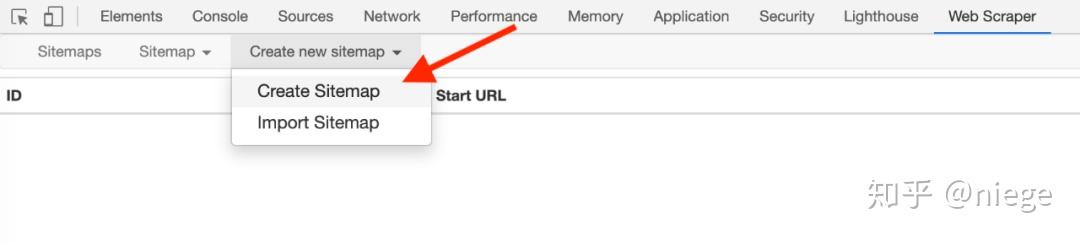

3、依次点击 create new sitemap 和 create sitemap,创建爬虫,sitemap name 里随便填,只是为了自己辨认,比如就填 dbtop250(别写汉字、空格、大写字母)。start url 里一般复制粘贴要爬网页的 URL,但为了让爬虫理解我们的意图,最好先观察一下网页布局和 URL,比如 top250 采用的是分页模式,250 个电影分布在 10 个页面里,每页 25 个。
第一页的 URL 就是 https://movie.douban.com/top250
而第二页开始是 https://movie.douban.com/top250?start=25&filter=
第三页是 https://movie.douban.com/top250?start=50&filter=
...
只有一个数字略不一样,我们的意图是爬取 top250 的电影数据,所以 start url 里不能简单的粘贴 https://movie.douban.com/top250,而应该是 https://movie.douban.com/top250?start=[0-250:25]&filter=
注意 start 后面[ ] 里的内容,它代表每隔 25 是一个网页,爬取 10 个网页。
最后点击 Create sitemap,这个爬虫就算建好了。


(URL 里填 https://movie.douban.com/top250 也能爬,但没法让 Web Scraper 理解我们要爬的是 top250 所有页面的数据,它只会爬第一页的内容。)
4、建好爬虫之后的工作是重点,为了让 Web Scraper 理解意图,必须创建选择器,点击 Add new selector。
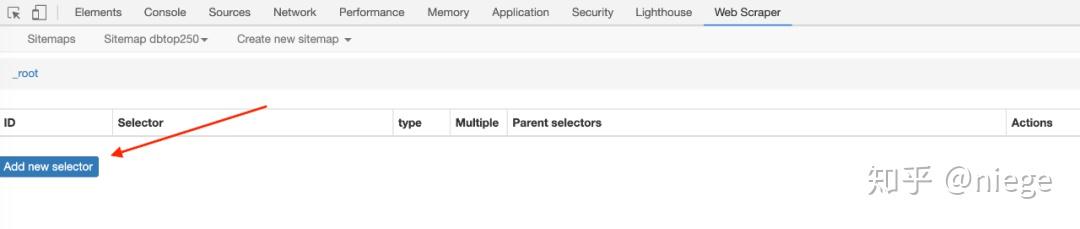

然后会进入选择器编辑页面,其实也是简单的点点点。它的原理是,几乎所有用 HTML 编辑的网页,构成元素都是一个个长得一样或差不多的方框(或者叫做容器),且每一个容器里的布局、标签也类似,越规整的页面越是统一,从 HTML 代码里也能看得出来。
所以,如果我们设定好了选择元素和顺序,爬虫就能照着设定自动模拟选择,也就能将数据整整齐齐的爬下来。在要爬取多种元素的情况下(比如爬豆瓣 top250 希望同时爬取排名、电影名、评分、一句话影评),可以先选容器,再依次选取容器内的元素。
如图所示,依次
- 在 id 栏里输入 container(容器)。Web Scraper 所以要输入东西的地方,都不要输入汉字。
- 在 Type(类型)的下拉选项里选择 Element(元素)。Web Scraper 的 Type 很多,可以满足不同网页类型、不同场景的爬虫需求。
- 勾选 Multiple(多选),因为要爬所有。
- 点击 Selector 里的 Select。
- 在网页里点击第一个方框(容器)。指针移到网页内容上时会自动显示不同大小的方框,方框框住整个电影所有信息时点击(边缘位置)。
- 同样点击第二个容器。这时可以看到当前网页所有电影都已被选择,因为 Web Scraper 理解了你要选择所有。
- 点击 Done selecting。选择完成,这时 Seletor 的第 4 个输入框里会自动填上 .grid_view li ,你要是能直接在输入框里写上 .grid_view li 也行。
- 最后点击 Save selecting。保存选择器。
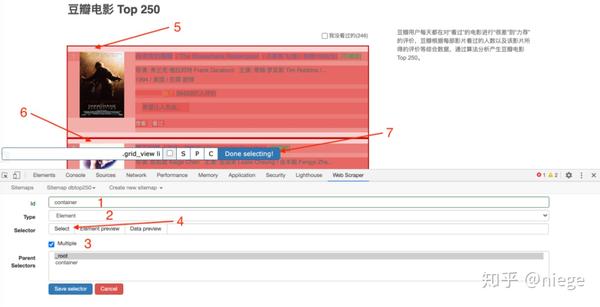

5、第 4 步只是创建了容器的选择器,要爬取的东西,Web Scraper 还是没有理解,需要进一步在容器里选择我们想要的数据(电影排名、电影名、评分、一句话影评)。
完成第 4 步 Save selecting 后,会看到爬虫的根目录 root,点击创建的 container 那一栏。


看到根目录 root 后跟着 container,点击 Add new selector,创建子选择器。


再次进入 seletor 编辑页面,如下图所示,这次不一样的地方是,id 那里填我们对所要抓取元素的定义,随便写,比如先抓取电影排名,写个 number;因为排名是文本类型,Type 里选择 Text;这次只选取一个容器里的一个元素,所以 Multiple 不勾选。另外,选择排名的时候,不要选错地方了,因为你选啥爬虫就爬啥。然后一样点击 Done selecting 和 save selector。
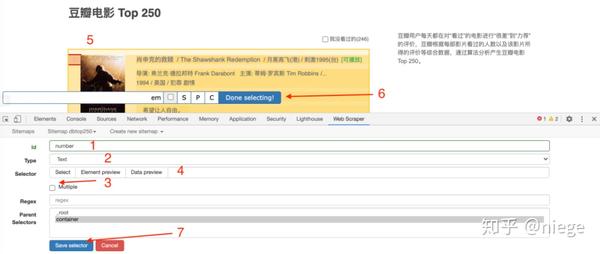

这时候爬虫已经知道爬取 top250 网页里所有容器的影片排名。再以同样的方法,创建另外 3 个子选择器(注意是在 container 的目录里),分别爬取电影名、评分、一句话影评。
创建好后是这样的,这时所有选择器已经都已创建完,爬虫已经完全理解意图。
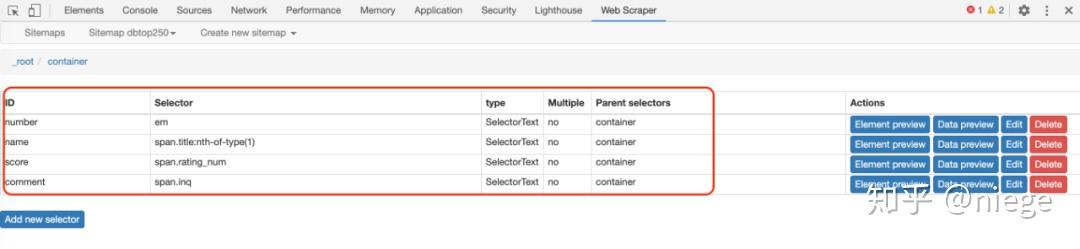

6、接下来的事就是让爬虫跑起来了,依次点击 sitemap dbtop250 和 scrape(抓取)
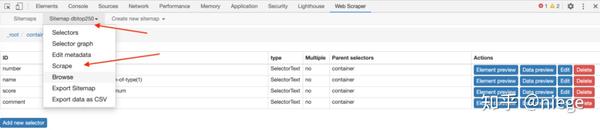

这时 Web Scraper 会让填写请求间隔时间和延迟时间,都保持默认的 2000 (单位是毫秒,即 2 秒)就好,除非网速特别快或特别慢,然后点击 Start sraping。


到了这里,会弹出一个新的自动滚动的网页,就是我们在创建爬虫时输入的 URL,大概一分钟左右,爬虫会工作完毕,弹窗自动消失(自动消失即代表爬取完毕)。

而 Web Scraper 页面也会变成这样
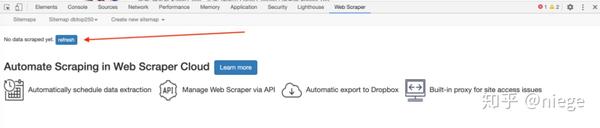

7、点击 refresh,即可预览爬虫成果:豆瓣电影 top250 的排名、影片名、评分、一句话影评。看看有没有问题。(比如有没有 null,有 null 说明对应的选择器没有选择好,一般页面越规整,null 就越少。遇到 HTML 不规整的网页,比如知乎,跑出 null 较多,可以返回选择器调整一下)
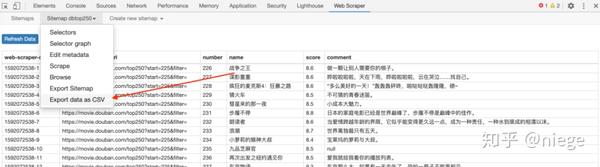

这时可以说是大功告成了,只要依次点击 sitemap dbtop250 和 Export date as CSV,即可将数据表以 CSV 的格式下载下来,之后想怎么用怎么用。
值得一提的是,浏览器抓取的内容,一般都保存在了 local starage 数据库里,这个数据库功能比较单一,并不支持自动排序。所以如果你没有安装额外的数据库并设置好,那么爬取下来的数据表会是乱序的。这种情况,一个解决办法是导入到 google sheet 再做清洗,另一个一劳永逸的办法是,安装额外的数据库,比如 CouchDB ,并在爬取数据之前,将数据保存路径更换为 CouchDB ,这时爬取数据,预览及下载下来,就是顺序的了,比如上面的预览图片。

这整个过程看起来可能麻烦,其实熟悉后很简单,这种小量级的数据,从头到尾二三分钟时间就 ok。而且像这种小量级数据,爬虫还没有充分体现出它用途。数据量越大,爬虫的优越性越明显。
比如爬取知乎各种话题的精选内容,可以同时爬取,20000 条数据也只要几十分钟。

自拍
如果看到这里,你觉得照上面这样一步步来还是费劲,有个更简单的方法:
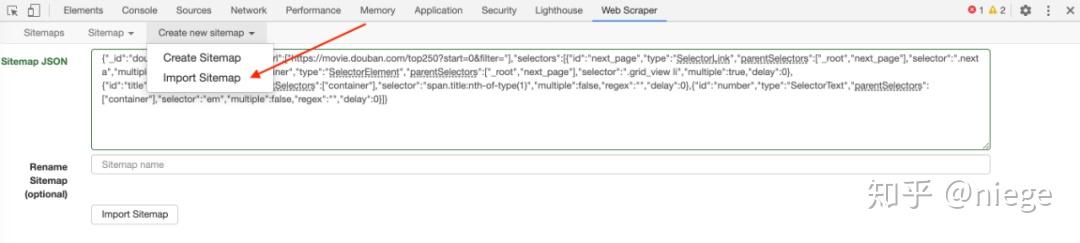
通过 Import sitemap,将下面这段爬虫代码复制粘贴一下,导入进去,就可以直接开始抓取豆瓣 top250 的内容了。(它就是由上面的一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":[" https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0}]}

最后,这个文章只涉及 Web Scraper 与爬虫的冰山一角,不同网站风格不一样、元素布局不一样、自身爬取需求不一样,爬取方法也各不一样。
比如有的网站需要点击「加载更多」才会加载更多,有的网站下拉即加载,有的网页乱七八糟,有时候需要限定爬取数量(不然不断网爬虫就一直爬),有时候需要抓取二级、多级页面的内容,有时候要抓取图片,有时候要抓取隐藏信息等等。各种情况多的很,爬豆瓣 top250 只是入门体验版操作,只有了解爬虫原理、观察网站规律,才能真正用好 Web Scraper,爬取想要的东西。
题图 by Hal Gatewood on Unsplash
文章首发于公众号「步学无术」,作者微 m644003222