首发于 NLP那点事
切换模式

文本相似度匹配模型--对knrm的改进

Edison
不忘初心 方得始终
一、knrm模型
knrm是Interaction based文本相似度模型,模型架构如下:

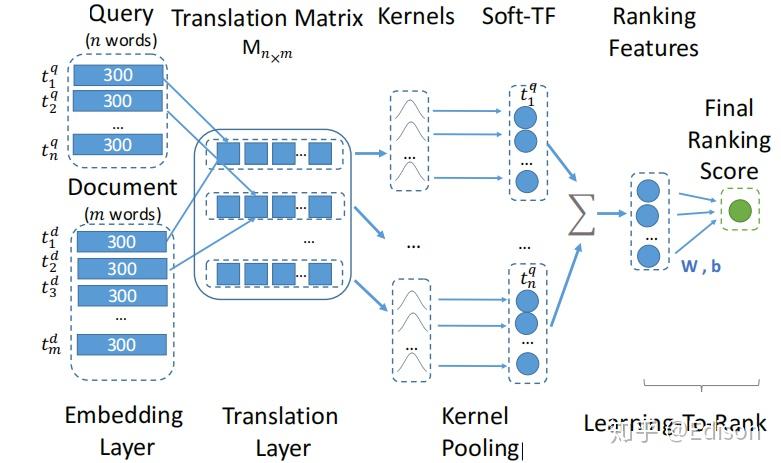
具体步骤如下:


公式从最后往前看,6)embedding;5)计算query 和document的cos matching matrix;4)对 matching matrix 每个元素计算RBF kernel,然后按列相加得到3),2)log然后累加,1)接tanh
具体可参见论文《End-to-End Neural Ad-hoc Ranking with Kernel Pooling》
本人自己用pytorch实现了knrm,并用蚂蚁金服ATEC数据做测试,acc在84%左右。
具体代码参见git: https://github.com/EdisonChen0816/knrm_pytorch
二、对knrm的改进
knrm是一个比较简单的特征提取器,只做了cos和kernel,并且输出接了一个简单的分类器tanh(wM+b)。
如果特征提取器比较强大,如bert,输出可接一个简单的分类器,比如,bert+softmax。
如果特征提取器不够强大,还想要一个不错的结果,那么输出应该接一个比较强大的分类器,比如,onehot+xgboost,tfidf+gbdt。
本着这样的思想,我们认为knrm的特征提取不是那么的强大,输出应该接个强大的分类器。我们对其做了两点改进:
改进一,用11个核,核参数不是学习出来的,而且按照一定的规则生成出来的。代码如下:
def kernel_mu(n_kernels, manual=False):
if manual:
return [1, 0.95, 0.90, 0.85, 0.8, 0.6, 0.4, 0.2, 0, -0.2, -0.4, -0.6, -0.80, -0.85, -0.90, -0.95]
mus = [1]
if n_kernels == 1:
return mus
bin_step = (1-(-1))/(n_kernels-1)
mus.append(1-bin_step/2)
for k in range(1, n_kernels-1):
mus.append(mus[k]-bin_step)
return mus
def kernel_sigma(n_kernels):
sigmas = [0.001]
if n_kernels == 1:
return sigmas
return sigmas+[0.1]*(n_kernels-1)改进二:输出改用更强大的分类器xgboost,knrm特征+xgboost
最终采用同样的数据做训练和测试,acc在87%左右,比knrm高出3个百分点。
具体代码参见git: https://github.com/EdisonChen0816/knrm_xgboost
编辑于 2020-08-01 19:21
自然语言处理
文本分类
相似度计算
文章被以下专栏收录
