
初识数据分析(一)

工作和生活中,我们每天都会做出形形色色的决策,这个衣服要不要买?哪个销售线索是最有效的?
决策是一个复杂的思维操作过程,你想想自己最近的一个决策是怎么进行的?
决策的过程由信息搜集、处理分析,最后作出判断、得出结论构成。没有数据思维的决策往往只依赖于决策者的经验和直觉,导致决策的结果有偏差,有很大的概率会造成失误。
而数据思维能帮助我们做出更精准的决策,找到解决问题的最优解,同时还能发现蕴藏在数据背后的奥秘,从而发挥巨大的价值。
越来越多的公司在推行数据驱动决策,各行各业都需要具有数据思维的人。拥有数据分析技能之后,能让你在工作和生活中做出更佳的决策。
要掌握数据分析需要三方面的知识:分析工具、统计学知识、行业基本知识。
据分析是一个完整的过程,从一开始的明确需求到最后的结果呈现,一般分为如下五个步骤:
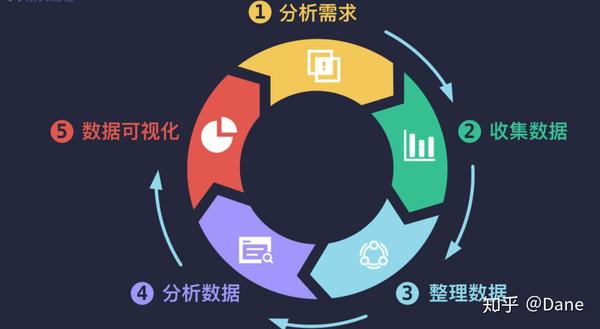

第一步,分析需求,明确目标。我们要确定进行数据分析任务要解决什么问题,这个目标非常重要,因为它是我们整个过程的导向。然后进行问题拆解,包括我们从哪些角度来分析这个问题,采用哪些方法和数据指标;
第二步,采集第一步确定的数据,常用的数据获取方法包括从公开数据库、自有数据库中获取,以及使用爬虫来爬取各种网站上的数据;
第三步,整理数据,也就是数据清洗。把上一步获取的杂乱无章的数据按照我们需要的维度进行整理。数据是数据分析过程里的证据,所以数据的获取和清洗非常重要;
第四步,分析数据,采用数学方法、统计方法等对数据进行分析操作;
第五步,数据可视化,将分析结果以直观的形式进行展示。
到这里你对数据分析过程已经有了大概的认识
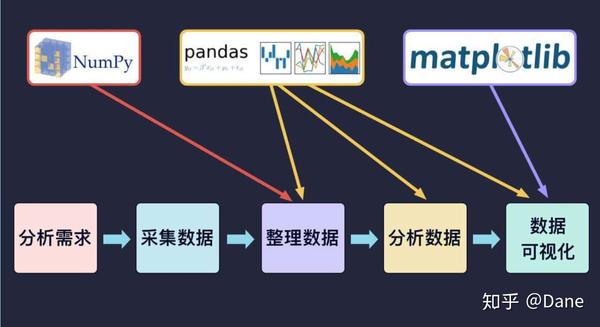
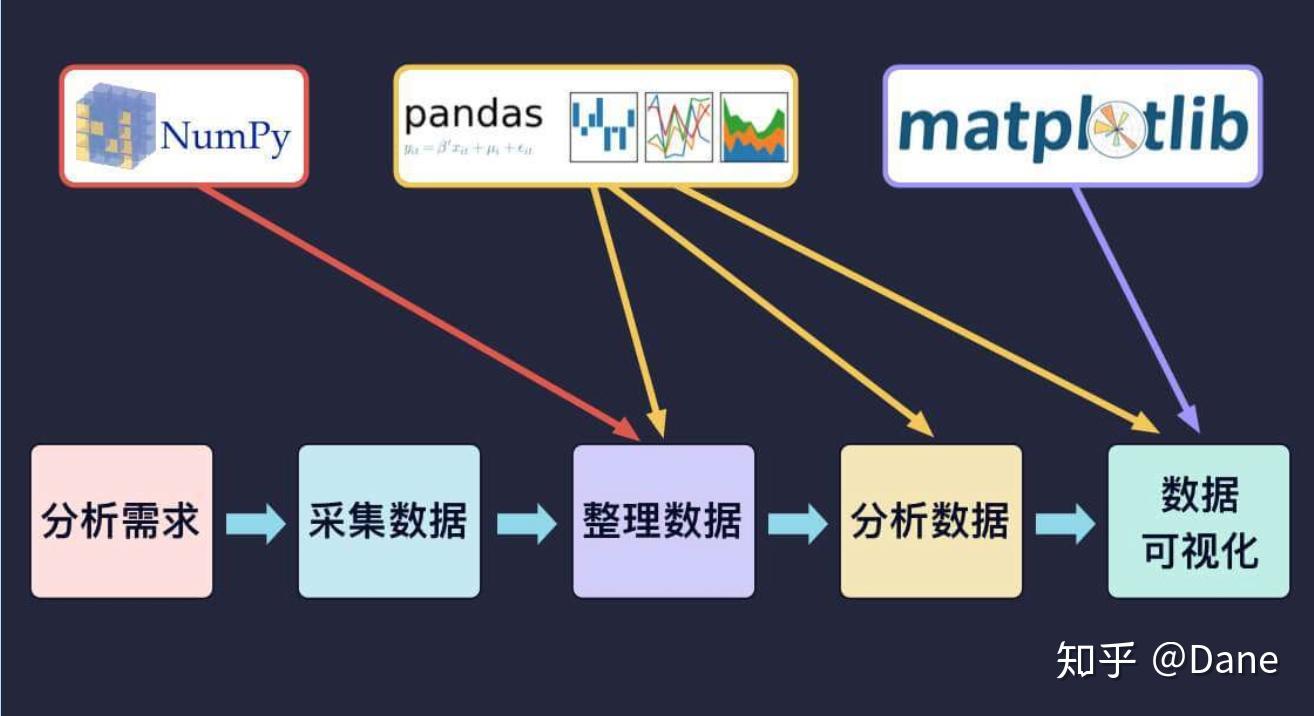
前面讲的数据分析五大步骤里,除了前两个步骤,后面三个都将借助 Python 数据分析模块来帮我们完成。
NumPy 是一个用于数值运算的 Python 库,专门对数值运算进行优化,最大的优势是运行高效。
Matplotlib 是常用的数据可视化的工具包,用来绘制各种图表,更好地展示数据。
Pandas 是 Python 重要的数据分析工具包,也是目前非常流行的 Python 数据分析工具。最初它被作为金融数据分析工具由全球资产管理公司 AQR 在 2008 年 4 月开发,最终在 2009 年底开源出来。
Pandas 的底层数据结构采用 NumPy 来实现,我们也可以把 pandas 理解成是对 NumPy 的封装,从而让数据分析的一些功能的实现变得更轻松方便。
多维数组
NumPy,全称是 Numerical Python,它是目前 Python 数值计算中最重要的基础模块。NumPy 是针对多维数组的一个科学计算模块,这个模块封装了很多数组类型的常用操作。
NumPy 中最重要的对象是多维数组(ndarray),ndarray 是 N-dimensional array,即 N 维数组。
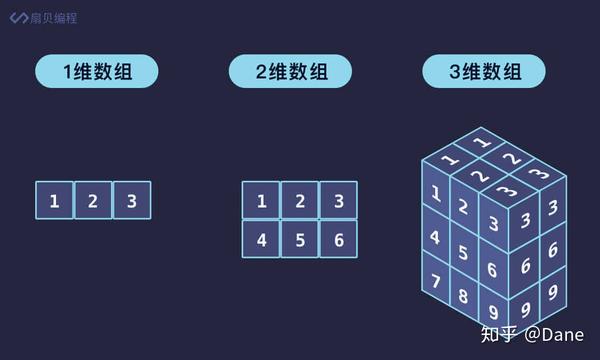
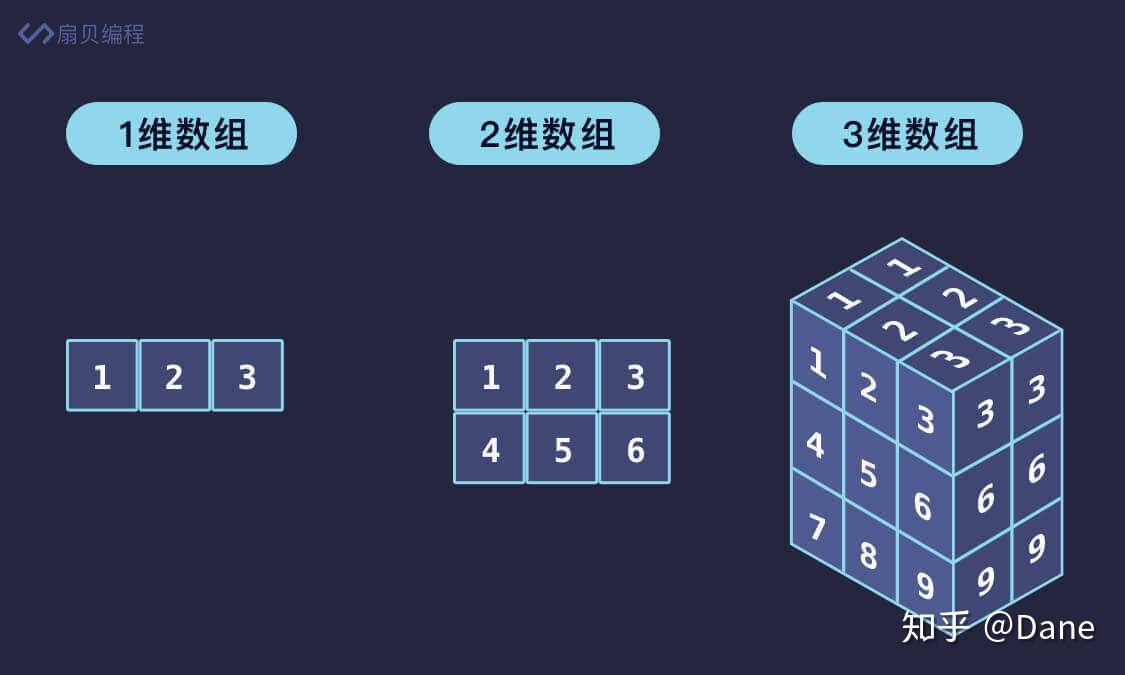
一维数组
一维数组是一系列相同类型数据的集合,它其实和列表很相似,只是列表中的元素类型可以是任意的。
要创建一个多维数组很简单,将一个列表作为参数传入 numpy 中的array()方法即可:
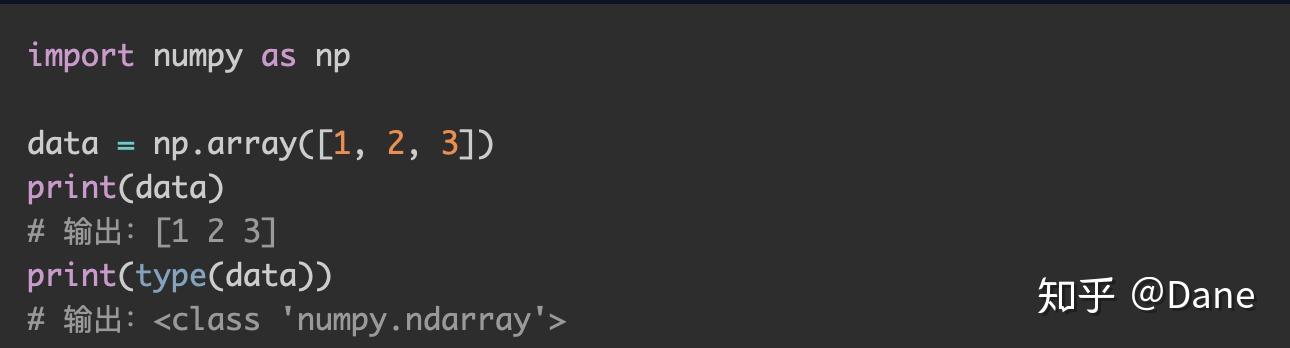

可以看到,打印出来的多维数组和列表也很像,只是少了分隔的逗号。通过type()函数可以看到,data确实是 numpy 中的 ndarray 类型。
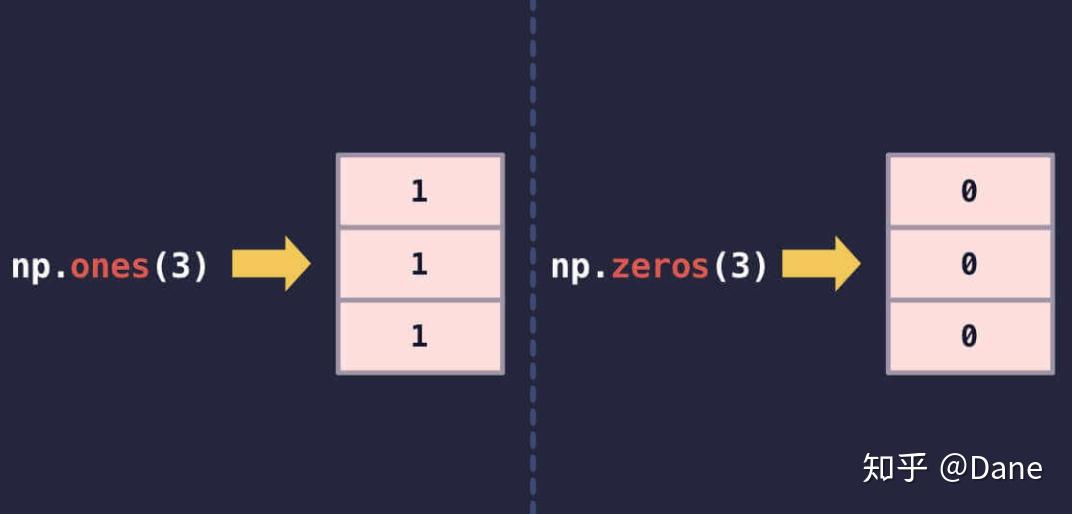
除了使用np.array()方法来创建一个多维数组,numpy 还提供了两个实用的方法——np.ones()和np.zeros()。
从这两个方法的名称就能猜出它们的作用是什么——分别生成元素全为 1 和 0 的多维数组。


np.ones()和np.zeros()的参数用于指定生成的多维数组里有多少个元素。上述代码中都传入了 3,因此生成了包含 3 个 1 和 0 的多维数组。

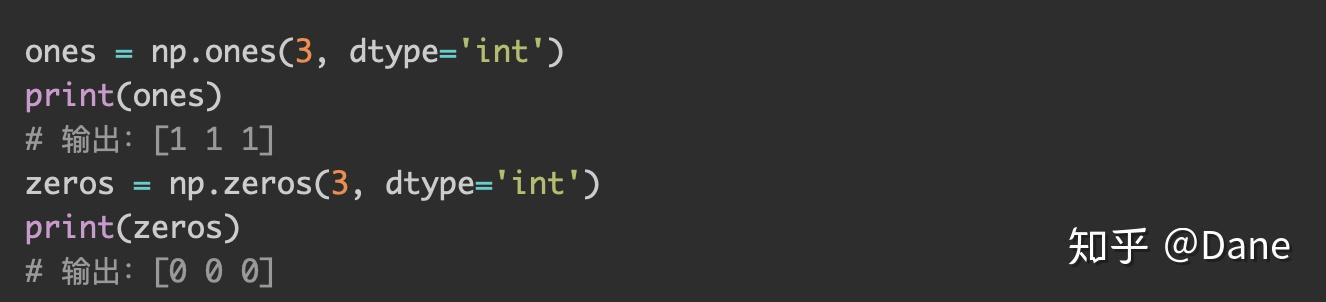
你应该发现了,生成出来的不是 1 和 0,而是 1. 和 0.。这是因为默认生成的是浮点数,numpy 会省略小数点后的 0,因此 1.0 和 0.0 变成了 1. 和 0.。
如果我们想要生成整数的话,可以传入dtype参数来指定类型。

你可能会好奇:既然有了列表类型,为什么 numpy 还要创造一个 ndarray 类型呢?
因为列表不能满足 numpy 的需求, ndarray 相比列表更加的简洁与高效。接下来,我来带你领略一下 ndarray 的强大!
多维数组的加减乘除
列表间只有加法操作,作用是将两个列表的元素合并在一起。而多维数组间可以进行加减乘除的四则运算,运算规则也很简单:将两个数组中对应位置的元素一一进行运算。
什么是对应位置的元素一一进行运算?


ata是[1 2],ones是[1. 1.],第一个元素和第一个元素相加,第二个元素和第二个元素相加,最终便得到[2. 3.]。
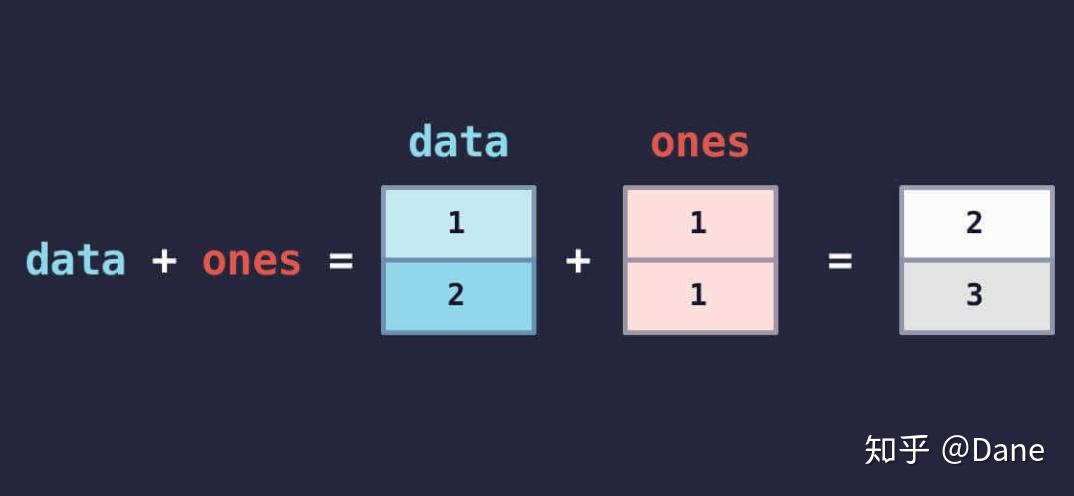

剩下的减法、乘法和除法的运算规则也同样如此,图解如下:
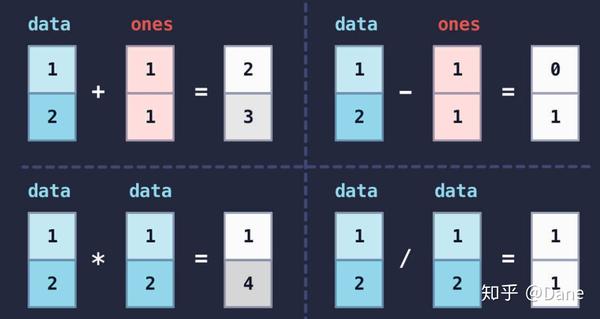

除了多维数组间的四则运算,多维数组直接和数字进行计算的方式也很常用,举个例子:


多维数组和数字的四则运算会作用在数组中的每个元素上,这在 numpy 中被称为广播(Broadcasting)。
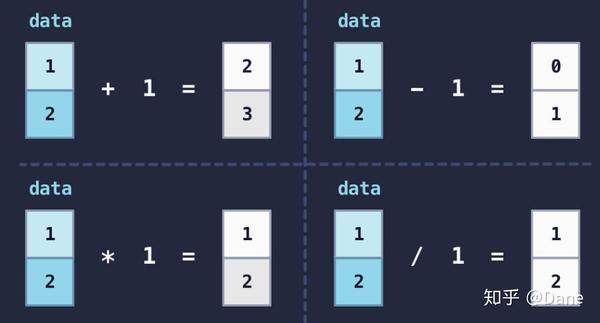
因为广播规则,[1 2] + 1相当于[1 2] + [1 1],因此结果为[2 3]。
剩下的减法、乘法和除法的运算规则也同样如此,图解如下:

上述效果用列表来实现也是可以的,一般我们会这样写:


用列表就必须用到循环,而 numpy 中这种不用编写循环就可以对数据进行批量运算的方式叫做矢量化。numpy 中的矢量化操作把内部循环委托给高度优化的 C 和 Fortran 函数,从而实现更清晰,更快速的 Python 代码。
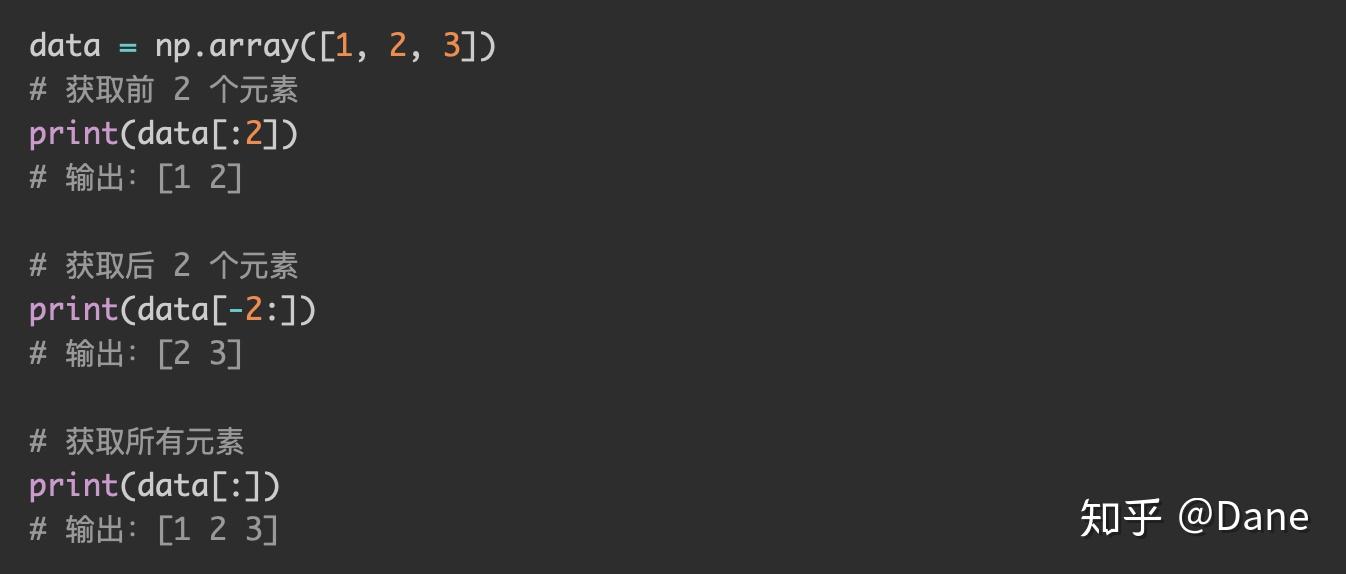
说到列表,你肯定会想到其中的索引、分片操作。同样的,在 numpy 的多维数组中也有索引和分片,使用方式和列表也很相似。
索引
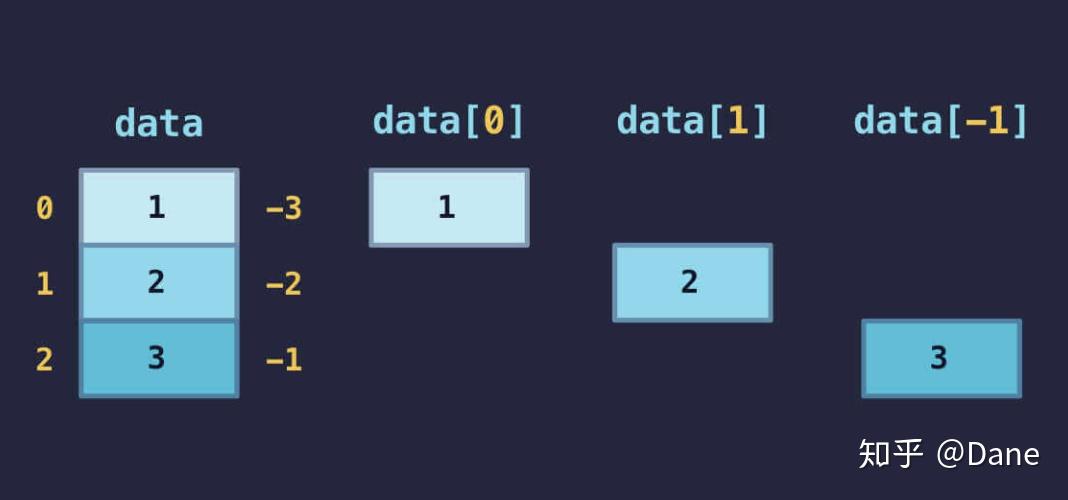
numpy 中多维数组的索引也是从 0 开始,以多维数组的长度减 1 结束。写法也和列表索引一样:


列表中很实用的反向索引在多维数组中也同样适用,我们可以直接使用data[-1]获取数组中的最后一个元素。

分片
多维数组的分片和列表的分片也是基本类似的,形如data[m:n]。分片是左闭右开区间,即包含 m 不包含 n,也就是获取索引为 m 到 n-1 之间的元素(包含 m 和 n-1)。


当然,多维数组也同样支持反向索引分片,使用data[-3:-1]也同样能得到[1 2]。
分片有几个小技巧。在学列表分片时我们讲过,冒号前后的值是可以省略的。省略后冒号前默认为 0,冒号后默认为列表的长度。这同样适用于多维数组,所以通过冒号前后值的省略,有如下分片小技巧:

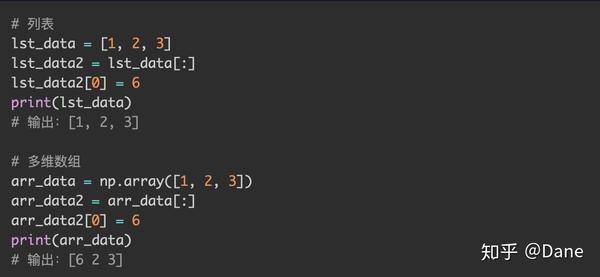
需要注意的是,列表分片是将分片后的数据复制了一份,而多维数组的分片则是返回原数据其中的一块,并没有复制数据。
因此,对列表分片后的数据进行更改不会影响原数据,但对多维数组分片后的数据进行更改会影响到原数据。

numpy 为什么会这样?答案是:这一切都是为了性能。
numpy 设计的目的是处理大数据,所以你可以想象一下,在处理几百万甚至几千万条数据时,每进行一次分片操作就将数据复制一遍将会产生何等的性能和内存问题。
所以,numpy 中的切片默认不会复制一份副本,而是返回原数据中的一块,被称为视图(View)。如果你确实想要得到一份副本,则需要手动调用copy()方法进行复制,例如:arr_data[:].copy()。
还有一个小技巧是分片支持传入第三个参数——步长。即分片时每隔几个数据取一次值,步长的默认值为 1。


当步长为负数时,会将顺序反转。我们可以利用这个特性来实现列表或多维数组的快速反转。


通用方法
在介绍通用方法前,我先向你提个问题:假设你是某篮球俱乐部的教练,现在首发阵容还差一人。现有三名球员备选,他们近 10 场比赛的得分数据如下,你会选择谁进入首发阵容呢?
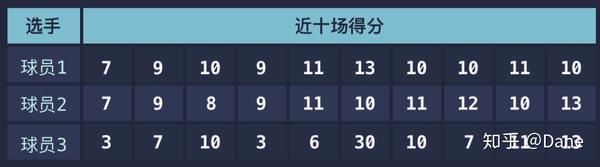

你可能会这么想:求出每个球员的平均得分,谁平均得分高就选谁。我们来用 numpy 求一下平均得分:


可以看到,使用 numpy 求平均数十分简单。我们先用np.array()方法将每位球员近十场得分存到一个多维数组当中,接着直接使用多维数组中的mean()方法即可得到多维数组中所有数据的平均值。
除了求平均值的mean()方法,numpy 中还有很多通用方法,比如求最大值的max()方法、求最小值的min()方法、求和的sum()方法等
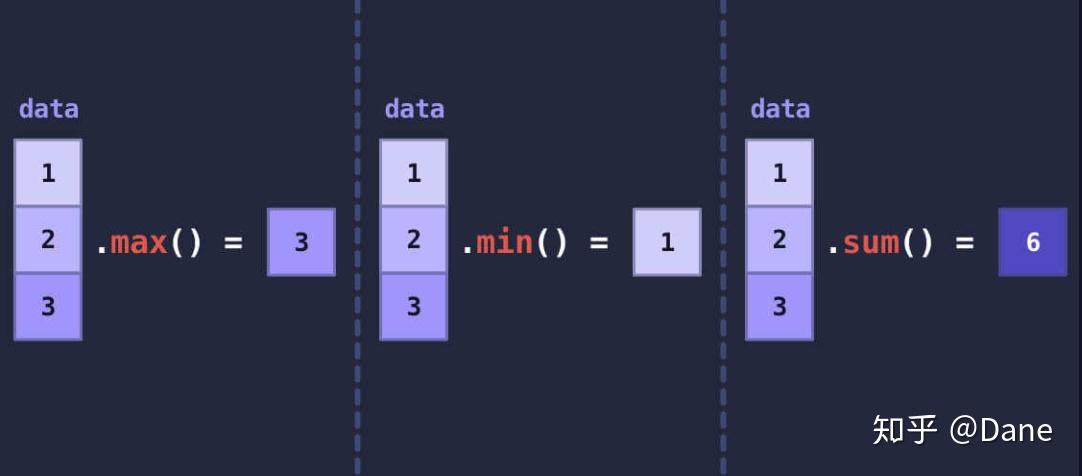

回到前面例子,代码的运行结果如下:


这 3 个球员的平均得分竟然都是 10 分,那该如何选择呢?
你肯定也想到了看看哪位球员发挥更稳定,选发挥最稳定的球员上场比赛。
没错,想法是对的。在分析哪位球员发挥更稳定之前,我们先来了解几个描述统计学中的概念。
在描述统计学中有很多数据指标,主要分为两类:集中趋势 和 离中趋势。
集中趋势
集中趋势所反映的是一组数据所具有的共同趋势,它代表了一组数据的总体水平。其常用指标有 平均数、中位数 和 众数。
求平均数很简单,就是把所有数据加起来,再除以这些数据的个数。但平均数对异常数值并不敏感,容易得到误导性的结论。比如,你和马云的身价求平均,你也是亿万富翁。
所以不能只看平均数,还有中位数和众数。中位数是指数据排序后处于中间的那个数。众数是指一组数据中出现次数最多的数。
离中趋势
离中趋势是指一组数据中各数据值以不同程度的距离偏离其中心(平均数)的趋势。其常用指标有 极差、方差 和标准差。
极差是一组数据的最大值减去最小值得到的,反应了数据变动的最大范围。
方差的计算方式是:将一组数据中的每个数减去这组数据的平均数,然后将得到的结果进行平方求和,最后再除以数据的个数。
而方差的平方根则是标准差。因为方差是对数据进行平方得到的,所以量纲(单位)和原数据不一致。对方差进行开根号后得到的标准差量纲和原数据一致,使用起来更方便。
方差和标准差都能反映数据的离散程度,也就是数据的波动程度。方差和标准差的值越小,说明数据越稳定。
除了众数则需要我们自己动手写代码计算,numpy 中没有直接计算的方法之外,其他的指标在 numpy 中都有对应的方法进行计算,对应的方法如下图所示:


这些方法有两种使用方式,一种是直接在多维数组上调用,如data.std();另一种是在 numpy 上调用并传入数据,如:np.std(data)。
需要注意的是,求中位数的median()方法只有 numpy 上有,只能使用np.median(data)来求中位数。
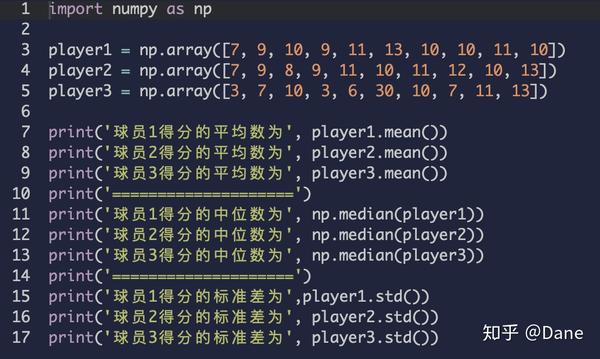

用 numpy 进行平均数、中位数和标准差的计算是不是很简单?
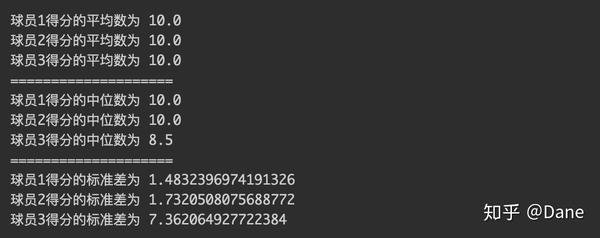

从中我们可以看出,虽然平均数都一样,但球员 3 得分的标准差很大,说明它发挥很不稳定。如果根据三位球员的得分画出一张折线图的话,你就能更直观地看出球员 3 发挥是非常不稳定的。
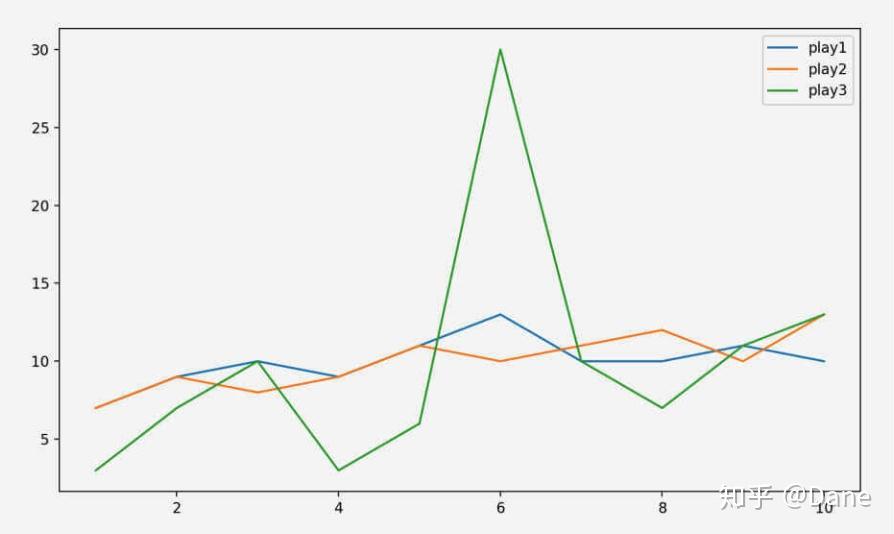

因此,从这些数据中我们可以得出结论:应该选球员 1 进入首发阵容。虽然他平均得分和其他两人一样,但发挥更加的稳定(标准差小)。
当然,有的球员虽然发挥不稳定,但发挥好的时候能力挽狂澜,得很多分;有的球员虽然发挥稳定,却平平无奇不够出彩。
这时就需要具体情况具体分析了,如果你的对手不是很强,那么可以选择发挥稳定的,稳稳地赢下比赛。如果你的对手十分强劲,原本很难赢,那么就可以选择发挥上限高的,说不定就创造了奇迹。
今天,认识了 numpy 中的多维数组(ndarray),并学习了多维数组中最简单的一维数组的基本运算和通用方法。多维数组和列表有很多相似的地方,但它比列表更加的简洁和高效。