【博客存档】机器学习模型评估

前言
当数据好了之后,你所需的只是调下开源包,然后一个模型就出来了,但是,好与不好?谁来界定?
这篇文章,主要针对模型的评估,系统介绍下各种不同的模型的各种评测标准,主要参考Alice Zhang的这篇文章 http://www.oreilly.com/data/free/evaluating-machine-learning-models.csp。
1-基础理解
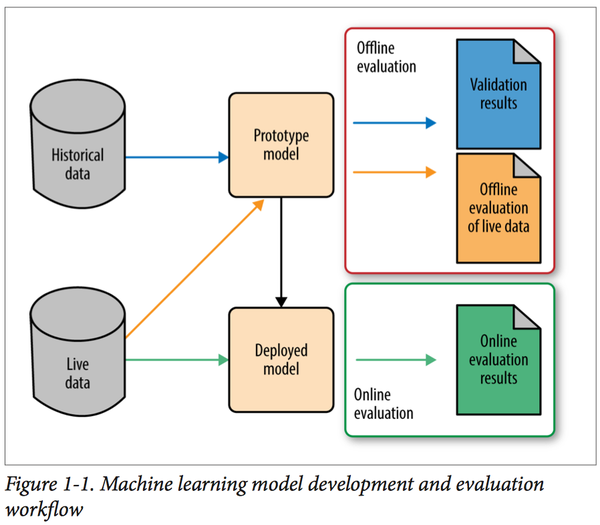

Figure1-1是一个比较合理的产生机器学习模型的workflow,首先,我们拿到Historical data 然后应用到我们选择的model,然后对数据进行离线评测,离线评测一般我们会从Historical data中,通过一些策略选择出一些数据作为Validation,用来离线评测我们的模型,进行model selection和model params selection;也会引入一些live data来离线评价模型,待选择出合理的model和对应的params后,会对线上数据来一些相关的线上测试,例如本人所在公司会按流量对新旧model来进行A/B testing,利用最终的kpi指标来作为model的评判标准
2-模型评估标准
ML中,有多重不同考量的model,不同的目标有不同的评估标准,本节主要介绍Classification Metrics、Regression Metrics、Ranking Metrics
2.1-Classification Metrics
Accuracy
分类Accuracy就是指在分类方法中,被正确分类的样本数据占所有样本数量的比例。
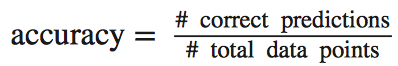
Confusion Matrix
Accuracy的计算十分简便,但是类别之间是等价的,很多时候,由于判断为某类的代价不一致,我们不能简单地利用Accuracy来说明某个分类器的好坏。比如一个医生将患病病人评价为没有患病的情况比将未患病用户判定为患病用户的代价要大得多,后者可以通过其他检测来继续验证,而前者则很难;另外当本身训练数据中各样本数量分布极度不均衡的时候,比如#0/#1=9:1,即使是一个分类器将所有样本全部判断为0时,这个分类的accuracy也达到了90%,很显然这里是有问题的。
假定某样本有100个正样本与200个负样本,confusion table如下:


从这张图表中,我们可以很明显的看出在正分类中,我们的分类器有较低的准确率:(80/(20+80)=80%),负分类中准确率为(195/(195+5)=97.5%),如果仅仅考虑全局的accuracy,(80+195)/(100+200)=91.7%,丢失了很多信息。
Per-Class Accuracy
在上面例子中,对每类的accuracy做一个平均:(80%+97.5%)/2=88.75%,和之前的准确率相差较大,尤其是在分布极度不均的正负样本数量时,9+1-判断为10+,accuracy为90%,(100%+0)/2=50%
Log-Loss
在Logisitic Regression分类器中,最终的分类是指定阈值,然后对predict的值来进行判断进行分类,假定指定阈值0.5,model计算得到属于class 1的概率为0.51,这里有一个错误,但是这里有余概率与分类阈值相差很少,Log-Loss就是一个将此类因素考虑的标准:


pi是属于ith class的概率,yi是第ith的真实label,如果数据功底较强的人可能一眼就可以看出,这里其实就是y和p分布的Cross-Entropy,即真实label与预测的y的分布之间的差异。最小化Log-Loss即为最大化分类器的性能。
AUC
AUC即Area Under the Curve,这里的Curve就是ROC曲线,ROC的横坐标为Flase positive rate,纵坐标为Ture Positive Rate,用分类器的FP和TP来衡量分类器的性能好坏。而这里ROC是一个曲线而非一个值,AUC就是将该ROC用一个数值表示,这个数值就是曲线之下的面积。
2.2-Ranking Metrics
Ranking Metrics和前面的分类的merics,有很多相似的地方,例如,用户给定一个query,然后搜索引擎会反馈一个item list, 这个item list会按照与用户query的相关性来进行排序,其本质就是一个0/1的二元分类器,其中score是分类为1的概率,以此为标准来进行相关性的判定。当然Ranking Metrics很多时候也使用Regression的Metrics,例如在个性化推荐系统中,会通过各种数据的feature来进行一个score的计算,并以此为标准对推荐结果进行排序。
这里,我们首先介绍下Precision-Recall,也就是在分类中经常使用的来作为Ranking Metrics
Precision Recall
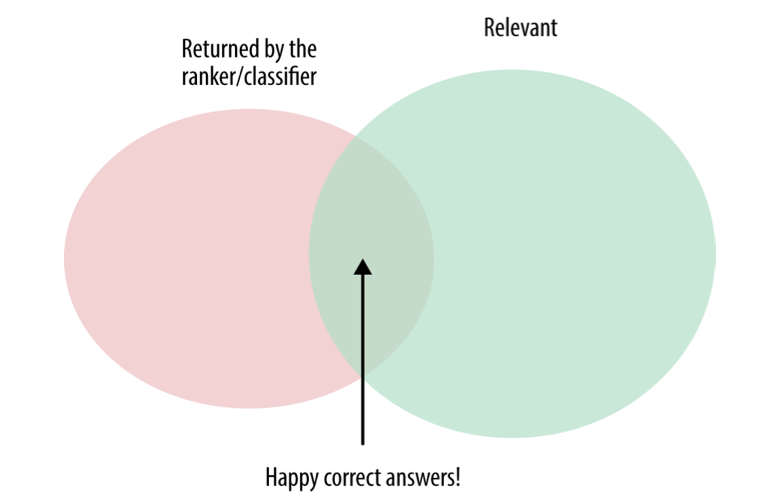



通常,我们在ranking中只对top K来进行计算,就是所谓的precision@k,recall@k,precision和recall之间的关系有点类似于True Postive 和False Postive之间的关系,单独谈其中一样是没有意义的,通常我们使用F1 score来表明其好坏:

NDCG
NDCG是另一种很有效地排序标准,这里不对其做详细概念说明,只举一个例子就明白了,如想详细了解,请阅读 https://en.wikipedia.org/wiki/Discounted_cumulative_gain
假定某一个排序方法,给出的结果为D1,D2,D3,D4,D5,D6,而用户的相关得分(比如通过用户对其点击率来计算)为3,2,3,0,1,2。
则这个搜索的累积的熵为:
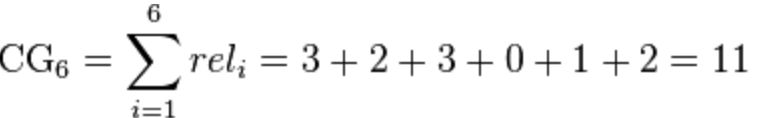

明显可知,CG对排序间item的相对位置不敏感,改变item彼此间的位置不影响CG的值,这是不合理的,这里我们添加一个Discounted信息:
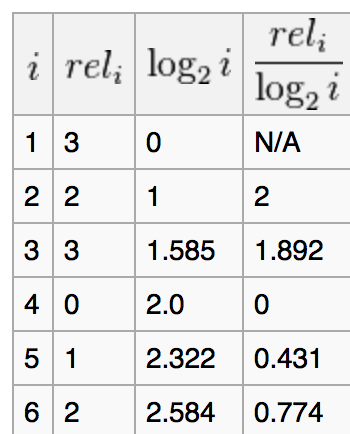
这个ranking的DCG计算如下:
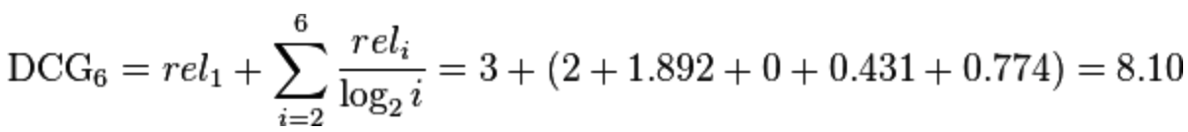

同理,我们做一个最佳的排序的计算,这里最佳的排序是按照用户相关得分的排序:
3,3,2,2,1,0
此时,最佳的DCG = 8.69
最终的Normalize DCG=8.10/8.69=0.932
2.3-Regression Metrics
在回归任务中,我们一般需要去预测数值型的得分,例如我们会预测未来一段时间股票的价格,另外个性化系统预测用户对某个item的得分,类似的这些任务我们都会用到回归方法。
RMSE
在回归任务中,最普通的评估标准是RMSE(root-mean-square error):
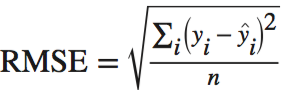
Quantiles of Errors
RMSE有个比较严重的问题,它对large outliers比较敏感,通常一个比较大的离群值会很大地影响最终的RMSE值。Quantiles在某一方面来说,相对于RMSE来说鲁棒性比较高。
Median Absolute Percentage一般能够有效地减少离群值的影响:

当然,我们也可以使用第>90%的数据来找到数据当中的worst case,或者用<0.1来表示数据当中的best case。
2.4-Cautions
Training Metrics 和Evaluation Metrics的差异
很多时候,Evaluation Metrics 和Training Metrics可以通用,我们可以直接选定Evaluation Metrics为目标函数来对其优化,例如RMSE,但是也有很多Evaluation Metrics 不能直接作为目标函数来优化。
Skewed Datasets:Imbalanced classes,outliers, and Rare Data

如果在datasets中,正负样本数相差很大,比如99/1,这样我们的分类器很容易全1,来达到accuracy达到99%,ROC也很好看,但此时其实算法的泛化能力很差,应该是无效的。
3-线下评估机制
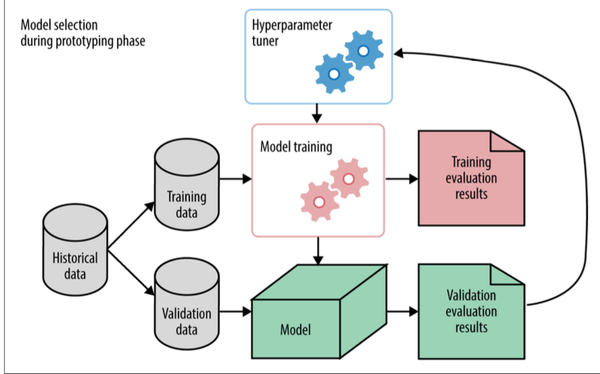
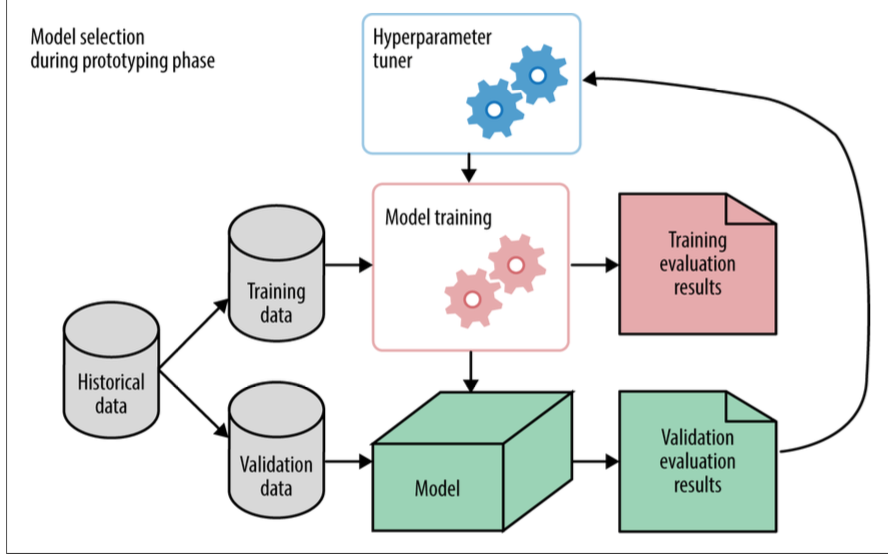
一般,我们将历史数据按某种策略分为训练数据和验证数据,以此我们做Model Training,根据相关评估标准来做Model Selection,选定好model方法之后,利用Validation data去做Hyperparameter tuner,选择出在验证集数据中性能最好的Hyperparameter sets。
很多时候,获取一个有效地历史训练数据集代价很大,我们通常只能获取到相对于真实数据很小的一部分数据,为了保证model的泛化能力,我们通常会采用很多其他的方法来充分验证,例如Hold-Out Validation,Cross-Validation,Bootstrap and Jackknife,这三种基本思想都相同,其中Hold-Out实现最简单,只是简单地将整个训练集分为训练集和验证集,然后用验证集的数据对训练集生成的model验证model有效性,Cross-Validation是将整个训练数据集划分为k-fold,多次取其中某一个fold做验证数据集,相对于Hold-Out Validation来说,相当于多次操作;前面两种可能大部分人都听说过,而Bootstrap很少有人了解,相对于Cross-Validation,其实质我们可以理解为,每次取K-fold里面的某部分做验证集,这其实是一种不放回的采样,而Bootstrap则恰好相反,它实质是一种由放回的采样原理:每次取其中某些数据做验证数据,然后放回重新选取,为什么要选择放回呢?统计学家们认为训练数据本身就有一种潜在的分布信息,我们称为”经验分布”,每次随机选取,然后不放回能够保证每次的经验分布都为原始的训练数据本身的分布信息,那么如此一来,bootstrap set中有很多数据是重复的(即为我们的经验分布),有个文档 https://lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/cv_boot.pdf http://www.americanscientist.org/issues/pub/2010/3/the-bootstrap/1里面有详细的说明。如果想试试具体效果,可以去sklearn里面尝试下: http://scikit-learn.org/stable/modules/grid_search.html#out-of-bag-estimates
4-Hyperparameter Tuning
首先,明白下Hyperparameter是个啥,和模型参数有啥区别
4.1-Model Parameter vs Hyperparameter
这里举个例子:我们有一个线性回归的模型来表示features和target之间关系:
前言
当数据好了之后,你所需的只是调下开源包,然后一个模型就出来了,但是,好与不好?谁来界定?
这篇文章,主要针对模型的评估,系统介绍下各种不同的模型的各种评测标准,主要参考Alice Zhang的这篇文章 http://www.oreilly.com/data/free/evaluating-machine-learning-models.csp。
1-基础理解
Figure1-1是一个比较合理的产生机器学习模型的workflow,首先,我们拿到Historical data 然后应用到我们选择的model,然后对数据进行离线评测,离线评测一般我们会从Historical data中,通过一些策略选择出一些数据作为Validation,用来离线评测我们的模型,进行model selection和model params selection;也会引入一些live data来离线评价模型,待选择出合理的model和对应的params后,会对线上数据来一些相关的线上测试,例如本人所在公司会按流量对新旧model来进行A/B testing,利用最终的kpi指标来作为model的评判标准
2-模型评估标准
ML中,有多重不同考量的model,不同的目标有不同的评估标准,本节主要介绍Classification Metrics、Regression Metrics、Ranking Metrics
2.1-Classification Metrics
Accuracy
分类Accuracy就是指在分类方法中,被正确分类的样本数据占所有样本数量的比例。
Confusion Matrix
Accuracy的计算十分简便,但是类别之间是等价的,很多时候,由于判断为某类的代价不一致,我们不能简单地利用Accuracy来说明某个分类器的好坏。比如一个医生将患病病人评价为没有患病的情况比将未患病用户判定为患病用户的代价要大得多,后者可以通过其他检测来继续验证,而前者则很难;另外当本身训练数据中各样本数量分布极度不均衡的时候,比如#0/#1=9:1,即使是一个分类器将所有样本全部判断为0时,这个分类的accuracy也达到了90%,很显然这里是有问题的。
假定某样本有100个正样本与200个负样本,confusion table如下:
从这张图表中,我们可以很明显的看出在正分类中,我们的分类器有较低的准确率:(80/(20+80)=80%),负分类中准确率为(195/(195+5)=97.5%),如果仅仅考虑全局的accuracy,(80+195)/(100+200)=91.7%,丢失了很多信息。
Per-Class Accuracy
在上面例子中,对每类的accuracy做一个平均:(80%+97.5%)/2=88.75%,和之前的准确率相差较大,尤其是在分布极度不均的正负样本数量时,9+1-判断为10+,accuracy为90%,(100%+0)/2=50%
Log-Loss
在Logisitic Regression分类器中,最终的分类是指定阈值,然后对predict的值来进行判断进行分类,假定指定阈值0.5,model计算得到属于class 1的概率为0.51,这里有一个错误,但是这里有余概率与分类阈值相差很少,Log-Loss就是一个将此类因素考虑的标准:
pi是属于ith class的概率,yi是第ith的真实label,如果数据功底较强的人可能一眼就可以看出,这里其实就是y和p分布的Cross-Entropy,即真实label与预测的y的分布之间的差异。最小化Log-Loss即为最大化分类器的性能。
AUC
AUC即Area Under the Curve,这里的Curve就是ROC曲线,ROC的横坐标为Flase positive rate,纵坐标为Ture Positive Rate,用分类器的FP和TP来衡量分类器的性能好坏。而这里ROC是一个曲线而非一个值,AUC就是将该ROC用一个数值表示,这个数值就是曲线之下的面积。
2.2-Ranking Metrics
Ranking Metrics和前面的分类的merics,有很多相似的地方,例如,用户给定一个query,然后搜索引擎会反馈一个item list, 这个item list会按照与用户query的相关性来进行排序,其本质就是一个0/1的二元分类器,其中score是分类为1的概率,以此为标准来进行相关性的判定。当然Ranking Metrics很多时候也使用Regression的Metrics,例如在个性化推荐系统中,会通过各种数据的feature来进行一个score的计算,并以此为标准对推荐结果进行排序。
这里,我们首先介绍下Precision-Recall,也就是在分类中经常使用的来作为Ranking Metrics
Precision Recall
通常,我们在ranking中只对top K来进行计算,就是所谓的precision@k,recall@k,precision和recall之间的关系有点类似于True Postive 和False Postive之间的关系,单独谈其中一样是没有意义的,通常我们使用F1 score来表明其好坏:
NDCG
NDCG是另一种很有效地排序标准,这里不对其做详细概念说明,只举一个例子就明白了,如想详细了解,请阅读 https://en.wikipedia.org/wiki/Discounted_cumulative_gain
假定某一个排序方法,给出的结果为D1,D2,D3,D4,D5,D6,而用户的相关得分(比如通过用户对其点击率来计算)为3,2,3,0,1,2。
则这个搜索的累积的熵为:
明显可知,CG对排序间item的相对位置不敏感,改变item彼此间的位置不影响CG的值,这是不合理的,这里我们添加一个Discounted信息:
这个ranking的DCG计算如下:
同理,我们做一个最佳的排序的计算,这里最佳的排序是按照用户相关得分的排序:
3,3,2,2,1,0
此时,最佳的DCG = 8.69
最终的Normalize DCG=8.10/8.69=0.932
2.3-Regression Metrics
在回归任务中,我们一般需要去预测数值型的得分,例如我们会预测未来一段时间股票的价格,另外个性化系统预测用户对某个item的得分,类似的这些任务我们都会用到回归方法。
RMSE
在回归任务中,最普通的评估标准是RMSE(root-mean-square error):
Quantiles of Errors
RMSE有个比较严重的问题,它对large outliers比较敏感,通常一个比较大的离群值会很大地影响最终的RMSE值。Quantiles在某一方面来说,相对于RMSE来说鲁棒性比较高。
Median Absolute Percentage一般能够有效地减少离群值的影响:
当然,我们也可以使用第>90%的数据来找到数据当中的worst case,或者用<0.1来表示数据当中的best case。
2.4-Cautions
Training Metrics 和Evaluation Metrics的差异
很多时候,Evaluation Metrics 和Training Metrics可以通用,我们可以直接选定Evaluation Metrics为目标函数来对其优化,例如RMSE,但是也有很多Evaluation Metrics 不能直接作为目标函数来优化。
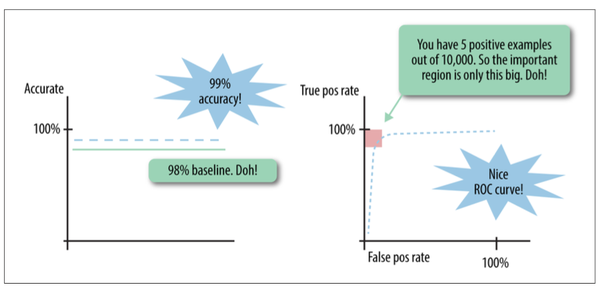
Skewed Datasets:Imbalanced classes,outliers, and Rare Data
如果在datasets中,正负样本数相差很大,比如99/1,这样我们的分类器很容易全1,来达到accuracy达到99%,ROC也很好看,但此时其实算法的泛化能力很差,应该是无效的。
3-线下评估机制
一般,我们将历史数据按某种策略分为训练数据和验证数据,以此我们做Model Training,根据相关评估标准来做Model Selection,选定好model方法之后,利用Validation data去做Hyperparameter tuner,选择出在验证集数据中性能最好的Hyperparameter sets。
很多时候,获取一个有效地历史训练数据集代价很大,我们通常只能获取到相对于真实数据很小的一部分数据,为了保证model的泛化能力,我们通常会采用很多其他的方法来充分验证,例如Hold-Out Validation,Cross-Validation,Bootstrap and Jackknife,这三种基本思想都相同,其中Hold-Out实现最简单,只是简单地将整个训练集分为训练集和验证集,然后用验证集的数据对训练集生成的model验证model有效性,Cross-Validation是将整个训练数据集划分为k-fold,多次取其中某一个fold做验证数据集,相对于Hold-Out Validation来说,相当于多次操作;前面两种可能大部分人都听说过,而Bootstrap很少有人了解,相对于Cross-Validation,其实质我们可以理解为,每次取K-fold里面的某部分做验证集,这其实是一种不放回的采样,而Bootstrap则恰好相反,它实质是一种由放回的采样原理:每次取其中某些数据做验证数据,然后放回重新选取,为什么要选择放回呢?统计学家们认为训练数据本身就有一种潜在的分布信息,我们称为”经验分布”,每次随机选取,然后不放回能够保证每次的经验分布都为原始的训练数据本身的分布信息,那么如此一来,bootstrap set中有很多数据是重复的(即为我们的经验分布),有个文档 https://lagunita.stanford.edu/c4x/HumanitiesScience/StatLearning/asset/cv_boot.pdf http://www.americanscientist.org/issues/pub/2010/3/the-bootstrap/1里面有详细的说明。如果想试试具体效果,可以去sklearn里面尝试下: http://scikit-learn.org/stable/modules/grid_search.html#out-of-bag-estimates
4-Hyperparameter Tuning
首先,明白下Hyperparameter是个啥,和模型参数有啥区别
4.1-Model Parameter vs Hyperparameter
这里举个例子:我们有一个线性回归的模型来表示features和target之间关系:
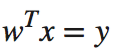
x是特征向量,y为对应的score值,而w则是我们通过训练得到的参数模型,我们所说的训练model其实就是最是采取优化策略来得到w产生最fit数据的预测数据。这里的w使我们常说的Model Parameter而Hyperparameter通常在原始的linear regression中不需要,但是在lasso、ridge 这些里面会增加一些正则化的考虑来惩罚复杂度较高的模型,而这里的惩罚系数就是我们这里提到的Hyperparameter。
在很多复杂的模型,例如Dt,SVM,GBDT中有很多复杂的Hyperparameter对最终的预测有很重要的影响。
4.2-Hyperparameter Tuning Mechanism

如何去选择Hyperparameter,我们提供四种方法:Grid Search,Random Search,Smart Hyperparameter Tuning,Nested Cross-Validation
- Grid Search就是把所有Hyperparameter做组合,然后贪婪去训练模型,选择效果最好的模型和对应的Hyperparameter
- Random Search就是采用随机的策略,和grid search的关系有点类似于随机梯度下降和批梯度下降的关系
- Smart Hyperparameter Tuning:计算下次参数选择,来更快速地收敛到最优参数
x是特征向量,y为对应的score值,而w则是我们通过训练得到的参数模型,我们所说的训练model其实就是最是采取优化策略来得到w产生最fit数据的预测数据。这里的w使我们常说的Model Parameter而Hyperparameter通常在原始的linear regression中不需要,但是在lasso、ridge 这些里面会增加一些正则化的考虑来惩罚复杂度较高的模型,而这里的惩罚系数就是我们这里提到的Hyperparameter。
在很多复杂的模型,例如Dt,SVM,GBDT中有很多复杂的Hyperparameter对最终的预测有很重要的影响。
4.2-Hyperparameter Tuning Mechanism
如何去选择Hyperparameter,我们提供四种方法:Grid Search,Random Search,Smart Hyperparameter Tuning,Nested Cross-Validation
- Grid Search就是把所有Hyperparameter做组合,然后贪婪去训练模型,选择效果最好的模型和对应的Hyperparameter
- Random Search就是采用随机的策略,和grid search的关系有点类似于随机梯度下降和批梯度下降的关系
- Smart Hyperparameter Tuning:计算下次参数选择,来更快速地收敛到最优参数
文章被以下专栏收录
