
python抓取信息学奥赛一本通OJ题库

〇、前言
一直想自己搭建一个OJ平台,以后或许可以给学校用,正在依次学习需要的知识。OJ平台需要题库,打算先从已有的OJ平台上抓下来,方便实验。
当然,能拿到的只有题目,测试点数据目前看来还是需要自己造咯。
学习python和爬虫有一段时间了,于是乎打算用python写个小爬虫抓题库。
OJ平台选择了大学课程上老师指定的 信息学奥赛一本通(C++)版在线测评网站(其实还有一个原因是他的网站设计相对简单,数据好拿一点)。
一、踩点
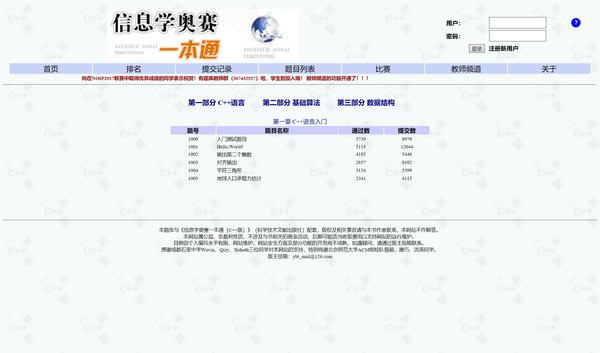

网站非常简洁(lou),不登录也可以看到题目。
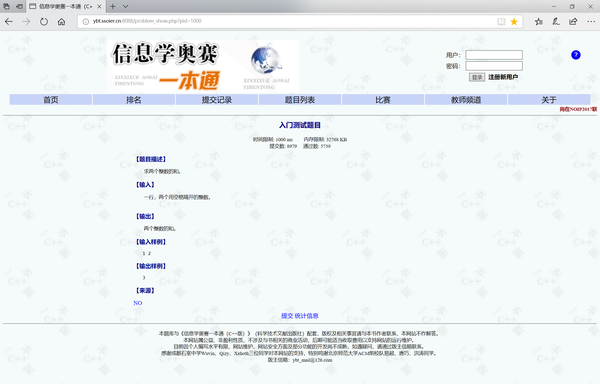

url里传递数据“pid=”后面的数字就是题目的编号,从1000开始。
我们需要的数据是一道题目的“编号”、“题目名称”、“题目描述”、“输入”、“输出”、“输入样例”、“输出样例”、“提示”(部分题目中有这一项)。这个OJ中“来源”写的都是“NO”,对我们意义不大,就不抓他了。
这里想到需要注意的部分:
1.可能会有图片。
2.部分题目有“提示”这一块内容。
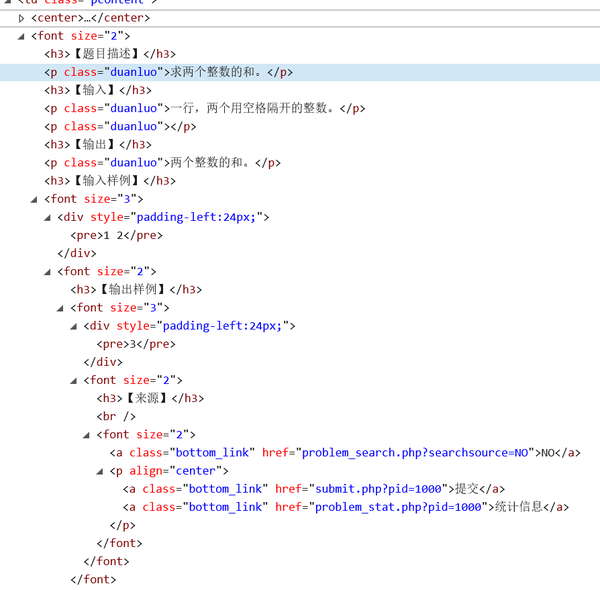
F12查看我们需要的数据的部分,写的不是很整齐,包含关系有点混乱。

二、抓取数据
这里用requests.get抓取网站。
复制题目的url,先随便写个合理的pid,到时候外层套个循环就能抓所有题目了。按照规范构造个headers模拟浏览器。
urls = 'http://ybt.ssoier.cn:8088/problem_show.php?pid=%d'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
req = requests.get(url=urls % '1000', headers=headers).text.encode('ISO-8859-1', 'ignore').decode('utf-8', 'ignore')三、数据整理
我用的是lxml库处理抓下来的网页数据。
from lxml import etree
reqhtml = etree.HTML(req)用xpath找我们想要的部分
例如找题目名称
res = reqhtml.xpath('//center/table/td/center/h3')
tmmc = res[0].text但是后面的数据有点难下手,小标题包含在<h3>标签中,内容文字在<p>标签里,且他俩并列而非包含,但是像pid=1000的例子中看到的那样,后面输入样例的数据、输出样例的标题和数据跑到下一层包含中去了。
那么我们只能暂且不从逻辑关系上分析,把他们可能存在的标签位置全部抓取下来,再根据小标题文字内容进行整理。
比如,“题目描述”之后的内容都为题目描述的文字部分,直到出现“输入”。
代码如下
res = reqhtml.xpath('//p|//h3|//font/div/pre|//font/p|//p/img/@src')
for i in res:
if not hasattr(i, 'text'):
with open('./%s' % str(i), 'wb') as f:
f.write(requests.get('http://ybt.ssoier.cn:8088/%s' % str(i)).content)
if tyb == 1:
tmms += str(i)
elif tyb == 2:
sr += str(i)
elif tyb == 3:
sc += str(i)
elif tyb == 4:
sryl += str(i)
elif tyb == 5:
scyl += str(i)
elif tyb == 6:
ts += str(i)
continue
if(i.text):
if i.text == '【题目描述】':
tyb = 1
elif i.text == '【输入】':
tyb = 2
elif i.text == '【输出】':
tyb = 3
elif i.text == '【输入样例】':
tyb = 4
elif i.text == '【输出样例】':
tyb = 5
elif i.text == '【提示】':
tyb = 6
elif i.text == '【来源】':
break
elif tyb == 1:
tmms += i.text
elif tyb == 2:
sr += i.text
elif tyb == 3:
sc += i.text
elif tyb == 4:
sryl += i.text
elif tyb == 5:
scyl += i.text
elif tyb == 6:
ts += i.text用一个tyb作为标记,指示现在读取的是哪一块内容。
如果读到图片——也就是说内容不存在“text”属性,把图片保存起来,在文本位置加一段“图片+图片序号”作为标记,方便后期处理,把图片再加上去。
如果是文字的话,就把他加入到相应的字符串之中。
读到“来源”,说明前面的内容都已经处理完了,而我们又不需要记录来源,直接结束掉。
四、效果




五、保存数据
上一步已经成功按照内容类别,把需要的数据记录到各自的字符串中,保存数据就非常方便了,打印输出、保存到数据库都不是难事,我这里先保存在了excel中。
import xlwt
save_file = xlwt.Workbook()
save_sheet = save_file.add_sheet(u'sheet1')
save_sheet.write(pid - 999, 0, pid)
save_sheet.write(pid-999, 1, tmmc)
save_sheet.write(pid - 999, 2, tmms)
save_sheet.write(pid - 999, 3, sr)
save_sheet.write(pid - 999, 4, sc)
save_sheet.write(pid - 999, 5, sryl)
save_sheet.write(pid - 999, 6, scyl)
save_sheet.write(pid - 999, 7, ts)
save_sheet.write(pid - 999, 7, ts)
save_file.save('./信息学奥赛题库.xls')五、完整代码
import requests
from lxml import etree
import xlwt
def bashuoj(save_file):
save_sheet = save_file.add_sheet(u'sheet1')
urls = 'http://ybt.ssoier.cn:8088/problem_show.php?pid=%d'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
for pid in range(1000, 1418):
req = requests.get(url=urls % pid, headers=headers).text.encode('ISO-8859-1', 'ignore').decode('utf-8', 'ignore')
print('开始抓取%d题' % pid)
reqhtml = etree.HTML(req)
res = reqhtml.xpath('//center/table/td/center/h3')
tmmc = res[0].text
tmms = ''
sr = ''
sc = ''
sryl = ''
scyl = ''
ts = ''
tyb = 0
res = reqhtml.xpath('//p|//h3|//font/div/pre|//font/p|//p/img/@src')
for i in res:
if not hasattr(i, 'text'):
with open('./%s' % str(i), 'wb') as f:
f.write(requests.get('http://ybt.ssoier.cn:8088/%s' % str(i)).content)
if tyb == 1:
tmms += str(i)
elif tyb == 2:
sr += str(i)
elif tyb == 3:
sc += str(i)
elif tyb == 4:
sryl += str(i)
elif tyb == 5:
scyl += str(i)
elif tyb == 6:
ts += str(i)
continue
if(i.text):
if i.text == '【题目描述】':
tyb = 1
elif i.text == '【输入】':
tyb = 2
elif i.text == '【输出】':
tyb = 3
elif i.text == '【输入样例】':
tyb = 4
elif i.text == '【输出样例】':
tyb = 5
elif i.text == '【提示】':
tyb = 6
elif i.text == '【来源】':
break
elif tyb == 1:
tmms += i.text
elif tyb == 2:
sr += i.text
elif tyb == 3:
sc += i.text
elif tyb == 4:
sryl += i.text
elif tyb == 5:
scyl += i.text
elif tyb == 6:
ts += i.text
save_sheet.write(pid - 999, 0, pid)
# print('【题目名称】')
# print(tmmc)
save_sheet.write(pid-999, 1, tmmc)
# print('【题目描述】')
# print(tmms)
save_sheet.write(pid - 999, 2, tmms)
# print('【输入】')
# print(sr)
save_sheet.write(pid - 999, 3, sr)
# print('【输出】')
# print(sc)
save_sheet.write(pid - 999, 4, sc)
# print('【输入样例】')
# print(sryl)
save_sheet.write(pid - 999, 5, sryl)
# print('【输出样例】')
# print(scyl)
save_sheet.write(pid - 999, 6, scyl)
# print('【提示】')
# print(ts)
save_sheet.write(pid - 999, 7, ts)
print(pid, '完毕')
if __name__ == '__main__':
save_file = xlwt.Workbook()
bashuoj(save_file)
save_file.save('./信息学奥赛题库.xls')