MYSQL索引介绍、使用

1、什么是索引?
快速检索某1列中,某1特定值的行。使用索引和不使用索引区别?
不使用索引:mysql必须从第一条记录开始读完整表,直到找到,表越大查询时间越多。
使用索引:mysql能快速到达一个位置去搜索数据文件,而不必查看所有数据,节省很多时间。
举例:
例如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。
如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。
如果有了索引,那么会将 Phone 字段,通过一定的方法进行存储,好让查询该字段上的信息时,能够快速找到对应的数据,而不必在遍历2W条数据了。其中MySQL中的索引的存储类型有两种:BTREE、HASH。 也就是用树或者Hash值来存储该字段,更详细的查找逻辑就需要会算法的知识了。我们现在只需要知道索引的作用,功能是什么就行。
2、索引优缺点?
优点:
1、任意字段都可设置索引。
2、查询数据变快。
缺点:
1、创建和维护索引耗费时间,随着数据量增加会增加。
2、索引占空间,因我们都知道数据表数据也有最大上限设置,如由大量索引,索引文件可能比数据文件更快达到上限值。
3、对表数据增删改时,索引需动态维护,降低数据维护速度。
使用原则:
通过上面说的优点和缺点,我们应该可以知道,并不是每个字段都设置索引好,也不是索引越多越好,而是需要自己合理的使用。
1、对经常更新的表避免设置过多索引,对经常查询的字段应设置索引。
2、数据量小最好不设置索引,效果不明显。
3、字段值类型较少,例如性别,男女不同值,不建议设置索引。
3、索引分类?
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引。
1、MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换。(但是innoDB存储引擎支持hash索引是自适应的,innoDB存储引擎会根据表的使用情况自动为表生成hash索引,不能人为干预是否在一张表中生成hash索引。)
2、MEMORY/HEAP存储引擎:支持HASH和BTREE索引。
存储引擎类型和特点:
引擎名称
1、MyISAM
2、InnoDB
优点
1、独立于操作系统,这说明可以轻松地将其从Windows服务器移植到Linux服务器
2、健壮的事务型存储引擎;支持事务/行级锁/外键约束自动灾难恢复/AUTO_INCREMENT
缺陷
1、不支持事务/行级锁/外键约束
应用场景
1、适合管理邮件或Web服务器日志数据
2、需要事务支持,并且有较高的并发读取频率索引四类:
单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引。
单列索引
单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。 这里不要搞混淆了。
1、普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数据更快一点。
2、唯一索引:索引列中的值必须是唯一的,但是允许为空值,
3、主键索引:是一种特殊的唯一索引,不允许有空值。组合索引
一个的索引包含多个列,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀。会在后面的例子细说。全文索引
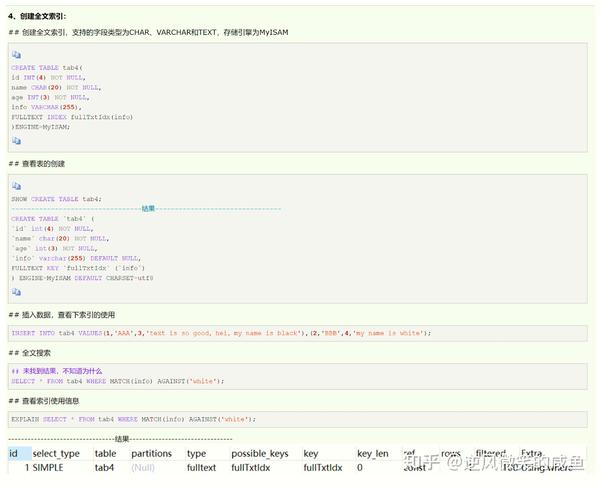
要求只有在MyISAM引擎上才能使用,只能在CHAR、VARCHAR、TEXT类型字段上使用全文索引。就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行,比如有"你是个大煞笔,二货 ..." 通过大煞笔,可能就可以找到该条记录。这里说的是可能,因为全文索引的使用涉及了很多细节。具体文章空间索引
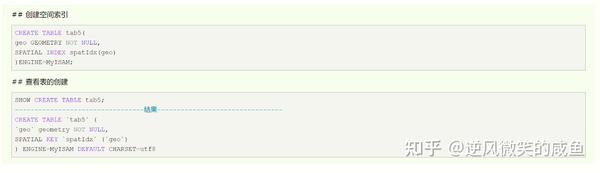
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。
在创建空间索引时,使用SPATIAL关键字。
要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。4、索引使用?
1、在创建表时创建索引
创建普通索引:
# 创建普通索引,创建索引时未指定索引的名,会自动帮我们用字段名当作索引名
CREATE TABLE book(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL,
info VARCHAR(255) NULL,
INDEX(author));
# 查看表的创建
SHOW CREATE TABLE book;
-------------------------------结果----------------------------------
CREATE TABLE `book` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`author` varchar(20) NOT NULL,
`info` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `author` (`author`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
# 用EXPLAIN关键字,来查看索引是否正在被使用,并且输出其使用的索引信息
EXPLAIN SELECT * FROM book WHERE author = 'nana';
虽然表中没数据,但是有EXPLAIN关键字,用来查看索引是否正在被使用,并且输出其使用的索引的信息。
id:为SELECT的识别符。这是SELECT的查询序列号,也就是一条语句中,该select是第几次出现。在上面语句中,select只有一个,所以是1。
select_type:表示使用SELECT的查询类型,SIMPLE表示为简单的SELECT,不适用于UNION或子查询,就是简单的SELECT。也就是说该SELECT查询时会使用索引。其他取值:
PRIMARY:最外面的SELECT,在有子查询时,就会出现两个以上的SELECT。
UNION:union(两张表连接)中的第二个或后面的select语句。
SUBQUERY:在子查询中,第二个SELECT。
table:数据表的名字。按照被读取的先后顺序排列,这里只查询一张表,所以只显示book。
type:指定本数据表和其他数据表之间的关联关系,该表中所有符合检索值的记录都会被取出来和从上一个表中取出来的记录作联合。
ref用于连接程序使用键的最左前缀或者是该键不是 primary key 或 unique索引(换句话说,就是连接程序无法根据键值只取得一条记录)的情况。当根据键值只查询到少数几条匹配的记录时,这就是一个不错的连接类型。(注意,个人这里不是很理解,百度了很多资料,全是大白话,等以后用到了这类信息时,在回过头来补充,这里不懂对后面的影响不大。)可能的取值有 system、const、eq_ref、index和All。
possible_keys:MySQL在搜索数据记录时可以选用的各个索引。目前表里有两个索引一个是主键一个是anthor。因为目前表里没有数据,所以主键索引未被使用。
key:实际选用的索引。
key_len:显示了mysql使用索引的长度(也就是使用的索引个数),当 key 字段的值为 null时,索引的长度就是 null。注意,key_len的值可以告诉你在联合索引中mysql会真正使用了哪些索引。
ref:给出关联关系中另一个数据表中数据列的名字。常量(const),这里使用的是'nana',就是常量。
rows:MySQL在执行这个查询时预计会从这个数据表里读出的数据行的个数。
extra:提供了与关联操作有关的信息,没有则什么都不写。
上面的一大堆东西能看懂多少看多少,我们最主要的是看 possible_keys 和 key 这两个属性,上面显示了key为anthor。说明使用了索引。

创建唯一索引:
## 创建唯一索引
CREATE TABLE tab1(
id INT(5) NOT NULL,
name CHAR(20) NOT NULL,
UNIQUE INDEX uniqId(id)
);
## 查看表的创建
SHOW CREATE TABLE tab1;
---------------------------------结果--------------------------------
CREATE TABLE `tab1` (
`id` int(5) NOT NULL,
`name` char(20) NOT NULL,
UNIQUE KEY `uniqId` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
## 查看索引使用信息
EXPLAIN SELECT * FROM tab1 WHERE id = 1;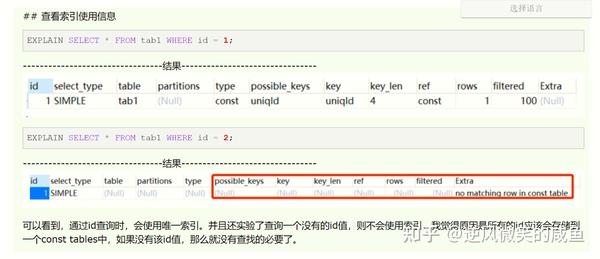
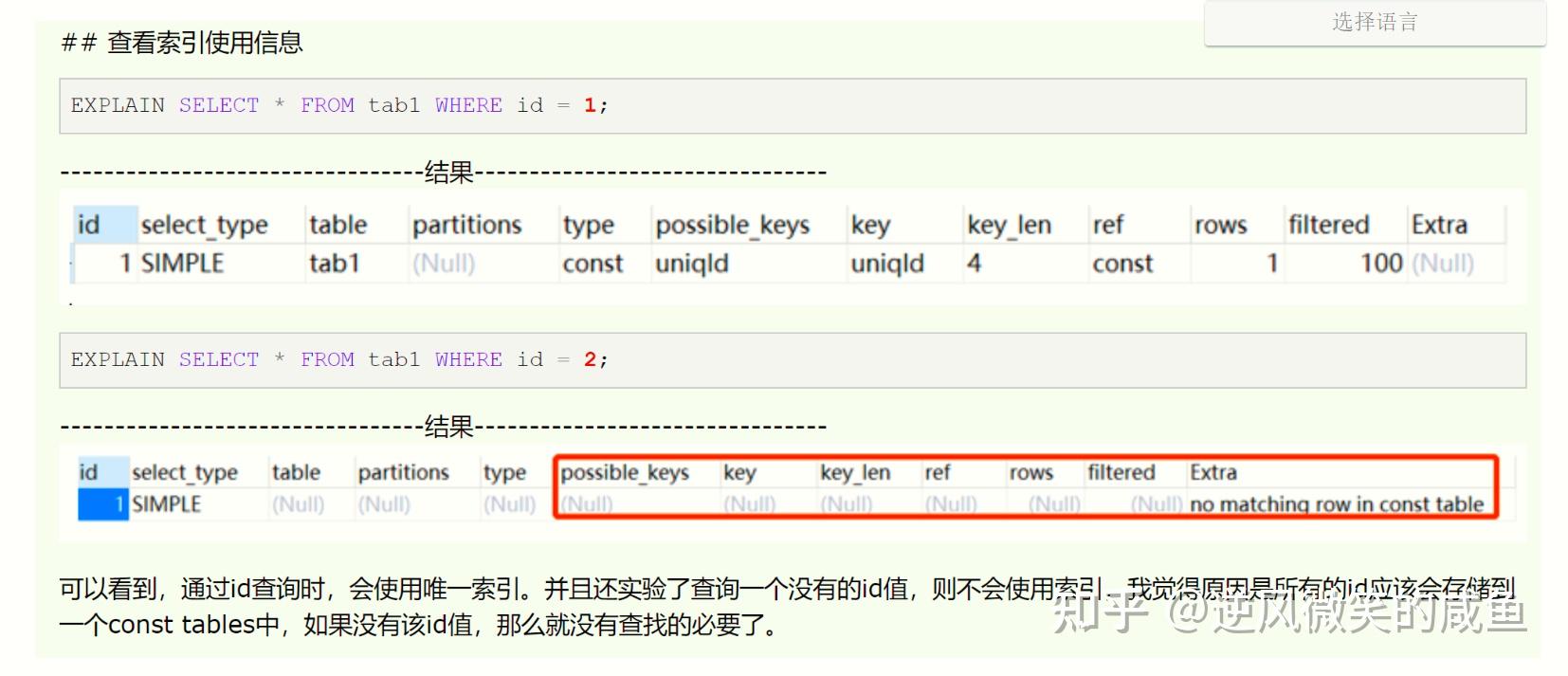
创建主键索引:
## 创建主键索引
CREATE TABLE tab2(
id INT(4) NOT NULL,
name char(20) DEFAULT NULL,
PRIMARY KEY(id));
## 查看表的创建
SHOW CREATE TABLE tab2;
---------------------------------结果--------------------------------
CREATE TABLE `tab2` (
`id` int(4) NOT NULL,
`name` char(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8

创建组合索引:
# 创建组合索引
CREATE TABLE tab3(
id INT(4) NOT NULL,
name CHAR(20) NOT NULL,
age INT(3) NOT NULL,
info VARCHAR(255),
INDEX multiIdx(id,name,age)
);
# 查看表的创建
SHOW CREATE TABLE tab3;
---------------------------------结果--------------------------------
CREATE TABLE `tab3` (
`id` int(4) NOT NULL,
`name` char(20) NOT NULL,
`age` int(3) NOT NULL,
`info` varchar(255) DEFAULT NULL,
KEY `multiIdx` (`id`,`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8最左前缀原则:使用索引(id,name,age)查询数据,判断条件需遵循最左原则,根据id查询匹配行。
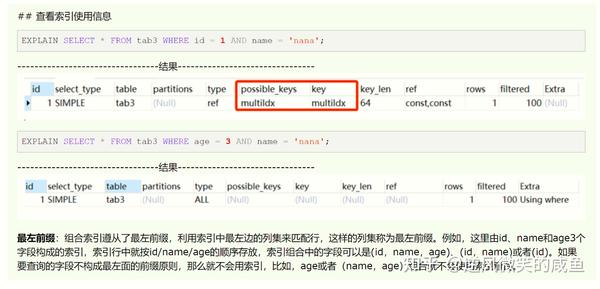
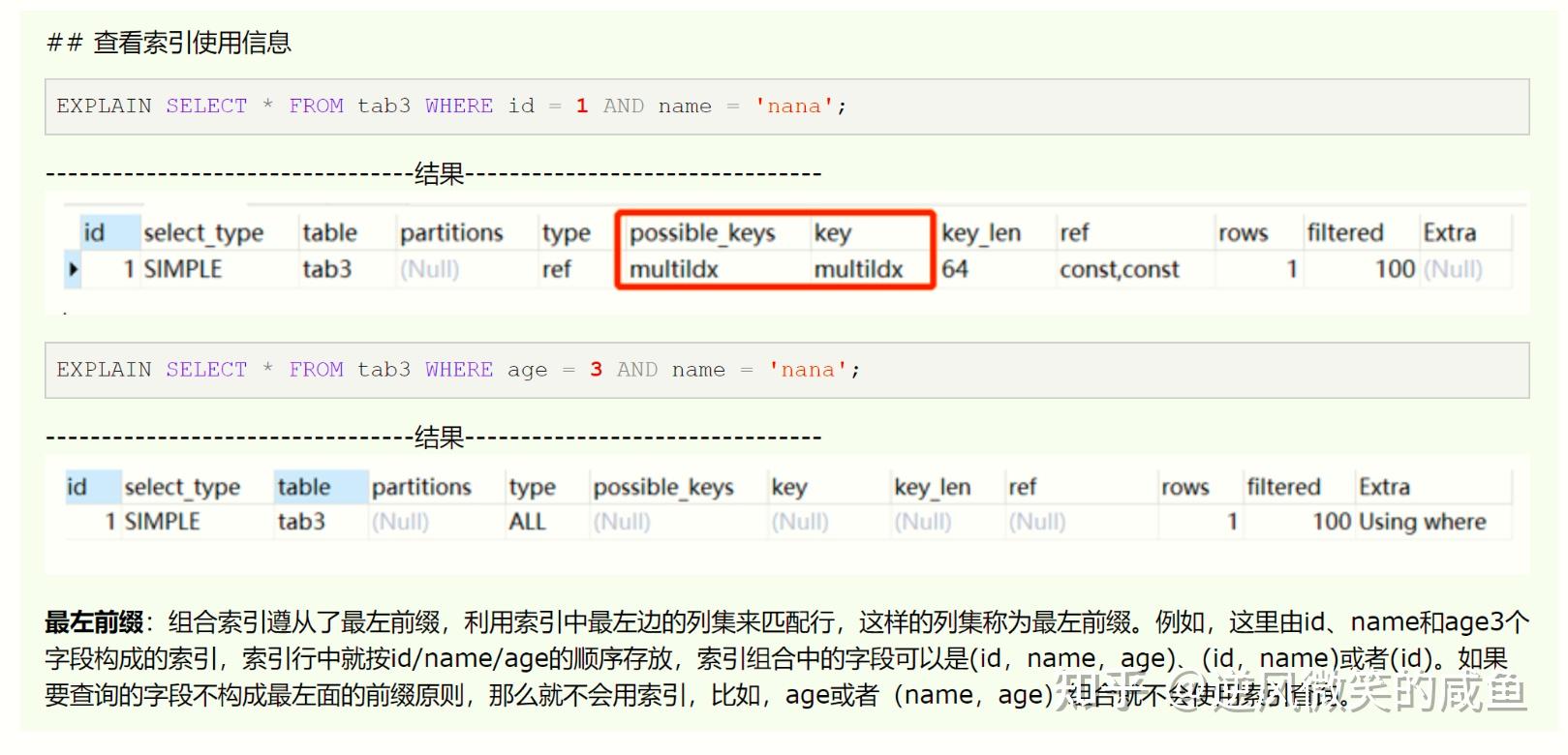
全文索引:引擎为MyISAM

创建空间索引:引擎为MyISAM

2、在创建表后创建索引:
# 查看表的索引
SHOW INDEX FROM book;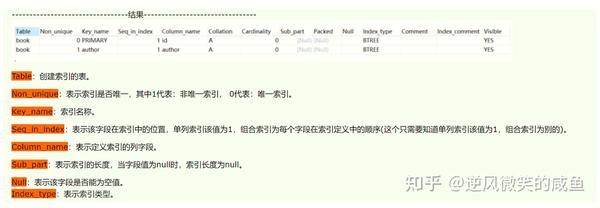

## 为表添加索引
ALTER TABLE book ADD INDEX BkNameIdx(name(30));
## 查看表的索引
SHOW INDEX FROM book;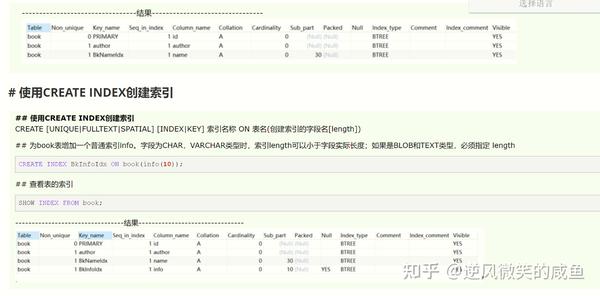

# 使用CREATE INDEX创建索引
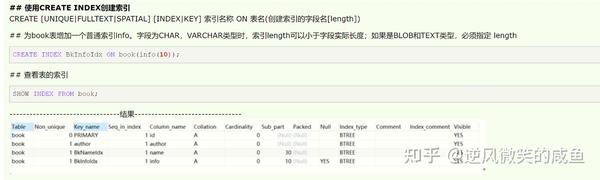

删除索引:
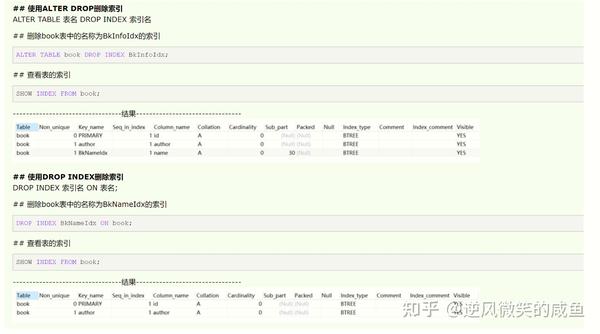

总结:


5、Mysql使用?
设计表或改变表-索引
联合索引
B树:BTREE默认索引,innodb和myisam默认支持,不能更改,hash是自适应的,根据表结构自动生成。
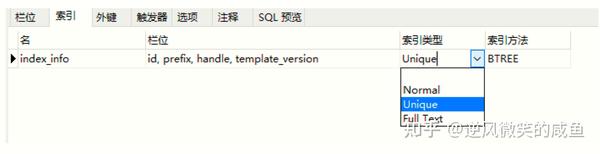

问题1: mysql索引类型normal,unique,full text的区别是什么?
normal:表示普通索引
unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique
full textl: 表示 全文搜索的索引。 FULLTEXT 用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
总结,索引的类别由建立索引的字段内容特性来决定,通常normal最常见。
问题2: 在实际操作过程中,应该选取表中哪些字段作为索引?
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引,有7大原则:
1.选择唯一性索引 2.为经常需要排序、分组和联合操作的字段建立索引 3.为常作为查询条件的字段建立索引 4.限制索引的数目 5.尽量使用数据量少的索引 6.尽量使用前缀来索引 7.删除不再使用或者很少使用的索引
文章被以下专栏收录
