
爬山虎采集实战-站长之家网站排行榜

目标采集网址: 中文网站总排名_网站排行榜
类型:标准列表页+详情页+翻页
数据量:1895页 x 30/页 = 56850条数据
采集工具:爬山虎采集器


首先我们建立一个任务,填写起始网址,因为本次采集结构没有那么复杂,不用生成网址,只要有一个List起始页就可以启动了,点击下一步。
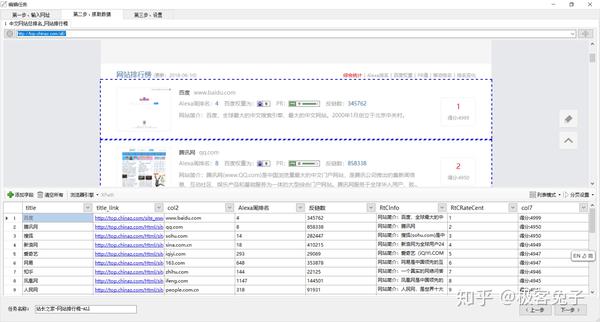

如图,可以看到,爬山虎采集器的分析非常智能化,由于这个是List页,所以爬山虎自动化解析了相应字段和格式。而我们只需要对字段名称修改一下,保证理解和符合命名规范便可。
由于本次是List - Detail的二级采集结构,有些字段在Detail页重复,所以可以在List页或Detail页采集时去掉部分,本案例中在Detail页中去除List页中已经采集的部分字段。


需要注意的是,List页采集时,由于我不想采集重复的Detail数据,并且以后我还想增量更新,所以我这里选择Detail_url字段不得为空也不得重复。
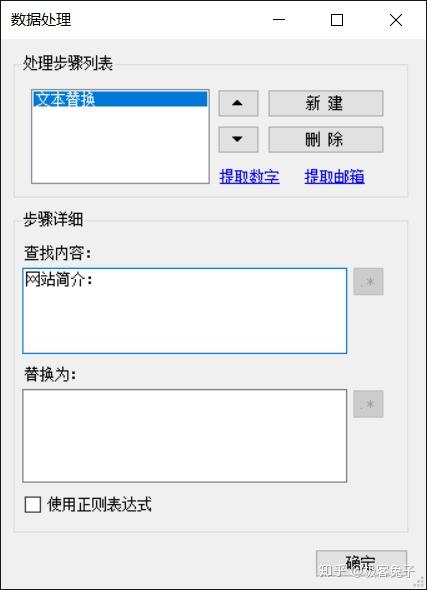

除此之外,对部分字段里不想要的数据,做了简单的文本替换。字段处理这部分确实爬山虎做的体验不够好,希望改进。
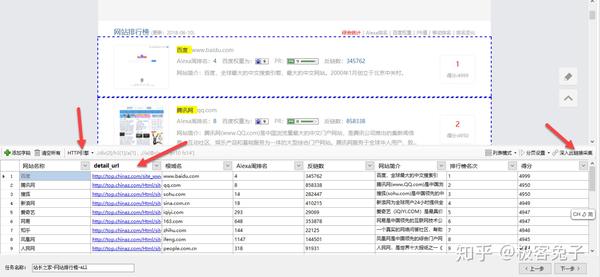

这里需要注意一下,首先是该页面并没有复杂的JS或者Ajax之类影响采集的代码,所以点击HTTP引擎后,仍然可以正常加载和采集。所以这个时候一定要勾选http引擎,可以极大地提高采集速度,类似于真正的爬虫采集机制,而不是浏览器渲染后采集。
之后,我们选择detail_url,然后选择深入此链接采集,这样我们就可以进入了二级页面。但是在此之前,我们还需要对翻页进行设置,爬山虎的翻页比较智能化,如果是普通翻页可以尝试自动识别。


本页面略微有些特殊,虽然显示已经自动识别翻页元素,但是本身应该标亮的却没有显示。安全起见我们选择手动标记,这样可以更安心而且不用最后才校验。
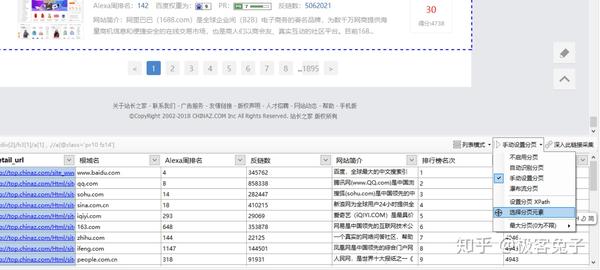

手动选择也很简单,通过点击定位到翻页的元素即可,本页面里就是1895后面的">"部分。
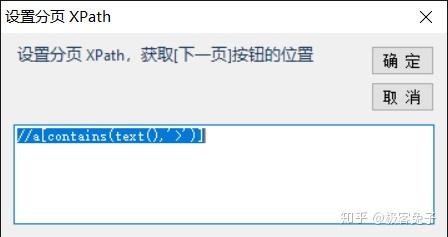

之后可以在手动设置xpath里看到软件自动定位的xpath结果。
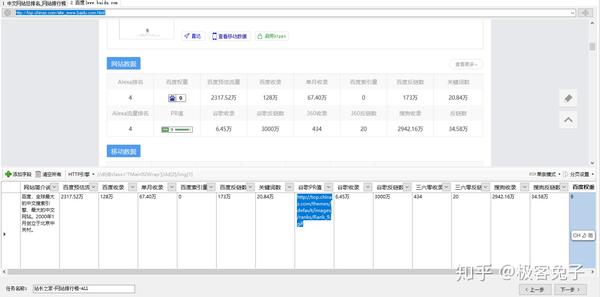

之后就可以进入Detail页面进行采集了,由于页面内容较多,而且Detail是没有自动解析的,只能自已一个一个手动添加字段,然后通过点击就可以采集到数据了,虽然繁琐,但是并不复杂。需要注意的是,采集百度权重和谷歌权重的时候,直接采集到的是图片的URL,但是由于图片的文件名就代表了PR值,所以可以用很简单的数据处理方式解决。
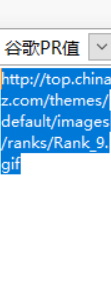
比如谷歌PR值,可以看到text部分只有一个数字,那么我们的正则表达式就用\d匹配便可。其他所有需要处理的数据都类似处理,基本上用文本替换就足够了。记得这个页面也可以选择http引擎处理,加快速度。


到了最后一步了,由于我对采集速度没有太特别的要求,我又不希望被站长之家封杀,所以我宁可采集慢一些,比如线程数2-3,间隔1000-5000毫秒。又或者直接挂代理服务器,速度全部可以加快。UA我习惯性的会选择一下,保证请求头数据的完整性。其他设置基本无需修改便可以启动采集。
由于不用渲染整个页面,所以用http引擎采集的速度是远大于浏览器引擎的,这点和火车头采集器的作用类似,但是更直观的界面和操作可以说让一般人很轻松就可以采集。对我来说,上述采集规则可以10分钟以内写完,已经比较熟练。尤其是理解采集机制的话,基本无需停留和思考便可搞定。
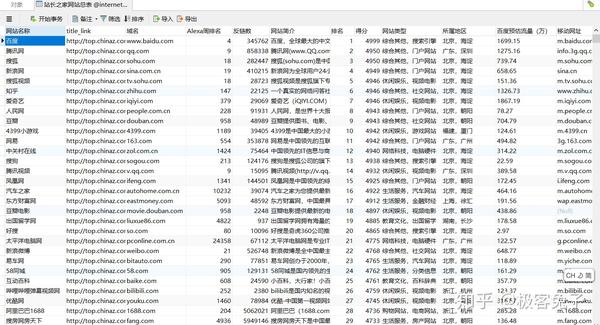

数据导出也很容易,这里放出以前采集并导入到数据库中的表格图片,在Navicat中可以比较直观和容易管理数据库。
以上的采集步骤和数据库管理都是面向非技术人员的,总体来说是比较容易上手的,大家可以尝试一下。
文章被以下专栏收录

极客兔子的小窝
