
SQL应知应会(26):索引使用原则


合理使用索引会极大的加速数据库的性能,不合理的使用索引反而会造成性能降低。
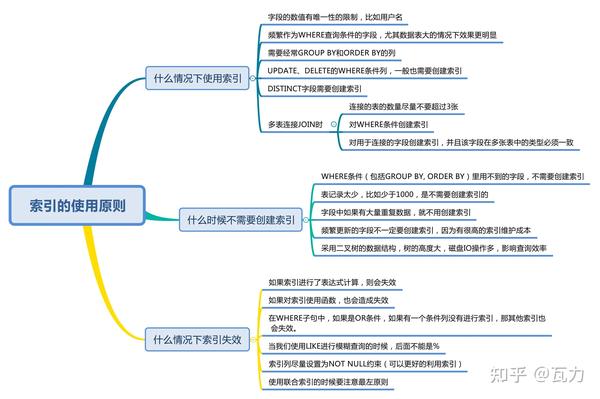
创建索引有哪些规律
1. 字段的数值有唯一性的限制,比如用户名
索引本身可以起到约束的作用,比如唯一索引、主键索引都是可以起到唯一性约束的,因此在我们的数据表中,如果某个字段是唯一性的,就可以直接创建唯一性索引,或者主键索引。
2. 频繁作为 WHERE 查询条件的字段,尤其在数据表大的情况下
在数据量大的情况下,某个字段在 SQL 查询的 WHERE 条件中经常被使用到,那么就需要给这个字段创建索引了。创建普通索引就可以大幅提升数据查询的效率。
我们看一下这个代码:
SELECT comment_id, product_id, comment_text, comment_time, user_id FROM product_comment WHERE user_id = 785110我们在where条件筛选里面用了user_id,表数据量在100万,执行的差异如下:
| 没有对user_id创建索引 | 对user_id创建索引 |
|---|---|
| 0.699s | 0.047s |
可以看到对user_id创建索引后这条sql语句的性能得到了大幅提升。
3. 需要经常 GROUP BY 和 ORDER BY 的列
索引就是让数据按照某种顺序进行存储或检索,因此当我们使用 GROUP BY 对数据进行分组查询,或者使用 ORDER BY 对数据进行排序的时候,就需要对分组或者排序的字段进行索引。
我们执行下列SQL:
SELECT user_id, count(*) as num FROM product_comment group by user_id limit 100| 没有对user_id创建索引 | 对user_id创建索引 |
|---|---|
| 1.666s | 0.042s |
可以看到性能得到大幅提升。
同样,如果是 ORDER BY,也需要对字段创建索引。我们再来看下同时有 GROUP BY 和 ORDER BY 的情况。
SELECT user_id, count(*) as num FROM product_comment group by user_id order by comment_time desc limit 100可以看到上面这条SQL中同时使用了userid和comment_time。我们看一下最终的结果:
| 索引 | 运行时间 |
|---|---|
| 两个单索引:user_id,comment_time | >100s |
| 联合索引:(user_id,commnet_time) | 0.775s |
| 联合索引:(comment_time,user_id) | 1.990s |
可以看到两个联合索引的创建字段顺序不一样也会导致一些性能上的差异。这是因为SELECT语句的执行顺序导致的:首先执行的是GROUP BY,最后执行ORDER BY。
4.UPDATE、DELETE 的 WHERE 条件列,一般也需要创建索引
UPDATE
针对UPDATE,我们用如下SQL:
UPDATE product_comment SET product_id = 10002 WHERE comment_text = '462eed7ac6e791292a79'在where条件筛选中使用了comment_text,我们在这个字段上进行加索引和不加索引的操作,结果对比如下:
| comment_text不加索引 | comment_text加索引 |
|---|---|
| 1.173s | 0.111s |
DELTE
DELETE FROM product_comment WHERE comment_text = '462eed7ac6e791292a79'| comment_text不加索引 | comment_text加索引 |
|---|---|
| 1.027s | 0.032s |
5.DISTINCT 字段需要创建索引
有时候我们需要对某个字段进行去重,使用 DISTINCT,那么对这个字段创建索引,也会提升查询效率。
SELECT DISTINCT(user_id) FROM `product_comment`| user_id不加索引 | user_id加索引 |
|---|---|
| 2.283s | 0.672s |
6. 做多表 JOIN 连接操作时,创建索引需要注意以下的原则
首先,连接表的数量尽量不要超过 3 张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长会非常快,严重影响查询的效率。
其次,对 WHERE 条件创建索引,因为 WHERE 才是对数据条件的过滤。如果在数据量非常大的情况下,没有 WHERE 条件过滤是非常可怕的。
最后,对用于连接的字段创建索引,并且该字段在多张表中的类型必须一致。比如 user_id 在 product_comment 表和 user 表中都为 int(11) 类型,而不能一个为 int 另一个为 varchar 类型。
SELECT comment_id, comment_text, product_comment.user_id, user_name
FROM product_comment
JOIN user ON product_comment.user_id = user.user_id
WHERE comment_text = '462eed7ac6e791292a79'对于该条SQL的执行,我们分别做如下操作:
| 对user_id创建索引 | 对comment_text创建索引 |
|---|---|
| 0.810s | 0.046s |
如果我们不使用 WHERE 条件查询,而是直接采用 JOIN…ON…进行连接的话,即使使用了各种优化手段,总的运行时间也会很长(>100s)。
什么时候不需要创建索引
我之前讲到过索引不是万能的,有一些情况是不需要创建索引的,这里再进行一下说明。
WHERE 条件(包括 GROUP BY、ORDER BY)里用不到的字段不需要创建索引,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的。举个例子:
SELECT comment_id, product_id, comment_time FROM product_comment WHERE user_id = 41251因为我们是按照 user_id 来进行检索的,所以不需要对其他字段创建索引,即使这些字段出现在 SELECT 字段中。
第二种情况是,如果表记录太少,比如少于 1000 个,那么是不需要创建索引的,表记录太少,是否创建索引对查询效率的影响并不大。
第三种情况是,字段中如果有大量重复数据,也不用创建索引,比如性别字段。不过我们也需要根据实际情况来做判断,这一点我在之前的文章里已经进行了说明,这里不再赘述。
最后一种情况是,频繁更新的字段不一定要创建索引。因为更新数据的时候,也需要更新索引,如果索引太多,在更新索引的时候也会造成负担,从而影响效率。
什么情况下索引失效
我们创建了索引,还要避免索引失效,你可以先思考下都有哪些情况会造成索引失效呢?下面是一些常见的索引失效的例子:
1. 如果索引进行了表达式计算,则会失效
EXPLAIN SELECT player_id,player_name FROM player WHERE player_id+1 = 10002;
EXPLAIN SELECT player_id,player_name FROM player WHERE player_id = 10002通过查看这两个SQL语句,可以看出第一条SQL语句会导致索引失效。
| 索引失效 | 索引未失效 |
|---|---|
| 0.577s | 0.038s |
2. 如果对索引使用函数,也会造成失效
EXPLAIN SELECT comment_id, user_id, comment_text FROM product_comment WHERE SUBSTRING(comment_text, 1,3)='abc'在where子句中对comment_id做了函数的处理,这时,索引就会失效。修改为:
SELECT comment_id, user_id, comment_text FROM product_comment WHERE comment_text LIKE 'abc%'这时,索引就会生效了。
3. 在 WHERE 子句中,如果在 OR 前的条件列进行了索引,而在 OR 后的条件列没有进行索引,那么索引会失效。
EXPLAIN SELECT comment_id, user_id, comment_text FROM product_comment WHERE comment_id = 900001 OR comment_text = '462eed7ac6e791292a79'在这条SQL的执行中,comment_id 是主键,而 comment_text 没有进行索引,因为 OR 的含义就是两个只要满足一个即可,因此只有一个条件列进行了索引是没有意义的,只要有条件列没有进行索引,就会进行全表扫描,因此索引的条件列也会失效。
而如果把comment_text也创建索引,执行计划显示如下:
+----+-------------+-----------------+------------+-------------+----------------------+----------------------+---------+------+------+----------+------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------------+------------+-------------+----------------------+----------------------+---------+------+------+----------+------------------------------------------------+
| 1 | SIMPLE | product_comment | NULL | index_merge | PRIMARY,comment_text | PRIMARY,comment_text | 4,767 | NULL | 2 | 100.00 | Using union(PRIMARY,comment_text); Using where |
+----+-------------+-----------------+------------+-------------+----------------------+----------------------+---------+------+------+----------+------------------------------------------------+你能看到这里使用到了 index merge,简单来说 index merge 就是对 comment_id 和 comment_text 分别进行了扫描,然后将这两个结果集进行了合并。这样做的好处就是避免了全表扫描。
4. 当我们使用 LIKE 进行模糊查询的时候,前面不能是 %
EXPLAIN SELECT comment_id, user_id, comment_text FROM product_comment WHERE comment_text LIKE '%abc'这个很好理解,如果一本字典按照字母顺序进行排序,我们会从首位开始进行匹配,而不会对中间位置进行匹配,否则索引就失效了。
5. 索引列尽量设置为 NOT NULL 约束。
MySQL 官方文档建议我们尽量将数据表的字段设置为 NOT NULL 约束,这样做的好处是可以更好地使用索引,节省空间,甚至加速 SQL 的运行。
判断索引列是否为 NOT NULL,往往需要走全表扫描,因此我们最好在设计数据表的时候就将字段设置为 NOT NULL 约束比如你可以将 INT 类型的字段,默认值设置为 0。将字符类型的默认值设置为空字符串 ('')。
6. 我们在使用联合索引的时候要注意最左原则
最左原则也就是需要从左到右的使用索引中的字段,一条 SQL 语句可以只使用联合索引的一部分,但是需要从最左侧开始,否则就会失效。我在讲联合索引的时候举过索引失效的例子。
总结
今天我们对索引的使用原则进行了梳理,使用好索引可以提升 SQL 查询的效率,但同时 也要注意索引不是万能的。为了避免全表扫描,我们还需要注意有哪些情况可能会导致索引失效,这时就需要进行查询重写,让索引发挥作用。
实际工作中,查询的需求多种多样,创建的索引也会越来越多。这时还需要注意,我们要尽可能扩展索引,而不是新建索引,因为索引数量过多需要维护的成本也会变大,导致写效率变低。同时,我们还需要定期查询使用率低的索引,对于从未使用过的索引可以进行删除,这样才能让索引在 SQL 查询中发挥最大价值。

文章被以下专栏收录

SQL
