
如何提高知乎排名?先看懂知乎搜索排序算法!

非技术的朋友,可以直接跳到最后,文章最后总结了影响排序算法的指标,也就是能影响排名的因素,对照着优化自己的知乎文章或回答吧。
知乎作为一大内容平台,有很多获取收益的机会,比如阅读量收益、好物推荐收益。无论是哪种方式,流量为王,这个道理亘古不变。因此,如果在某个回答下,或者某个搜索词条下,占据排名TOP3,基本可以抢占70%的流量。

那么,知乎是如何判定回答或者文章的排名的?百度一下,很多回答会告诉你,威尔逊得分。
对威尔逊得分感兴趣的,可以去自行搜索。公式写的很复杂,说白了,意思就是:
- 赞同越多,排名越靠前
- 赞同足够多时,踩的权重会逐渐变大
直观的可操作的启示,也有两点:
- 刚发布内容时,启动赞很重要
- 刷高赞有风险
由于知乎不展示踩的数量,所以计算威尔逊得分很不现实。
经过一番寻找,找到了知乎算法工程师的技术分享报告。下面会总结一下知乎的搜索排序算法的演进过程,希望对运营知乎账号的小伙伴们有所启示。
发展流程
首先,大致了解一下知乎搜索算法的发展历程。这图其实就说明一件事,自深度学习得到广泛发展很久很久以后,知乎才用深度学习代替机器学习算法,不过方法迭代还是很快的!


根据图中提到的方法,本文会进行介绍。须知,不保证所有细节都是最新的,但是大致框架应该没有变动。
搜索排序
用户在知乎客户端输入问题后,会按照顺序排列展示出一系列相关文章和回答,这整个过程都是用模型实现的。
这整个过程主要包含三个模块,解析—召回—排序。
这三个模块中还包含不少细节,这里不细说,这里介绍一下各个模块中主要的功能:
- 解析:对用户问题(qury)进行解析、表示成向量。
- 召回:通过倒排召回和向量召回两个环节,筛选出TOP400的文档。
- 排序:通过精排序和重排序两个环节,决定文档的输出顺序。其中,先通过精排序对文档进行打分排序;然后,重排序对精排序后的TOP16进行位置的微调。
本文将介绍排序模块的算法,这也是作为知乎博主和运营者最关注的模块。
排序算法
基于Google的TF-Ranking进行开发,有兴趣的朋友可以去看看源码 https://github.com/tensorflow/ranking
TF-Ranking主要包含四个独立模块,特征输入、特征处理、模型打分和损失计算。可以非常灵活的进行改动,并且已经封装好了一些常用的方法,比如排序常用的损失Pairwise Loss 和 NDCG指标,可以快速开发。
当然,知乎结合积累的数据和线上效果,对TF-Ranking还做了很多其他改进和尝试,排序模型的框架如下:


其中,
- 特征输入:将 query特征、相关性特征、文档质量特征、当下点击特征和历史点击特征等输入模型。
- 特征转化:做一些常见的特征处理工作,比如取 log、归一化、onehot 和类别特征转 Embeding 等。
- 模型主体结构:包括主网络部分、 End2End 部分,SERank 部分,Unbias tower 部分和 MOE 方式实现的多目标排序部分
End2End
对于输入的特征,由上面的框架可以看到,排序模型并没有把原文当作特征输入,而是将原文和query通过相似度模型得到的相似分数,作为相关性特征输入排序模型。
为了弥补这部分不足,也做了一些尝试,但是由于计算量和线上效果提升不明显,最终将 BERT 编码之后的query和标题的 Embedding 向量加入到排序模型中,这种做法获得了一定收益。
SERank
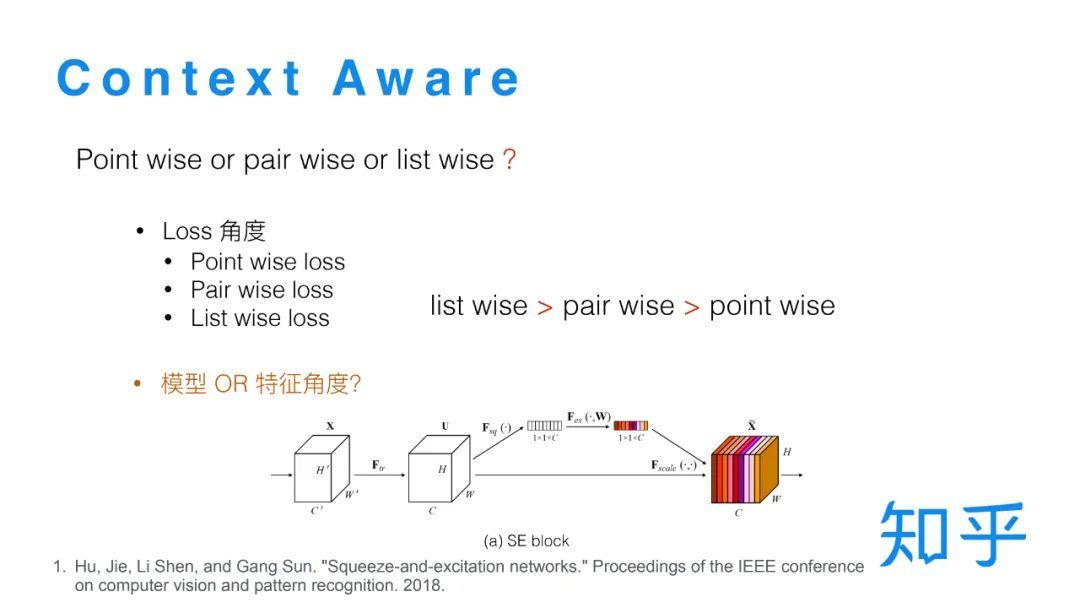

通常来说,比较排序有三种策略:
- point wise:对每个文档分别计算得分,按得分排序
- pair wise:两两比较排序
- list wise:直接输出整体顺序
排序模型选择的是list wise这种策略,为了在对文档打分时,考虑到其他文档,参考SE Block的结构,将处理后的特征和End2End的特征进行排序。
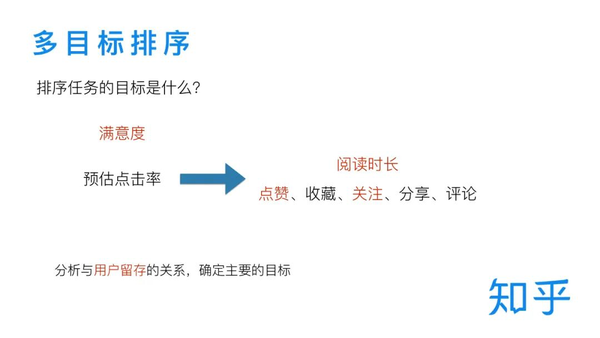
MMOE多目标
排序模型是个多目标任务,知乎希望这个模型输出的排序,能够得到最大程度的用户留存和满意度,这就是排序模型要优化的损失。
有很多指标都可以用来预测用户留存和满意度,比如阅读时长、点赞、收藏、关注、分享、评论,其中相对重要的是阅读时长、点赞、关注。

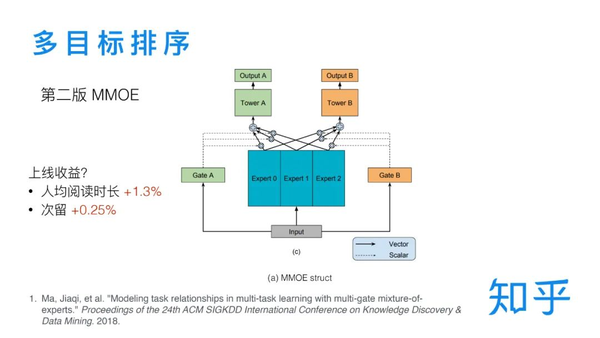
最终,选择MMOE来做多任务排序。主要思路就是,对于多个任务,共享底层的权重,到最后再作区分,保留了各任务一定的独立性。

Tips 如何提升知乎回答和文章排名
根据对知乎搜索排序算法的分析,分析总结了以下提升知乎回答和文章排名的因素,按照重要性进行排序:
- 标题:覆盖尽可能多的高频搜索词条
- 用户留存:阅读时长、点赞、关注
- 首发非常重要:首次发布后的反响,基本决定了文章的是否有潜力冲击前排,往后再更新文章的作用并不大。说白了,得有启动赞。
- 内容:不要标新立异、只与自己比较,模仿排名靠前的文章
本文首发于公众号「一知行」
干货多多 欢迎留言与我交流