Python爬虫:用python爬虫框架Scrapy来完成一个小项目

作为一个爬虫的老手了,不知道大家有没有一种感觉:要写出一个完整的爬虫程序需要做很多琐碎的工作。比如,要针对不同的网站制定不同的解析方式;要导入不同功能的模块;还要编写各种爬取流程的代码。我们在日常工作中会使用PPT模板来制作PPT。那么有没有一个现成的爬虫模板,让我们能够改之即用,也就是说对这个模板进行适当的修改,就能完成一个爬虫项目的开发呢?”
那就让我们来一起学习一下Scrapy这个nb的框架 (只要认真学,绝对能搞懂) 一.什么是Scrapy 在学习python的过程中,我们用到了许多的模块,他们有不同的功能,比如: 1. requests模块:进行请求 2. csv模块:储存数据 而在Scrapy框架里面,我们不需要做怎么多,因为在这个框架里面都能自动实现,下面,我们就来了解Scrapy的基础知识,包括Scrapy的结构及其工作原理
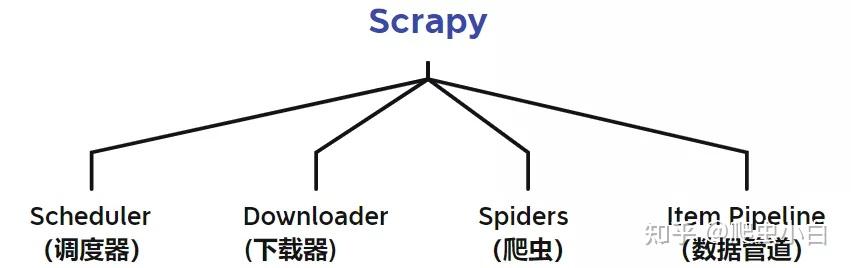

上面的这张图是Scrapy的整个结构。你可以把整个Scrapy框架当成是你所在的部门。最中心位置的Scrapy Engine(引擎)就是你所在部门的大boss,负责统筹规划你这个部门的四大职能。 Scheduler(调度器) 主要负责处理引擎发送过来的requests对象(即网页请求的相关信息集合,包括params,data,cookies,request headers…等),会把请求的url以有序的方式排列成队,并等待引擎来提取(功能上类似于gevent库的queue模块)。 Downloader(下载器) 则是负责处理引擎发送过来的requests,进行网页爬取,并将返回的response(爬取到的内容)交给引擎。它对应的是爬虫流程【获取数据】这一步。 Spiders(爬虫) 主要任务是创建requests对象和接受引擎发送过来的response(Downloader部门爬取到的内容),从中解析并提取出有用的数据。它对应的是爬虫流程【解析数据】和【提取数据】这两步。 Item Pipeline(数据管道) 负责存储和处理Spiders提取到的有用数据。这个对应的是爬虫流程【存储数据】这一步。 Downloader Middlewares(下载中间件) 它的工作相当于下载器的助手,比如会提前对引擎发送的诸多requests做出处理。 Spider Middlewares(爬虫中间件) 它的工作则相当于爬虫的助手,比如会提前接收并处理引擎发送来的response,过滤掉一些重复无用的东西。
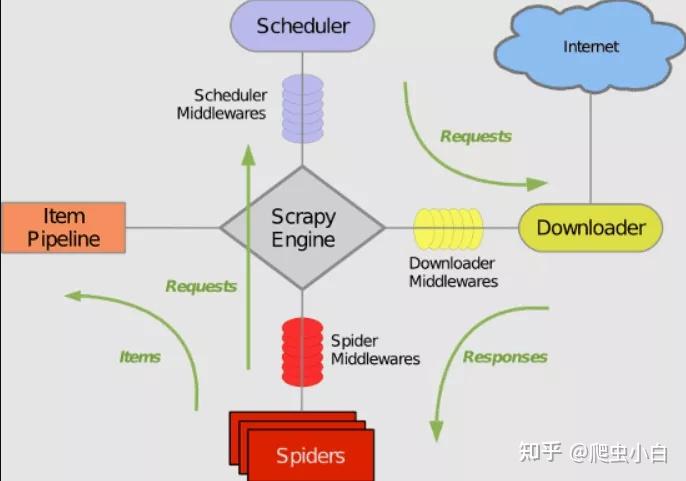

二.Scrapy的工作原理 在Scrapy爬虫部门里,每个成员都各司其职,互相配合,这套运行流程的逻辑很简单,其实就是:引擎大boss说的话就是最高需求!看下面的对话: ScrapyEngine: 今天我们要爬什么呢?: Spiders: 爬取一个url:htpps://…,我已经分装成requests了 ScrapyEngine: 调度器,配合Spiders的工作。把requests都放进队列 调度器: 收到! ScrapyEngine: 下载器,把这些requests爬下来,爬取结果发给我 下载器: 下载器:收到,现在开始处理 下载器: 已完成,现在把response发给你。 ScrapyEngine: Spiders, 我已经把response发给你,请尽快解析和处理 Spiders: 收到。已完成,提取出来的Item已经发送给你了。 ScrapyEngine: 数据管道,把Spider这些Otem处理一下。 数据管道: 收到,现在开始处理。 从上面的对话可以看出Scrapy框架的工作原理。也有许多的优势和好处 在使用 Scrapy 的时候。我们不需要去关心爬虫的每个流程。 并且Scrapy中的网络请求都是默认异步模式,请求和返回都会由引擎去自动分配处理。 如果某个请求出现异常,框架也会帮我们做异常处理,跳过这个异常的请求,继续去执行后面的程序。 所以说,我们使用 Scrapy 可以省掉很多的时间和工作 三.Scrapy的用法 初学的小伙伴在没搞懂原理之前,先别急着看下面的内容,试着把原理搞懂再来做项目。 再了解了Scrapy的结构和工作原理,我们就来试着爬一爬——豆瓣Top250的图书。
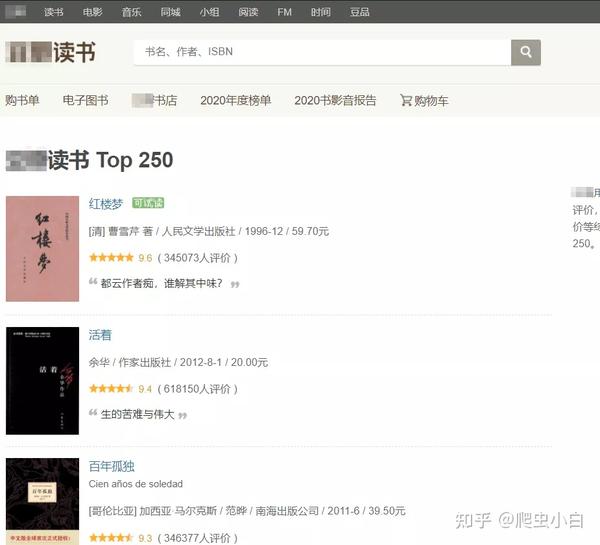

1.明确目标 我们先来看一下我们要爬取的网址 : https://book.douban.com/top250 豆瓣Top250图书一共有10页,每页有25本书籍。我们的初步目标是:先只爬取前三页书籍的信息,总共是 25 x 3 = 75 本,包含书名、出版信息和书籍评分。 2.分析目标 接下来就是要分析爬取网站的网页结构, 首先得判断这些信息被存在了哪里,为了防止出错,大家最好跟着操作,按F12打开快乐爬虫模式,点开
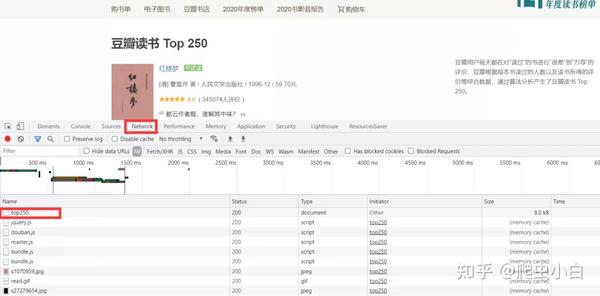

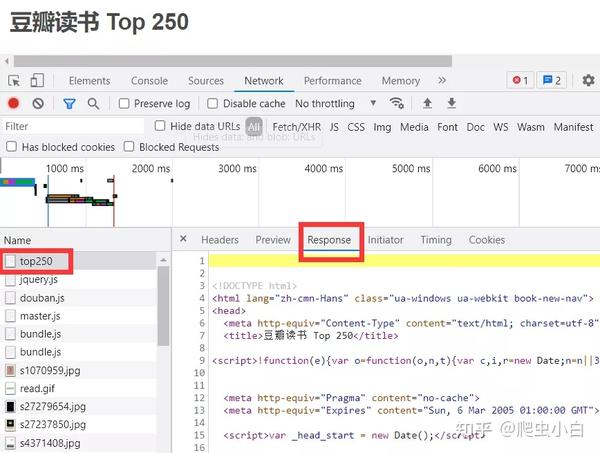

刷新页面,然后点击第0个请求top250,看Response. 我们能在里面找到书名、出版信息,说明我们想要的书籍信息就藏在这个网址的HTML里。 我们能在里面找到书名、出版信息,说明我们想要的书籍信息就藏在这个网址的HTML里。


接着,我们就来具体观察一下这个网站,因为它是带分页的。 所以点击翻到豆瓣Top250图书的第2页。 https://book.douban.com/top250?start=25
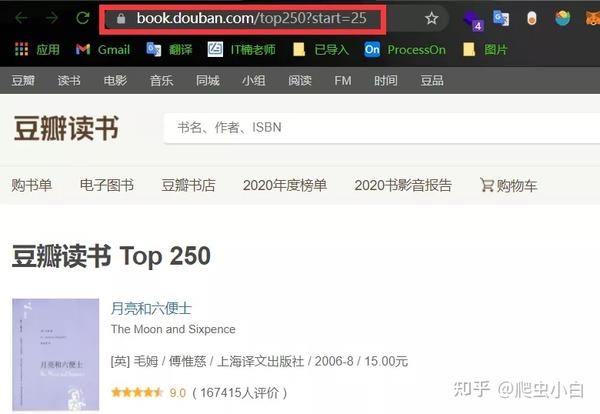

我们可以看到,网址发生了变化,后面多了?start=25。现在的你,应该就能猜到后面的数字应该是代表一页的25本书籍吧?我们还可以看一下第三页,来验证一下
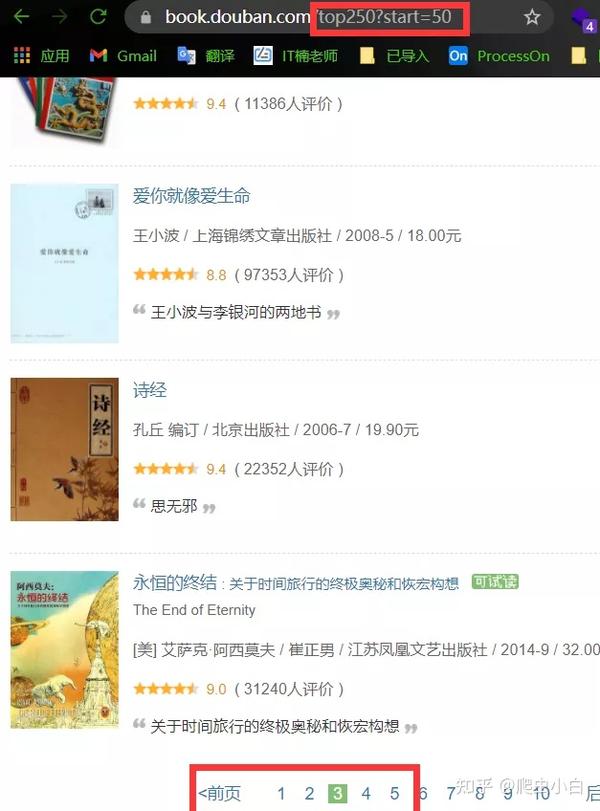

事实证明,我们猜对了。每翻一页,网址后面的数字都会增加25,说明这个start的参数就是代表每页的25本书籍。
也就是说只要改变?start=后面的数字(翻一页加25),我们就能得到每一页的网址。
网页我们已经得到,接下来就是如何去得到所要爬取的内容了
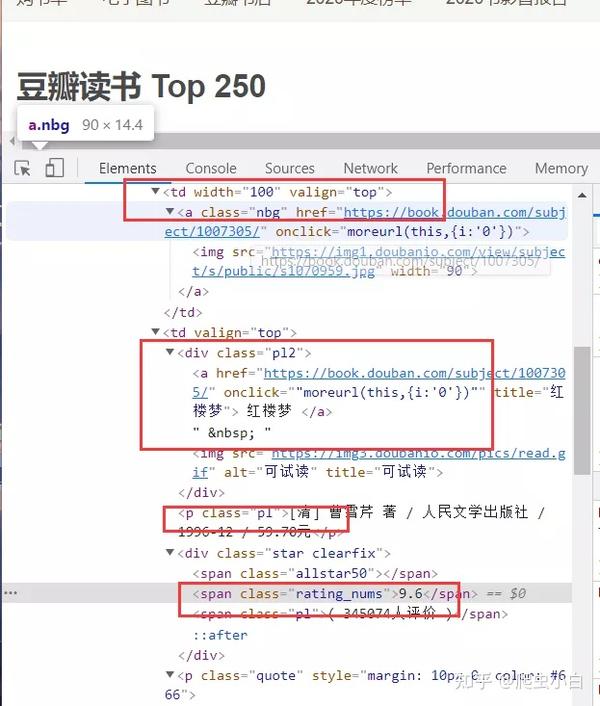
还是是右击打开“检查”工具,点击Elements,再点击光标,把鼠标依次移到书名、出版信息、评分处,就能在HTML里找到这些书籍信息。如下图,《红楼梦》的书籍信息就全部放在table width="100%"标签里.


但是问题出现了: 其实每一页的25本书籍信息都分别藏在了一个table width="100%"标签里。不过这个标签没有class属性,也没有id属性,不方便我们提取信息。 这咋办呢?我们得继续再找一个既方便我们提取,又能包含所有书籍信息的标签。 我们可以看看table width="100%"标签下的tr class="item"元素,好像刚好都能满足我们的要求,既有class属性,又包含了书籍的信息。


最后来总结一下: 我们只要取出<tr class="item">元素下<a>元素的title属性的值、<p class="pl">元素,<span class="rating_nums">元素,就能得到书名、出版信息和评分的数据。

3.代码实现 接下来会涉及到很多Scrapy的用法,如果想学会的话,请你一定要认真地看! (1).Scrapy的安装和文件生成 使用 conda 安装 Scrapy,运行:
conda install -c conda-forge scrapy或者,可以从pypi安装scrappy及其依赖项
pip install Scrapy安装完成后,要在本地电脑打开一个你要保存的文件


再框内输入cmd,然后回车


就能跳转到对于文件的终端 然后,再输入一行能帮我们创建Scrapy项目的命令:scrapy startproject douban,douban就是Scrapy项目的名字。回车,一个Scrapy项目就创建成功了,只要一步一步来,肯定不会出错的


下载完成后,可以看到有这些文件
Scrapy项目里每个文件都有它对应的具体功能。例如 settings.py 是scrapy里的各种设置、 items.py是用来定义数据的、 pipelines.py是用来处理数据的, 它们对应的就是Scrapy的结构中的Item Pipeline(数据管道)。其中最重要的是spiders是放置爬虫的目录。我们可以在spiders这个文件夹里创建爬虫文件。我们来把这个文件,命名为Book_douban_Top250。后面的大部分代码都需要在这个Book_douban_Top250.py文件里编写。
(2).Scrapy核心代码 接下来,都是高能部分了,跟紧了 导入BeautifulSoup用于解析和提取数据;导入scrapy是待会我们要用创建类的方式写这个爬虫,我们所创建的类将直接继承scrapy中的scrapy.Spider类。这样,有许多好用属性和方法,就能够直接使用。


接着我们开始编写爬虫的核心代码。 在Scrapy中,每个爬虫的代码结构基本都如下所示:
import scrapy
import bs4
class DoubanSpider(scrapy.Spider):
# 定义一个爬虫类DoubanSpider
name = 'book_douban'
# name是定义爬虫的名字,这个名字是爬虫的唯一标识。
# name = 'book_douban'意思是定义爬虫的名字为book_douban。
# 等会我们启动爬虫的时候,要用到这个名字。
allowed_domains = ['book.douban.com']
# allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。
# 如果网址的域名不在这个列表里,就会被过滤掉。
start_urls = ['https://book.douban.com/top250?start=0']
# start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。
# 并且allowed_domains的设定对start_urls里的网址不会有影响。
def parse(self, response):
# parse是Scrapy里默认处理response的一个方法。
print(response.text)是不是觉得和之前自己动手写爬虫的完全不一样了呢?怎么连requests.get() 都没有了呀?其实在框架里,我们并不需要写这一句。scrapy框架会为我们做这件事,写好请求后,接下来你就可以直接写对 response 如何做处理,我会在后面做出示例。 在上面我们已经找到了网站的规律,我们直接用for循环得到每个网址: https://book.douban.com/top250?start=(页数-1)*25 ,代码如下:
for x in range(3):
# 获取网址,添加到start_urls
url = f'https://book.douban.com/top250?start={x * 25}'
start_urls.append(url)我们只先爬取豆瓣Top250前3页的书籍信息,接下来,只要再借助DoubanSpider(scrapy.Spider)中的 parse 方法处理 response,借助 BeautifulSoup 来取出我们想要的书籍信息的数据。Let’s go
def parse(self, response):
#parse是默认处理response的方法。
bs = bs4.BeautifulSoup(response.text,'html.parser')
#用BeautifulSoup解析response。
datas = bs.find_all('tr',class_="item")
#用find_all提取<tr class="item">元素,这个元素里含有书籍信息。按照流程,接下来就应该保存数据了,但是在Scrapy里面有点不一样哦。 spiders(如Book_douban_Top250.py)只干spiders应该做的事。对数据的后续处理,另有其他“部门”负责。在scrapy中,我们会专门定义一个用于记录数据的类。定义这些数据类的python文件,正是items.py。 接下来让我们在 items.py 中编写这部分的代码
import scrapy
# 导入scrapy
class BookDoubanItem(scrapy.Item):
# 定义一个类BookDoubanItem,它继承自scrapy.Item
title = scrapy.Field()
# 定义书名的数据属性
publish = scrapy.Field()
# 定义出版信息的数据属性
score = scrapy.Field()
# 定义评分的数据属性scrapy.Field()这行代码实现的是,让数据能以类似字典的形式记录。但它却并不是dict,它的数据类型是我们定义的DoubanItem,属于“自定义的Python字典”。 紧接着,我们去重写Book_douban_Top250.py
def parse(self, response):
# parse是默认处理response的方法
bs = bs4.BeautifulSoup(response.text, 'html.parser')
# 用BeautifulSoup解析response
datas = bs.find_all('tr', class_="item")
# 用find_all提取<tr class="item">元素,这个元素里含有书籍信息
for data in datas:
# 遍历data
item = BookDoubanItem()
# 实例化DoubanItem这个类
item['title'] = data.find_all('a')[1]['title']
# 提取出书名,并把这个数据放回DoubanItem类的title属性里
item['publish'] = data.find('p', class_='pl').text
# 提取出出版信息,并把这个数据放回DoubanItem类的publish里
item['score'] = data.find('span', class_='rating_nums').text
# 提取出评分,并把这个数据放回DoubanItem类的score属性里。
print(item['title'])
# 打印书名
yield item
# yield item是把获得的item传递给引擎 当我们需要记录一次数据的时候,比如前面在每一个最小循环里,都要记录“书名”,“出版信息”,“评分”。我们会实例化一个item对象,利用这个对象来记录数据。一个对象对应一次数据
在Scrapy框架里,每一次当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。这里,要用到yield语句。 yield语句你可能还不太了解,这里你可以简单理解为:它有点类似return,不过它和return不同的点在于,它不会结束函数,且能多次返回信息。 3).Scrapy思路整理 来让我们理一下思路: 爬虫(Spiders)会把豆瓣的10个网址封装成requests对象,引擎会从爬虫(Spiders)里提取出requests对象,再交给调度器 (Scheduler),让调度器把这些requests对象排序处理。 然后引擎再把经过调度器处理的requests对象发给下载器(Downloader),下载器会立马按照引擎的命令爬取,并把response返回给引擎。 紧接着引擎就会把response发回给爬虫(Spiders),这时爬虫会启动默认的处理response的parse方法,解析和提取出书籍信息的数据,使用item做记录,返回给引擎。引擎将它送入Item Pipeline(数据管道)处理。 如果现在运行还是会报错,原因在于Scrapy里的默认设置没被修改。比如我们需要修改请求头(User-Agent需要设置)。点击settings.py文件,你能在里面找到如下的默认设置代码:
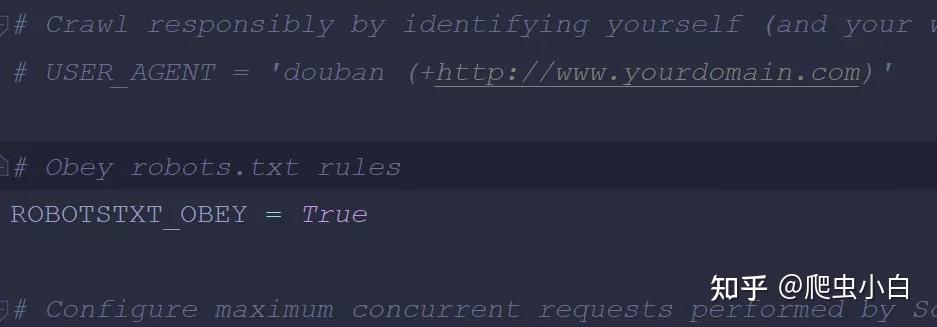

在这里我们把USER _AGENT的注释取消(删除#),然后替换掉user-agent的内容,就是修改了请求头。
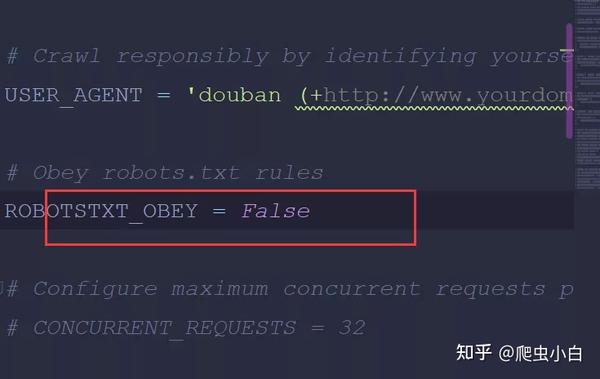
又因为Scrapy是遵守robots协议的,如果是robots协议禁止爬取的内容,Scrapy也会默认不去爬取,所以我们还得修改Scrapy中的默认设置 把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False,就是把遵守robots协议换成无需遵从robots协议,这样Scrapy就能不受限制地运行。

最后来看一下Book_douban_Top250.py的完整代码:
import scrapy
import bs4
from ..items import BookDoubanItem
class DoubanSpider(scrapy.Spider):
# 定义一个爬虫类DoubanSpider
name = 'book_douban'
# name是定义爬虫的名字,这个名字是爬虫的唯一标识。
# name = 'book_douban'意思是定义爬虫的名字为book_douban。
# 等会我们启动爬虫的时候,要用到这个名字。
allowed_domains = ['book.douban.com']
# allowed_domains是定义允许爬虫爬取的网址域名(不需要加https://)。
# 如果网址的域名不在这个列表里,就会被过滤掉。
start_urls = ['https://book.douban.com/top250?start=0']
# start_urls是定义起始网址,就是爬虫从哪个网址开始抓取。
# 并且allowed_domains的设定对start_urls里的网址不会有影响。
for x in range(3):
url = f'https://book.douban.com/top250?start={x * 25}'
start_urls.append(url)
def parse(self, response):
# parse是默认处理response的方法
bs = bs4.BeautifulSoup(response.text, 'html.parser')
# 用BeautifulSoup解析response
datas = bs.find_all('tr', class_="item")
# 用find_all提取<tr class="item">元素,这个元素里含有书籍信息
for data in datas:
# 遍历data
item = BookDoubanItem()
# 实例化DoubanItem这个类
item['title'] = data.find_all('a')[1]['title']
# 提取出书名,并把这个数据放回DoubanItem类的title属性里
item['publish'] = data.find('p', class_='pl').text
# 提取出出版信息,并把这个数据放回DoubanItem类的publish里
item['score'] = data.find('span', class_='rating_nums').text
# 提取出评分,并把这个数据放回DoubanItem类的score属性里。
print(item['title'])
# 打印书名
yield item
# yield item是把获得的item传递给引擎(4).Scrapy运行 想要运行Scrapy有两种方法: 一种是在本地电脑的终端跳转到scrapy项目的文件夹,然后输入命令行:scrapy crawl book_douban(book_douban就是我们爬虫的名字)。 另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。
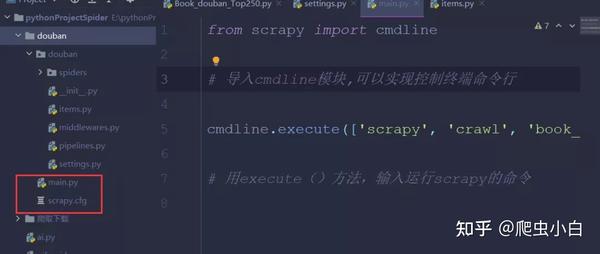

代码:
from scrapy import cmdline
#导入cmdline模块,可以实现控制终端命令行
cmdline.execute(['scrapy','crawl','book_douban'])
#用execute()方法,输入运行scrapy的命令大功告成,让我们来运行试一试吧。


在终端可以看到所爬取的数据,Nice!!这里没有保存数据,因为存储数据需要修改pipelines.py文件。内容过多,过几天会继续更新,教大家如何保存数据 四.总结 Scarpy好使是好使,但是对于小白来说学习起来还是有一定难度的,但是我相信,在看完我的教程后,在通过自己的摸索,一定能成功的。如果有小伙伴想进一步学习可以看中文文档: 这是保存下来的用python爬虫框架Scrapy来完成一个小项目,如有不足之处或更多技巧,欢迎指教补充。愿本文的分享对您之后爬虫有所帮助。谢谢~
编辑排版:筱筱 原创:武亮宇

