
Python爬虫之思维导图汇总【资源可下载】

昨天跟大家捋了一下Python数据分析方向的学习内容,干脆今天也把Python爬虫方向的学习思路也捋一捋吧。
之前分享的爬虫新手学习教程,也看到好多人收藏了,就是不知道有没有躺在大家的收藏夹里吃灰(狗头),今天再做一次总结。(资源文中可获取)
先放一张完整的Python爬虫学习知识框架导图:
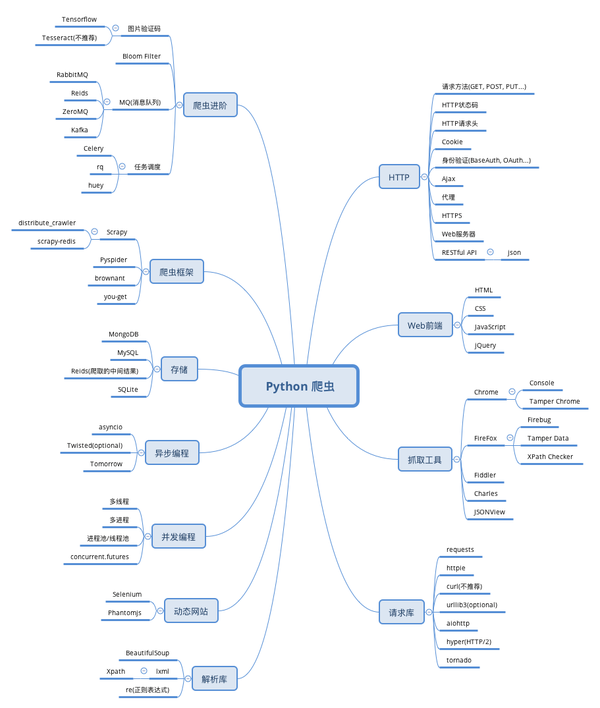

Python爬虫的工作流程无非就是获取数据——解析提取数据——存储数据这三步,所以要想上手爬虫,这三步得先搞懂了。
在讲这三部分内容之前先啰嗦补充两个点:
1)部分计算机网络知识
爬虫通过编程向网络服务器请求数据后,再对HTML解析,然后提取所需数据,所以在这之前计算机网络知识还是要去补充学习的,对这块完全不懂怎么去爬网页?
也不用全都学,但HTTP & HTTPS、网络协议、网络结构(HTML语法、html标签、数据、css样式、js等等什么的)这些得知道。


2)前期的Python基础
学习爬虫是有一定的前提的:不需要你做到完全精通Python,但你不能不会!
比如:
List dict:用来序列化你爬的东西
切片:用来对爬取的内容进行分割、生成
条件判断(if等):用来解决爬虫过程中哪些要哪些不要的问题
循环和迭代(for while):用来循环、重复爬虫动作
文件读写操作:用来读取参数、保存趴下来的内容等
像Python基础中的数据类型、数据结构、逻辑结构、列表、字典、字符串、if语句、for循环等一些最核心的语法结构是必须要弄清楚的!
还在Python基础学习阶段的小伙伴不用太着急,慢慢来,先把基础的东西学好再上手爬虫的学习会顺畅很多,我这里也把自己学习Python时收集到的一些不错的语法学习资料整理出来了,方便大家学习,需要的可点击下方找群管理免费获取↓↓
<Python基础核心语法学习 附教程视频>



接下里重点讲一下获取数据——解析提取数据——存储数据这三部分的细分内容;
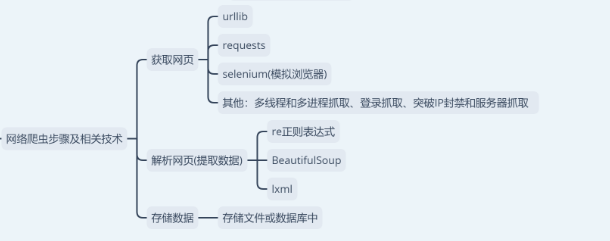

文章有点长,有些小伙伴可能想直接下载资源,所以我把后面讲到的一些具体的知识体系框架导图先统一打包好放在下方了,需要的可点击下方卡片找群管理免费获取资源。
<Python爬虫全套核心学习资料 点击下载>




1 获取数据
爬虫爬取的目标绝大多数情况下要么是网页,要么是 App,通常可以用到的请求库有Requests、urllib、aiohttp、selenium等。
我个人比较推荐新手掌握精通Requests库,爬取网页最好的第三方库,简单简洁,有了它,Cookies、登录验证、代理设置等操作都不是事儿。
安装方法:Anaconda中已经包含了这个库,如果要安装,使用命令:pip install requests
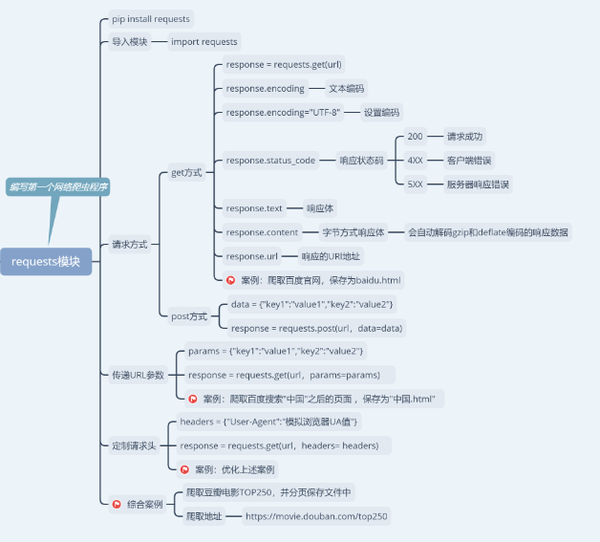

requests的7个主要方法:
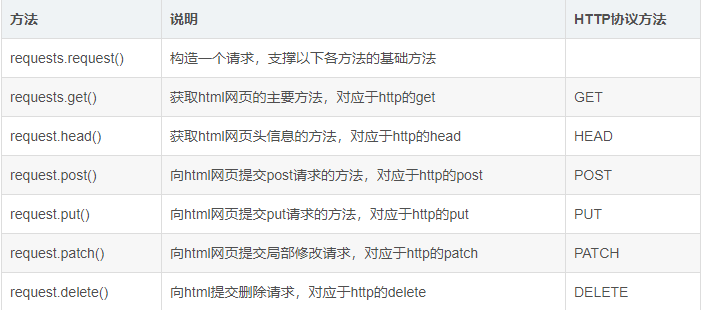

最常被用到的两种方法:GET 和 POST。
GET - 从指定的资源请求数据。
POST - 向指定的资源提交要被处理的数据
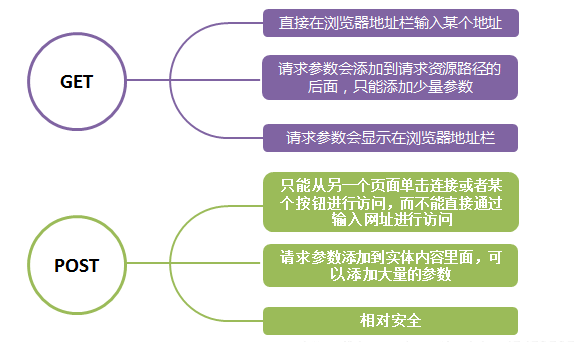

动态页面的爬取目前有两种方法:
1)分析页面请求
2)selenium模拟浏览器行为(霸王硬上弓,以后再说)
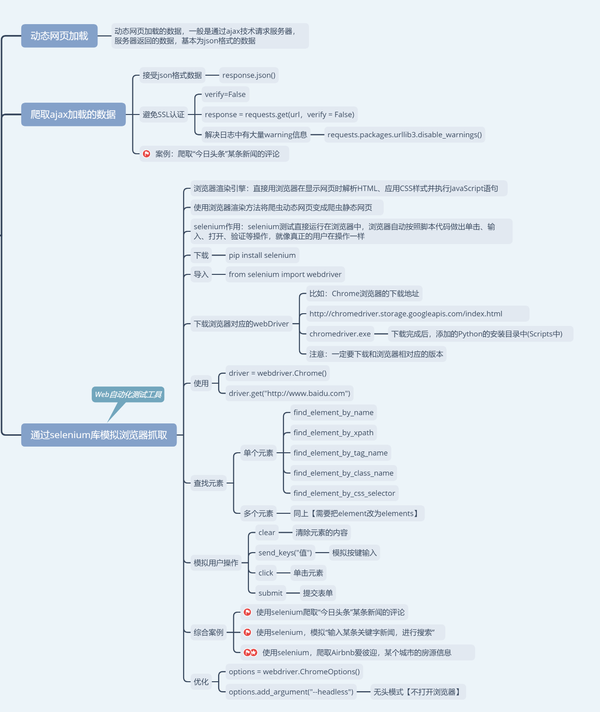

2 解析数据
对于 HTML 类型的页面来说,常用的解析方法无非就那么几种,BeautifulSoup,正则、XPath、CSS Selector等;
另外对于某些接口,常见的可能就是 JSON、XML 类型,使用对应的库进行处理即可,这里新手熟练掌握一到两种库的使用方法就行。
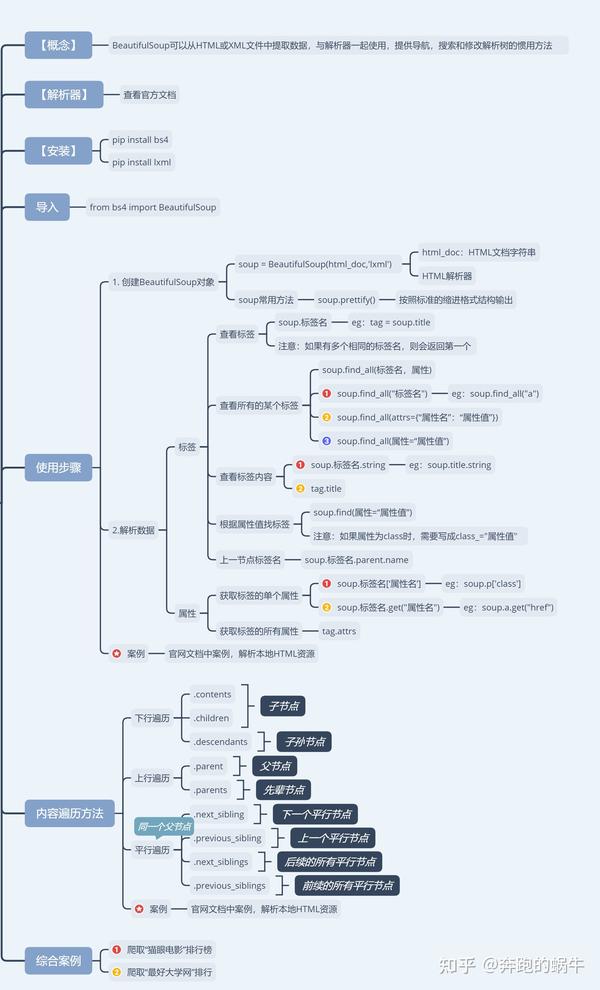
BeautifulSoup
是python的一个库,最主要的功能是从网页抓取数据,处理高效,支持多种解析器,利用它就不用编写正则表达式也能方便的实现网页信息的抓取。

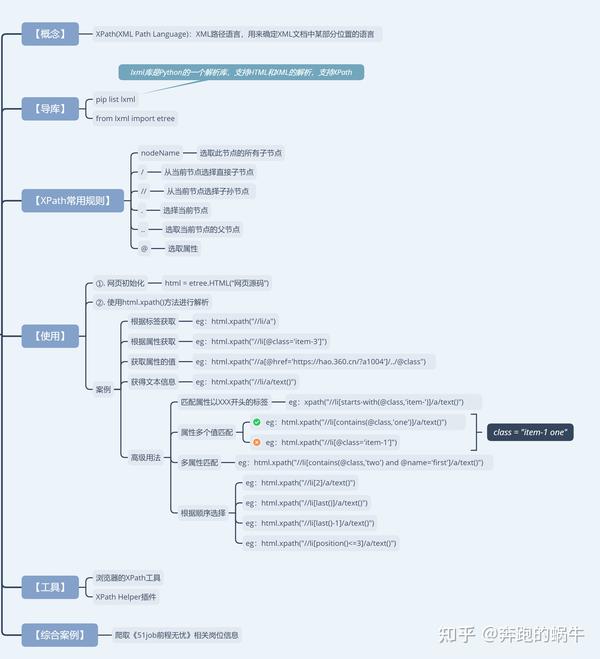
Xpath
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,掌握以后基本不用正则表达式。
另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择。

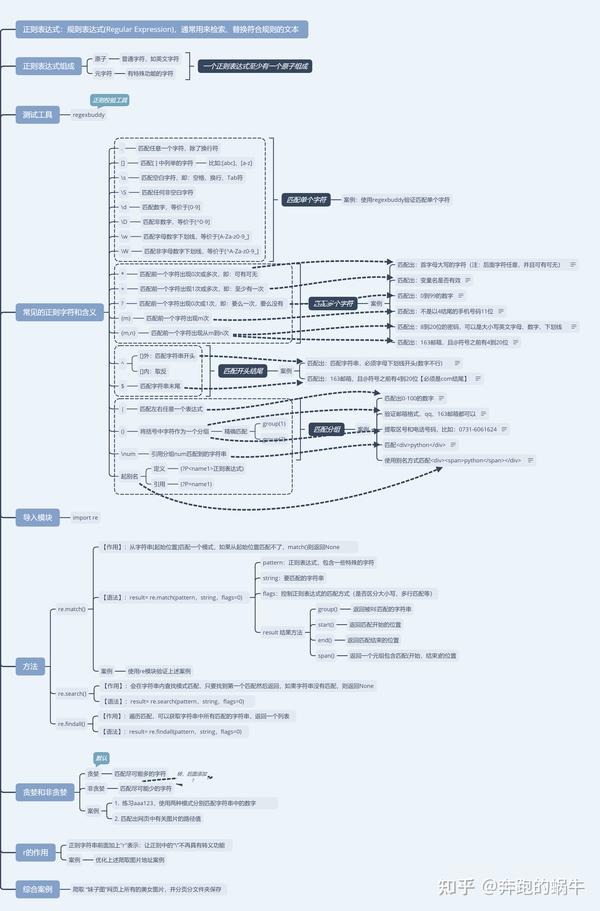
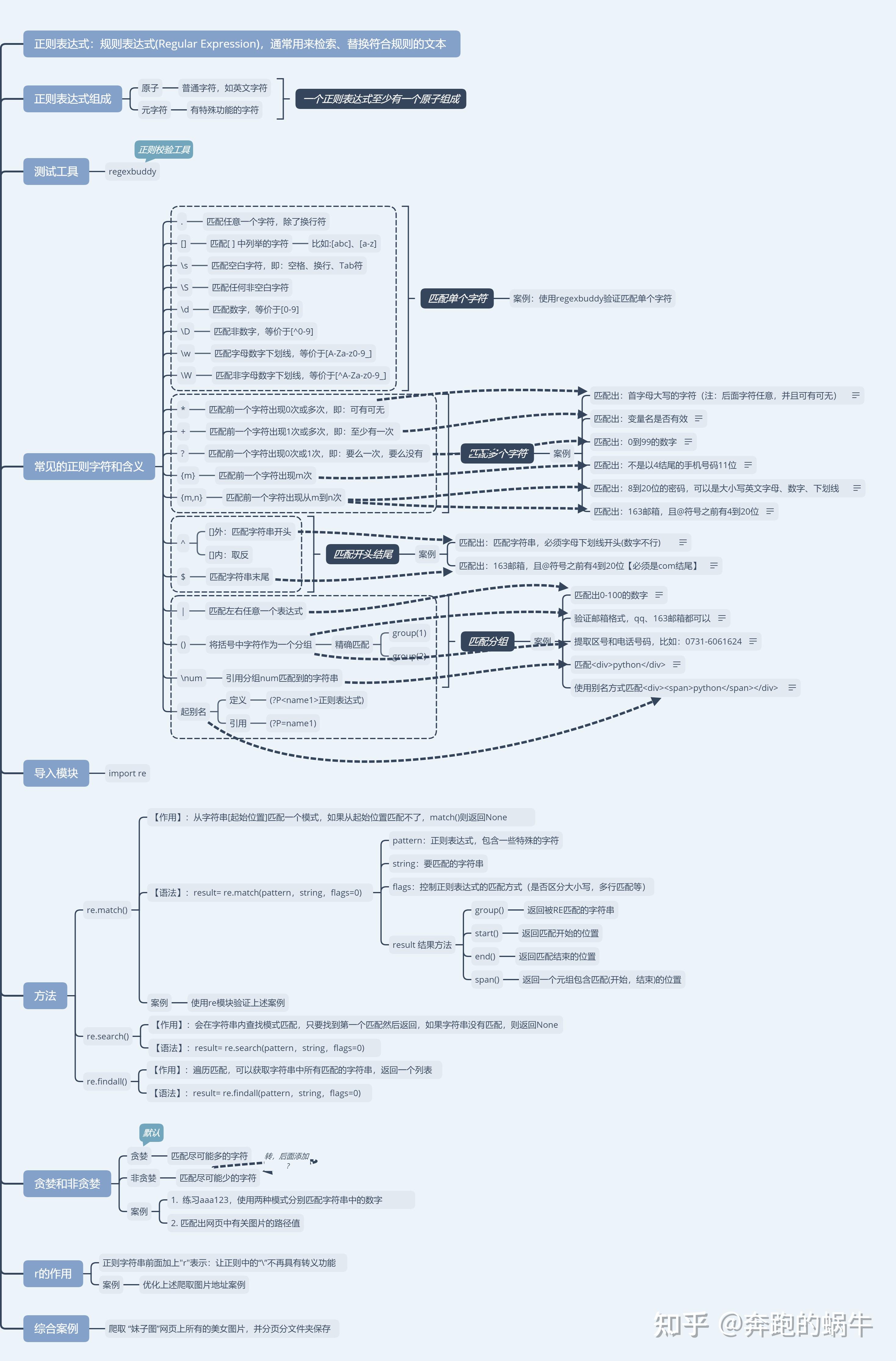
正则表达式-re模块
正则表达式通常用于在文本中查找匹配的字符串,在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:


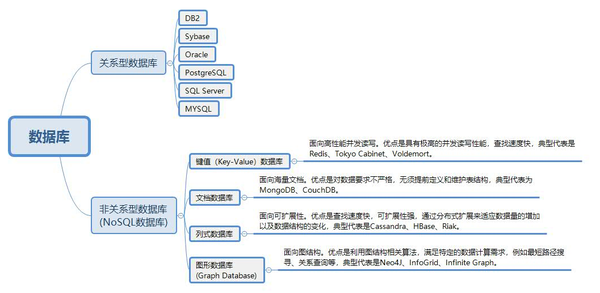
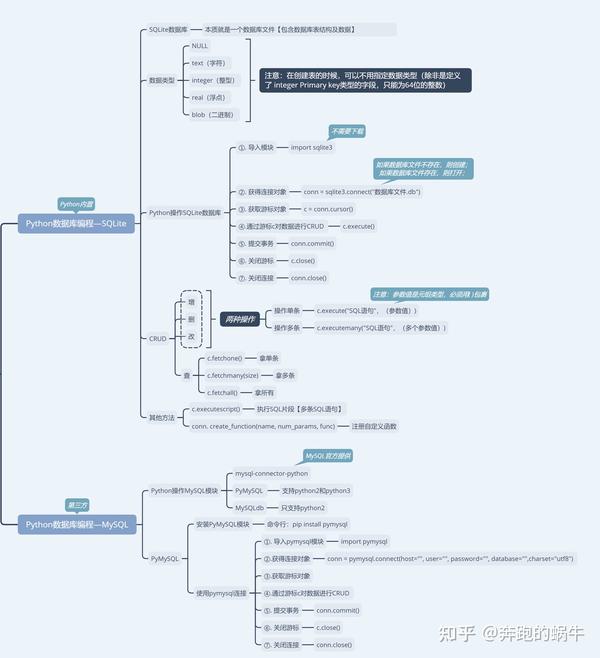
3 存储数据
这一步比较简单,主要介绍两种存储方式:
A、文件:如 JSON、CSV、TXT、图⽚、视频、⾳频等,常用的一些库有 csv、xlwt、json、pandas、pickle、python-docx 等。
B、数据库:分为关系型数据库、非关系型数据库,如 MySQL、MongoDB、HBase 等,常用的库有 pymysql、redis-py、pymongo、py2neo、thrift。
建议学习掌握主流的一两种数据存储方式即可


学到这里,爬虫的重点内容基本也学的差不多了,如果你是想掌握更高的爬虫技术或者想走职业化的发展道路,那这些是远远不够的,需要深入学习的地方还有很多。
还不太清楚自己爬虫进阶-高级要怎么学的话,这里推荐一个Python爬虫学习交流群,群内有很多大牛老师可以帮你解答疑惑哦~
<Python爬虫学习交流群 资源共享>
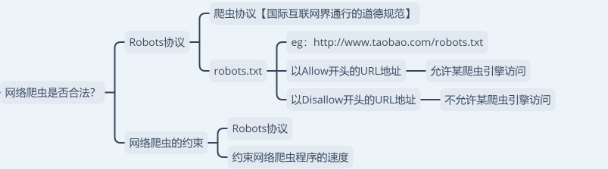
反爬
反爬这部分是个重点,爬虫现在已经越来越难了,非常多的网站已经添加了各种反爬措施,在这里可以分为非浏览器检测、封 IP、验证码、封账号、字体反爬等。
常规的解决技巧有比如控制访问频率、抓包、反加密字体、验证码OCR处理、使用代理IP池等,使用代理适用于大部分网站均限制了IP的访问量;
对于“频繁点击”的情况,我们还可以通过限制爬虫访问网站的频率来避免被网站禁掉。
友情提示:不要去做垃圾爬虫!原因不需要我说了吧

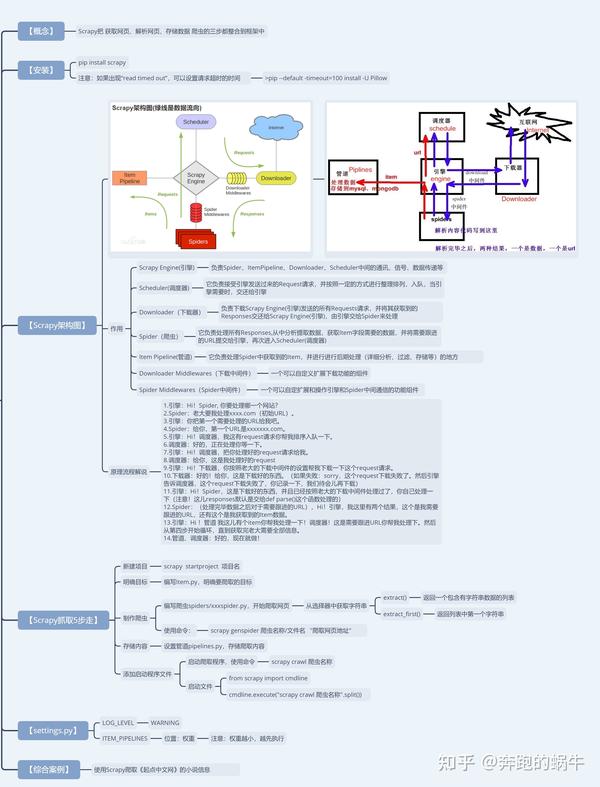
爬虫框架scrapy
通过前面几部分的学习一般的爬虫已经不是问题了,但碰到更复杂的情况下,scrapy框架的作用就出来了。
这里可根据自己的学习需要进行选择性学习,如果是想要提升爬虫的效率,掌握scrapy框架会非常便利。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试. 最吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。

最后的一些个人建议:
不管学习Python的哪个应用方向都需要勤动手练习滴,光是纸上谈兵是很难真正学会的,一定要坚持动手练习,学习没有捷径,不要急于求成!