SQL Server 索引及执行计划使用案例介绍

索引的相关术语
1 堆(Heap)是一种没有指定排序的数据结构,通俗的理解堆就像是按照顺序排放的杂物。在数据库里也即是对应没有聚集索引。
2 聚集索引:一个表只有一个聚集索引且数据存放在聚集索引内。
3 非聚集索:是一个B-树(B-Tree)结构,它包含了索引键和指向数据行的指针。
我们可以在堆或聚集索引类型的表里创建非聚集索引。一个表的非聚集索引最多支持999个。在覆盖索引的应用场景下,可以定义非聚集索引时指定包含(include)其它字段。
4 唯一索引:唯一索引不允许表里的指定的列数据有重复的值,一个表可以有一个或多个唯一索引。
5 主键:主键是一个表里每行记录的唯一标识同时默认情况下也是聚集索引。
6 RID lookup 堆形式的表的执行计划里通过ROW id映射匹配其它非聚集索引字段的操作。
堆的演示案例
建立验证表
借助CTE插入100万条记录到EMPLOYEES表。
USE ShenLiang2025
GO
CREATE TABLE EMPLOYEES
(
id INT IDENTITY,
name NVARCHAR(50),
email NVARCHAR(50),
dept NVARCHAR(50)
)
GO
WITH T AS (
SELECT 1 AS NUM
UNION ALL
SELECT T.NUM+1
FROM T
WHERE T.NUM<1000000 )
INSERT INTO EMPLOYEES
SELECT 'ABC ' + RTRIM(NUM), 'ABC' + RTRIM(NUM) + '@shenliang2025.COM',
'dept ' + RTRIM(NUM)
FROM T
OPTION(MAXRECURSION 0)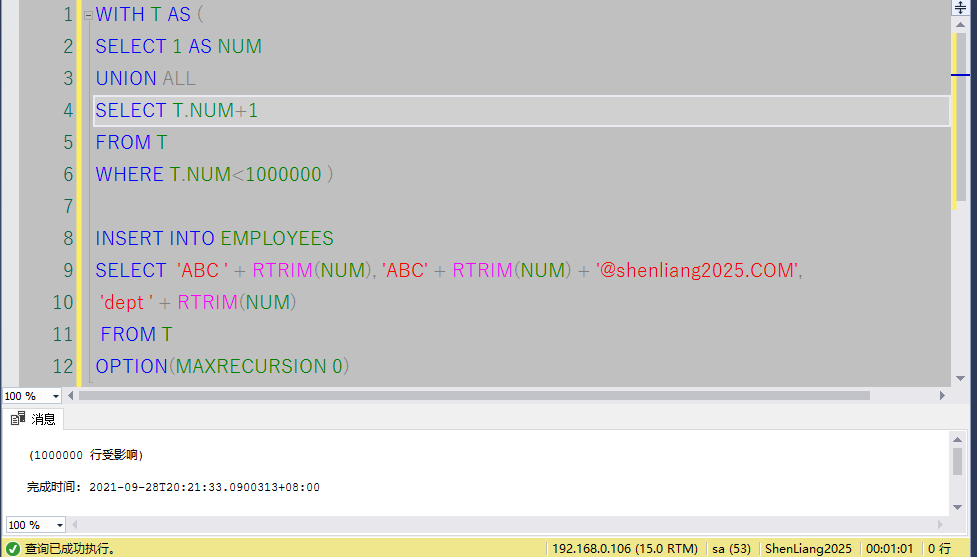

系统表查看当前表的类型
SELECT * FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.EMPLOYEES')

无索引下WHERE查询
--查询名字是ABC 874000的员工信息。
-- 执行时点击SSMS里的“包括实际的执行计划按钮”菜单(或者用CTRL+M快捷键)。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'

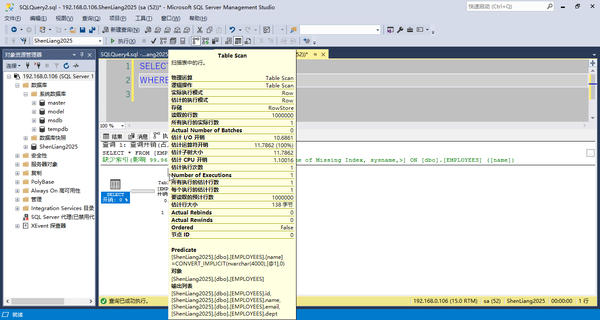
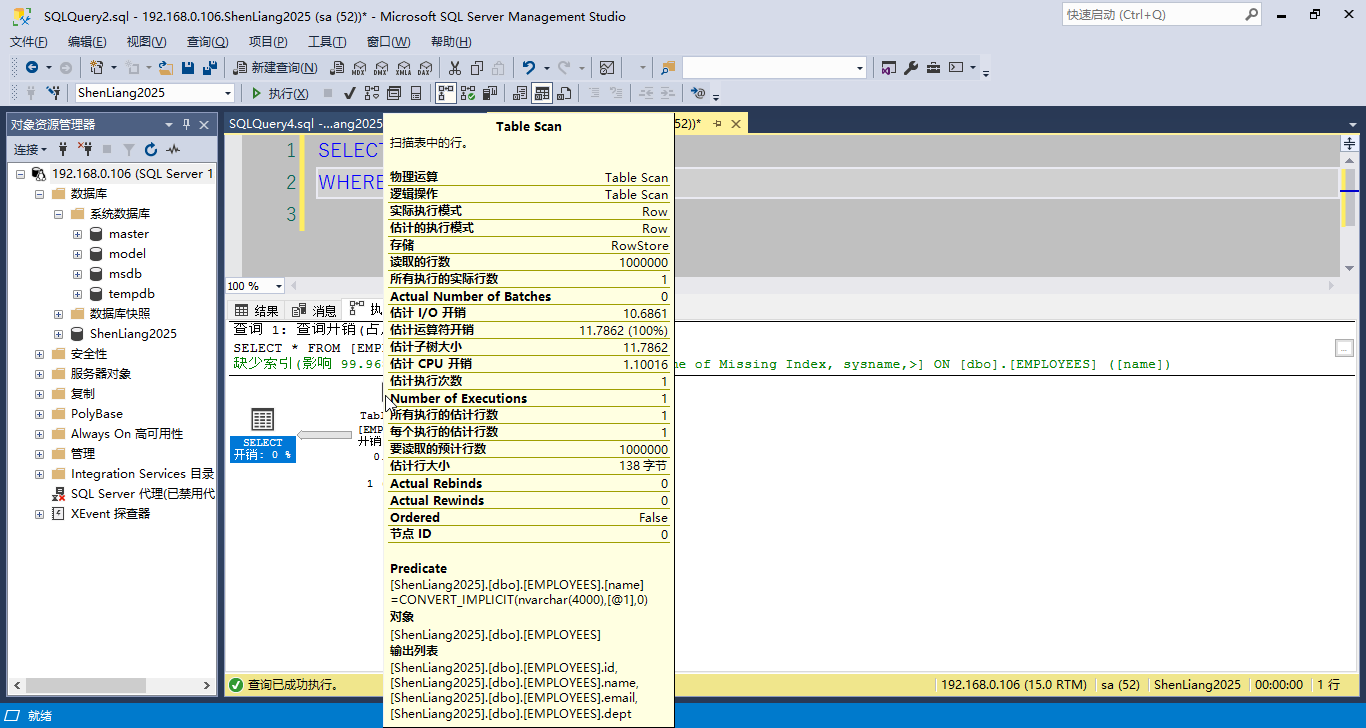
通过分析实际的执行计划不难发现,在堆情况下的表里应用WHERE查询1条记录时需要遍历表里所有的所有记录(这里是100万条)。
非聚集索引下WHERE查询
--在NAME字段上建立非聚集索引。
CREATE NONCLUSTERED INDEX IX_EMP_NAME ON EMPLOYEES(NAME)
-- 再次执行WHERE查询并含实际执行计划。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'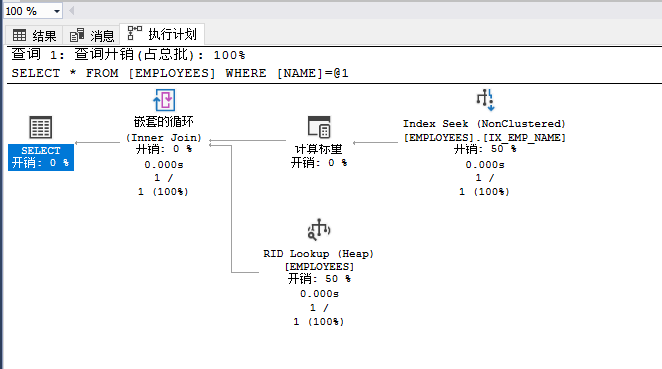

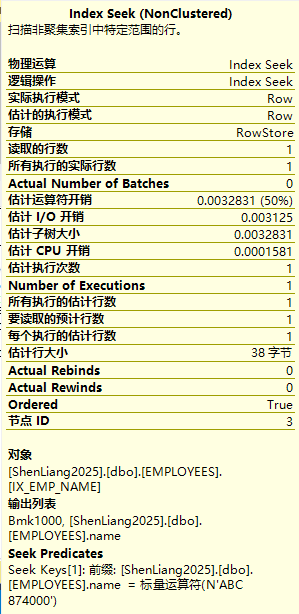
可见在index seek下读取的行数和所实际执行的行数都是1,而且估计子树大小为0.0032831相对于上例的11改进巨大。
RID映射查找
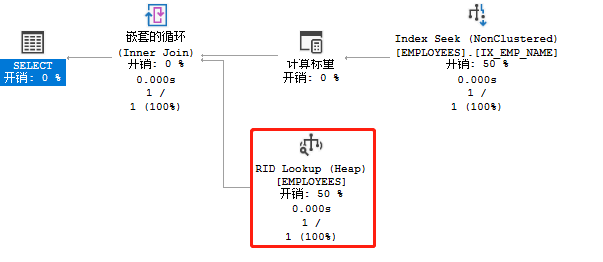

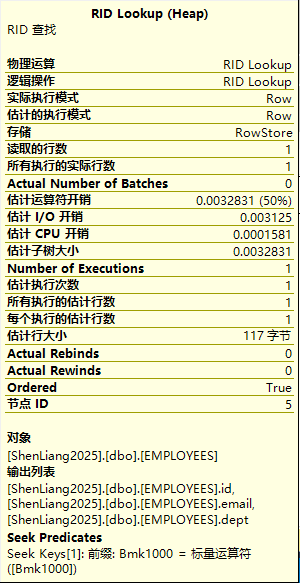
上例的执行计划中我们可以看到RID lookup过程,这个映射查找出现的原因是我们的查询里name字段虽然可以在非聚集索引IX_EMP_NAME上支持获取到,但id、email、dept而这些信息则需要通过Row ID来映射匹配到。
注:非聚集索引在建立时已经有name字段和Row ID的匹配信息。
RID Lookup示意
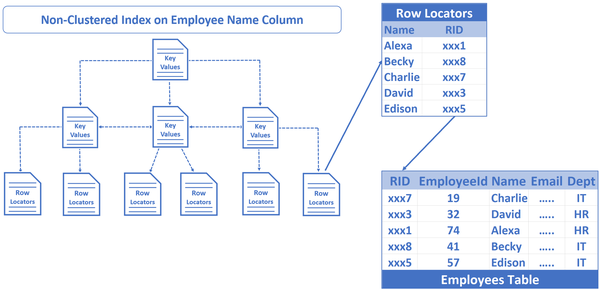

通过上图我们可以看到在非聚集索引的叶子节点里存放了索引字段和RID,而通过RID可以找到记录的所有的字段。
什么时候用堆类型的表
1 用于插入大量、无序数据的临时表时。
2 数据量较小时。
3 始终通过非聚集索引访问数据时。
聚集索引的演示案例
添加主键
-- 删除原有的索引
DROP INDEX EMPLOYEES.[IX_EMP_NAME]
ALTER TABLE EMPLOYEES ADD CONSTRAINT PK_EMPLOYEES_ID PRIMARY KEY(id);
GO
系统表查看当前表的类型
SELECT * FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.EMPLOYEES')

无索引下WHERE查询
--查询名字是ABC 874000的员工信息。
-- 执行时点击SSMS里的“包括实际的执行计划按钮”菜单(或者用CTRL+M快捷键)。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'

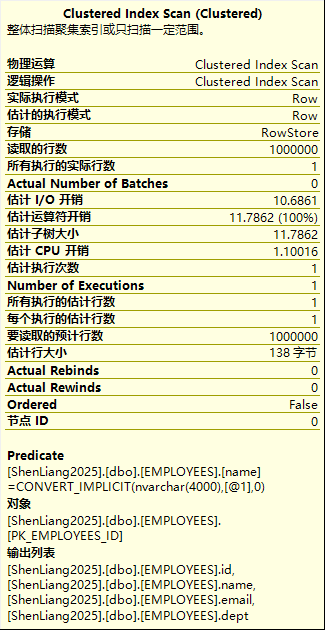
这里因为是建了聚集索引,表数据存储在索引的叶子节点,所以应用的clustered index scan,读取的行数还是100W,所有实际执行的行数为1行。
非聚集索引下WHERE查询
--在NAME字段上建立非聚集索引。
CREATE NONCLUSTERED INDEX IX_EMP_NAME ON EMPLOYEES(NAME)
-- 再次执行WHERE查询并含实际执行计划。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'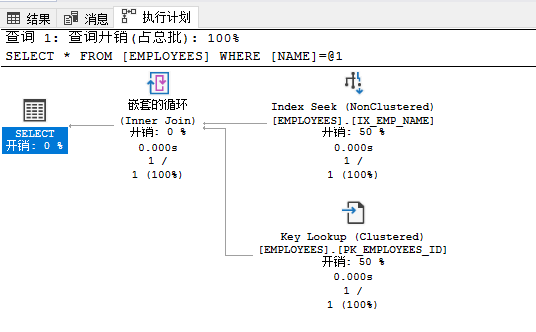

Key映射查找
查询例子同上。
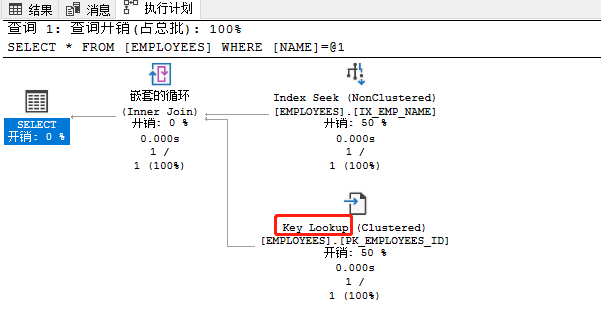
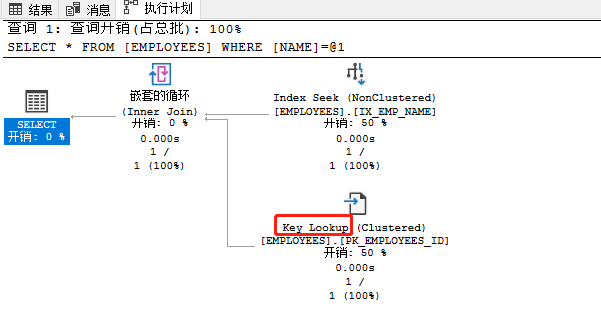
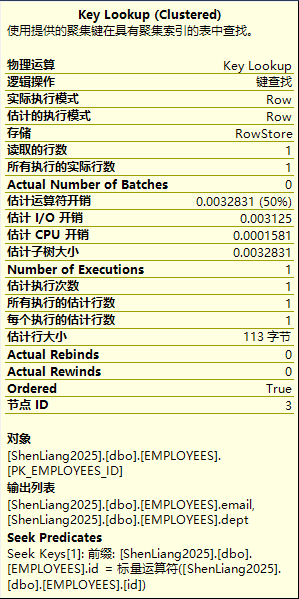
上例的执行计划中我们可以看到key lookup过程,这个映射查找出现的原因是我们的查询里name字段虽然可以在非聚集索引IX_EMP_NAME上支持获取到,但id、email、dept而这些信息则需要通过聚集索引里的记录ID来映射匹配到。为了区分堆形式的RID lookup,这里用的标识是key lookup。
Key Lookup示意
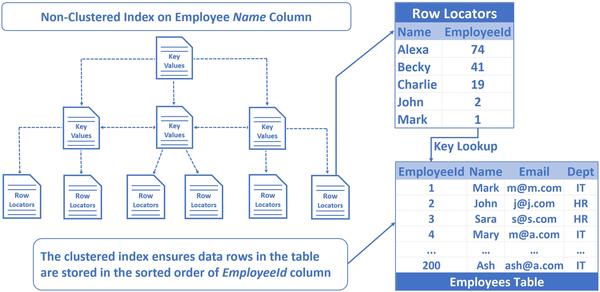

通过上图我们可以看到在非聚集索引的叶子节点里存放了索引字段和主键(如Employeeid),而通过主键可以找到记录的所有的字段。
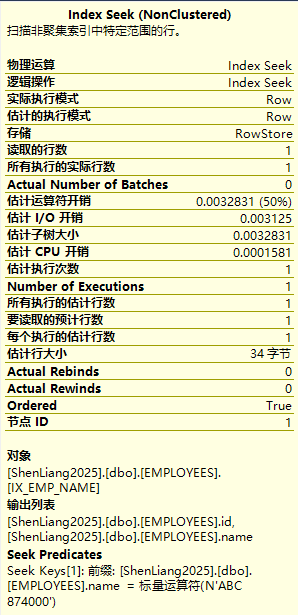
索引查找的演示案例
聚集索引查找
索引查找(index seek)即查询条件内命中索引,直接接用主键匹配时触发聚集索引查找(Index Seek)
SELECT * FROM EMPLOYEES
WHERE id IN(10,100,1000,10000,100000,1000000)
SELECT * FROM EMPLOYEES WHERE id = 57864
SELECT * FROM EMPLOYEES WHERE id >10000 AND id < 1000000以第一个查询为例,其执行计划见下:
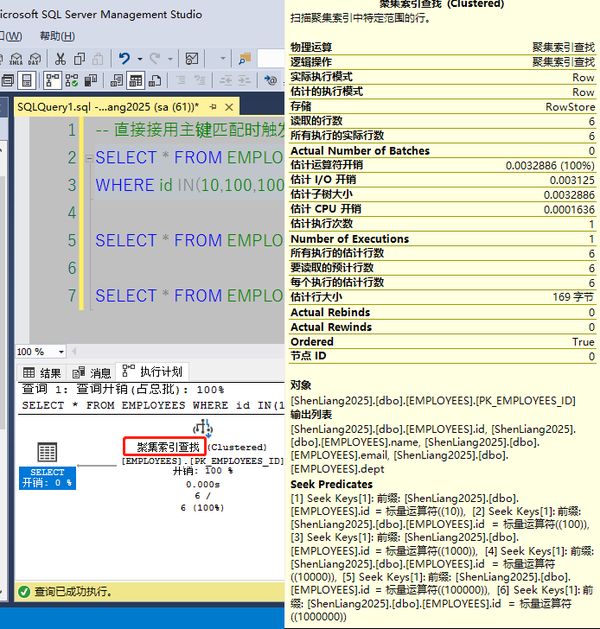

可见用index seek时读取的行数和所有执行的实际行数都是6,命中率很高。
非聚集索引查找
命中非聚集索引的条件,再通过key lookup找到其它字段。
详见“聚集索引的演示案例”里的“非聚集索引下WHERE查询”章节。
--在NAME字段上建立非聚集索引。
CREATE NONCLUSTERED INDEX IX_EMP_NAME ON EMPLOYEES(NAME)
-- 再次执行WHERE查询并含实际执行计划。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'聚集索引应用场景概述
以下示例查询条件会用到索引查找:
id = 12000
score < 89
name = ’John’
name LIKE ’John%’索引扫描的演示案例
索引扫描
详见“聚集索引的演示案例”里的“无索引下WHERE查询”章节
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'这里因为没有索引,只能通过扫描聚集索引以索引扫描的方式获得数据。
索引扫描应用场景概述
以下示例查询条件会用到索引扫描:
ABS(id) = 12000
score+10< 89
name LIKE ’%john’
UPPER(name) = 'JOHN'覆盖索引的演示案例
建立索引时指定以include方式。
CREATE NONCLUSTERED INDEX IX_EMP_NAME2 ON EMPLOYEES(NAME) INCLUDE(email,dept)
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'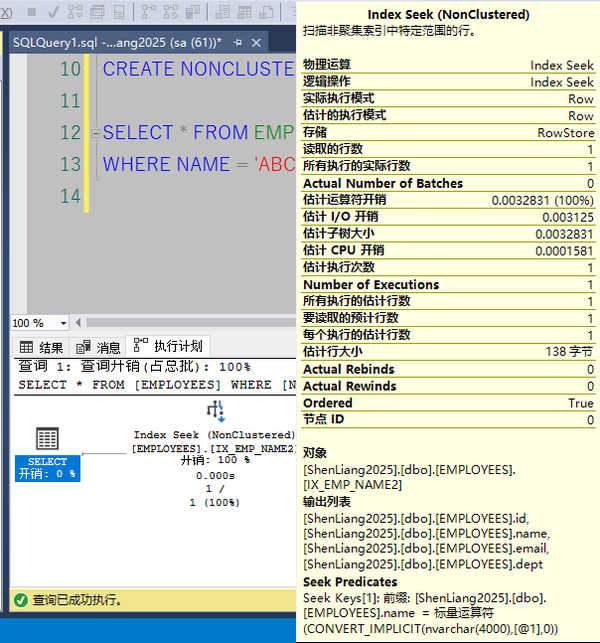

通过执行计划我们不难看出直接走覆盖索引IX_EMP_NAME2,因为该索引覆盖查询里的所有字段。
数据存储介绍
物理存储方式
SQL Server里的数据在逻辑上以行列方式存储,在物理上以数据页的形式存储。一个数据页是SQL Server存储数据的基本单位,它有8k大小。当我们往表里插入时,数据会被存放在一系列的8k的数据页里。


数据实际存储示意
一系列的数据页以树的形式组织起来,具体见下图示意。这个树叫做B-Tree,索引B-Tree或者聚集索引结构。
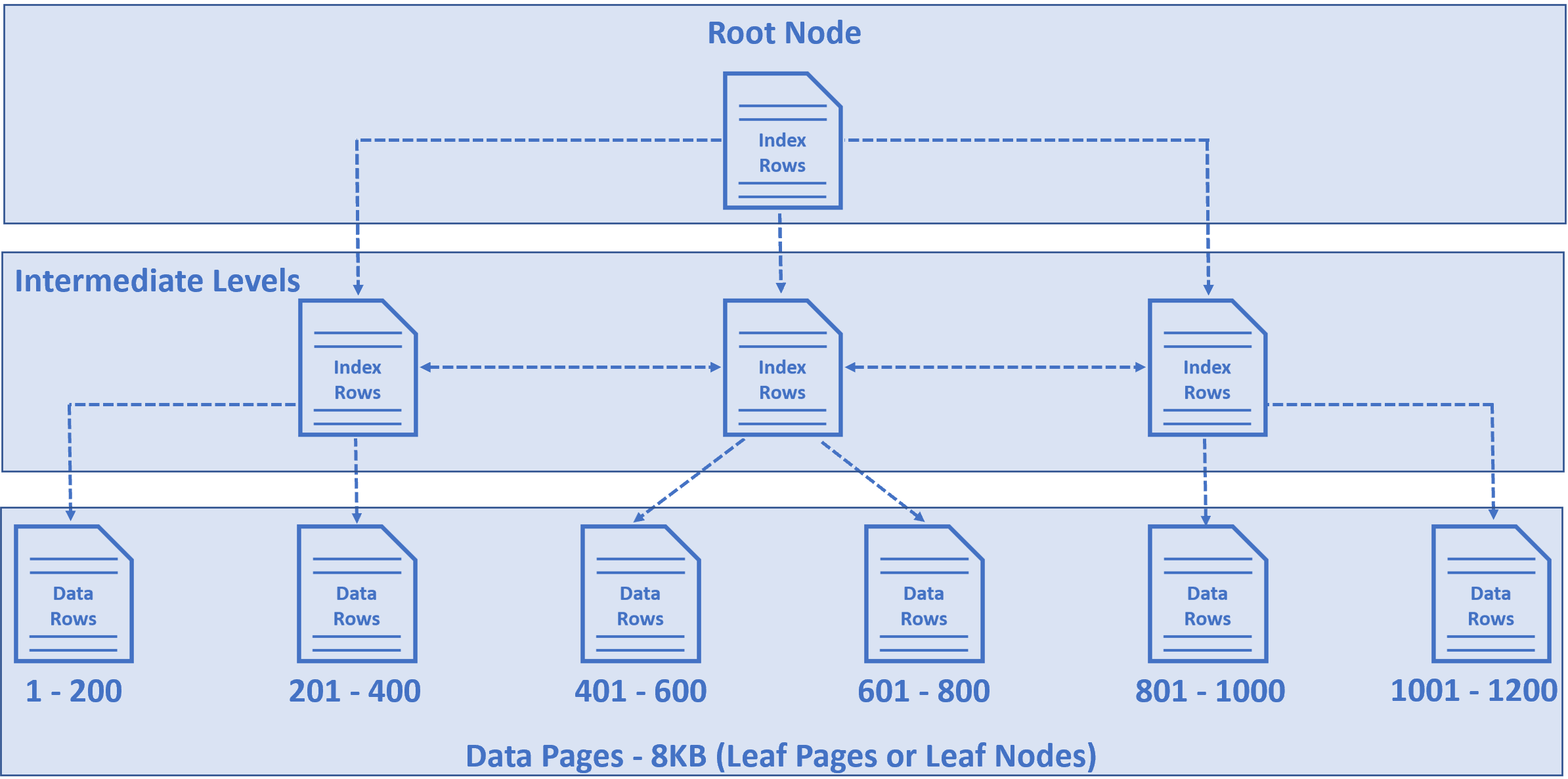

上图B-tree里最底端的节点叫做数据页或者树的叶子节点,这些叶子节点里存放了表的数据。
数据页默认大小是8k,也即是说数据页能存放表的几行数据依赖于行数据的大小。
从示意图里可以看到第一个数据页存放1-200行数据,而第二页存放201-400依次类推。
B-tree的顶上的节点叫做根节点。
跟节点和叶子节点直接的叫做中间节点,根节点和中间节点存放索引行。
在每个索引行里都包含一个主键(如这里的Employeeid)、一个指向中间节点和叶子节点的指针。
B-Tree遍历示意
以通过员工号查询员工信息为例,我看下B-tree是怎么工作的。语句见下:
select * from Employees where EmployeeId = 1189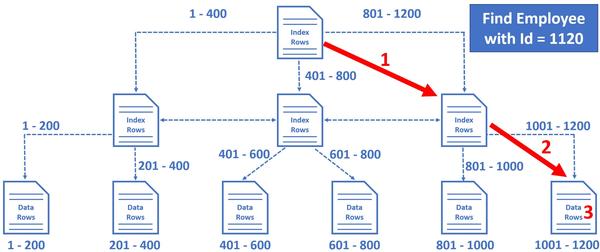

1 数据库引擎首先从数据的根节点开始遍历,因为我们的查询条件是Employeeid=1189,它属于索引行801-1200所在的范畴。
2 然后再从1里的子节点锁定Employeeid走右边的分支即属1001-1200的范畴。
3 最后从叶子节点对应的1001-1200的数据页里找到数据。
索引维护介绍
索引碎片
当索引中页面的逻辑顺序与数据文件中的物理顺序不匹配时,就会发生碎片。因为索引碎片会影响查询的性能,所以有时需要做索引重建。
1 索引碎片仅影响索引扫描和范围扫描的效率,对索引查找没有任何影响。
2 查询优化器不受碎片,不论是高碎片还是低碎片生成的计划都是相同的。
3 可以通过sys.dm_db_index_physical_stats 动态函数查看索引碎片情况。
SELECT a.object_id, a.index_id, name, avg_fragmentation_in_percent, fragment_count,
avg_fragment_size_in_pages
FROM sys.dm_db_index_physical_stats (DB_ID('ShenLiang2025'),
OBJECT_ID('EMPLOYEES'), NULL, NULL, NULL) AS a
JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id

索引重建
索引重建见如下语句:
--1重建指定索引
ALTER INDEX IX_EMP_NAME ON EMPLOYEES REBUILD;
--2 重建表里所有索引
ALTER INDEX ALL ON dbo.EMPLOYEES REBUILD文章被以下专栏收录
