
机器学习工程 - 如何进行模型部署

概述
对于一个机器学习模型来说,完成训练过程通常并不意味着结束,真正的挑战才真正开始。从这张经典的机器学习系统的模块图来看,模型代码只占很小一部分,作为一名合格的数据科学家,理应掌握整个机器学习的工作流程,模型服务部署是其中一个十分重要的环节,因为只有当完成了模型部署,才能真正为业务创造价值。
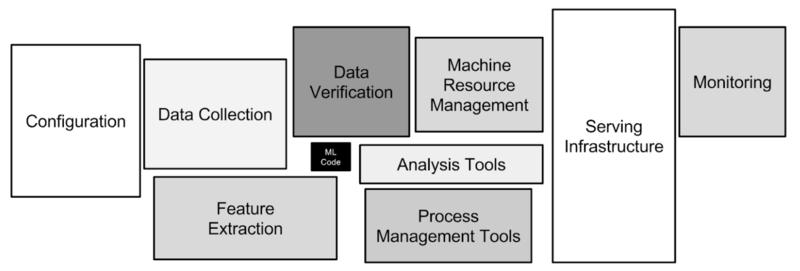

因此这个系列就来学习部署模型的简单系统架构设计,对于机器学习的系统设计来说,有两个需要考虑的关键点,模型持久化方式和模型部署架构。
模型持久化(Model persistence)
模型持久化的意思是当我们训练完一个模型以后,用一种特定的方式将模型训练结果保存下来,以便在应用中直接调用,模型持久化的格式基本分为以下几种:
- python专有格式pickle
- 通用交换格式(如PMML/ONNX)
- 第三方机器学习流程框架(如MLflow)
对于使用python搭建的机器模型,最简单的方式是直接使用官方库将模型储存为pickle格式,使用时再进行加载。这种方式优势在于简单便捷,缺点是兼容性较差,首先pickle格式只能用于python,当你的生产环境需要其他语言时,则无法直接调用。其次pickle的序列化和反序列化过程也和python版本有关,切换python版本后可能会导致解析失败。
因此这就引入了第二种通用交换格式,常见的两种格式是 Open Neural Network Exchange(ONNX)和 Predictive Model Markup Language(PMML)。使用通用格式的好处是不受语言和版本的限制,从模型可重复性和质量控制角度来看,是一种更优的格式,缺点是需要进行额外的格式转换。幸好有一些第三方库提供了格式转换的功能,以机器学习包sklearn为例,目前 sklearn-onnx和 sklearn2pmml 可以用来进行格式转换。
第三种方式使用第三方机器学习流程框架进行模型部署,框架已经为我们做了部署流程的基础工作,使我们只用把精力放在模型上即可。
先留一个站位坑,之后填补模型持久化的具体操作。
模型部署架构
模型部署涉及到当我们已经拥有了一个模型以后,用户如何使用来预测新数据,模型部署方案的选择是便捷性和灵活性之间的权衡。按照从简单到复杂,有四种通用的部署方式。
- 离线预测
- 模型内嵌于应用
- 以API方式发布
- 实时推送模型数据
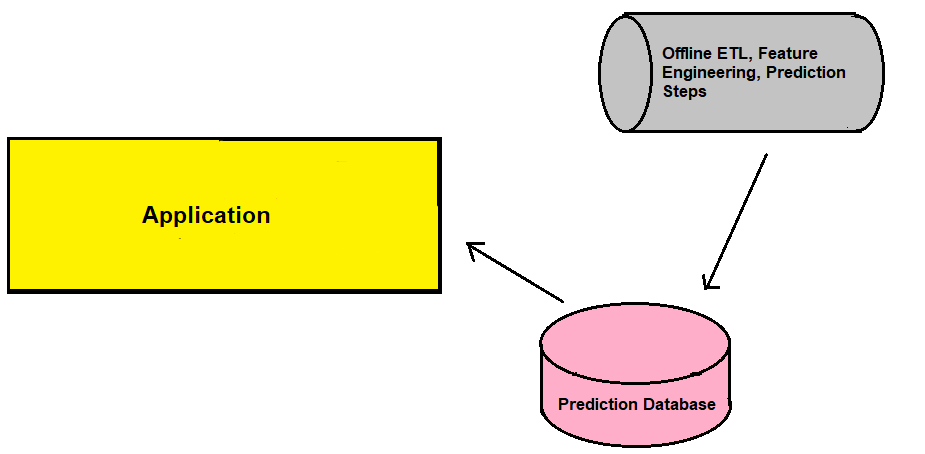
第一种方式最简单,也是唯一一种离线部署的方式,有点像通常的ETL流程,设置定时任务每天定期收集完新数据并进行预测,之后写入数据库中供查询使用。这种方式适用于对实时性要求不高的场景。

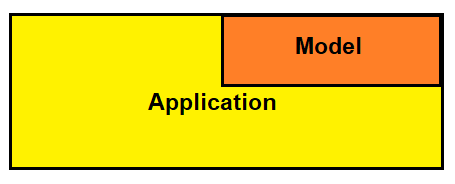
第二种方式是模型内嵌于应用,例如你已经有了一个完整的应用,此时模型时作为应用的一个部分(或功能)发布,这种方式虽然可以做到实时预测,但是模型的更新较为麻烦,涉及到整个应用的部署,以及不同部分之间的兼容性。

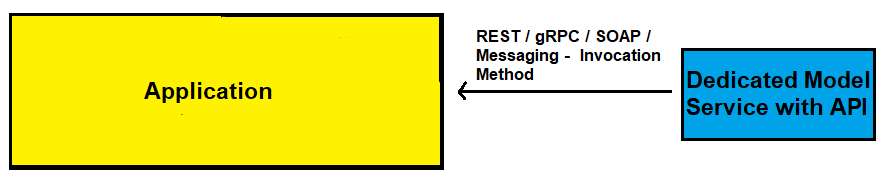
第三种方式是以API的形式发布,通过这种方式部署最大的好处是将模型侧和应用侧分离开了,扩展性和维护性都得到了提升,缺点是结构更复杂了,需要专门维护API接口和其通信过程。

第四种方式最为复杂,将模型以类似数据的方式发布到流平台(如kafka),应用侧以消费模型的方式进行模型的调用和预测,这种方式几乎可以做到模型的无缝升级和切换,但代价是需要额外维护一个流平台架构。
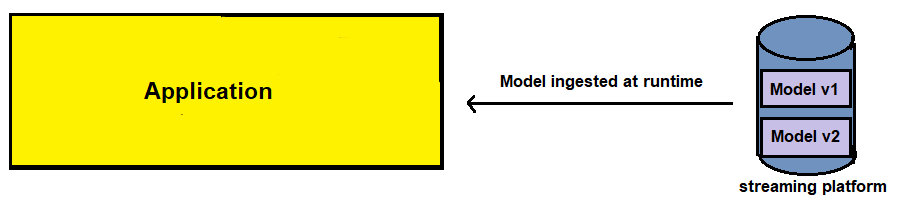

综上而言,第三种方式在简单性和灵活性之间取到了不错的平衡点,也是很多时候会选择的一种方式。
再留一个站位坑,之后填补第三种方案搭建API的具体操作。
参考资料
- https://towardsdatascience.com/4-machine-learning-system-architectures-e65e33481970
文章被以下专栏收录
