
强化学习采样频率和更新频率的关系探讨


# 强化学习采样频率和更新频率的关系探讨
前言:
这个问题很多做强化的朋友都遇到过,今天中午答应群友今天要写出来,尽管少了几组实验没做,但是先勉强凑出一个文档解析吧。
并且可能因为我关键词没找对,我只在spinningup的代码中,看到了一个update every的关键词,但是搜索起来,好像也没有太多帖子和论文(只看到了rainbow那篇论文是4个agent step,更新一次网络)讨论这个,如果有人看到过类似的帖子,或者论文,欢迎告知!
问题起源:
在经典的论文伪代码和SpinningUp这种代码库中,会出现这样的一个经典问题:agent和环境交互一次,policy就要update一次。
DQN的伪代码:


DDPG 也是这样:


甚至TD3都是:


SpinningUp关于这部分的注释:
Number of env interactions that should elapse between gradient descent updates. Note: Regardless of how long you wait between updates, the ratio of env steps to gradient steps is locked to 1. 即openai团队的人认为应该绑定起来。采样多少次,更新多少次。
即采样频率和策略网络更新的频率绑定一致。但是实际上我们的代码中并不会采取这样的操作。
潜在的缺陷--限制了batch-size的设定:
如果我们的buffer的大小是常用的1e6,batch-size是256,采样一次,更新一次,那么对于某一个具体的transition来说,它进入一个先入先出的buffer中,从它刚进入的那一个时间步,它被随机采样的概率是多少?P=batch_size/buffer_size=256/1e6.
那么它在整个buffer的“生存周期”中,它总的被采样次数的期望是多少?
当update_every_n_steps=1时,即交互获取1个样本,更新1次网络;
当update_every_n_steps=2时,即交互获取2个样本,更新1次网络;
E=P*buffer_size/(update_every_n_steps)=batch_size/update_every_n_steps!
问题一目了然了,如果采样次数和更新次数绑定,即update_every_n_steps=1,那么一个transition被策略网络利用的次数,就等于batch-size了!
这样如果你想调大batch-size,就会发现,有时候batch-size值越大,性能越下降!
这个性能下降,有两个可能,一个是这个 博客里面提到的:batch-size增加了会让梯度更加平滑,噪声波动没有那么大,但是也可能会陷入局部最优。
也有另外一个可能, 是因为单一数据被更新的次数太多,产生了某种类似于“过拟合”的效果。
我下面贴一下我之前的比较简单的实验结果,可以证明绑定的情况下,更新次数增加,确实会降低性能。
下周会丰富一下实验,解绑之后,单纯的batch-size的增加,是否在一定程度上增加性能。
也许可以在实验中,为大家找到一个比较好的参数:单个样本的更新次数。
如果有人对这个点感兴趣的话,欢迎合作和讨论~
updata_every=1的情况下,batch-size的增加会性能降低:
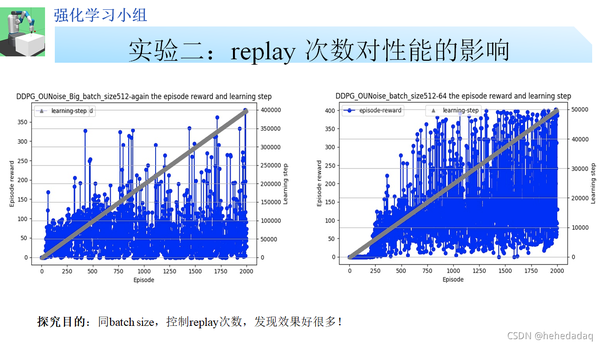

左右图的batch-size都是512,左边网络的更新频次是512,右边是64,性能就上去了。如果这个实验结果具有普适性的话,那么可以说明在大的batch-size情况下,降低更新频次,可以提高性能。
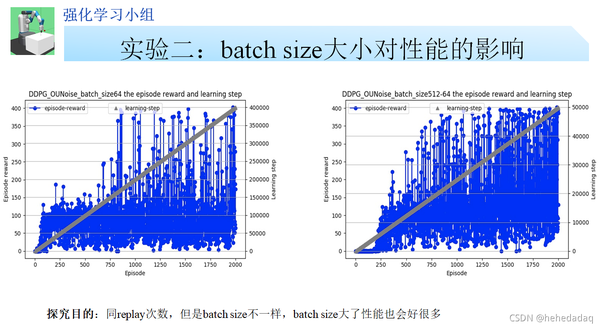

左右图的更新频次都是64,左边网络的batch-size是64,右边是512,性能就上去了。如果这个实验结果具有普适性的话,那么可以说明在一定的更新频次下,增加batch-size,可以提高性能。
总结:
目前我的实验经验模糊的告诉我,batch-size可以适当的调大一点,单个样本更新的频次可以降低一些。
联系方式:
ps: 欢迎做强化的同学加群一起学习:
深度强化学习-DRL:799378128 Mujoco建模:818977608 欢迎玩其他物理引擎的同学一起玩耍~
欢迎关注知乎帐号: 未入门的炼丹学徒
CSDN帐号: https://blog.csdn.net/hehedadaq
极简spinup+HER+PER代码实现: https://github.com/kaixindelele/DRLib
文章被以下专栏收录
