
【论文速递11-5】领域自适应方向优质论文与代码

Domain Adaptation - 领域自适应
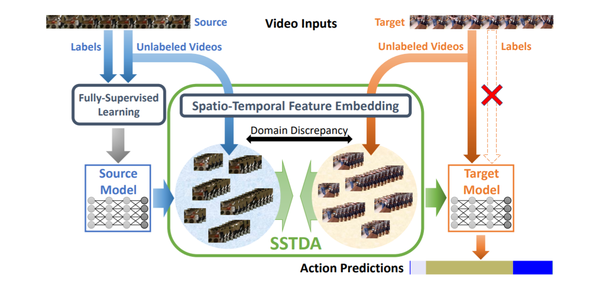
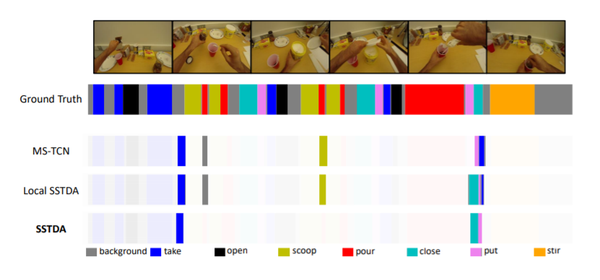
1. 【Domain Adaptation】Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
【领域自适应】具有联合自我监督时域自适应的动作分割

作者:Min-Hung Chen, Baopu Li, Yingze Bao, Ghassan AlRegib, Zsolt Kira
链接: https://arxiv.org/abs/2003.02824v3
代码: https://github.com/cmhungsteve/SSTDA
英文摘要:
Despite the recent progress of fully-supervised action segmentation techniques, the performance is still not fully satisfactory. One main challenge is the problem of spatiotemporal variations (e.g. different people may perform the same activity in various ways). Therefore, we exploit unlabeled videos to address this problem by reformulating the action segmentation task as a cross-domain problem with domain discrepancy caused by spatio-temporal variations. To reduce the discrepancy, we propose Self-Supervised Temporal Domain Adaptation (SSTDA), which contains two self-supervised auxiliary tasks (binary and sequential domain prediction) to jointly align cross-domain feature spaces embedded with local and global temporal dynamics, achieving better performance than other Domain Adaptation (DA) approaches. On three challenging benchmark datasets (GTEA, 50Salads, and Breakfast), SSTDA outperforms the current state-of-the-art method by large margins (e.g. for the F1@25 score, from 59.6% to 69.1% on Breakfast, from 73.4% to 81.5% on 50Salads, and from 83.6% to 89.1% on GTEA), and requires only 65% of the labeled training data for comparable performance, demonstrating the usefulness of adapting to unlabeled target videos across variations.
中文摘要:
尽管最近全监督动作分割技术取得了进展,但其性能仍不能完全令人满意。一个主要挑战是时空变化问题(例如,不同的人可能以不同的方式执行相同的活动)。因此,我们利用未标记的视频通过将动作分割任务重新定义为跨域问题来解决这个问题,该问题具有由时空变化引起的域差异。为了减少差异,我们提出了自监督时域自适应(SSTDA),它包含两个自监督辅助任务(二进制和顺序域预测),以联合对齐嵌入局部和全局时间动态的跨域特征空间,从而实现更好的效果。性能优于其他领域适应(DA)方法。在三个具有挑战性的基准数据集(GTEA、50Salads和早餐)上,SSTDA大大优于当前最先进的方法(例如F1@25分数,从早餐的59.6%到69.1%,从73.4%在50Salads上达到81.5%,在GTEA上从83.6%到89.1%),并且只需要65%的标记训练数据即可获得可比的性能,这证明了适应跨变体的未标记目标视频的有用性。


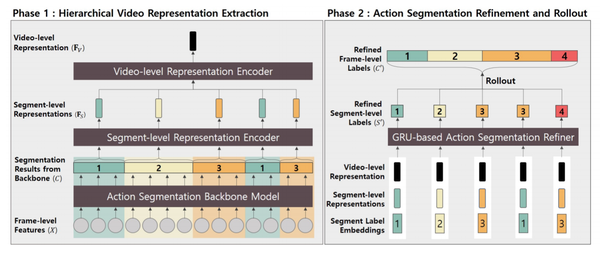
2. 【Domain Adaptation】Refining Action Segmentation With Hierarchical Video Representations
【领域自适应】使用分层视频表示细化动作分割

作者:Hyemin Ahn, Dongheui Lee
链接:
https://openaccess.thecvf.com/content/ICCV2021/html/Ahn_Refining_Action_Segmentation_With_Hierarchical_Video_Representations_ICCV_2021_paper.html
代码: https://github.com/cotton-ahn/hasr_iccv2021
英文摘要:
In this paper, we propose Hierarchical Action Segmentation Refiner (HASR), which can refine temporal action segmentation results from various models by understanding the overall context of a given video in a hierarchical way. When a backbone model for action segmentation estimates how the given video can be segmented, our model extracts segment-level representations based on frame-level features, and extracts a video-level representation based on the segment-level representations. Based on these hierarchical representations, our model can refer to the overall context of the entire video, and predict how the segment labels that are out of context should be corrected. Our HASR can be plugged into various action segmentation models (MS-TCN, SSTDA, ASRF), and improve the performance of state-of-the-art models based on three challenging datasets (GTEA, 50Salads, and Breakfast). For example, in 50Salads dataset, the segmental edit score improves from 67.9% to 77.4% (MS-TCN), from 75.8% to 77.3% (SSTDA), from 79.3% to 81.0% (ASRF). In addition, our model can refine the segmentation result from the unseen backbone model, which was not referred to when training HASR. This generalization performance would make HASR be an effective tool for boosting up the existing approaches for temporal action segmentation.
中文摘要:
在本文中,我们提出了分层动作分割细化器(HASR),它可以通过以分层方式理解给定视频的整体上下文来细化来自各种模型的时间动作分割结果。当用于动作分割的主干模型估计给定视频的分割方式时,我们的模型根据帧级特征提取段级表示,并根据段级表示提取视频级表示。基于这些分层表示,我们的模型可以参考整个视频的整体上下文,并预测应该如何纠正脱离上下文的片段标签。我们的HASR可以插入各种动作分割模型(MS-TCN、SSTDA、ASRF),并提高基于三个具有挑战性的数据集(GTEA、50Salads和早餐)的最先进模型的性能。例如,在50Salads数据集中,分段编辑分数从67.9%提高到77.4%(MS-TCN),从75.8%提高到77.3%(SSTDA),从79.3%提高到81.0%(ASRF)。此外,我们的模型可以从看不见的主干模型中细化分割结果,在训练HASR时没有提到。这种泛化性能将使HASR成为提升现有时间动作分割方法的有效工具。


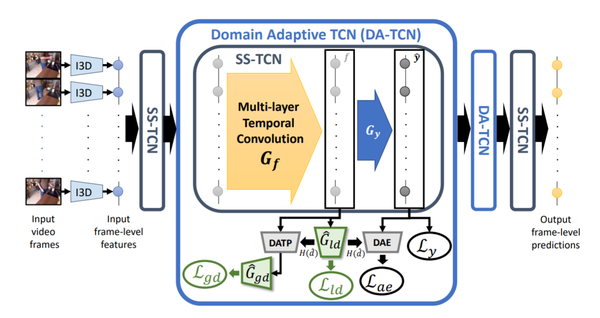
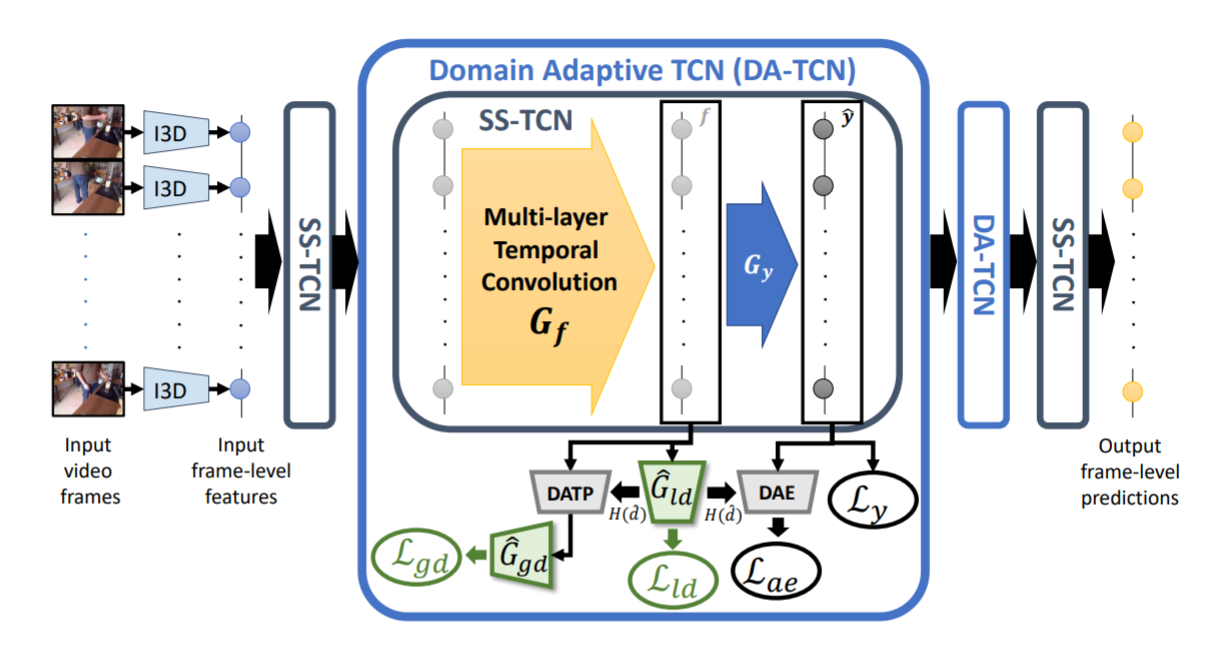
3. 【Domain Adaptation】Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
【领域自适应】具有联合自我监督时域自适应的动作分割
作者:Min-Hung Chen, Baopu Li, Yingze Bao, Ghassan AlRegib, Zsolt Kira
链接: https://arxiv.org/abs/2003.02824v3
代码: https://github.com/cmhungsteve/SSTDA
英文摘要:
Despite the recent progress of fully-supervised action segmentation techniques, the performance is still not fully satisfactory. One main challenge is the problem of spatiotemporal variations (e.g. different people may perform the same activity in various ways). Therefore, we exploit unlabeled videos to address this problem by reformulating the action segmentation task as a cross-domain problem with domain discrepancy caused by spatio-temporal variations. To reduce the discrepancy, we propose Self-Supervised Temporal Domain Adaptation (SSTDA), which contains two self-supervised auxiliary tasks (binary and sequential domain prediction) to jointly align cross-domain feature spaces embedded with local and global temporal dynamics, achieving better performance than other Domain Adaptation (DA) approaches. On three challenging benchmark datasets (GTEA, 50Salads, and Breakfast), SSTDA outperforms the current state-of-the-art method by large margins (e.g. for the F1@25 score, from 59.6% to 69.1% on Breakfast, from 73.4% to 81.5% on 50Salads, and from 83.6% to 89.1% on GTEA), and requires only 65% of the labeled training data for comparable performance, demonstrating the usefulness of adapting to unlabeled target videos across variations.
中文摘要:
尽管最近全监督动作分割技术取得了进展,但其性能仍不能完全令人满意。一个主要挑战是时空变化问题(例如,不同的人可能以不同的方式执行相同的活动)。因此,我们利用未标记的视频通过将动作分割任务重新定义为跨域问题来解决这个问题,该问题具有由时空变化引起的域差异。为了减少差异,我们提出了自监督时域自适应(SSTDA),它包含两个自监督辅助任务(二进制和顺序域预测),以联合对齐嵌入局部和全局时间动态的跨域特征空间,从而实现更好的效果。性能优于其他领域适应(DA)方法。在三个具有挑战性的基准数据集(GTEA、50Salads和早餐)上,SSTDA大大优于当前最先进的方法(例如F1@25分数,从早餐的59.6%到69.1%,从73.4%在50Salads上达到81.5%,在GTEA上从83.6%到89.1%),并且只需要65%的标记训练数据即可获得可比的性能,这证明了适应跨变体的未标记目标视频的有用性。

4. 【Domain Adaptation】Unsupervised Bidirectional Cross-Modality Adaptation via Deeply Synergistic Image and Feature Alignment for Medical Image Segmentation
【领域自适应】通过深度协同图像和特征对齐进行无监督双向跨模态适应,用于医学图像分割


作者:Cheng Chen, Qi Dou, Hao Chen, Jing Qin, Pheng Ann Heng
链接:
https://openaccess.thecvf.com/content/ICCV2021/html/Ahn_Refining_Action_Segmentation_With_Hierarchical_Video_Representations_ICCV_2021_paper.html
代码: https://github.com/cotton-ahn/hasr_iccv2021
英文摘要:
Unsupervised domain adaptation has increasingly gained interest in medical image computing, aiming to tackle the performance degradation of deep neural networks when being deployed to unseen data with heterogeneous characteristics. In this work, we present a novel unsupervised domain adaptation framework, named as Synergistic Image and Feature Alignment (SIFA), to effectively adapt a segmentation network to an unlabeled target domain. Our proposed SIFA conducts synergistic alignment of domains from both image and feature perspectives. In particular, we simultaneously transform the appearance of images across domains and enhance domain-invariance of the extracted features by leveraging adversarial learning in multiple aspects and with a deeply supervised mechanism. The feature encoder is shared between both adaptive perspectives to leverage their mutual benefits via end-to-end learning. We have extensively evaluated our method with cardiac substructure segmentation and abdominal multi-organ segmentation for bidirectional cross-modality adaptation between MRI and CT images. Experimental results on two different tasks demonstrate that our SIFA method is effective in improving segmentation performance on unlabeled target images, and outperforms the state-of-the-art domain adaptation approaches by a large margin.
中文摘要:
无监督域自适应越来越引起医学图像计算的兴趣,旨在解决深度神经网络在部署到具有异构特征的不可见数据时性能下降的问题。在这项工作中,我们提出了一种新的无监督域适应框架,称为协同图像和特征对齐(SIFA),以有效地使分割网络适应未标记的目标域。我们提出的SIFA从图像和特征的角度进行域的协同对齐。特别是,我们通过在多个方面利用对抗性学习和深度监督机制,同时跨域转换图像的外观并增强提取特征的域不变性。特征编码器在两个自适应视角之间共享,以通过端到端学习利用它们的共同利益。我们已经广泛评估了我们的方法,包括心脏亚结构分割和腹部多器官分割,用于MRI和CT图像之间的双向跨模态适应。在两个不同任务上的实验结果表明,我们的SIFA方法在提高未标记目标图像的分割性能方面是有效的,并且在很大程度上优于最先进的域适应方法。


5. 【Domain Adaptation】Universal Domain Adaptation through Self Supervision
【领域自适应】通过自我监督实现通用域适应


作者:Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Kate Saenko
链接: https://arxiv.org/abs/2002.07953v3
代码: https://github.com/VisionLearningGroup/DANCE
英文摘要:
Unsupervised domain adaptation methods traditionally assume that all source categories are present in the target domain. In practice, little may be known about the category overlap between the two domains. While some methods address target settings with either partial or open-set categories, they assume that the particular setting is known a priori. We propose a more universally applicable domain adaptation framework that can handle arbitrary category shift, called Domain Adaptative Neighborhood Clustering via Entropy optimization (DANCE). DANCE combines two novel ideas: First, as we cannot fully rely on source categories to learn features discriminative for the target, we propose a novel neighborhood clustering technique to learn the structure of the target domain in a self-supervised way. Second, we use entropy-based feature alignment and rejection to align target features with the source, or reject them as unknown categories based on their entropy. We show through extensive experiments that DANCE outperforms baselines across open-set, open-partial and partial domain adaptation settings.
中文摘要:
无监督域适应方法传统上假设所有源类别都存在于目标域中。在实践中,关于两个域之间的类别重叠可能知之甚少。虽然一些方法使用部分或开放集类别解决目标设置,但它们假设特定设置是先验已知的。我们提出了一个更普遍适用的域适应框架,可以处理任意类别转移,称为通过熵优化(DANCE)的域自适应邻域聚类。DANCE结合了两个新颖的想法:首先,由于我们不能完全依赖源类别来学习区分目标的特征,因此我们提出了一种新颖的邻域聚类技术,以自监督的方式学习目标域的结构。其次,我们使用基于熵的特征对齐和拒绝来将目标特征与源对齐,或者根据它们的熵将它们拒绝为未知类别。我们通过广泛的实验表明,DANCE在开放集、开放部分和部分域适应设置中优于基线。

AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索【AIandR艾尔】关注我们,❤biubiubiu~