树形动态规划详解

作为动态规划问题中非常重要的一类,树形动态规划一般用于处理求树上最优值的问题。
在计算机领域中的树是这样一种数据结构:
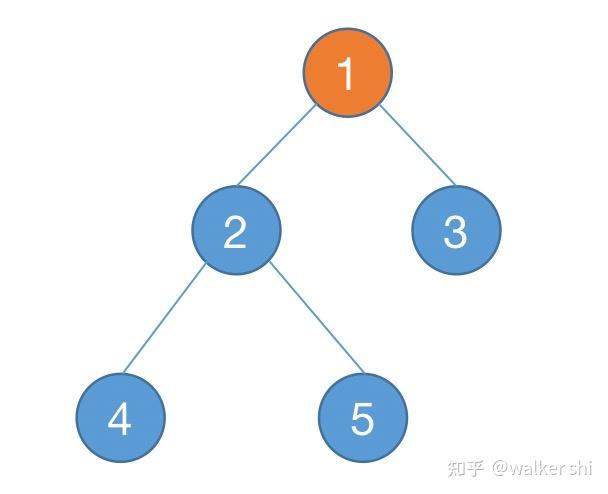

树有一个根(上图中的 1 号点),对于所有非根节点,它都有唯一的父亲(比如说 2 号点的父亲是 1 号点,我们把 2 号点称为 1 号点的儿子),这样的结构被称为有根树。我们在所有非根节点和它的父亲之间连边,如果 i 号点在 j 号点到根结点的路径上,则称 i 号点为 j 号点的祖先(i 号点是 j 号点的父亲的父亲的父亲的....父亲),j 号点为 i 号点的子孙(j 号点是 i 号点的儿子的儿子的儿子的....儿子)。叶子结点指的是没有任何儿子的点。有时候我们会讲以 i 号点为根的子树,这句话指的是包含 i 号点和它所有子孙的一个子结构(以 2 号点为根的子树包含 2 号点、4 号点和 5 号点)。
与有根树对应的还有无根树的概念,今天的内容主要围绕有根树展开,我们会在下一章中介绍与无根树有关的动态规划问题。
让我们先来看这样一个题:
统计人数
一家公司里有 n(2≤n≤100000) 个员工,除了公司 CEO 外,每个人都有一个直接上司。我们想知道,每个人的团队(包括他/她自己、他/她的直接下属和间接下属)一共有多少人?CEO 是公司的 1 号员工。
Daimayuan Online Judge
首先我们观察到,公司的上下级关系其实是一个树形结构,CEO 是树的根,某个员工的直接上司是他/她在树形结构中的父亲。i 号员工的团队里有多少人,其实等于以 i 为根的子树中包含多少个点。例如,假设公司有 5 个员工,2、3、4、5 号员工的直接上司分别是 1、1、2、2,公司的上下级关系和上面例子中的图是一样的。1、2、3、4、5 号员工的团队大小分别是 5、3、1、1、1。
我们怎么来解决这个问题呢?现在我们要计算 i 号员工的团队里有多少人,除了他/她自己之外,每个员工一定在他/她的某个直接下属的团队里,所以 i 号员工的团队人数等于他/她的每个直接下属的团队人数的总和 + 1(加的 1 表示的是他/她自己)。例如,1 号员工有 2 个直接下属 2 号员工和 3 号员工,他们的团队里分别有 3 个和 1 个人,所以 1 号员工的团队里一共有 3 + 1 + 1 = 5 个人。
定义 size[i] 表示 i 号员工的团队里有多少人,有 size[i] = \sum_{j \in son(i)} size[j] + 1 ,其中 son(i) 表示 i 号员工的直接下属的集合。
接下来,我们一起来研究研究怎么实现上面的想法。一般来说,我们有深度优先搜索(dfs)和宽度优先搜索(bfs)两种实现树形动态规划的方法(由于本文主要为了介绍树形动态规划,在这里就不展开介绍 dfs 和 bfs啦!)。
深度优先搜索(DFS)
dfs 的方法本质上是一种递归的写法,其核心思想是为了求出 i 号员工的团队人数,我们先递归求出他/她的所有直接下属 j 的团队人数,然后把这些数字加起来再加一,就是 i 号员工的团队人数。在上面的例子中,为了求出 1 号员工的团队人数,首先我们需要先求出 2 号员工和 3 号员工的团队人数。为了求出 2 号员工的团队人数,我们需要先求出 4 号员工和 5 号员工的团队人数。碰到叶子结点时终止递归,他/她的团队人数等于 1。
#include <bits/stdc++.h>
using namespace std;
struct node {
node *next;
int where;
} *first[100001], a[100001];
int n, l, size[100001];
inline void makelist(int x, int y) {
a[++l].where = y;
a[l].next = first[x];
first[x] = &a[l];
}
inline void solve(int i) {
size[i] = 1;
for (node *x = first[i]; x; x = x->next) {
solve(x->where);
size[i] += size[x->where];
}
}
int main() {
scanf("%d", &n);
memset(first, 0, sizeof(first));
l = 0;
for (int i = 2; i <= n; i++) {
int x;
scanf("%d", &x);
makelist(x, i);
}
solve(1);
for (int i = 1; i <= n; i++)
printf("%d ", size[i]);
}
让我们一起来看看代码!
struct node {
node *next;
int where;
} *first[100001], a[100001];
inline void makelist(int x, int y) {
a[++l].where = y;
a[l].next = first[x];
first[x] = &a[l];
}
储存树形结构有很多种不同的方法,在这里我们选择使用链表来完成这项工作(也可以使用 vector 来存),其中 makelist(x, y) 的作用是连一条从 x 到 y 的边。如果大家对链表还不太熟悉的话,可以先自己研究研究。
for (int i = 2; i <= n; i++) {
int x;
scanf("%d", &x);
makelist(x, i);
}
我们读入每个点的父亲(直接上司),在父亲和这个点之间连边。
inline void solve(int i) {
size[i] = 1;
for (node *x = first[i]; x; x = x->next) {
solve(x->where);
size[i] += size[x->where];
}
}
接下来我们通过 solve(i) 递归求出 i 号员工的团队里多少人,为了计算出这个数值,我们需要先求出他/她的所有直接下属的团队里有多少人。
for (int i = 1; i <= n; i++)
printf("%d ", size[i]);
最后,size[i] 就是答案—— i 号员工的团队里多少人。
由于在递归的过程每个点都只会算一次,所以总的时间复杂度为 O(n)。
宽度优先搜索(BFS)
和 dfs 对应的,bfs 也可以被用来处理树上问题。我们先从 CEO 出发做一遍 bfs,在 bfs 序(我们把在 bfs 过程中访问到的点按访问顺序放入这个序列里) 中,所有员工一定在他/她的直接下属前面(也就是说,他/她一定比他/她的直接下属先被 bfs 到),于是我们可以按 bfs 序从大到小的顺序,一个个算每个员工的团队人数。在计算某个员工的团队人数之前,他/她的直接下属的团队人数都已经被算出来了。在上面的例子中,一个合法的 bfs 序为 1 2 3 4 5,我们可以按照 5 4 3 2 1 的顺序计算每个员工的团队人数。
#include <bits/stdc++.h>
using namespace std;
struct node {
node *next;
int where;
} *first[100001], a[100001];
int n, l, size[100001], c[100001];
inline void makelist(int x, int y) {
a[++l].where = y;
a[l].next = first[x];
first[x] = &a[l];
}
int main() {
scanf("%d", &n);
memset(first, 0, sizeof(first));
l = 0;
for (int i = 2; i <= n; i++) {
int x;
scanf("%d", &x);
makelist(x, i);
}
c[1] = 1;
for (int k = 1, l = 1; l <= k; l++) {
int m = c[l];
for (node *x = first[m]; x; x = x->next)
c[++k] = x->where;
}
for (int i = n; i; --i) {
int m = c[i];
size[m] = 1;
for (node *x = first[m]; x; x = x->next)
size[m] += size[x->where];
}
for (int i = 1; i <= n; i++)
printf("%d ", size[i]);
}
我们来看看代码。
c[1] = 1;
for (int k = 1, l = 1; l <= k; l++) {
int m = c[l];
for (node *x = first[m]; x; x = x->next)
c[++k] = x->where;
}
c 数组用来存储 bfs 序。
for (int i = n; i; --i) {
int m = c[i];
size[m] = 1;
for (node *x = first[m]; x; x = x->next)
size[m] += size[x->where];
}
我们按 bfs 序从大到小的顺序计算每个员工的团队人数。
因为每个点都只会算到一次,所以 bfs 的时间复杂度也是 O(n) 的。
在初步介绍了树的两种处理方法后,我们再来看看这样一个题:
没有上司的舞会
一家公司里有 n(2≤n≤100000) 个员工,除了公司 CEO 外,每个人都有一个直接上司。今天公司要办一个舞会,为了大家玩得尽兴,如果某个员工的直接上司来了,他/她就不想来了。第 i 个员工来参加舞会会为大家带来 a_i(1≤a_i≤100000) 点快乐值。请求出快乐值最大是多少。CEO 是公司的 1 号员工。
Daimayuan Online Judge
这题怎么做呢?我们先考虑 i 号员工的团队(以 i 为根的子树),他/她有参加/不参加舞会两种选择,我们能不能把两种情况下整个 i 号员工的团队的最大快乐值都算出来呢?
i 号员工的团队由两部分组成——每个直接下属的团队以及他自己。
如果他/她参加舞会,我们考虑某个直接下属 j 号员工的团队。由于不想碰到自己的直接上司,j 号员工不会参加舞会。在 j 号员工不参加舞会的条件下, j 号员工的团队里的其他人参不参加舞会是不关键的。也就是说,我们只要知道在 j 号员工不参加舞会的条件下, j 号员工的团队的最大快乐值是几就可以啦!于是,我们只要把考虑每个直接下属 j 号员工的团队 ,他/她不参加舞会的条件下,他/她的团队的最大快乐值加起来,然后再加上 a[i](i 号员工参加了,所以要把他/她的快乐值加进来),就是他/她参加舞会时团队的最大快乐值啦!
如果他/她不参加舞会,我们仍然考虑某个直接下属 j 号员工的团队。j 号员工既可以参加舞会,也可以不参加舞会,于是我们选择两种情况中 j 号员工的团队快乐值较大的一个。我们把考虑每个直接下属 j 号员工的团队时对应的值加起来就是他/她不参加舞会时团队的最大快乐值啦!
接着,我们就可以用动态规划的思想来解决这个问题啦!
最优子结构:为了计算考虑 i 号员工的团队的情况,我们需要先算出考虑所有满足 j 是 i 的直接下属的 j 号员工的团队的情况;
无后效性:我们只关心考虑 i 号员工的团队,他/她不参加/参加的情况下快乐值最大是几,不关心团队中具体哪些员工参加了舞会;
状态:定义 f[i][0] 表示考虑 i 号员工的团队,他/她不参加的情况下的最大快乐值,定义 f[i][1] 表示考虑 i 号员工的团队,他/她参加的情况下的最大快乐值;
转移:根据上面的分析,有
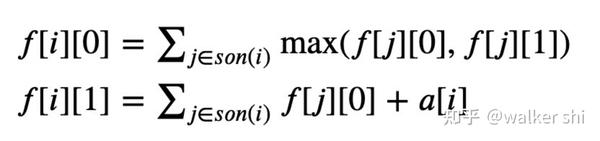

让我们看看代码!
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <ctime>
#include <cmath>
#include <iostream>
#include <algorithm>
using namespace std;
struct node {
node *next;
int where;
} *first[100001], a[100001];
int n, l, c[100001];
long long f[100001][2];
inline void makelist(int x, int y) {
a[++l].where = y;
a[l].next = first[x];
first[x] = &a[l];
}
inline void solve(int i) {
f[i][0] = 0; f[i][1] = c[i];
for (node *x = first[i]; x; x = x->next) {
solve(x->where);
f[i][0] += max(f[x->where][0], f[x->where][1]);
f[i][1] += f[x->where][0];
}
}
int main() {
scanf("%d", &n);
for (int i = 2; i <= n; i++) {
int x;
scanf("%d", &x);
makelist(x, i);
}
for (int i = 1; i <= n; i++)
scanf("%d", &c[i]); // 这里的 c[i] 指的是题目中的 a[i],也就是 i 号员工参加舞会带来的快乐值。
solve(1);
printf("%lld\n", max(f[1][0], f[1][1]));
}
我们采用 dfs 的写法,整个代码的核心是 solve 函数。
inline void solve(int i) {
f[i][0] = 0; f[i][1] = c[i];
for (node *x = first[i]; x; x = x->next) {
solve(x->where);
f[i][0] += max(f[x->where][0], f[x->where][1]);
f[i][1] += f[x->where][0];
}
}
solve(i) 计算的是考虑 i 号员工的团队时的情况,为了计算 f[i][0], f[i][1],我们先递归求出所有直接下属的情况。
printf("%lld\n", max(f[1][0], f[1][1]));
由于 1 号员工有参加/不参加两种选择,所以最后答案等于两种选择下快乐值较大的一个。
由于每个点只会算到一次,每次算的时候都是 O(1) 的(只进行了取最大值和加法两种操作),所以总的时间复杂度是 O(n) 的。
现在我们已经初步了解了基础的树形动态规划思想,接下来我们想把背包问题和树形动态规划问题结合,解决一类被称为树形背包的问题。在介绍树形背包之前,我们先来看看这样一个问题。
新的背包
有 n(1≤n≤500) 种物品要放到一个袋子里,袋子的总容量为 m(1≤m ≤500) ,每种物品都有 m 个,它们的体积都是 1,对于第 i 种物品,如果我们一共取了 j 个,会获得 w_{i, j}(1≤w_{i, j}≤1000) 的收益,问如何选择物品,使得在物品的总体积不超过 m 的情况下,获得最大的收益?请求出最大收益。
Daimayuan Online Judge
在之前的章节中,我们介绍了各类背包问题的解法,在此不再赘述。有兴趣的读者可以阅读 walker shi:27000字初级背包问题详解。
我们直接来解决这个问题。
状态:用 f[i][j] 表示考虑了前 i 种物品,总体积不超过 j 时的最大收益;
转移:为了计算 f[i][j] 的值,我们枚举第 i 种物品取了 k 个,从中选择收益最大的方案,有:
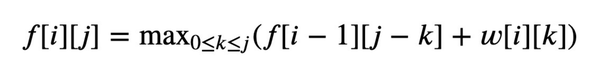

#include <bits/stdc++.h>
using namespace std;
int n, m, f[501][501], w[501][501];
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
scanf("%d", &w[i][j]);
for (int i = 1; i <= n; i++)
for (int j = 0; j <= m; j++)
for (int k = 0; k <= j; k++)
f[i][j] = max(f[i][j], f[i - 1][j - k] + w[i][k]);
printf("%d\n", f[n][m]);
}
我们按照 i 从小到大的顺序一步步考虑取了前 i 种物品时的情况。由于考虑了前 i 种物品时的状态只与考虑了前 i - 1 种物品时的状态有关,所以 j 是从小到大枚举还是从大到小枚举还是乱序枚举都是不关键的。
i 需要从 1 枚举到 n,j 需要从 0 枚举到 m,k 需要从 0 枚举到 j,时间复杂度是 O(nm^2) 的。
我们使用了一个 n*m 的数组 f,空间复杂度为 O(nm),我们能不能把 f 数组的大小从 n*m 优化到 m 呢?
答案当然是可以的,具体的思路详见 walker shi:27000字初级背包问题详解 中的“01 背包”做法四以及“多重背包1”。
#include <bits/stdc++.h>
using namespace std;
int n, m, f[501], w[501][501];
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
scanf("%d", &w[i][j]);
for (int i = 1; i <= n; i++)
for (int j = m; j >= 0; j--)
for (int k = 0; k <= j; k++)
f[j] = max(f[j], f[j - k] + w[i][k]);
printf("%d\n", f[m]);
}
再强调下,在这里,j 只能从大到小枚举。
于是,我们做完了前期准备工作,现在可以来看看树形背包问题啦!
没有上司的舞会 II
一家公司里有 n(1≤n≤500) 个员工,除了公司 CEO 外,每个人都有一个直接上司。今天公司要办一个舞会,为了大家玩得尽兴,如果某个员工的直接上司来了,他/她就不想来了。第 i 个员工来参加舞会会为大家带来 ai(1≤ai≤100000) 点快乐值。由于场地有大小限制,场地最多只能容纳 m (1≤m ≤n) 个人。请求出快乐值最大是多少。CEO 是公司的 1 号员工。
Daimayuan Online Judge
和“没有上司的舞会”相比,现在多了一个人数限制 m。当我们考虑 i 号员工的团队,除了要考虑他/她参不参加,还需要考虑他/她的团队中一共有多少人参加了舞会。在我们设计的状态中也需要加入一个新的维度—— i 号团队中参加舞会的人数。
状态:用 f[i][k][0] 表示考虑 i 号员工的团队,他/她的团队中一共有不超过 k 个人参加,他/她不参加的情况下的最大快乐值;用 f[i][k][1] 表示考虑 i 号员工的团队,他/她的团队中一共有不超过 k 个人参加,他/她参加的情况下的最大快乐值;
转移:回忆“没有上司的舞会“时的转移
现在我们相应的也要考虑 k —— 团队中参加舞会的人数。
当 i 固定的时候,对于所有的 k,我们先来考虑如何计算 f[i][k][1],也就是 i 号员工参加舞会的情况。考虑 i 号员工的某个直接下属 j 号员工,由于 i 号员工参加了,所以 j 号员工不会参加。j 号员工的团队中有不超过 1 人参加时的最大快乐值是 f[j][1][0],有不超过 2 人参加时的最大快乐值是 f[j][2][0],....,有不超过 l 人参加时的最大快乐值是 f[j][l][0]。这是不是和“新的背包”问题很像?
我们把 i 的每个直接下属 j 抽象成“新的背包”问题中的一种物品,把 j 号员工的团队中有不超过 l 人参加抽象成取了 l 个这种物品,可以获得的收益是 f[j][l][0]。就可以用“新的背包”问题的思路解决这个问题啦!现在的人数限制就是“新的背包”问题中的容量限制。
然后,对于所有的 k,我们再来考虑如何计算 f[i][k][0],也就是 i 号员工不参加舞会的情况。这种情况和 i 号员工参加舞会的情况是类似的。考虑 i 号员工的某个直接下属 j 号员工,他/她既可以参加也可以不参加。我们也可以把 i 的每个直接下属 j 抽象成“新的背包”问题中的一种物品,把 j 号员工的团队中有不超过 l 人参加抽象成取了 l 个这种物品,可以获得的收益是 max(f[j][l][0], f[j][l][1]),也就是在 j 号员工参加/不参加两种情况中选择快乐值较大的一个就可以啦!
于是,所有的问题都迎刃而解啦!
#include <bits/stdc++.h>
using namespace std;
struct node {
node *next;
int where;
} *first[501], a[501];
int n, m, l, v[501];
long long f[501][501][2];
inline void makelist(int x, int y) {
a[++l].where = y;
a[l].next = first[x];
first[x] = &a[l];
}
inline void solve(int i) {
for (node *x = first[i]; x; x = x->next) {
solve(x->where);
for (int k = m; k >= 0; --k)
for (int l = 0; l <= k; l++) {
f[i][k][0] = max(f[i][k][0], f[i][k - l][0] + max(f[x->where][l][0], f[x->where][l][1]));
f[i][k][1] = max(f[i][k][1], f[i][k - l][1] + f[x->where][l][0]);
}
}
for (int k = m; k; --k)
f[i][k][1] = f[i][k - 1][1] + v[i];
f[i][0][1] = 0;
}
int main() {
scanf("%d%d", &n, &m);
memset(first, 0, sizeof(first));
l = 0;
for (int i = 2; i <= n; i++) {
int x;
scanf("%d", &x);
makelist(x, i);
}
for (int i = 1; i <= n; i++)
scanf("%d", &v[i]); // 这里的 v[i] 指的是题目中的 a[i],也就是 i 号员工参加舞会带来的快乐值。
solve(1);
printf("%lld\n", max(f[1][m][0], f[1][m][1]));
}
我们来看看代码。
for (node *x = first[i]; x; x = x->next) {
solve(x->where);
for (int k = m; k >= 0; --k)
for (int l = 0; l <= k; l++) {
f[i][k][0] = max(f[i][k][0], f[i][k - l][0] + max(f[x->where][l][0], f[x->where][l][1]));
f[i][k][1] = max(f[i][k][1], f[i][k - l][1] + f[x->where][l][0]);
}
}
solve 函数中的这一块的作用是递归计算 i 的每个直接下属 x->where 的情况,然后在这里套用一次“新的背包“问题的第二种做法。
for (int k = m; k; --k)
f[i][k][1] = f[i][k - 1][1] + v[i];
f[i][0][1] = 0;
由于 f[i][k][1] 对应的是 i 号员工参加舞会的情况,之前过程中我们只考虑了直接下属的团队中参加的人数,现在我们要把 i 号员工也考虑进来,也就是说,i 号员工参与进来以后的 f[i][k][1] 对应了原来的 f[i][k - 1][1] + v[i] (由于 i 号员工要参加,直接下属的团队中参加的人数不能超过 k - 1,v[i] 表示 i 号员工参加舞会带来的快乐值)。在具体操作的过程中,k 必须从大到小枚举,否则会出现类似 f[i][0][1] 先更新 f[i][1][1],f[i][1][1] 再更新 f[i][2][1],i 号员工参加了超过一次的情况。
最后,由于 f[i][0][1] 对应的情况不可能出现(不可能出现 1 号员工参加了,但是他/她的团队中一共参加了不超过 0 人的情况),它的值需要被设置成负无穷大,但由于在转移的过程中,每次 f[i][k][1] 出现时都会与 f[i][k][0] 取 max,而 f[i][0][0] = 0,所以 f[i][0][1] 只要设置成小于等于 0 的数字就可以啦!
printf("%lld\n", max(f[1][m][0], f[1][m][1]));
答案等于考虑了 1 号员工的团队(整个团队),参加人数不超过 m 人, 1 号员工参加/不参加两种情况下较大的快乐值。
对于每个员工的团队,在合并到他/她的父亲的团队的过程中,我们都需要从 m 到 0 枚举 k 以及从 0 到 k 枚举 l,所以处理每个员工的时间复杂度是 O(m^2) 的。每个员工都只会在合并到父亲的过程中被处理一次,所以总的时间复杂度为 O(nm^2) 。
树形动态规划,完结撒花!
文章被以下专栏收录
