
【论文速递12-29】领域自适应方向优质的论文及其代码

Domain Adaptation - 领域自适应
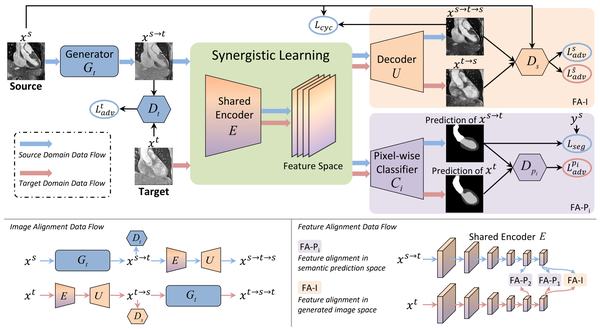
1. 【Domain Adaptation】Unsupervised Bidirectional Cross-Modality Adaptation via Deeply Synergistic Image and Feature Alignment for Medical Image Segmentation
【领域自适应】通过深度协同图像和特征对齐进行无监督双向跨模态适应,用于医学图像分割

作者:Cheng Chen, Qi Dou, Hao Chen, Jing Qin, Pheng Ann Heng
链接:
https://arxiv.org/abs/2002.02255v1
代码:
https://github.com/cchen-cc/SIFA
英文摘要:
Unsupervised domain adaptation has increasingly gained interest in medical image computing, aiming to tackle the performance degradation of deep neural networks when being deployed to unseen data with heterogeneous characteristics. In this work, we present a novel unsupervised domain adaptation framework, named as Synergistic Image and Feature Alignment (SIFA), to effectively adapt a segmentation network to an unlabeled target domain. Our proposed SIFA conducts synergistic alignment of domains from both image and feature perspectives. In particular, we simultaneously transform the appearance of images across domains and enhance domain-invariance of the extracted features by leveraging adversarial learning in multiple aspects and with a deeply supervised mechanism. The feature encoder is shared between both adaptive perspectives to leverage their mutual benefits via end-to-end learning. We have extensively evaluated our method with cardiac substructure segmentation and abdominal multi-organ segmentation for bidirectional cross-modality adaptation between MRI and CT images. Experimental results on two different tasks demonstrate that our SIFA method is effective in improving segmentation performance on unlabeled target images, and outperforms the state-of-the-art domain adaptation approaches by a large margin.
中文摘要:
无监督域自适应越来越引起医学图像计算的兴趣,旨在解决深度神经网络在部署到具有异构特征的不可见数据时性能下降的问题。在这项工作中,我们提出了一种新的无监督域适应框架,称为协同图像和特征对齐(SIFA),以有效地使分割网络适应未标记的目标域。我们提出的SIFA从图像和特征的角度进行域的协同对齐。特别是,我们通过在多个方面利用对抗性学习和深度监督机制,同时跨域转换图像的外观并增强提取特征的域不变性。特征编码器在两个自适应视角之间共享,以通过端到端学习来利用它们的共同利益。我们已经广泛评估了我们的方法,包括心脏亚结构分割和腹部多器官分割,用于MRI和CT图像之间的双向跨模态适应。在两个不同任务上的实验结果表明,我们的SIFA方法可有效提高未标记目标图像的分割性能,并且在很大程度上优于最先进的域适应方法。


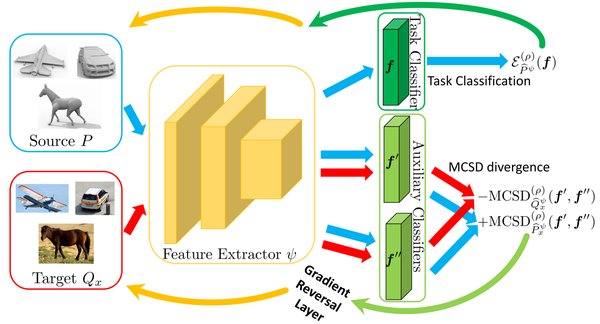
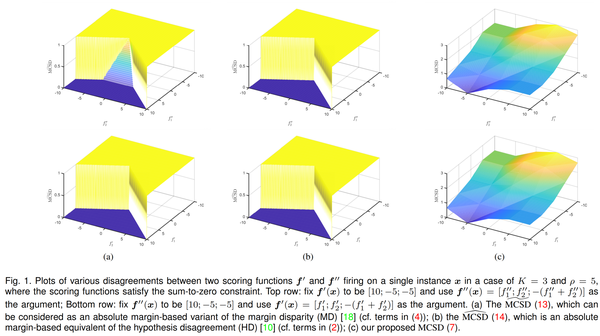
2. 【Domain Adaptation】Unsupervised Multi-Class Domain Adaptation: Theory, Algorithms, and Practice
【领域自适应】无监督多类域适应:理论、算法和实践

作者:Yabin Zhang, Bin Deng, Hui Tang, Lei Zhang, Kui Jia
链接:
https://arxiv.org/abs/2002.08681v2
代码:
https://github.com/YBZh/SymNets
https://github.com/YBZh/MultiClassDA
英文摘要:
In this paper, we study the formalism of unsupervised multi-class domain adaptation (multi-class UDA), which underlies a few recent algorithms whose learning objectives are only motivated empirically. Multi-Class Scoring Disagreement (MCSD) divergence is presented by aggregating the absolute margin violations in multi-class classification, and this proposed MCSD is able to fully characterize the relations between any pair of multi-class scoring hypotheses. By using MCSD as a measure of domain distance, we develop a new domain adaptation bound for multi-class UDA; its data-dependent, probably approximately correct bound is also developed that naturally suggests adversarial learning objectives to align conditional feature distributions across source and target domains. Consequently, an algorithmic framework of Multi-class Domain-adversarial learning Networks (McDalNets) is developed, and its different instantiations via surrogate learning objectives either coincide with or resemble a few recently popular methods, thus (partially) underscoring their practical effectiveness. Based on our identical theory for multi-class UDA, we also introduce a new algorithm of Domain-Symmetric Networks (SymmNets), which is featured by a novel adversarial strategy of domain confusion and discrimination. SymmNets affords simple extensions that work equally well under the problem settings of either closed set, partial, or open set UDA. We conduct careful empirical studies to compare different algorithms of McDalNets and our newly introduced SymmNets. Experiments verify our theoretical analysis and show the efficacy of our proposed SymmNets. In addition, we have made our implementation code publicly available.
中文摘要:
在本文中,我们研究了无监督多类域适应(多类UDA)的形式,它是一些最近的算法的基础,这些算法的学习目标仅凭经验。多类评分不一致(MCSD)分歧是通过聚合多类分类中的绝对边界违规来呈现的,并且该提议的MCSD能够充分表征任何一对多类评分假设之间的关系。通过使用MCSD作为域距离的度量,我们为多类UDA开发了一个新的域自适应边界;它的数据依赖,可能近似正确的界限也被开发出来,自然地建议对抗性学习目标来对齐源域和目标域的条件特征分布。因此,开发了多类域对抗学习网络(McDalNets)的算法框架,其通过替代学习目标的不同实例与一些最近流行的方法一致或相似,因此(部分)强调了它们的实际有效性。基于我们对多类UDA的相同理论,我们还引入了域对称网络(SymmNets)的新算法,该算法的特点是新的域混淆和区分对抗策略。SymmNets提供了简单的扩展,它们在封闭集、部分或开放集UDA的问题设置下同样有效。我们进行了仔细的实证研究,以比较McDalNets和我们新引入的SymmNets的不同算法。实验验证了我们的理论分析并展示了我们提出的SymmNets的有效性。此外,我们还公开了我们的实现代码。

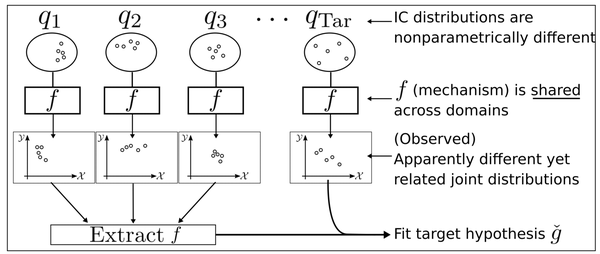
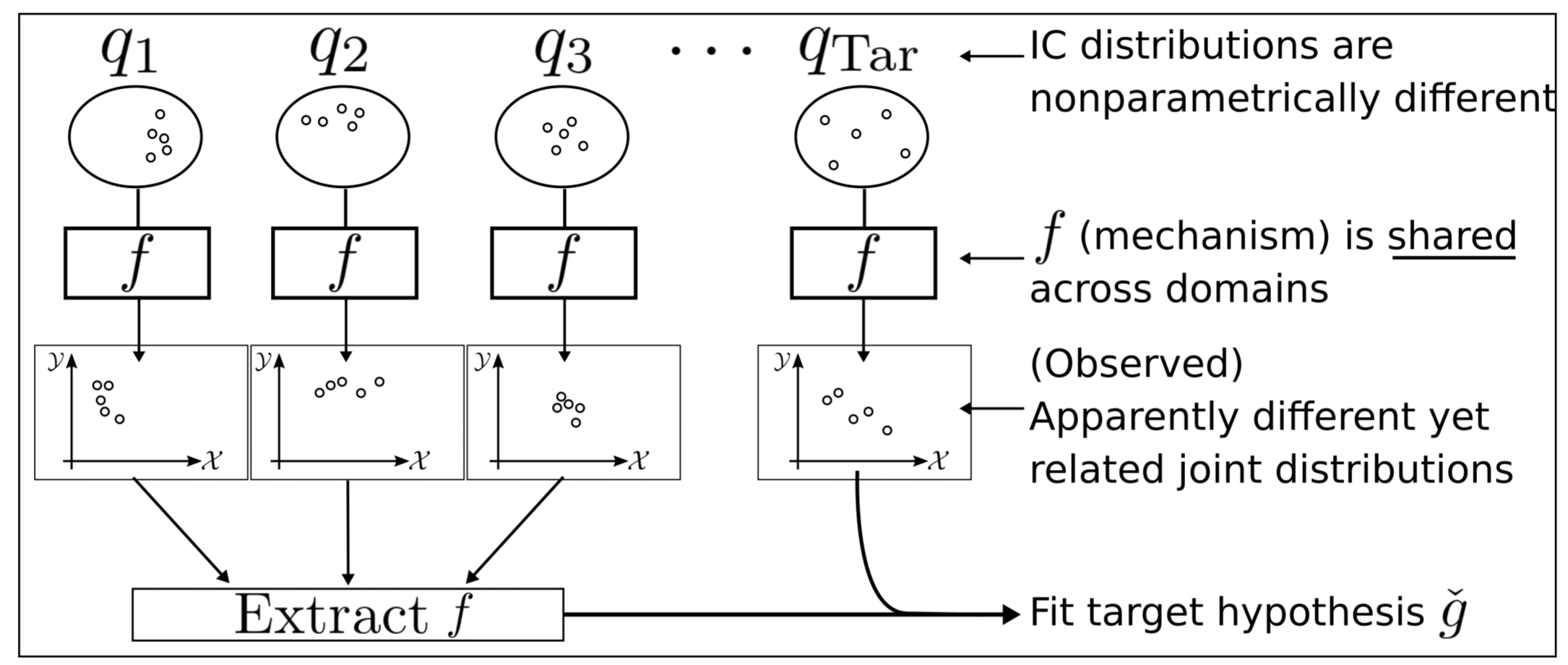
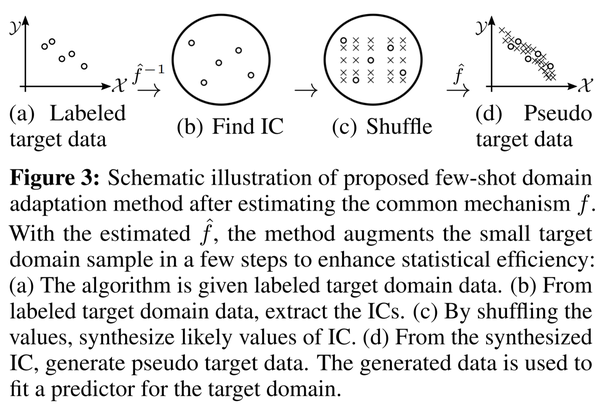
3. 【Domain Adaptation】Few-shot Domain Adaptation by Causal Mechanism Transfer
【领域自适应】因果机制转移的小样本域适应
作者:Takeshi Teshima, Issei Sato, Masashi Sugiyama
链接:
https://arxiv.org/abs/2002.03497v2
代码:
https://github.com/takeshi-teshima/few-shot-domain-adaptation-by-causal-mechanism-transfer
英文摘要:
We study few-shot supervised domain adaptation (DA) for regression problems, where only a few labeled target domain data and many labeled source domain data are available. Many of the current DA methods base their transfer assumptions on either parametrized distribution shift or apparent distribution similarities, e.g., identical conditionals or small distributional discrepancies. However, these assumptions may preclude the possibility of adaptation from intricately shifted and apparently very different distributions. To overcome this problem, we propose mechanism transfer, a meta-distributional scenario in which a data generating mechanism is invariant among domains. This transfer assumption can accommodate nonparametric shifts resulting in apparently different distributions while providing a solid statistical basis for DA. We take the structural equations in causal modeling as an example and propose a novel DA method, which is shown to be useful both theoretically and experimentally. Our method can be seen as the first attempt to fully leverage the structural causal models for DA.
中文摘要:
我们研究了用于回归问题的小样本监督域适应(DA),其中只有少数标记的目标域数据和许多标记的源域数据可用。许多当前的DA方法基于参数化分布偏移或表观分布相似性(例如,相同的条件或小的分布差异)进行转移假设。然而,这些假设可能排除了适应错综复杂且明显不同的分布的可能性。为了克服这个问题,我们提出了机制转移,这是一种元分布场景,其中数据生成机制在域之间是不变的。这种转移假设可以适应导致明显不同分布的非参数变化,同时为DA提供可靠的统计基础。我们以因果建模中的结构方程为例,提出了一种新的DA方法,该方法在理论上和实验上都证明是有用的。我们的方法可以看作是充分利用DA的结构因果模型的第一次尝试。

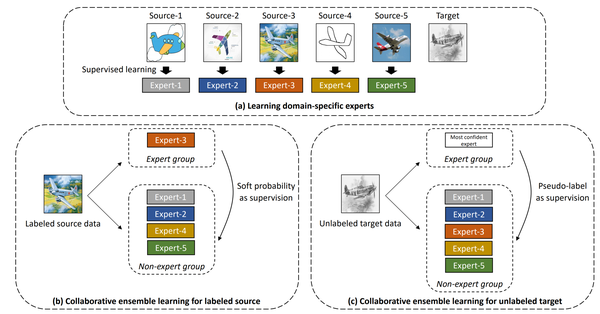
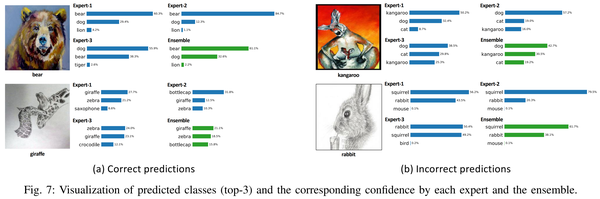
4. 【Domain Adaptation】Domain Adaptive Ensemble Learning
【领域自适应】领域自适应集成学习

作者:Kaiyang Zhou, Yongxin Yang, Yu Qiao, Tao Xiang
链接:
https://arxiv.org/abs/2003.07325v3
代码:
https://github.com/KaiyangZhou/Dassl.pytorch
英文摘要:
The problem of generalizing deep neural networks from multiple source domains to a target one is studied under two settings: When unlabeled target data is available, it is a multi-source unsupervised domain adaptation (UDA) problem, otherwise a domain generalization (DG) problem. We propose a unified framework termed domain adaptive ensemble learning (DAEL) to address both problems. A DAEL model is composed of a CNN feature extractor shared across domains and multiple classifier heads each trained to specialize in a particular source domain. Each such classifier is an expert to its own domain and a non-expert to others. DAEL aims to learn these experts collaboratively so that when forming an ensemble, they can leverage complementary information from each other to be more effective for an unseen target domain. To this end, each source domain is used in turn as a pseudo-target-domain with its own expert providing supervisory signal to the ensemble of non-experts learned from the other sources. For unlabeled target data under the UDA setting where real expert does not exist, DAEL uses pseudo-label to supervise the ensemble learning. Extensive experiments on three multi-source UDA datasets and two DG datasets show that DAEL improves the state of the art on both problems, often by significant margins.
中文摘要:
将深度神经网络从多个源域泛化到目标域的问题在两种设置下进行研究:当未标记的目标数据可用时,它是一个多源无监督域适应(UDA)问题,否则是域泛化(DG)问题.我们提出了一个称为域自适应集成学习(DAEL)的统一框架来解决这两个问题。DAEL模型由跨域共享的CNN特征提取器和多个分类器组成,每个分类器都经过训练以专门研究特定的源域。每个这样的分类器都是其自己领域的专家,而对其他人则是非专家。DAEL旨在协作学习这些专家,以便在形成集成时,他们可以利用彼此的互补信息对看不见的目标领域更有效。为此,每个源域依次用作伪目标域,其自己的专家向从其他源学习的非专家集合提供监督信号。对于不存在真正专家的UDA设置下的未标记目标数据,DAEL使用伪标签来监督集成学习。在三个多源UDA数据集和两个DG数据集上进行的大量实验表明,DAEL改进了这两个问题的现有技术,通常是显着的优势。

5. 【Domain Adaptation】Unsupervised Domain Adaptation via Structurally Regularized Deep Clustering
【领域自适应】通过结构正则化深度聚类的无监督域适应
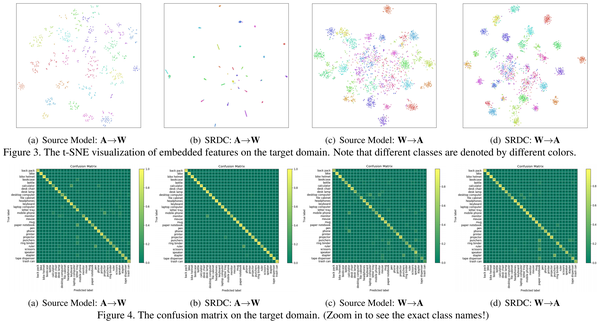

作者:Hui Tang, Ke Chen, Kui Jia
链接:
https://arxiv.org/abs/2003.08607v1
代码:
https://github.com/huitangtang/SRDC-CVPR2020
英文摘要:
Unsupervised domain adaptation (UDA) is to make predictions for unlabeled data on a target domain, given labeled data on a source domain whose distribution shifts from the target one. Mainstream UDA methods learn aligned features between the two domains, such that a classifier trained on the source features can be readily applied to the target ones. However, such a transferring strategy has a potential risk of damaging the intrinsic discrimination of target data. To alleviate this risk, we are motivated by the assumption of structural domain similarity, and propose to directly uncover the intrinsic target discrimination via discriminative clustering of target data. We constrain the clustering solutions using structural source regularization that hinges on our assumed structural domain similarity. Technically, we use a flexible framework of deep network based discriminative clustering that minimizes the KL divergence between predictive label distribution of the network and an introduced auxiliary one; replacing the auxiliary distribution with that formed by ground-truth labels of source data implements the structural source regularization via a simple strategy of joint network training. We term our proposed method as Structurally Regularized Deep Clustering (SRDC), where we also enhance target discrimination with clustering of intermediate network features, and enhance structural regularization with soft selection of less divergent source examples. Careful ablation studies show the efficacy of our proposed SRDC. Notably, with no explicit domain alignment, SRDC outperforms all existing methods on three UDA benchmarks.
中文摘要:
无监督域适应(UDA)是对目标域上的未标记数据进行预测,给定源域上的标记数据,其分布从目标域偏移。主流UDA方法学习两个域之间的对齐特征,这样在源特征上训练的分类器可以很容易地应用于目标特征。然而,这种转移策略存在破坏目标数据内在辨别力的潜在风险。为了减轻这种风险,我们受到结构域相似性假设的启发,并建议通过目标数据的判别聚类来直接揭示内在的目标判别。我们使用取决于我们假设的结构域相似性的结构源正则化来约束聚类解决方案。从技术上讲,我们使用基于深度网络的判别聚类的灵活框架,最大限度地减少网络的预测标签分布与引入的辅助标签分布之间的KL散度;用源数据的真实标签形成的辅助分布替换辅助分布,通过联合网络训练的简单策略实现结构源正则化。我们将我们提出的方法称为结构正则化深度聚类(SRDC),其中我们还通过中间网络特征的聚类来增强目标辨别力,并通过对较少发散源示例的软选择来增强结构正则化。仔细的消融研究显示了我们提议的SRDC的功效。值得注意的是,由于没有明确的域对齐,SRDC在三个UDA基准测试中优于所有现有方法。

6. 【Domain Adaptation】Learning to Match Distributions for Domain Adaptation
【领域自适应】学习匹配域适应的分布


作者:Chaohui Yu, Jindong Wang, Chang Liu, Tao Qin, Renjun Xu, Wenjie Feng, Yiqiang Chen, Tie-Yan Liu
链接:
https://arxiv.org/abs/2007.10791v3
代码:
https://github.com/jindongwang/transferlearning
英文摘要:
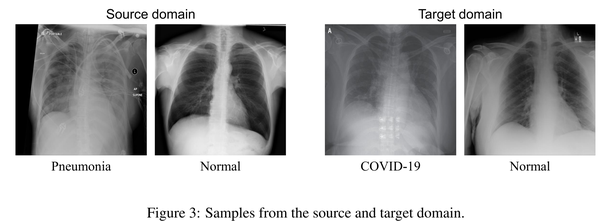
When the training and test data are from different distributions, domain adaptation is needed to reduce dataset bias to improve the model's generalization ability. Since it is difficult to directly match the cross-domain joint distributions, existing methods tend to reduce the marginal or conditional distribution divergence using predefined distances such as MMD and adversarial-based discrepancies. However, it remains challenging to determine which method is suitable for a given application since they are built with certain priors or bias. Thus they may fail to uncover the underlying relationship between transferable features and joint distributions. This paper proposes Learning to Match (L2M) to automatically learn the cross-domain distribution matching without relying on hand-crafted priors on the matching loss. Instead, L2M reduces the inductive bias by using a meta-network to learn the distribution matching loss in a data-driven way. L2M is a general framework that unifies task-independent and human-designed matching features. We design a novel optimization algorithm for this challenging objective with self-supervised label propagation. Experiments on public datasets substantiate the superiority of L2M over SOTA methods. Moreover, we apply L2M to transfer from pneumonia to COVID-19 chest X-ray images with remarkable performance. L2M can also be extended in other distribution matching applications where we show in a trial experiment that L2M generates more realistic and sharper MNIST samples.
中文摘要:
当训练和测试数据来自不同的分布时,需要进行域自适应以减少数据集偏差,以提高模型的泛化能力。由于很难直接匹配跨域联合分布,现有方法倾向于使用预定义的距离(例如MMD和基于对抗性的差异)来减少边际或条件分布的差异。然而,确定哪种方法适合给定的应用程序仍然具有挑战性,因为它们是基于某些先验或偏见构建的。因此,他们可能无法揭示可转移特征和联合分布之间的潜在关系。本文提出了学习匹配(L2M)来自动学习跨域分布匹配,而不依赖于匹配损失上的手工制作的先验。相反,L2M通过使用元网络以数据驱动的方式学习分布匹配损失来减少归纳偏差。L2M是一个通用框架,它统一了与任务无关和人为设计的匹配特征。我们为具有自监督标签传播的这一具有挑战性的目标设计了一种新颖的优化算法。公共数据集的实验证实了L2M优于SOTA方法。此外,我们应用L2M从肺炎转移到COVID-19胸部X射线图像,性能卓越。L2M也可以扩展到其他分布匹配应用程序中,我们在试验实验中展示了L2M生成更真实、更清晰的MNIST样本。

AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~