
简单爬虫:千图网高清图片爬取(python_004)

目标需求:将千图网( http://www.58pic.com/)某个频道的所有图片爬下来,要高清图!
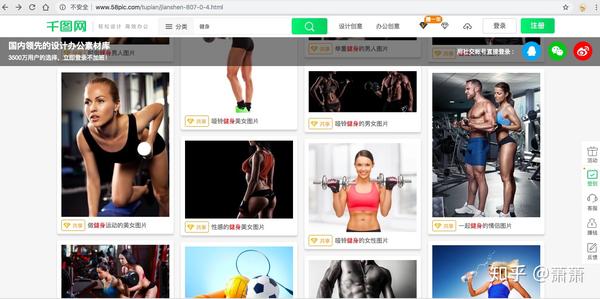
选定“健身”频道,链接地址: http://www.58pic.com/tupian/jianshen-807-0.html

爬虫实现步骤:
第一步:分析URL,寻找翻页规律,构造URL。


我们看到健身频道下的图片总共有208页,每页约30张图片,总共有图片约6000张。
需要爬虫将每一页上的图片爬取下来,并实现自动翻页,那么就需要找到URL中翻页的规律,并构造出我们需要的URL。分析如下:
第1页: http://www.58pic.com/tupian/jianshen-807-0.html
第2页: http://www.58pic.com/tupian/jianshen-807-0-2.html
第3页: http://www.58pic.com/tupian/jianshen-807-0-3.html
分析前三页的规律很容易知道,页面是在最后一个数字逐页递增。所以,
第4页应该是: http://www.58pic.com/tupian/jianshen-807-0-4.html
输入网址验证一下,验证成功,链接能够成功条状到第4页。
那么,很简单我们需要构造的URL就是如下了:


第二步:查看网页源代码,通过正则表达式,找到所有高清图片的位置。
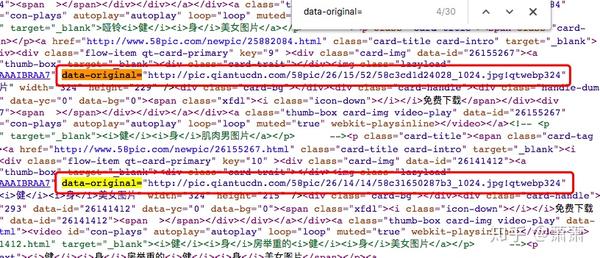

通过分析页面源代码,我们很快发现“data-original="后面的链接就是我们需要的图片地址,而且正好是30张图片。
比如,这个链接: http://pic.qiantucdn.com/58pic/26/14/14/58c31650287b3_1024.jpg!qtwebp324
输入地址框,出来是下面这张图片:


咦~尺寸好像不对,再观察图片url,正常的图片应该以“.jpg”结尾,这个URL后面多了一串文字:!qtwebp324。
试着把 !qtwebp324 删掉看看效果。没想到运气很好,就是要找的高清图的地址。


哦耶~这下就很清楚了,我们要找的高清图片地址就是将“data-original="后面的链接全部找出来,然后删除掉.jpg后面多余的部分即可。
实现起来也很容易,通过正则表达式全部匹配出来,再通过replace()方法将多余部分喜欢掉即可。


通过正则匹配出来得到的图片链接如下:
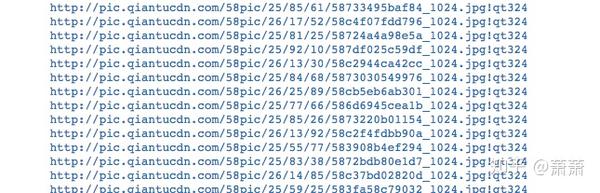

然后,将链接尾部多余部分替换掉即可。


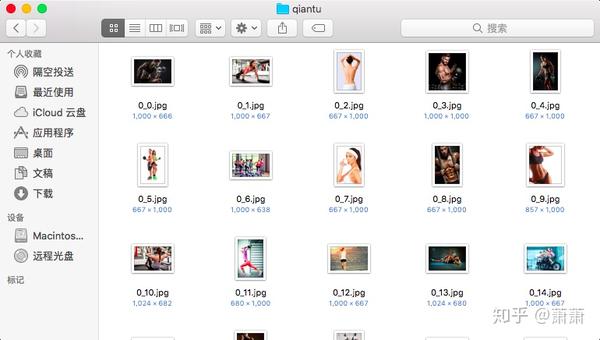
最后将所有的链接保存到本地即可。
第三步:完整代码。
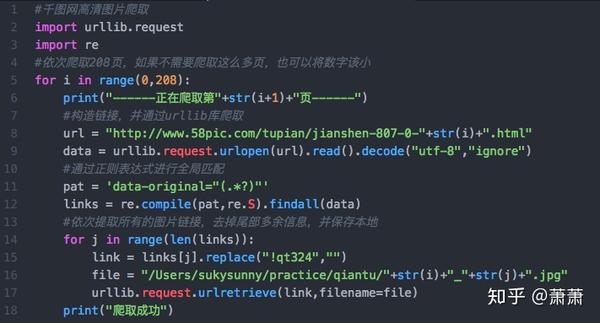

搞定。文件已经按顺序保存到本地:

文章被以下专栏收录