【数据库】数据库索引介绍和使用

1. 索引
索引在数据库中起到加快查询速度的作用,假设需要查询一条数据,select * from user where id = '1'; 如果没有索引,则需要挨个记录匹配,最终匹配到对应的记录,时间复杂度则为 O(N).
如果通过索引查询,以 mysql 为例,索引采用的是 B+ 树结构来构建,B+ 树是一颗变种的 B树,变种的主要目的是减少树的深度和大小,以减少 IO 的次数,提升效率。那 B树 可以理解为是一颗平衡多叉树,所以再这种数据结构下,查找的时间复杂度可以理解为 二分查找的时间复杂度,同样的上面的 sql,其时间复杂度则为 O(log(N))。
B+ 树 和 B树的区别见: 【数据结构】二叉树 平衡二叉树 B树 B+树
为什么二分查找的时间复杂度是 O(logN)见: 为什么二分查找的时间复杂度是 logN
2. 索引查询
加入有 sql select * from user where id = '55';
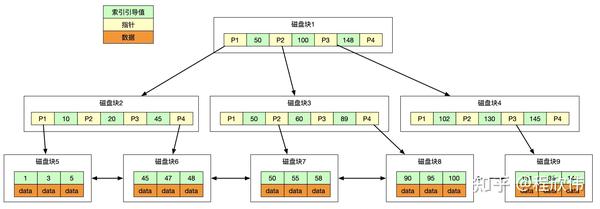
如果我们要加载 id = 55 的数据,那么
- 把磁盘块1的数据由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定 55 在 50 - 100,确磁盘磁盘块1的P2指针,确定了磁盘块3的位置
- 加载磁盘块3的数据到内存,发生第二次IO,确定了 55 在 50 - 60 之间,锁定磁盘块3的P2指针,确定了磁盘块7的位置。
- 加载磁盘块7的数据到内存,发生第三次IO,在内存中做二分查找确定数据 55,结束查询,总计三次IO。
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
2.1. B+树 和 B树区别
B树和B+树最大的区别在于非叶子节点保存的数据上,B树在每个节点上都会保存,索引值,关键数据,对应磁盘指针地址,子节点对应磁盘指针地址,而 B+树把数据保存在叶子节点,非叶子节点只保存索引值,子节点对应磁盘的位置。
2.2. 为什么要采用 B+ 树?
- 降低树的高度:由上面的推演可以得出,想加快一次索引的查找,应该尽量减少树的高度,树的深度越是深,则查询效率越是低,因为 B+ 树所有叶子节点是平级的,在不考虑缓存的情况下,树的结构每多一个深度则多一次 IO。所以减少树的高度是考虑的核心要素,B树在非叶子节点会保存数据的指针和关键数据,这意味着非叶子节点需要存储的数据会比 B+ 树要多,叶子节点数据越多代表每一个磁盘块存储的数据少,从而会增加树的高度。
- B+ 树的每个叶子节点有个指针指向下一个叶子节点,对于范围查询的实现更简单,减少复杂度一样可以提高查询效率。
3. 索引实现
3.1. 聚簇索引
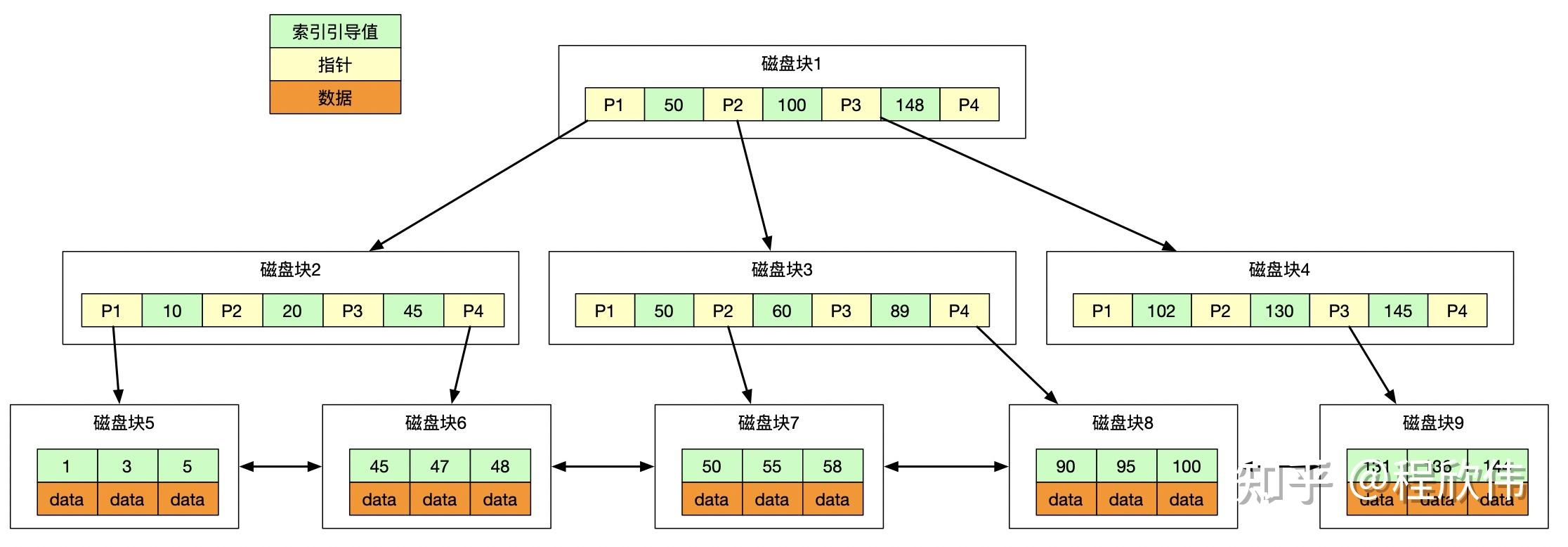
innoDB 采用 B+ 树来实现索引,并且其原始数据本身就是一颗 B+ 树,也称为聚簇索引,所以每一张 innoDB 的表数据,必须有切只有一个聚簇索引,聚簇索引的 B+ 树,地下保存的 data 也就是原始数据,即 下图
- 表结构有3个字段,id int primary key, name varchar(32) , age int, sex(char);
- 索引 idx_age(age)


3.2. 辅助索引
辅助索引,也称为二级索引,有时候也叫普通索引,他的数据结构也是 B+ 树,但是普通索引叶子节点的数据是聚簇索引的值,所以普通索引在定位到聚簇之后,需要去聚簇表再查询一次,称之为回表,所以尽量避免使用数据量大的字段作为聚簇索引,一方面是会增大聚簇索引的高度,更重要的是会增加所有辅助索引的大小,下图是 age 的索引的结构。
查询 age = 30 的数据,基于 age 的索引查到聚簇索引 = 1,再基于 1 去聚簇索引里面找到对应的数据。
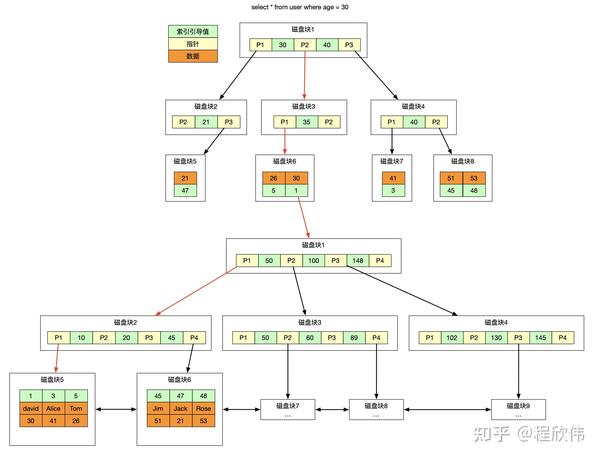

3.3. 怎么避免回表?
回表在辅助索引定位到聚簇索引的值之后,如果当前的索引数据无法满足需要满足返回的值的时候会出现回表,即基于 聚簇的值 去聚簇索引中再次查询数据,以上面的sql 为例
select id, age from user where age = 30 不需要回表,因为 id 是聚簇索引,age 是辅助索引。
select id, age, sex from user where age = 30 则需要回表,因为 id 是聚簇索引,age 是辅助索引,sex 不在索引数据范围内,需要基于 age 30 定位到 聚簇是 1,根据 1 再回表查。
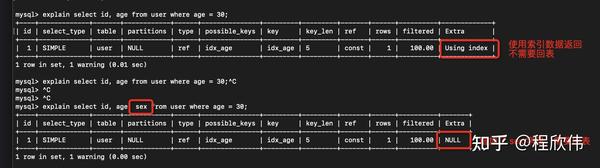

如果想避免回表的话,可以在 age 索引后增加 sex,变成组合索引,修改索引之后看到索引如下


再次执行同样的sql,会发现没有回表了


4. 索引原则
4.1. 聚簇索引
上文提到了辅助索引定位到聚簇索引之后,还需要进行回表的操作,所以如果查询可以使用聚簇索引优先使用聚簇。


根据聚簇索引查找,type = 'const'
key_len 表示该基于使用的索引的字节数,因为 user 表的主键 id 是 int,int 占4个字节,所以 key_len = 4
4.2. 组合索引 最左原则
组合索引的原则是向左匹配,如果左侧匹配不到,则之后的索引字段都无法走上索引,这个和 B+ 树的实现有关。因为建立好组合索引之后,索引的数据顺序和建立的顺序一致,B+树的生成也是基于这个顺序来,所以在查询的时候,必须先匹配索引排序的第一个字段,依次第二个第三个。
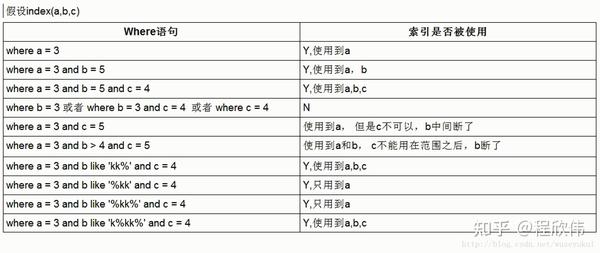

接下来逐个分析为什么能使用上索引和为什么使用不上索引
案例表:
| user | CREATE TABLE `user` (
`id` int NOT NULL,
`a` int DEFAULT NULL,
`b` varchar(4) DEFAULT NULL,
`c` char(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a_b_c` (`a`,`b`,`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |下面的例子中,
- a 字段类型是 int null,int 是4个字节
- b 字段类型是 varchar (4) 因为我本地 mysql 使用的编码是 utf8mb4,1个 varchar 占 4个字符,varchar(4) 大小的是 4 x 4 = 16个字节
- c 字段类型是 char (1)
4.2.1. where a = 3
可以使用到 索引 idx_a_b_c (a, b, c) 中的 字段 a 字段的索引。


- type 是 ref ,表示使用的辅助索引
- key_len = 5,5是因为该字段是 a 字段是 int 类型,4个字节,加上是一个可空字段加1个字节,所以等于5. 通过 key_len 可以推导出来使用了组合索引中的几个字段。
4.2.2. where a = 3 and b = 5
可以使用到 索引 idx_a_b_c (a, b, c) 中的 字段 a, b 字段的索引


key_len 是 24,上面计算了 a 字段是5个字节,b 字段因为是 varchar(4),16个字节 + 变长 2个字节 + 可空字段的一个字节,= 5 + 16 + 2 + 1 = 24
4.2.3. where a = 3 and b = 5 and c = 4


key_len = 29,a 加 b 是 24,上面计算过了,1个 char 是4个字节,加上可空 1个字节(因为 char 是定长,所以不需要加上 varchar 的2个字节)所以最后是 24 + 4+ 1 = 29
4.2.4. where b = 5


前面解释过了索引的匹配是最左开始匹配的,索引建立是 a, b, c ,如果只有 b 的话是无法匹配到索引的。
无法匹配上索引之后,会变成全表扫描,也就是挨个记录扫描,type = ALL,这个是尽量要避免的。
4.2.5. where a = 3 and c = 4


这个案例是因为没有 b 所以 c 无法使用上索引,a 字段是可以匹配上索引的,所以对应的 key_len 是 4,一个int
4.2.6. where a = 3 and b > 5 and c = 4
a 和 b 是是可以走上索引的,c 无法走上索引


key_len 是 24,是 a+b 的字节数
4.2.6.1. 为什么范围查询之后的字段无法走上索引呢?


以这个图为例,可以看到
a 的数据集合是 1, 1, 2, 2, 3, 3
b 的数据集合是 1, 2, 1, 4, 1, 2
我们看到 a 的数据范围是有序的集合,所以在 B+ 树查询的时候,本身 a 字段还是一棵树,可以基于 二分查找来查找数据,时间复杂度依旧是 logN,当 a 给的是一个范围的时候,比如上面那个图,a >=0,则会获得 1, 2, 3 获取这下面的 b 的集合不是一个有序的集合,也不是一颗树,无法通过二分来查找,所以只能采用扫描。
4.2.6.2. 为什么等值查询之后的范围查询可以走上索引呢?
还是以上面为例,可以发现,a 是定值的时候,b 一定是有序的,比如
- a = 1 的时候,b = 1,2
- a = 2 的时候,b = 1,4
- a = 3 的时候,b = 1,2
所以在 a 的值确定了之后,b 是有序集合,可以通过二分查找来定位,可以走上索引。
4.2.7. where a = 3 and b like 'abc%' and c = 4


从 key_len = 29 可以看出这确实是走了 a b c 3个字段的索引,但是为什么范围查询之后的字段不能走索引,但是 like 的条件之后的字段可以走呢?
4.2.8. where a = 3 and b like '%abc' and c = 4
通配符出现在开头,无法使用索引 b,间接导致了 c 字段也无法使用索引


key_len = 5,代表字段 a
4.3. 其他参考原则
4.3.1. 查询条件中包含函数计算可能无法走上索引
在查询的字段上做函数计算,无法使用索引,type = ALL,全表扫描


4.3.2. 不等后的条件无法走上索引
这个原理和 范围查询之后的字段无法走上索引一样
4.3.3. 减少磁盘 IO 的读取
假设现在有购物车的表,里面有 cart id, user id, 和其他购物车的必要信息,在购物车的场景下,绝大部分的查询都是给予用户 id 查询用户的购物车的信息,我们来看下索引的建立:
- cart id 为主键,user id 建辅助索引
- 当根据 user id 查询的时候,会返回很多 cart id,会产生很多次回表,又因为购物车的场景,用户添加购物车,可能是隔几天添加一个,所以一个用户下的 cart id 在物理上不一定在一个磁盘块,则会产生很多次的 IO。
- user id + cart id 作为主键
- 优点:相比于只把 cart id 作为主键从数据查询上来说,因为 user id 在前面,所以聚簇上的数据更连续,在查询的时候会减少 IO 的读取次数
- 缺点:在写入的时候,因为聚簇的顺序是 user id 为主,所以在数据写入的时候,并不一定会写在聚簇索引的末端,会导致 B+ 树频繁的 rebalance,会牺牲一部分写入的性能。
索引如何建立需要根据当前业务场景来说,如果是大量读少量写的话,可以重写轻读,反之一样。
4.3.4. 减少回表
如果需要查询的列是索引可以覆盖的,不要额外增加查询列
举例:user 表有辅助索引 idx_age (age).
通过辅助索引查询,当索引可以满足查询数据时,不需要回表,extra中显示 using index.


通过辅助索引查询,当索引无法满足查询数据时,则需要回表。


4.3.5. 减少回表的量
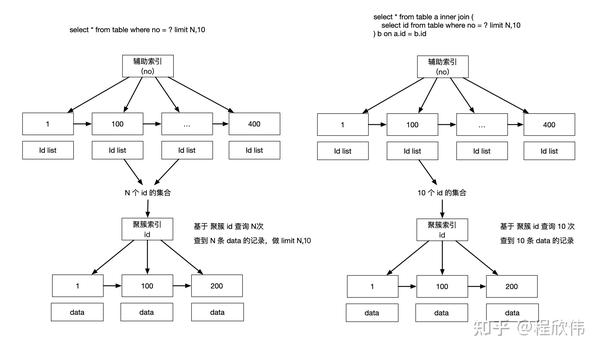
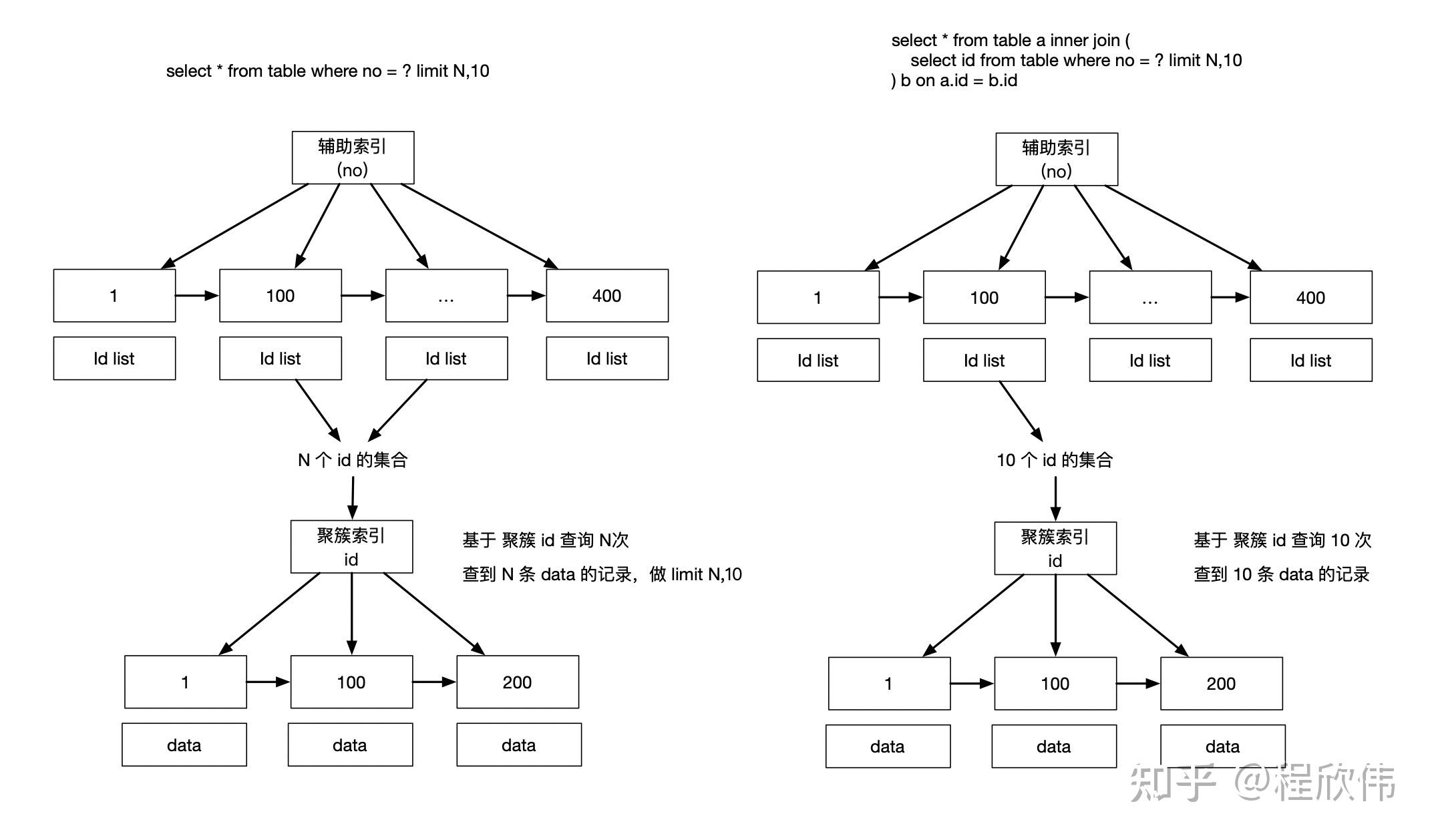
在limit 的场景,如果通过二级索引的筛选之后limit,会回表之后再limit,可以通过子查询减少回表的量。
比如sql:
-- 回表之后在进行 limit
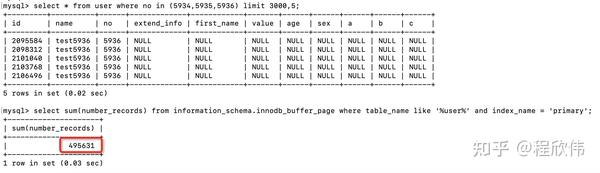
select * from user where no in (5934,5935,5936) limit 3000,5;可以优化成:
-- 先 limit 筛选出 id,然后再回表
select * from user a
inner join (
select id from user where no in (5934,5935,5936) limit 3000,5
) b on a.id = b.id;思路:
优化的思路,是通过子查询,或者inner join,先确定需要查询的 id,然后再回表,这样可以减少回表的量,如果是原始未优化的sql,会在辅助索引查询出所有可能的 id,全部进行回表,回表之后,查到数据再进行 limit 3000,5,这其中前面 3000 条数据,会被 mysql 丢弃掉,白白浪费性能。
原理:
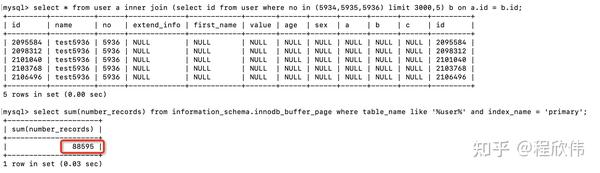
通过 information_schema.innodb_buffer_page 表可以查看 innodb 内存缓存页的数据,通过这个值可以确定 load 了多少数据到内存页中,可以看到如果是通过子查询优化的语句,load 内存的记录数是 8.8W ,在没有优化之前的 sql 语句,执行之后内缓存页的记录数是 49W。


5. 参考文献
https://tech.meituan.com/2014/06/30/mysql-index.html
https://zhuanlan.zhihu.com/p/52127386
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
https://www.modb.pro/db/52861
https://juejin.cn/post/6844904134261342216