
MySQL查询(select)优化--各种索引的使用

1、SQL提示
SQL提示是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
例如,使用索引(一种建议手段,若MySQL认为这种索引不合适就不会使用):
explain select * from tb_user use index(idx_user_pro) where profession="软件工程";
不使用哪个索引:
explain select * from tb_user ignore index(idx_user_pro) where profession="软件工程";
必须使用哪个索引:
explain select * from tb_user force index(idx_user_pro) where profession="软件工程";
use 是建议,实际使用哪个索引 MySQL 还会自己权衡运行速度去更改,force就是无论如何都强制使用该索引。
2、索引覆盖&&回表查询
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能找到),减少 select *。
例如:
-- 这里首先给出一个数据表
mysql> select * from tb_user;
+----+-----------------+----------------+-------------+--------------------------+------+--------+--------+---------------------+
| id | name | email | phone | profession | age | gender | status | create_time |
+----+-----------------+----------------+-------------+--------------------------+------+--------+--------+---------------------+
| 1 | 孙悟空 | 1111@qq.com | 11111111111 | 软件工程 | 500 | 1 | 1 | 2022-06-20 11:35:11 |
| 2 | 周瑜 | 1121@qq.com | 11111111112 | 软件工程2 | 50 | 1 | 0 | 2022-06-20 11:35:11 |
| 3 | 孙尚香 | 1113@qq.com | 11111111113 | 计算机科学与技术 | 30 | 2 | 2 | 2022-06-20 11:35:11 |
| 4 | 白龙马 | 1114@qq.com | 11111111114 | 飞翔科学 | 300 | 1 | 0 | 2022-06-20 11:35:11 |
| 5 | 唐曾 | 1115@qq.com | 11111111115 | 软件工程 | 50 | 1 | 5 | 2022-06-20 11:35:11 |
+----+-----------------+----------------+-------------+--------------------------+------+--------+--------+---------------------+
-- 里面有三个索引,主键索引 PRIMARY ,根据name的索引idx_user_name和根据phone的索引idx_user_phone
mysql> show index from tb_user;
+---------+------------+-----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible |
+---------+------------+-----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| tb_user | 0 | PRIMARY | 1 | id | A | 12 | NULL | NULL | | BTREE | | | YES |
| tb_user | 0 | idx_user_phone | 1 | phone | A | 12 | NULL | NULL | YES | BTREE | | | YES |
| tb_user | 1 | idx_user_name | 1 | name | A | 11 | NULL | NULL | YES | BTREE | | | YES |
+---------+------------+-----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
6 rows in set (0.05 sec)
-- 情况1
-- 使用explain执行计划查看下列语句,其中Extra为Using index,并且key为idx_user_name,这说明使用到了索引
-- 这是因为索引idx_user_name是一个非聚簇索引,在索引的叶子存放了当前数据的id,索引数据就是name,在SQL中,也只需要name和id两个字段,所以就不需要回表了。
mysql> explain select id,name from tb_user where name = '孙尚香';
+----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | tb_user | NULL | ref | idx_user_name | idx_user_name | 123 | const | 1 | 100.00 | Using index |
+----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 情况2
-- 在下面的explain执行计划中Extra 为NULL,说明整个操作要么没有使用索引,要么有回表操作,由key为idx_user_name可以看出使用name索引,但是在索引结构中没有SQL中需要的gender值,所以就必须回表操作才能回去到gender值。
mysql> explain select id,name,gender from tb_user where name = '孙尚香';
+----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | tb_user | NULL | ref | idx_user_name | idx_user_name | 123 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
-- 注意,数据库版本不同,环境不同时,有没有回表操作在Extra中的表现形式是不一样的。
-- 常见的还有using index condition:查找使用了索引,但是需要回表查询数据;using where; using index;:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询。
-- 笔者这里是Using index和NULL回表的详细过程请参考
悄悄绽放的海棠花:MySQL索引分类?在InnoDB 存储引擎中,使用聚簇索引和非聚簇索引的查询机制?
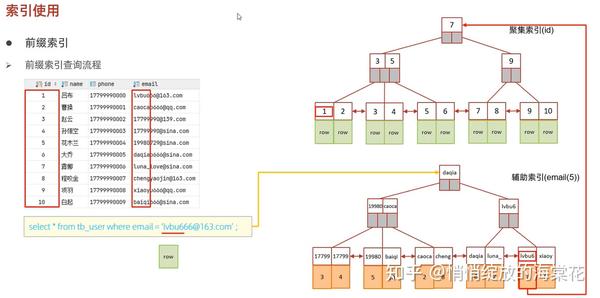
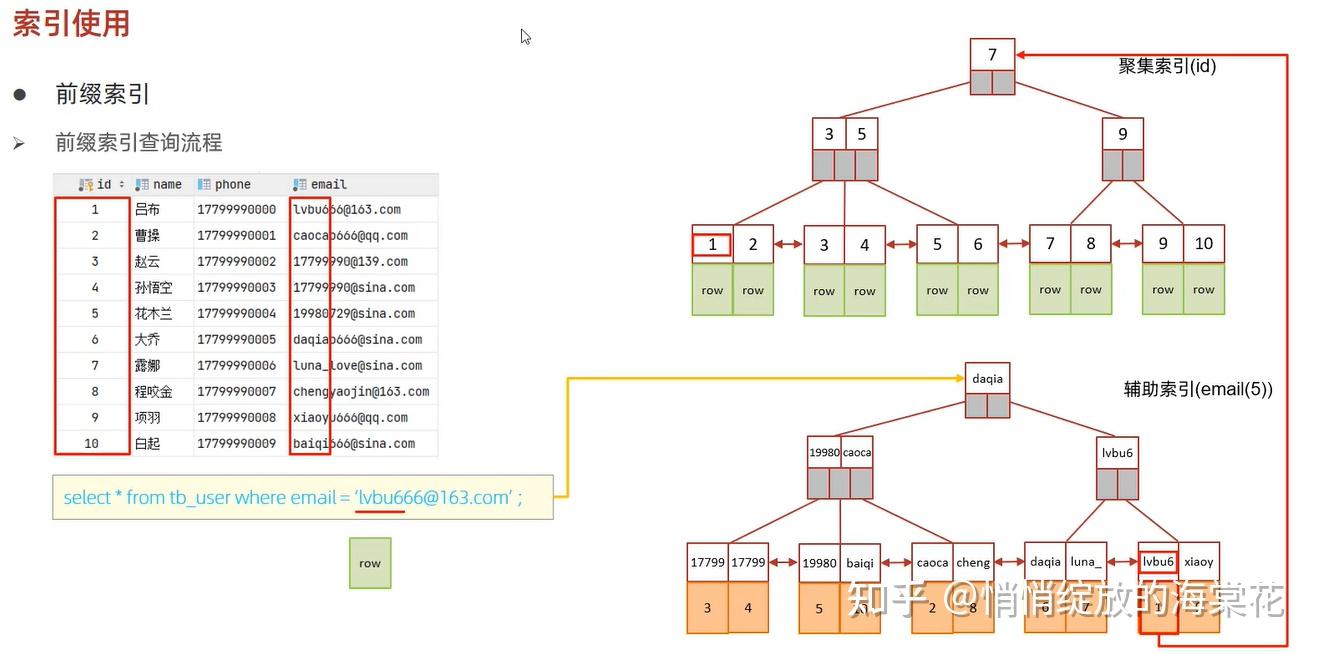
3、前缀索引
当字段类型为字符串(varchar, text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率,此时可以只降字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法:create index idx_xxxx on table_name(column(n)); 前缀长度:可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。 求选择性公式:
select count(distinct email) / count(*) from tb_user;
select count(distinct substring(email, 1, 5)) / count(*) from tb_user;show index 里面的sub_part可以看到接取的长度
mysql> create index idx_tb_user_email_4 on tb_user(email(4));
Query OK, 0 rows affected (0.16 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from tb_user;
+---------+------------+-----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible |
+---------+------------+-----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| tb_user | 0 | PRIMARY | 1 | id | A | 12 | NULL | NULL | | BTREE | | | YES |
| tb_user | 1 | idx_tb_user_email_4 | 1 | email | A | 11 | 4 | NULL | YES | BTREE | | | YES |
+---------+------------+-----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
7 rows in set (0.05 sec)前缀索引查询流程如下:
4、单例索引VS联合索引
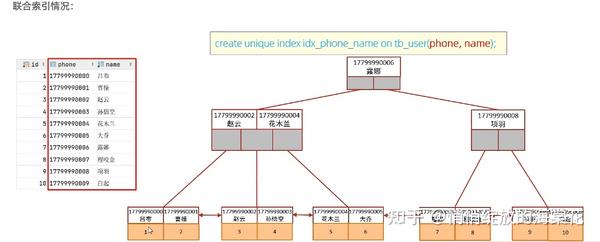
单列索引:即一个索引只包含单个列 联合索引:即一个索引包含了多个列 在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
-- 使用phone和email字段创建联合索引
mysql> create index idx_tb_user_phone_name on tb_user(phone,email);
Query OK, 0 rows affected (0.08 sec)
Records: 0 Duplicates: 0 Warnings: 0
-- 查看索引 idx_tb_user_phone_name
mysql> show index from tb_user;
+---------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible |
+---------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| tb_user | 0 | PRIMARY | 1 | id | A | 12 | NULL | NULL | | BTREE | | | YES |
| tb_user | 0 | idx_user_phone | 1 | phone | A | 12 | NULL | NULL | YES | BTREE | | | YES |
| tb_user | 1 | idx_user_name | 1 | name | A | 11 | NULL | NULL | YES | BTREE | | | YES |
| tb_user | 1 | idx_tb_user_phone_name | 1 | phone | A | 12 | NULL | NULL | YES | BTREE | | | YES |
| tb_user | 1 | idx_tb_user_phone_name | 2 | email | A | 12 | NULL | NULL | YES | BTREE | | | YES |
+---------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
9 rows in set (0.01 sec)
-- 我们可以看出在tb_user中,存在phone和name各自的单例索引(idx_user_phone和idx_user_name),也有他们两个组成的联合索引(idx_tb_user_phone_name)
-- 单列索引情况:从explain执行计划中可以看出,Extra为NULL,说明这个SQL存在回表操作,key为idx_user_phone,说明只是使用了phone形成的单列索引,这样效率会不高
mysql> explain select id, phone, name from tb_user where phone = '11111111113' and name = '孙尚香';
+----+-------------+---------+------------+-------+-----------------------------------------------------+----------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+-----------------------------------------------------+----------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | tb_user | NULL | const | idx_user_phone,idx_user_name,idx_tb_user_phone_name | idx_user_phone | 63 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+-----------------------------------------------------+----------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
-- 联合索引的情况,Extra为Using where表示没有回表,使用了idx_tb_user_phone_name联合索引,执行效率会高于使用单列索引。
mysql> explain select id, phone, name from tb_user use index(idx_tb_user_phone_name) where phone = '11111111113' and name = '孙尚香';
+----+-------------+---------+------------+------+------------------------+------------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+------------------------+------------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | tb_user | NULL | ref | idx_tb_user_phone_name | idx_tb_user_phone_name | 63 | const | 1 | 9.09 | Using where |
+----+-------------+---------+------------+------+------------------------+------------------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)使用联合索引查询流程如下:

5、索引设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
文章被以下专栏收录
