论文分享:对软机械臂闭环动态控制的基于模型的强化学习

题目:Model-Based Reinforcement Learning for Closed-Loop Dynamic Control of Soft Robotic Manipulators [1]
作者:Thomas George Thuruthel, Egidio Falotico, Federico Renda, and Cecilia Laschi
机构:The BioRobotics Institute, Scuola Superiore Sant'Anna, Pisa, Italy; the Department of Mechanical Engineering and the Center for Autonomous Robotics Systems, Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates
发表于期刊 IEEE Transactions on Robotics
(阅读本文章前建议首先阅读前置文章 [2], [3], [4], [5], [6],在之后的内容中,前置文章将默认已被阅读。)
0. 摘要
柔性机器人的动态控制是一个有待深入研究和分析的问题。目前大多数软机器人的应用都是基于关节空间的运动学模型或线性的静态或准动态控制器。然而,这样的方法并没有真正地利用软体系统的丰富动态。本文提出了一种基于模型的软机械臂闭环预测控制策略学习算法。用递归神经网络表示正向动力学模型。利用轨迹优化和监督学习的方法推导出闭环策略。首先在索驱动欠驱动软机械臂分段恒应变仿真模型上对该方法进行了验证。此外,我们在一个柔性气动驱动机械臂上实验演示了如何推导闭环控制策略,以适应可变频率控制和未建模的外部负载。
1. 前期知识
A. 实体机器人
本文采取两段式软体机器人作为实体机器人,如图1所示。

其中近端由三根线缆驱动,第二段无驱动。机器人状态由视觉追踪器记录。
B. 仿真模型
本文利用分段恒应变模型作为仿真模型,模型示意图与参数如图2所示。
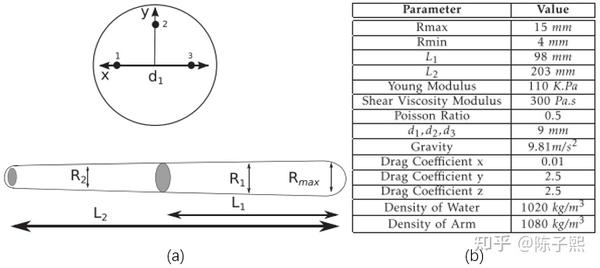
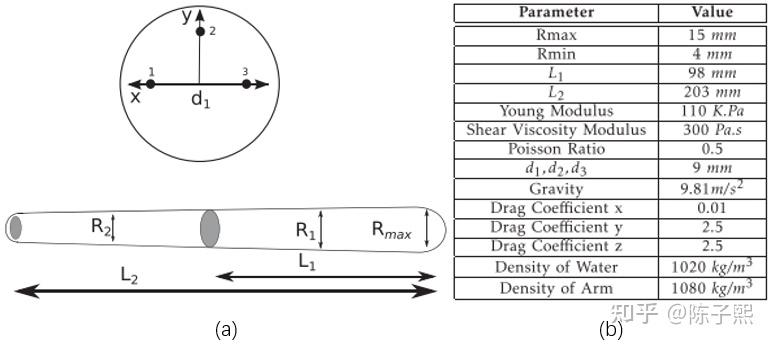
C. 正动力学模型
本文利用NARX网络作为正动力学模型,映射关系为 (\tau_i,x_i,x_{i-1})\rightarrow x_{i+1}, 其中 x_{i-1},x_i,x_{i+1} 是上一个、本个与下个时间点的机器人状态, \tau_i 代表本时刻的机器人控制信号。对于仿真,以100Hz的频率采样7000个样本,线缆驱动最大力为3N,对于实体机器人,以50Hz的频率采样12000个样本,并且只记录远端的三个标记点的位置。具体正动力学模型细节可以参考本文和[4]。
D. 轨迹优化
对于轨迹优化问题的目标函数、约束条件也可以参考[4]。需要注意的是,[4]使用的SQP计算太慢,无法在MPC中实现闭环控制,所以本文采用了导向策略搜索(guided policy search)。
2. 策略学习
首先,收集样本。为了尝试收集多样性强的样本,作者尝试利用优化法对于一个目标点生成不同的轨迹,优化目标如下
\Pi_n^p(t)^*=\min_\tau({\Vert x^{tip}_{\frac{t_f}{dt}}-x^{des}\Vert}^2-\alpha\ min[dist(X^n,X)*dist(X^n,X)]) ,(1)\\ X^n \triangleq \{x_1^n,x_2^n,\dots x_{\frac{t}{dt}-k}^n\},\\ X \triangleq \{ X^1, X^2,\dots X^{n-1}\}\\ \forall\ n=1\dots N\ \forall\ p=1\dots P\\ 其中参数 \alpha 即可控制轨迹的多样性,参数 k 为每个轨迹的时间长度。基于该策略收集到的数据,训练一个神经网络控制器,映射为 (x_i,x_{i-1},x^{des})\rightarrow\tau_i .综上,控制器训练策略如图3所示。


对于仿真实验,作者对于65个随机目标生成各20个轨迹,而对于实际实验,由于正向动力学模型的误差,增加的轨迹会引起更大的误差,所以作者随机选择了200个目标,每个目标1个轨迹作为控制器的训练数据。
3. 仿真结果
在本段中,利用神经网络控制器作为控制器,并且将控制策略实行在仿真模型中。
A. 全局动态到达
为了验证控制器在工作空间中动态到达目标点的能力,作者随机选择50个目标点,并在仿真模型中进行试验。控制器的策略对于NARX模型与仿真模型而产生的误差如表1所示。


B. 外部干扰下的到达
为了验证此闭环控制系统的鲁棒性,在到达任务中随机进行瞬时干扰,受干扰的机器人运动轨迹如图4所示。不同干扰情况对于末端误差与到达时间的影响如图5所示。可见此闭环控制对外部干扰有很强的鲁棒性。




C. 多点到达
之前的实验都以原点作为起始点,为了验证该控制器对于其他点作为起点的情况的表现,作者提出了多点到达任务,即让机器人连续到达两个随机点。多点到达的误差如表2所示,其中一个轨迹示意图如图6。结果显示,尽管第二个目标点的到达需要更长时间,该控制器也能很好地完成多点到达任务。




D. 改变控制频率
尽管训练集的数据是以100Hz的频率收集,此控制器也可应用在更低频率上,不同的控制频率的效果示意图如图7所示,控制信号如图8所示。可见改变控制频率对到达误差与时间影响不大,但是控制信号更不光滑,对实际实验比较有参考意义。




4. 实际实验
A. 全局动态到达
全局动态到达的误差如表3,两个轨迹示意图如图9。




尽管该控制器能达到目标点,但是和模拟实验相比,机器人运动情况有更大的不确定性,这一现象可由同一起点的不同轨迹所体现。一个可能的解释是由机器人的高度非线性与随机摩擦的影响,气动腔的滞回效应也是可能的原因之一,还有原点在实际实验中的不确定性。
B. 低频到达
将控制器从20Hz降低到10Hz,机器人末端误差如表4所示。如仿真情况相同,控制器效果更差,甚至有无法到达的情况。

C. 负载下到达
相比于开环控制,闭环控制的好处就是可以处理一些位置的扰动和影响,比如机器人末端的未知负载。在有105g负载情况下的机器人末端误差如表5所示,一个轨迹如图9所示。在图9中可以看到软体机器人由于负载需要一定时间的“能量存储”期,才能把末端“悠”到目标位置。




参考
- ^Thuruthel T G, Falotico E, Renda F, et al. Model-based reinforcement learning for closed-loop dynamic control of soft robotic manipulators[J]. IEEE Transactions on Robotics, 2018, 35(1): 124-134. https://ieeexplore.ieee.org/abstract/document/8531756
- ^论文分享:针对连续软体机器人的逆运动学学习解 https://zhuanlan.zhihu.com/p/570058144
- ^论文分享:非结构环境中连续体机械臂的闭环运动学控制器学习 https://zhuanlan.zhihu.com/p/570245062
- ^论文分享:针对受章鱼启发的软体机械臂的动力学学习与轨迹优化 https://zhuanlan.zhihu.com/p/570475520
- ^论文分享:软体机械手的稳定开环控制 https://zhuanlan.zhihu.com/p/570473808
- ^论文分享:用于控制器设计及刚度估计的柔性机器人机械臂的诱导振动 https://zhuanlan.zhihu.com/p/575590492
文章被以下专栏收录
