HRBI | 一文厘清如何使用PowerBI计算员工表的入职人数、在职人数、离职人数、离职率

复盘下:文章写于2023年1月,用了3天时间学习powerbi,7天时间做出来看板。那时只是个初学者,但是满腔热情,技术不是太成熟,入门要感谢孙兴华,在职人数要感谢BI佐罗的帖子。大差不差,基本公式没有大问题,只是规不规范的小问题。
时间现在到了五月,比之前更成熟了,已经给薪酬做出来了一个看板,近期打算把这个完整的项目做成教程,持续更新,专门针对人力资源的场景,还会对比excel,powerbi结合讲解,甚至会做出来excel和powerbi的两种看板版本,以及更贴近业务场景。有兴趣可以关注我,私信+V
想要做出这样的仪表盘,最基本的是要厘清下面几个离职人数、入职人数、在职人数的相关数据

(一)离职
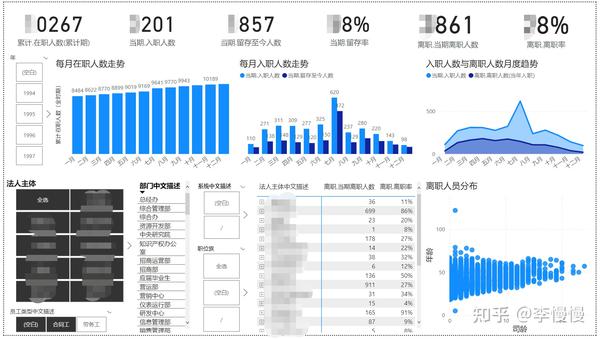
下图包含了日期筛选器、公司筛选器(未在图中显示),可视化对象,也就是把公司、部门作为行,四个离职指标作为值放入了矩阵,并按照年份、公司进行了筛选。
这四个指标各有不同含义,下面每个指标我都附了DAX语言代码,得到我下面这个图。我会每个指标单独说,并结合excel里面的原始数据向你讲解。每个指标可以对照下面的图,以及excel里面的原始数据,加深理解。


1、当年入职后又离职的人数
(注1:不包含所筛选日期之前的年份;注2:只包含2020年入职的员工)
离职.离职人数(当年入职) = CALCULATE(COUNTROWS(
FILTER('花名册','花名册'[离职日期]<>BLANK()))
)
//如果筛选2020年,那么数据会先挑出只有2020年入职的员工,随后再找出离职日期不为空的员工,统计人数
//为什么会先挑出只有2020年入职的员工呢?
//目前数据模型中日期表和花名册是按[入职日期】建立表关系的(实线),外部筛选器加会先筛选2020年入职的人员
//解决方法是使用USERELATIONSHIP('花名册'[离职日期],'日期表'[Date])(2中讲解)
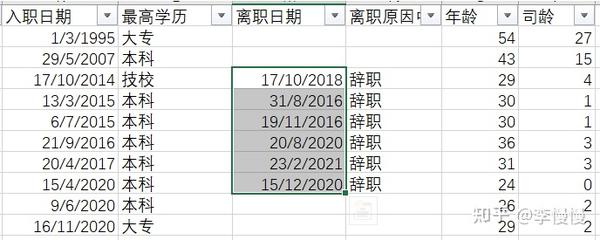
//那么就会日期表和花名册是按[离职日期】建立表关系(由虚线变为实线),此时就会筛选离职日期为2020年的员工在excel中找出原始数据,筛选出该部门2020年以前的入职的数据信息,确实只有一个2020年当期入职且在当期离职的员工。


但事实上,我们谈离职人数的时候,是不管他哪一年入职的,只要在当期离职的,都会算是离职人员
你可能以为上面的写法可以得出当期离职人员,事实上有可能(只是有可能)你和我出现过一样的问题
2、当期离职人数
(注1:不包含所筛选日期之前的年份;注2:只包含2020年入职的员工)
离职.当期离职人数 = CALCULATE(COUNTROWS(FILTER('花名册','花名册'[离职日期]<>BLANK())),
USERELATIONSHIP('花名册'[离职日期],'日期表'[Date]))首先要明确,那我们在使用外部筛选器(也就是筛选年份)的时候,他到底是按照两个表的已经连接的字段去筛选的。
下图是PowerBI中数据模型中,可以看到我们花名册和日期表通过离职日期、入职日期两个字段连接的。那么筛选的到底是筛选离职日期为2020年的数据,还是入职日期为2020年的数据呢?
先看模型,一条是实线,一条是虚线,实线是表示被激活的关系,被激活也就是目标的表关系是入职日期生效,鼠标放是线上会看到对应入职日期;虚线表示的是未被激活的日期,这里对应的是离职日期,因为未被激活,实际此表关系未生效,也就是默认会筛选入职是2020年的员工。
但是,我们可以使用USERELATIONSHIP来激活离职日期的连接关系,上述用法只筛选出2020年离职的员工,而让入职日期的连接关系失效了。


现在你看excel的2020年当期正是两个人离职,且没有受到入职日期的限制


总的来说,这个指标应该是我们习惯用到的离职人数,我们一般说离职人数都默认是某一段时期内的,比如今年、去年、本月的离职人数,只要在日期筛选器里筛选,这个指标帮你实现的就是这种。也就是,这里的离职人数,你选哪一年的就是哪一年的离职人数。
如果还是没有理解USERELATIONSHIP的用法,可以参考我另一篇文章,有更详细的解说
李慢慢:HRBI | PowerBI计算离职人数的坑——表关系激活:USERELATIONSHIP的运用
但是,如果你想要显示2020年及2020年以前所有离职的人数,怎么做?
虽然这种累计的往年离职人数应用的场景其实相当少,但是弄清楚这点也是有意义的。我们举一反三,换个变量,如果你想要的是[在职人数]而不是[当期离职人数]呢,所谓的[在职人数]其实就是累计所有往年的[入职人数],这个就是必要得了。不过先不说入职和在职人数,还是回到累计的离职人数,到底怎么计算,请看下面示例
3、累计离职人数(全时期):累计当期及往期所有离职的人数
(注1:包含所筛选日期之前所有年份;注2:离职的人员只包含2020年及之前所有入职人员,不包含2020年之后入职的人员,但是会包括2020年后离职的人员)
离职.累计人数(全时期) =
CALCULATE(
[离职.离职人数(当年入职)],
FILTER(ALL('日期表'[Date]),'日期表'[Date] <= MAX('日期表'[Date])),
'花名册'[离职日期] <> BLANK()
)
//会累计所有小于所筛选日期的最大值的所有离职人员,假如筛选2020年,则会累计2020年12月31日之前所有离职人员累计2020年前入职的人里离职的人数,下面选中的六个离职都被计算在内了,尤其要注意那个2021年离职的也计算在内。


实现这种累计的离职人数有一个关键,一个坑
一个关键:ALL的作用,让筛选上下文失效,所有年份的数据都进来了,注意我说的进来,是以'入职日期'为连接[日期表]和[花名册]的表关系的(而不是'离职日期'),又因为加了条件'日期表'[Date] <= MAX('日期表'[Date]),所以筛选出了2020年及之前入职的员工。
一个坑:这里只限定了离职日期。上面说只筛选出了2020年及之前的员工(事实上还是我们写了条件才限定的),但在2020年之后离职的人,是不会被去掉的,因为离职日期是不被判断的,只有入职日期被判断(如果你掌握USERELATIONSHIP,就一定能理解这一点)。所以你看到那6个离职的人员,里面那个2021年离职的,就是我所说的没有被你筛选日期所去掉的。所以必须要注意这一点,即使你筛选2020年,仍会包括2022年离职的人员。
注意,这个指标可以发挥的场景比较少,但也有运用的场合,比如计算特定时期/类型的人员的流失率/不合格率。
一、计算流失率,比如公司从2010年开始建立管培生体系,此后每年都引入一批管培生,投入了巨大资源。那么现在是2022年,但你只想知道2020年及2020年之前,所有管培生的流失率,那么就要用这种累计离职人数。为什么呢?因为你人是2020年之前进来的,但2022年流失了你也得算上啊。当然计算流失率,你还得再计算一个累计入职的人数,流失率 = 累计这批管培生已经离职的人数/ 累计202入职人数
二、比如你以前拿到了融资,2020年前高薪引进了一批职业经理人。但是2020年后你钱没了,此后引进的职业经理人和往年标准没法比。所以你只关心2020之前引进的那批职业经理人的流失率,也可以用这种。
三、培训,一般有些培训是分期,那一年就是那一期,你想知道那一期之前中途退出/被淘汰/不合格的人,和所有纳入那期培训计划完成/达标/优秀的人,通过这两个数计算出一个培训成功率。那一期往前所有中途退出/被淘汰/不合格的人的计算方式是一样的。
四、考试通过率。比如说法考、CPA都说这几年通过率越来越高,那就可以做一个今年通过率,和往年所有人通过率的比较。
五、某类客户的流失率
好吧,正是觉得他很少被应用,反而想出了很多应用的场景。
回到正题,这个指标的问题在于他把你筛选日期后面离职的人员也算上了,如果不想算上的话,请见下面的示例。
4、累计离职人数(累计期):累计当期及往期所有离职的人数
(注1:包含所筛选日期之前所有年份;注2:离职的人员只包含2020年及之前所有入职及离职的人员,2020年之后就完全不管了)
离职.累计人数(累计期) = CALCULATE([离职.当期离职人数],
FILTER(ALL('日期表'[Date]),'日期表'[Date] < MAX('日期表'[Date])),
'花名册'[离职日期]<>BLANK() || '花名册'[离职日期] <= MAX('日期表'[Date])
)
//算的只是往年至筛选器当期入职的且在这段时期尚在职的人数这里是5个人被计算在内,去除了2021年离职的人员。


小结:
3、4两个累计离职人数:其实入职和离职的范围都是你自己限定的,只要通过MAX和MIN函数就可以根据外部筛选器筛选上下文,三四的区别也就是最后那句'花名册'[离职日期]<>BLANK() || '花名册'[离职日期] <= MAX('日期表'[Date]),但这都是你自己写出来的,完全看你的需求灵活应变。
(二)入职、在职
老规矩,还是上四个入职、在职人数的相关指标,放入矩阵,还是筛选那个部门,筛选2020年,四个指标结果显示如下图:


1、在档人数
(只要曾经入职过,在花名册记录中即计入在档人数)
累计.在档人数 =
CALCULATE(
DISTINCTCOUNT('花名册'[员工编号]),
FILTER(ALL('日期表'[Date]),'日期表'[Date] <= MAX('日期表'[Date]))
)只要理解离职那块,这个指标很好理解,也用了ALL使上下文失效,然后用MAX让外部筛选器生效,限制统计当期及以前的累计的所有记入花名册的员工。
从excel中看,正好是十人(已包含所有曾入职的人数)

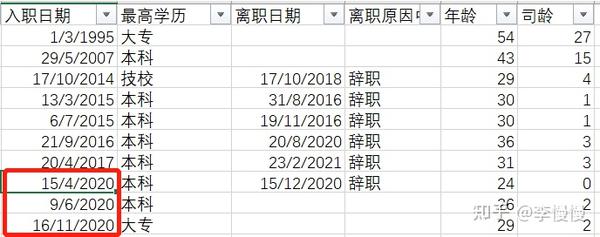
2、当期入职人数
(注:只包含当期2020年入职的人数)
当期.入职人数 = CALCULATE(
DISTINCTCOUNT('花名册'[员工编号]),
FILTER('花名册',
'花名册'[入职日期] <= MAX('日期表'[Date]) && '花名册'[入职日期] >= MIN('日期表'[Date])
)
)
//在筛选日期入职的员工数量2020年有三人入职,而非2020年入职的都未计算在内

3、累计在职人数(全时期)
(注1:显示为2020年当期及所有往期入职的,仍在职的人数;注2:这里的在职得是至今还在职,也就是2022年还在职,2020在职但2021年离职的则不算在内)
累计.在职人数(全时期) =
CALCULATE(
DISTINCTCOUNT('花名册'[员工编号]),
FILTER(ALL('日期表'[Date]),'日期表'[Date] <= MAX('日期表'[Date])),
'花名册'[离职日期] = BLANK()
)这里与之前的累计离职人数是同样的道理,用ALL让筛选上下文失效,再用MAX筛选出当期以前入职的员工。
从原始数据看到四个人是在2020年及之前入职的,但至今仍在职的。同时也要看到有一个2021年才离职的,并没有算上他。


4、累计在职人数(累计期)
(注1:显示为2020年当期及所有往期入职的,仍在职的人数;注2:只要2020当期在职都会算入在在职人数)
累计.在职人数(累计期) =
CALCULATE(
DISTINCTCOUNT('花名册'[员工编号]),
FILTER(ALL('日期表'[Date]),'日期表'[Date] <= MAX('日期表'[Date])),
'花名册'[离职日期] = BLANK() || '花名册'[离职日期] > MAX('日期表'[Date])
)下面的表格看到是累计在职人数是5个人没错。尤其要理解那个离职在2021年的数据,他虽然是2021年离职,但是他2020年仍在职,那么就会被计入在职人数了。


这种统计口径就是我们习惯用的在职人数,因为我们说在职人数往往说的是那个时期的在职人数,本年、去年、上个月的所有在职人数,去年的在职的人尽管今年离职了,我们在统计去年在职人数的时候仍然会算上他。
(三)离职率、留存率
这里使用的离职率计算方式为:离职率 = 离职人数 / (离职人数 + 在职人数),因此在PowerBI中公式为,
离职.离职率 = [离职.当期离职人数] / ([离职.当期离职人数]+[累计.在职人数(累计期)])这里踩过的坑是,试过把[累计.在职人数(累计期)]、[在档人数]都当成过分母。