切换模式
用 ChatGPT 生成 VAE 模型代码

Arino
CS专业研究生在读,编程爱好者
最近在学习 VAE 的时候,上网找了很多代码,发现质量参差不齐,东拼西凑花了好几天才写好一份像样的代码,遂尝试使用 ChatGPT生成训练模型的代码。
可以看到,一个简单的问题,ChatGPT分分钟就把代码全写完了,如下:
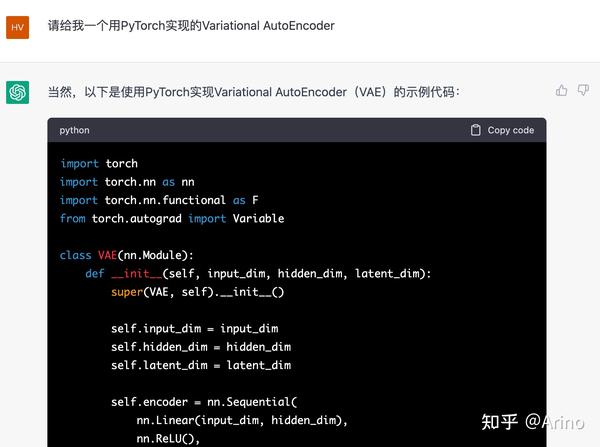

全部代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU()
)
self.mu_layer = nn.Linear(hidden_dim, latent_dim)
self.logvar_layer = nn.Linear(hidden_dim, latent_dim)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim),
nn.Sigmoid()
)
def encode(self, x):
h = self.encoder(x)
return self.mu_layer(h), self.logvar_layer(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x.view(-1, self.input_dim))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
def loss_function(recon_x, x, mu, logvar):
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
# 加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
# 初始化模型、优化器和损失函数
vae = VAE(input_dim=784, hidden_dim=256, latent_dim=20)
optimizer = torch.optim.Adam(vae.parameters(), lr=1e-3)
loss_fn = loss_function
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = Variable(data)
optimizer.zero_grad()
recon_batch, mu, logvar = vae(data)
loss = loss_fn(recon_batch, data, mu, logvar)
loss.backward()
total_loss += loss.item()
optimizer.step()
avg_loss = total_loss / len(train_loader.dataset)
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, avg_loss))
总的来说,代码写的还是相当不错的,非常简洁易懂,适合初学者学习。这里数据集采用的是 MNIST,encoder 和 decoder 网络采用的是最基本的网络模型,只用了 nn.Linear 和 nn.ReLU ,最后一层输出的时候用了一个 nn.Sigmoid ,把输出压缩到 [0, 1](因为我们的图片在输入前被 normalize 到了 [0, 1],输出的 range 需要匹配输入的 range 才能计算 reconstruction loss)。
VAE 模型里最重要的几个概念,reparameterization trick (重参数化技巧),损失函数里的 reconstruction loss 和 KL 散度在代码之中都有体现,唯一不足的是少 import 了几个包,代码运行不了,然后经过我自己的一点修改现在代码就可以运行了,现在我的代码名为chatgpt_vae.py,全部代码如下:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, hidden_dim), nn.ReLU()
)
self.mu_layer = nn.Linear(hidden_dim, latent_dim)
self.logvar_layer = nn.Linear(hidden_dim, latent_dim)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim),
nn.Sigmoid(),
)
def encode(self, x):
h = self.encoder(x)
return self.mu_layer(h), self.logvar_layer(h)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
return self.decoder(z)
def forward(self, x):
mu, logvar = self.encode(x.view(-1, self.input_dim))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
def loss_function(recon_x, x, mu, logvar):
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction="sum")
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
if __name__ == "__main__":
# 加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(
root="./data", train=True, download=True, transform=transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
# 初始化模型、优化器和损失函数
vae = VAE(input_dim=784, hidden_dim=256, latent_dim=20)
optimizer = torch.optim.Adam(vae.parameters(), lr=1e-3)
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):
total_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = Variable(data)
optimizer.zero_grad()
recon_batch, mu, logvar = vae(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
total_loss += loss.item()
optimizer.step()
avg_loss = total_loss / len(train_loader.dataset)
print("Epoch [{}/{}], Loss: {:.4f}".format(epoch + 1, num_epochs, avg_loss))
torch.save(vae.state_dict(), "data/vae.pth")
代码训练完后,模型参数被保存在了 "data/vae.pth",我们再写一个用模型生成图片的代码,名为 chatgpt_vae_generate.py,全部代码如下:
import torch
import matplotlib.pyplot as plt
from chatgpt_vae import VAE
if __name__ == "__main__":
latent_dim = 20
vae = VAE(input_dim=784, hidden_dim=256, latent_dim=latent_dim)
vae.load_state_dict(torch.load("data/vae.pth"))
# Generate some samples from the VAE
vae.eval()
with torch.no_grad():
z = torch.randn(16, latent_dim)
x_hat = vae.decode(z)
# Plot generated images
fig, axs = plt.subplots(4, 4, figsize=(5, 5))
for i in range(4):
for j in range(4):
axs[i, j].imshow(x_hat[i * 4 + j].view(28, 28), cmap="gray")
axs[i, j].axis("off")
plt.show()
生成的图片如下:


总结
ChatGPT 生成模型代码的能力还是很强大的,感觉以后深度学习初学者没必要上 Kaggle 那些个地方找代码了,花了一大堆时间发现都没什么用,直接问问神奇的 ChatGPT 就完事儿了,省时又省力。
发布于 2023-03-09 10:05・IP 属地北京
建筑模型
OpenAI