
PPO 算法

最近火出圈的 RLHF 主要采用了就是 PPO 进行强化学习训练
主要运用在微调阶段(微调整个 10B~100B+ 参数的成本其实也非常高 )使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (PPO) 微调初始 LM 的部分或全部参数。
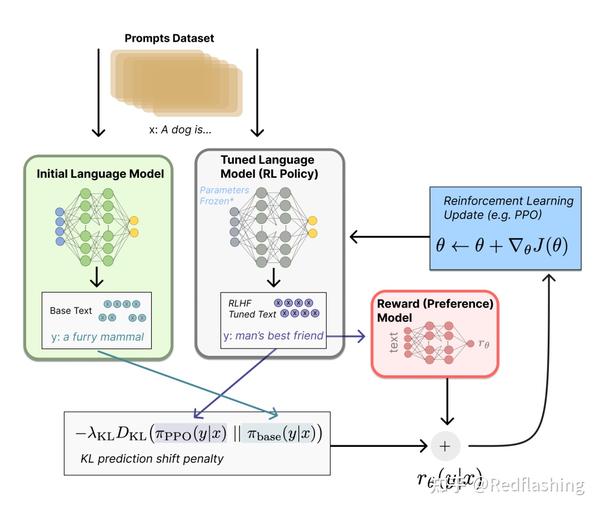
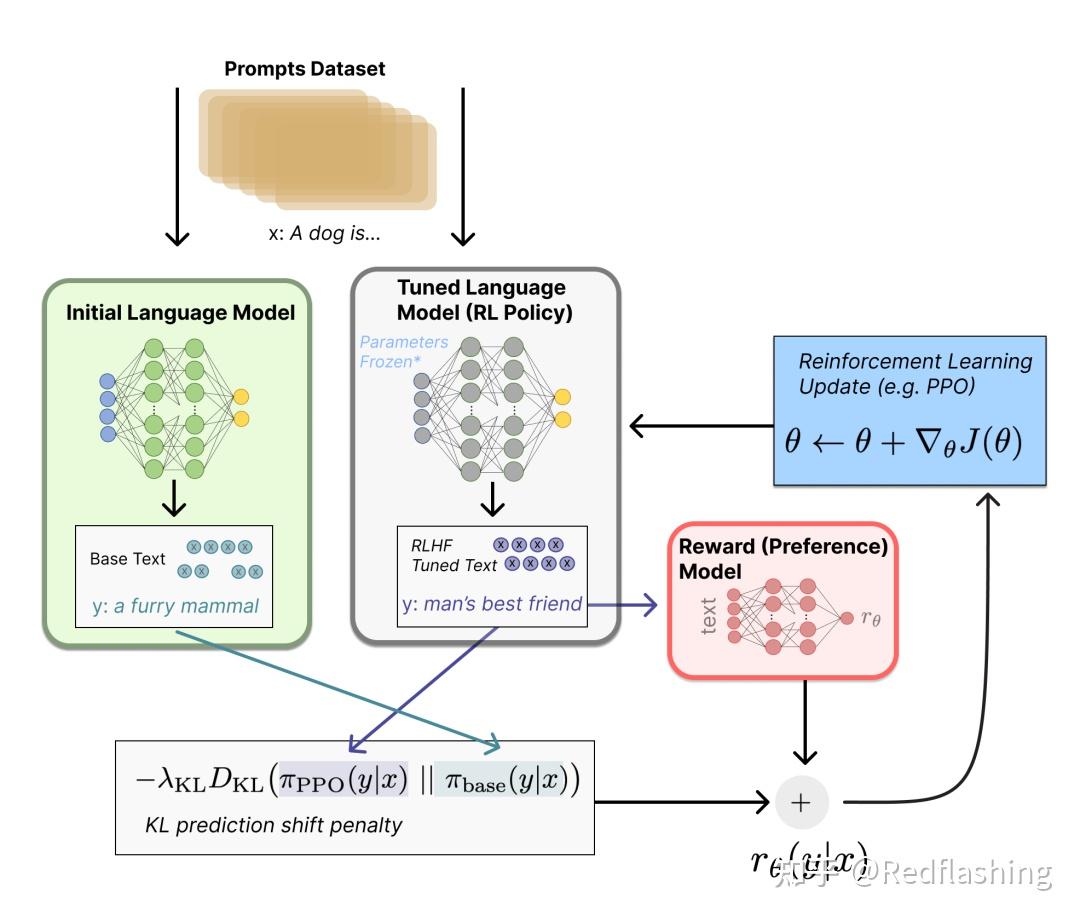
以下主要参考台大李宏毅的推导过程
1. Vanilla policy gradient
- 动作/环境/奖励之间的关系:


轨迹可以表示为一个集合 \tau = \{s_1,a_1,s_2,a_2,...,s_T,a_T\}
\begin{equation} \begin{aligned} p_{\theta}(\tau)&=p(s_1)p_{\theta}(a_1|s_1)p(s_2|s_1,a_1)p_{\theta}(a_1|s_1)p(s_3|s_2,a_2)...\\ &=p(s_1)\prod_{t=1}^T p_{\theta}(a_t|s_t)p(s_{t+1}|s_t,a_t) \end{aligned} \end{equation} \\
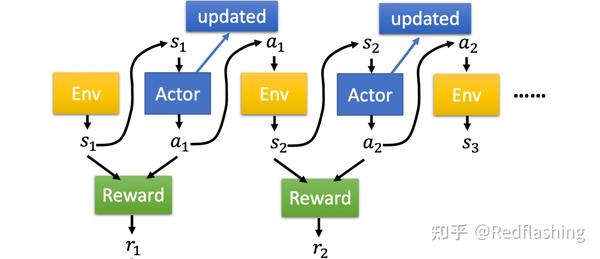
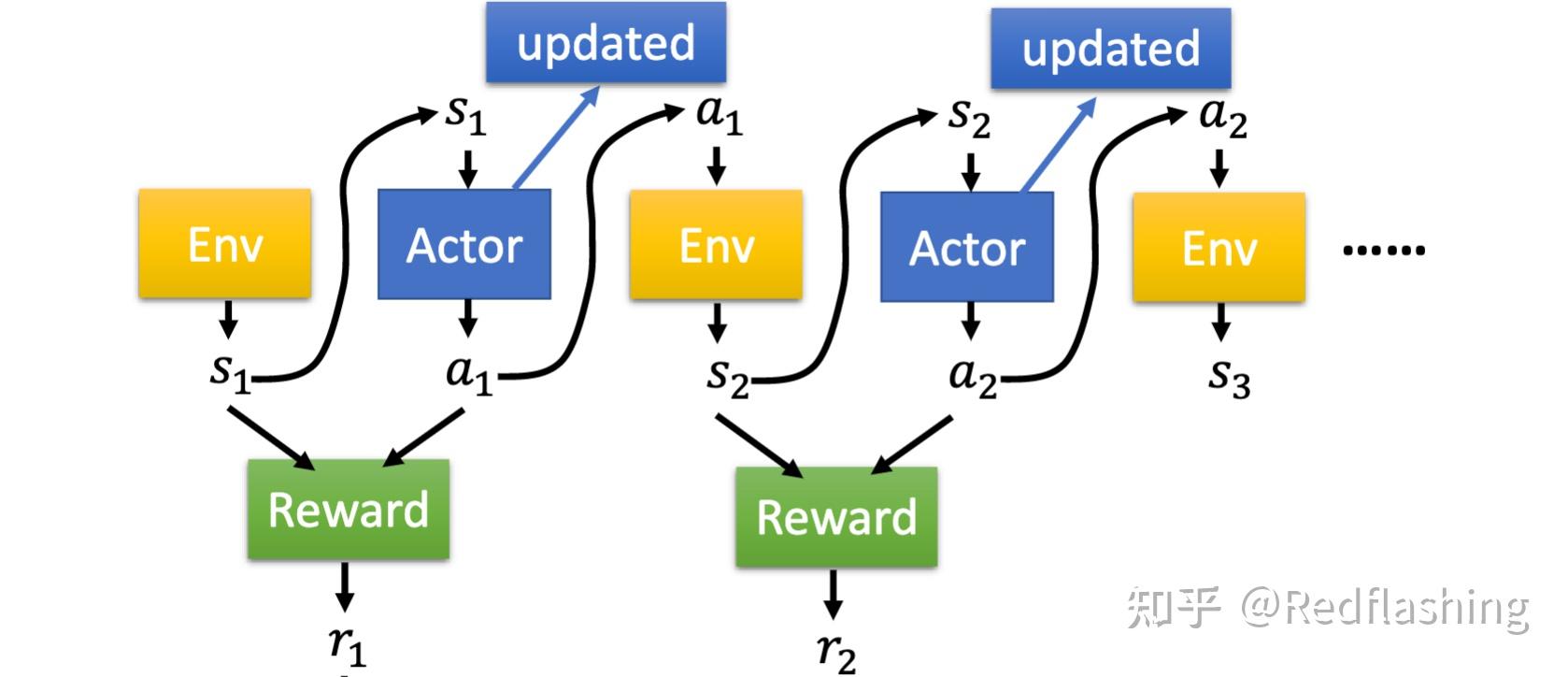
一个轨迹的奖励总和为:
R(\tau)=\sum_{t=1}^T r_t \\
则奖励的期望为:
\bar{R}_\theta = \sum_{\tau}R(\tau)p_\theta(\tau)=E_{\tau\sim p_\theta(\tau)}[R(\tau)] \\
将 R(\tau) 看成常量,对其求微分:
\begin{equation} \begin{aligned} \nabla\bar{R}_\theta &= \sum_{\tau}R(\tau)\nabla p_\theta(\tau)\\ &=\sum_{\tau}R(\tau)p_\theta(\tau) \frac{\nabla p_\theta(\tau)}{p_\theta(\tau)}\\ &=\sum_{\tau}R(\tau)p_\theta(\tau)\nabla\log{p_\theta(\tau)} \ \ \ {\nabla f(x)=f(x)\nabla\log f(x)}\\ &= E_{\tau\sim p_\theta(\tau)}[R(\tau)\nabla \log p_\theta(\tau)]\\ &\approx \frac{1}{N} \sum_{n=1}^N R(\tau^n)\nabla \log p_\theta (\tau^n) \\ &= \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} R(\tau^n)\nabla \log p_\theta(a_t^n|s_t^n) \end{aligned} \end{equation} \\
策略网络梯度更新:
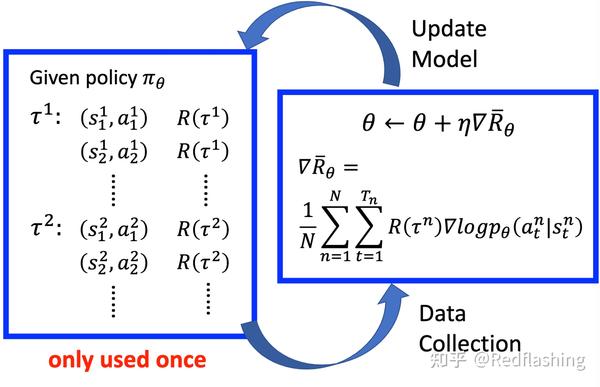
可以看成一个分类问题(游戏中通过键盘输入来互动,分类类别为所有可操作的键位):

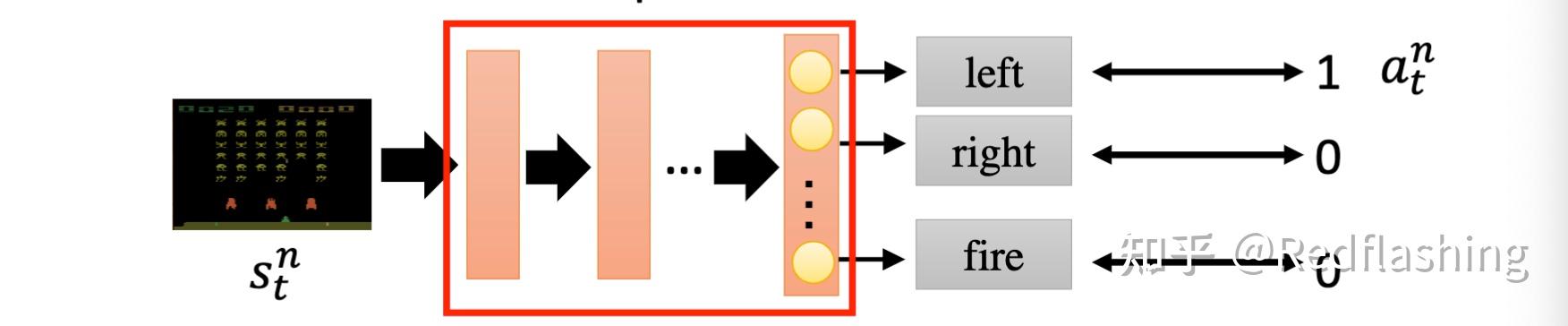
- 理想情况下,R(\tau^n) 并不一直为正数,增加一个 baseline:
\nabla\bar{R}_\theta= \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} (R(\tau^n) {-b} )\nabla \log p_\theta(a_t^n|s_t^n)\\ {b \approx E[R(\tau)]} \\
在电子游戏中,奖励值常常为正(通常为游戏分数)。这时需要增加一个偏置来保证同时有正样本和负样本
- 分配合适的学分
一个高分的游戏轨迹中也可能存在错误的动作,同样的,一个低分的游戏轨迹也可能存在正确的动作,而上文中的计算将最后的奖励值(最后的游戏分数)都一视同仁视为该游戏轨迹每个动作的学分。
为了更准确地描述每个动作所得到的学分,将一个动作执行后对应的学分为后续的所有奖励值的总和

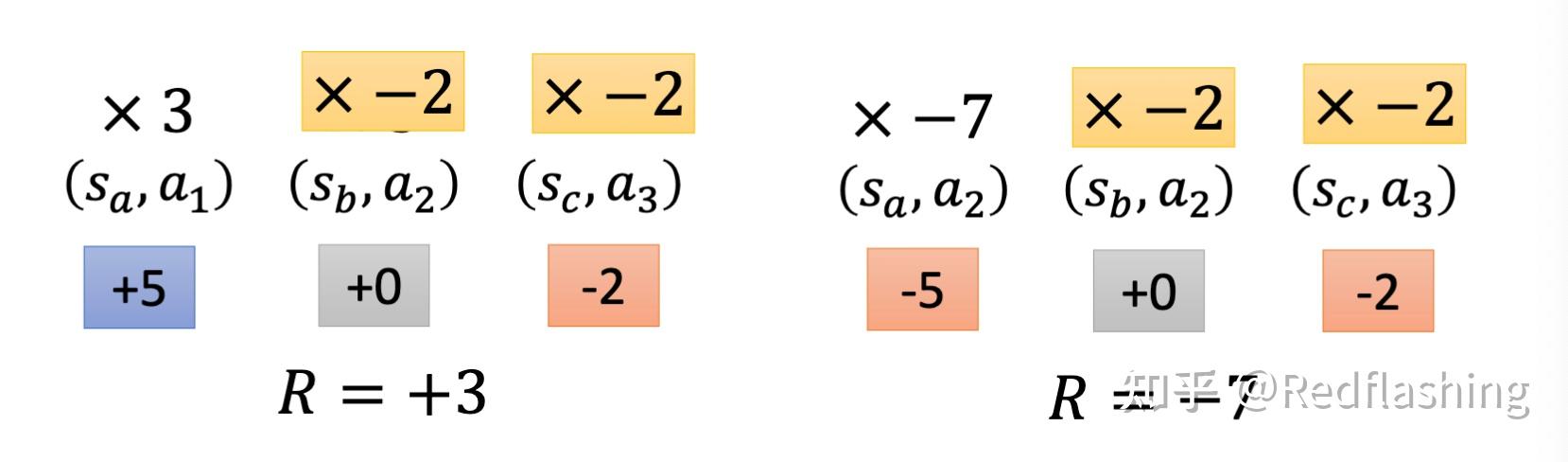
\nabla\bar{R}_\theta= \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} ({R(\tau^n)} -b )\nabla \log p_\theta(a_t^n|s_t^n)\\ \Downarrow\\ \nabla\bar{R}_\theta= \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} ({\sum_{t'=t}^{T_n} r_{t'}^n} -b )\nabla \log p_\theta(a_t^n|s_t^n) \\
当某个动作执行以后,其对后续的奖励分数的影响在慢慢减少,再增加一个衰减因子:
\nabla\bar{R}_\theta= \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} ({\sum_{t'=t}^{T_n} r_{t'}^n})\nabla \log p_\theta(a_t^n|s_t^n)\\ \Downarrow\\ \nabla\bar{R}_\theta= \frac{1}{N} \sum_{n=1}^N \sum_{t=1}^{T_n} ({\sum_{t'=t}^{T_n} \gamma^{t'-t} r_{t'}^n} -b )\nabla \log p_\theta(a_t^n|s_t^n),{\gamma<1} \\
2. 从 on-policy 到 off-policy
两者区别:
- On-policy:学习到的 agent 和与环境交互的 agent 是相同的,每一次梯度更新都需要重新采样
- Off-policy:学习到的 agent 和与环境交互的 agent 是不同的,每次梯度更新不需要重新采样
重新看看 \nabla\bar{R}_\theta 的表达式:
\nabla\bar{R}_\theta = E_{{\tau\sim p_\theta(\tau)}}[R(\tau)\nabla \log p_\theta(\tau)] \\
- 使用策略网络 \pi_\theta 收集数据。当 \theta 更新后,则需要重新收集训练样本
- 目标:使用相同的样本(通过 \pi_{\theta'} 采样)训练 \theta。其中 \theta' 为固定的,因此我们可以重复使用其样本数据
2.1 重要性采样(Importance Sampling)
考虑一个场景,假如正在尝试计算函数 f(x) 的期望值,其中 x \sim p(x) 服从某种分布。则对 E(f(x)) 有以下估计:
E_{x\sim p}[f(x)] = \int f(x)p(x)dx \approx \frac{1}{n} \sum_i f(x_i) \\
蒙特卡洛抽样方法是简单地从分布 p(x) 中抽出 x,然后取所有样本的平均值来得到期望值的估计。那么问题来了,如果 p(x) 非常难取样怎么办?是否能够根据一些已知的、容易抽样的分布来估计期望值?
答案是肯定的。公式的一个简单转换就可以做到
E_{x \sim p}[f(x)] = \int f(x)p(x)dx = \int f(x)\frac{p(x)}{q(x)}q(x)dx =E_{x \sim q}[f(x){\frac{p(x)}{{q(x)}}}] \\
其中 x 从分布 q(x) 中采样,q(x) 不应为 0。通过这种方式,估计期望能够从另一个分布 q(x) 中采样, p(x)/q(x) 是称为采样率或采样权重,它作为校正权重以抵消来自不同分布的概率采样。
- 重要性采样的缺陷
虽然重要性采样保证了期望的一致,但是这里来计算一下方差是否一致
方差的计算:
Var[X] = E[X^2] - (E[X])^2 \\
分别计算方差:
Var_{x\sim p}[f(x)] = E_{x\sim p}[f(x)^2] - (E_{x\sim p}[f(x)])^2 \\ \begin{equation} \begin{aligned} Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]&=E_{x\sim q}[(f(x)\frac{p(x)}{q(x)})^2] - (E_{x\sim q}[f(x)\frac{p(x)}{q(x)}])^2\\ &=E_{{x\sim p}}[f(x)^2{{\frac{p(x)}{q(x)}}}]-(E_{{x\sim p}}[f(x)])^2\\ \end{aligned} \end{equation} \\
可以发现两者虽然期望相等但方差并不一致
2.2 从 on-policy 到 off-policy
我们使用重要性采样将 on-policy 调整为 off-policy
\nabla\bar{R}_\theta = E_{{\tau\sim p_{\theta'}(\tau)}}[{\frac{p_{\theta}(\tau)}{p_{\theta'}(\tau)}}R(\tau)\nabla \log p_\theta(\tau)] \\
- 从 \theta' 采样得到数据集
- 使用该 数据集多次训练 \theta
梯度更新过程:
\begin{equation} \begin{aligned} &= E_{(s_t,a_t)\sim \pi_\theta}[A^{\theta}(s_t,a_t)\nabla \log p_\theta (a_t^n|s_t^n)]\\ &=E_{(s_t,a_t)\sim {\pi_{\theta'}}}[{\frac{p_\theta (s_t,a_t)}{p_{\theta'} (s_t,a_t)}A^{\theta'}(s_t,a_t)}\nabla \log p_\theta (a_t^n|s_t^n)]\\ &=E_{(s_t,a_t)\sim {\pi_{\theta'}}}[{\frac{p_\theta (a_t|s_t)}{p_{\theta'} (a_t|s_t)} \frac{p_\theta (s_t)}{p_{\theta'}(s_t)} A^{\theta'}(s_t,a_t)}\nabla \log p_\theta (a_t^n|s_t^n)]\\ &=E_{(s_t,a_t)\sim {\pi_{\theta'}}}[{\frac{p_\theta (a_t|s_t)}{p_{\theta'} (a_t|s_t)}A^{\theta'}(s_t,a_t)}\nabla \log p_\theta (a_t^n|s_t^n)]\\ \end{aligned} \end{equation} \\
- 其中 A^{\theta}(s_t,a_t) 指的是 advantage 函数,其计算方式为加上衰减机制后的奖励值并减去基线。
- 由于 \frac{p_\theta (s_t)}{p_{\theta'}(s_t) } 的值难以计算,将其设置为 1,简化计算
目标函数可以表示为:
由于 \nabla f(x)=f(x)\nabla\log f(x) 再结合不定积分,目标函数可以表示为:
J^{\theta'}(\theta) = E_{(s_t,a_t)\sim \pi_{\theta'}}[\frac{p_\theta (a_t|s_t)}{p_{\theta'} (a_t|s_t)}A^{\theta'}(s_t,a_t)] \\
3. PPO/TRPO
为了消除重要性采样的缺陷的影响,以下为两种方式
- PPO(Proximal Policy Optimization)
- 算法:
- 初始化策 略网络参数 \theta^0
- 在每次迭代过程中:
- 使用 \theta^k 与环境互动以收集 \{s_t,a_t\},并计算出 advantage 值 A^{\theta^k}(s_t,a_t)
- 更新 \theta 优化 J_{PPO}(\theta)
- 目标函数:
{PPO\ algorithm:}\\ J^{\theta^k}_{PPO}(\theta) = J^{\theta^k}(\theta) - \beta KL(\theta,\theta^k)\\ J^{\theta^k}(\theta) = E_{(s_t,a_t)\sim \pi_{\theta^k}}[\frac{p_\theta (a_t|s_t)}{p_{\theta^k} (a_t|s_t)}A^{\theta^k}(s_t,a_t)]\approx\sum_{(s_t,a_t)}\frac{p_\theta (a_t|s_t)}{p_{\theta^k} (a_t|s_t)}A^{\theta^k}(s_t,a_t)\\ \\
自适应 KL 惩罚:如果 KL(\theta,\theta^k)>KL_{\max},增大 \beta;如果 KL(\theta,\theta^k)<KL_{\min} ,减小 \beta
{PPO2\ algorithm:}\\ J^{\theta^k}_{PPO2}(\theta) \approx \sum_{(s_t,a_t)} \min(\frac{p_\theta (a_t|s_t)}{p_{\theta^k} (a_t|s_t)}A^{\theta^k}(s_t,a_t),clip(\frac{p_\theta (a_t|s_t)}{p_{\theta^k} (a_t|s_t)},1-\varepsilon,1+\varepsilon)A^{\theta^k}(s_t,a_t)) \\
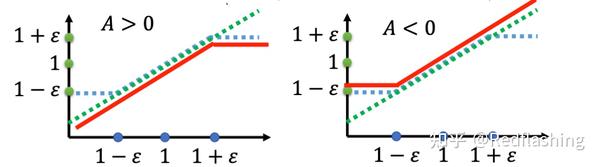

- TRPO(Trust Region Policy Optimizatio)
J^{\theta'}_{TRPO}(\theta) = E_{(s_t,a_t)\sim \pi_{\theta'}}[\frac{p_\theta (a_t|s_t)}{p_{\theta'} (a_t|s_t)}A^{\theta'}(s_t,a_t)]\\ KL(\theta,\theta') < \delta \\
TRPO 和 PPO 在各个测试上性能差不多。但相比 PPO ,TRPO 计算要更复杂
参考
- https://spinningup.openai.com/en/latest/algorithms/ppo.html
- https://openai.com/research/openai-baselines-ppo
- https://huggingface.co/blog/deep-rl-ppo
- https://huggingface.co/blog/rlhf
文章被以下专栏收录
