
机器学习-SVM



今天给大家讲解下如何用SVM进行房价预测(回归预测)和鸢尾花分类预测。
整个程序大概分以下几个步骤:


1.载入数据:(这里我们载入sklearn自带的数据集,load_boston波士顿房价数据)
#1.导入数据集
from sklearn.datasets import load_boston
boston = load_boston()
# print(boston)
# print(boston.DESCR)
# print(boston.feature_names)
# print(boston.data)
# print(boston.target)
x = boston.data
y = boston.targetx就是我们要给机器进行学习的特征,如房间大小,位置,房间数等等,
y就是我们要得到的预测结果(房价)
2.将数据分割成训练集和测试集:为什么要这么做呢?从字面上看,我们其实可以理解,训练集,就是我们要给机器进行训练学习的数据。测试集是当机器进行训练学习完毕后,我们对训练结果的一个检验。
#2.将数据分割成训练集和测试集
from sklearn.model_selection import train_test_split
#随机采样33%作为测试 67%作为训练
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0.33, random_state=43)
# print(train_x.shape) #训练集输入特征
# print(test_x.shape) #测试集输入特征
# print(train_y.shape) #训练集的目标值(房价)
# print(test_y.shape) #测试集的目标值(房价)3.数据标准化:为什么要进行数据标准化,例如房间的面积数值一般在十位到百位之间,而房间的卧室数量一般在各位数之间,在比如房屋的均价,一般都是万位(买不起啊!),这样数值较大的指标,在评价模型中的绝对作用就会显得较为突出和重要,而数值较小的指标,其作用则可能就会显得微不足道。为了消除不同变量之间性质、量纲、数量级等特征属性的差异,将其转化为一个无量纲的相对数值,也就是标准化数值,使各指标的数值都处于同一个数量级别上,从而便于不同单位或数量级的指标能够进行综合分析和比较。
#3.数据标准化
from sklearn.preprocessing import StandardScaler
ss_x = StandardScaler()
train_x = ss_x.fit_transform(train_x)
test_x = ss_x.transform(test_x)(如果大家感兴趣,可以把标准化这段代码注销掉在跑遍模型,你会发现和进行标准化的数据之间准确率的差距)
4.创建SVM回归模型,得到房价预测结果:其实机器学习并不是很复杂,很多方法科学家们和大神已经帮我们封装好了,我们只需要拿来用就可以了。(这里我们一般只要记住 SVR用于回归预测(房价预测),SVC用于分类预测)
#4.创建SVM回归模型,得到房价预测结果
from sklearn.svm import SVR #SVR用于回归预测,SVC用于分类预测大家记住
boston_svr = SVR()
boston_svr.fit(train_x, train_y)
#训练集train_x的预测结果
boston_svr_train_y_predict = boston_svr.predict(train_x)
print(boston_svr_train_y_predict)这里我们会看到我们对训练集数据进行学习并产生的预测结果。
5.准确率:模型训练完成后,我们也产生了对训练集的预测结果,模型的效果如何,我们要怎么看呢,下面我们来进行准确率的计算。这里我们记住,回归预测和分类预测准确率计算的方法是不一样的,这里大家一定要弄清楚。
#5.准确率
from sklearn.metrics import r2_score #r2_score我们是用在回归预测的准确率判断,对于分类预测准确率的判断我们用 accuracy_score
#训练集的准确率
boston_train_acc = r2_score(train_y, boston_svr_train_y_predict)
print('训练集的准确率{}'.format(boston_train_acc))

6.保存模型:模型训练好后,我们一定想要保存模型,那要如何保存呢?大家放心,保存的方法也是很简单的就两行代码。
#6.保存模型成sklearn自带的文件格式
from sklearn.externals import joblib
joblib.dump(boston_svr, './model/boston_svr.pkl')我在项目文件夹下,建立了一个model文件夹,大家可以根据自己的需要把boston_svr.pkl保存到自己需要的位置
7.加载模型:模型既然保存好了,那我们就要拿来使用,如何使用我们保存好的模型进行房价预测呢,其实也很简单。
#7.加载模型boston_svr.pkl
boston_svr_model = joblib.load('./model/boston_svr.pkl')
boston_svr_test_y_predict = boston_svr_model.predict(test_x) #使用加载的模型对测试数据进行预测
print(boston_svr_test_y_predict)这里我们用加载的模型对测试集的数据进行了预测,并产生了预测值。
我们来看看我们模型对测试数据的准确率如何
#测试集的准确率
boston_test_acc = r2_score(test_y, boston_svr_test_y_predict)
print('测试集的准确率{}'.format(boston_test_acc))

整体来说。svm对房价预测(回归预测)的方法基本算是讲完了,当然,其中svm还有好多细节大家可以去学习,例如 svm有几个核函数,我们可以通过改变不同的核函数,来提升模型预测的准确率。
如果大家要把预测结果给别人看,可以进行数据可视化,把结果以图形的形式显示出来
#绘图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置图形大小
plt.figure(figsize=(8, 4), dpi=80)
plt.plot(range(len(test_y)), test_y, ls='-.',lw=2,c='r',label='真实值')
plt.plot(range(len(boston_svr_test_y_predict)), boston_svr_test_y_predict, ls='-',lw=2,c='b',label='预测值')
# 绘制网格
plt.grid(alpha=0.4, linestyle=':')
plt.legend()
plt.xlabel('number') #设置x轴的标签文本
plt.ylabel('房价') #设置y轴的标签文本
# 展示
plt.show()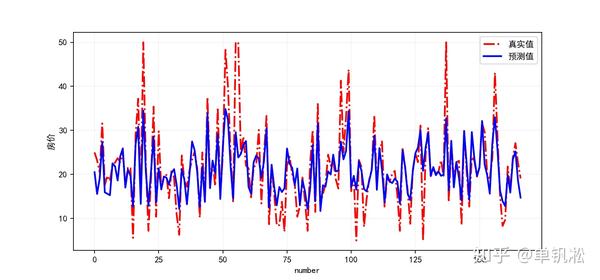

通过图形,我们可以直观的看出,我们的预测值和真实值还是有很大差距的,模型还是有很大改善空间的,大家可以试试其他机器学习方法。例如我们常听说的随机深林(提示,要是预测房价这类回归预测,要用随机深林的回归方法,RandomForestRegressor,可别用错了分类方法RandomForestClassifier)
上面给大家讲了,使用 SVM进行房价预测(回归预测),下面要给大家讲讲,如何用SVM进行数据分类预测,鸢尾花数据集分类预测,方法步骤大致跟房价预测基本一致,只是有以下2点不同
1.在进行分类预测时,我们使用svc 不使用svr
2.在进行准确率评估时,我们使用的是accuracy_score。
大家记住这两点就可以了,下面是预测模型的全部代码。
#鸢尾花数据进行分类预测
#1.导入数据集
from sklearn.datasets import load_iris
iris = load_iris()
# print(iris)
# print(iris.DESCR) #数据基本情况
# print(iris.target_names) #3类鸢尾花的名称
# print(iris.data)
# print(iris.target)
x = iris.data
y = iris.target
#2.将数据分割成训练集和测试集
from sklearn.model_selection import train_test_split
#随机采样30%作为测试数据,70%作为训练数据
train_x, test_x, train_y, test_y = train_test_split(x, y, train_size=0.7, random_state=43)
print(train_x.shape)
print(test_x.shape)
print(train_y.shape)
print(test_y.shape)
#3.数据标准化
from sklearn.preprocessing import StandardScaler
ss_x = StandardScaler()
train_x = ss_x.fit_transform(train_x)
test_x = ss_x.transform(test_x)
#4.创建SVM分类模型,得到鸢尾花分类预测结果
from sklearn.svm import SVC ##SVR用于回归预测,SVC用于分类预测大家记住
iris_svc = SVC()
iris_svc.fit(train_x,train_y)
#训练集train_x的预测结果
iris_svc_train_y_predict = iris_svc.predict(train_x)
print(iris_svc_train_y_predict)
#5.准确率
from sklearn.metrics import accuracy_score # #r2_score我们是用在回归预测的准确率判断,对于分类预测准确率的判断我们用 accuracy_score
#训练集的准确率
iris_train_acc = accuracy_score(train_y, iris_svc_train_y_predict)
print('训练集的准确率{}'.format(iris_train_acc))
#6.保存模型
from sklearn.externals import joblib
joblib.dump(iris_svc, './model/iris_svc.pkl')
#7.加载模型
iris_svc_model = joblib.load('./model/iris_svc.pkl')
iris_svc_test_y_predict = iris_svc_model.predict(test_x) #使用加载的模型对测试数据进行预测
print(iris_svc_test_y_predict)
#测试集的准确率
iris_test_acc = accuracy_score(test_y, iris_svc_test_y_predict)
print('测试集的准确率{}'.format(iris_test_acc))
#画图
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Reds) #画混淆矩阵图,配色风格使用cm.Reds,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
cm_plot(test_y, iris_svc_test_y_predict).show() #显示混淆矩阵可视化结果


我们会发现,svm在分类上的准确率还是蛮高的。
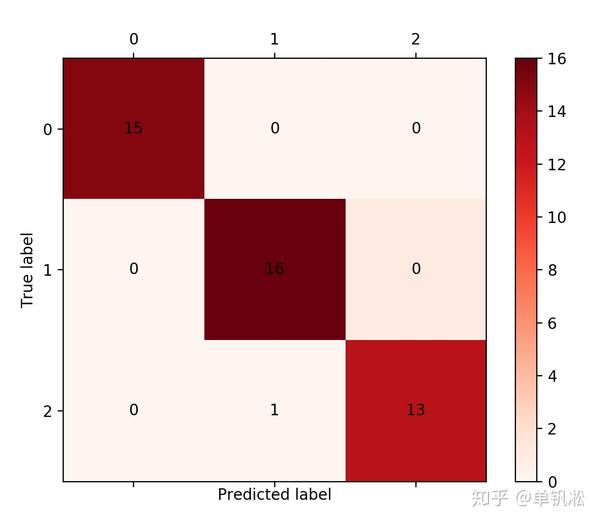

最后我们在把我们的预测结果显示出来。