
OPPO大数据诊断平台设计与实践

导读 在大数据行业中数据量大、任务多的背景下,如何做智能化、自动化的异常任务识别和分析至关重要。本文就将分享OPPO大数据诊断平台的设计与实践。
全文目录:
1. 背景
2. 技术方案
3. 时间效果
4. 总结与规划
分享嘉宾|戴巍 OPPO 数据平台架构师
编辑整理|依依 哔哩哔哩
内容审核|李瑶
出品社区|DataFun
01/背景
1.OPPO大数据现状


首先介绍一下OPPO大数据的现状。整体大数据的数据量已经超过了一亿,系统组件20+,整体离线任务达到百万级别,实时任务也有数千,整个公司的数据分析师和开发师超过了1000人。数据和任务的复杂情况也带来了系统级的复杂度,其中包括:
- 数据开发人员水平参差不齐,问题排查困难;
- 任务链路长,组件众多,运维复杂;
- 僵尸任务和不合理任务治理难度大;
2.业界产品对比


现在业界有一些类似的开源产品,比如Dr. Elephant,它是Linkedin开发并开源的,主要用来提高开发人员的效率和增加集群任务调试的高效性。
支持很多种计算引擎,例如Spark,Tez,MapReduce,同时也支持多种调度框架,比如Azkaban,Airflow等。并且能够形成分析报告,作为历史作业和工作流性能统计的指标。
通过我们的实践和测试,发现它存在一些不足之处。首先,它对于新版本的兼容性不够好;另外,支持的Spark诊断指标非常少,目前只有4个;诊断手段也相对较少;最后就是存在一些稳定性风险,因为它需要不断对Spark History的服务接口做频繁的调用,影响了整体的稳定性。
基于这样的背景,我们自研了一套大数据平台的任务诊断系统。
02/技术方案
1.平台特性


我们的平台具有以下一些特性:
- 首先,做到了非侵入式,即时诊断,无需修改已有的调度平台,即可体验诊断效果;
- 第二,支持OPPO自研调度平台以及多种主流开源调度平台,包括DolphinScheduler,Airflow等,并可进行工作流层面的异常诊断;
- 第三,在计算引擎和存储上面支持多版本的Flink、Hadoop、Spark;
- 第四,目前支持了40+ 离线和实时场景的异常类型判定,并仍在不断完善和丰富;
- 最后,支持自定义规则编写和异常阈值调整,可以针对不同场景自行调整。
诊断规则层面,可以通过效率分析、成本分析以及稳定性分析等,做任务诊断分析。在交互层面,首先提供了我们自己的Web UI,来查看整体的任务情况,也提供了Http API接口,这样可以将我们的任务诊断能力赋能给交互查询、任务调度和数据治理等数据应用。在交互查询上可以帮助开发人员快速做异常发现和任务排查,应用在任务调度上可以做后续任务的不断优化,在数据治理上可以提供健康分的概念,推动数据治理在集团当中的推广。
2.系统架构


系统架构主要分为三层:
- 外部系统适配层,将Yarn、调度器、计算引擎、集群状态、运行环境状态等指标收集到诊断系统当中;
- 诊断架构层,主要包括数据采集,元数据关联,数据模型标准化,异常检测以及诊断Portal模块;
- 底层是通用基础组件层。
3.流程阶段
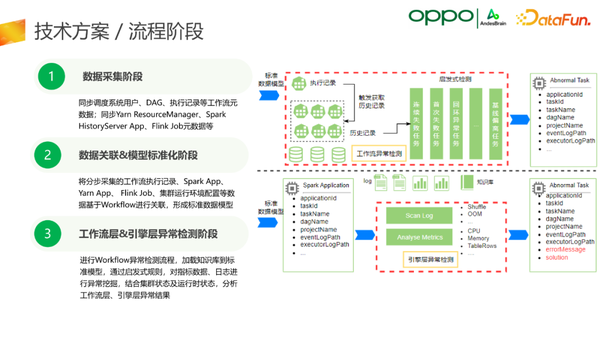

整体流程包括三大阶段:
- 首先是数据采集阶段,会将调度系统的DAG、用户、执行记录等工作流的元数据进行同步,在计算引擎采集Yarn、ResourceManager、Spark、Flink的元数据;
- 采集完成之后,会通过工作流的模式把各个组件的数据关联起来,并行成一个标准化的模型;
- 得到标准化模型之后,通过加载已有的知识库到标准模型,通过启发式规则,进行诊断和异常挖掘,并结合集群状态以及运行时状态做相关的分析,最终得到是否异常的结果。
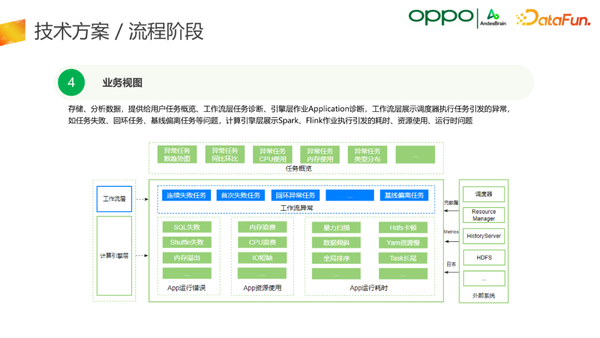

最终我们会将相关数据的存储和分析,通过直观、简洁的UI提供给业务方,帮助业务方及时准确地发现问题。
03/实践效果
下面我们来看一下诊断平台在我们公司内部的实践效果。
1.交互设计
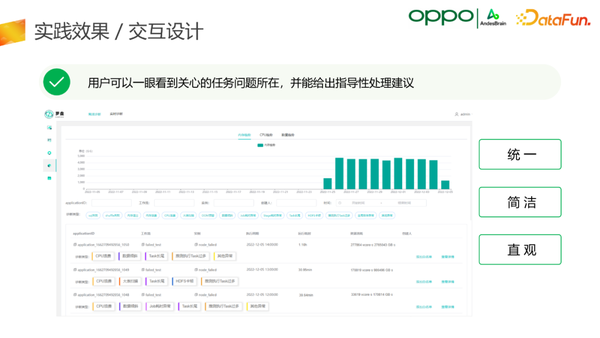

交互设计层面,我们做到了非常统一、简洁和直观的Web UI,这样用户可以一眼看到他所关心的任务问题所在,并且我们也会给出一些指导性处理建议。
2.诊断类型丰富
平台提供了较为丰富的诊断类型,针对离线、实时任务的健康度诊断,目前支持了40+ 场景的异常类型判定。整体上可分为四大方面:
- 效率分析方面,包括长尾Task分析、HDFS卡顿分析、推测执行过多分析,以及全局排序异常分析等;
- 稳定性分析方面,例如全表扫描问题、数据倾斜分析、Shuffle失败分析、内存溢出等;
- 实时作业分析,支持作业TM空跑、并行度不足、反压算子和慢算子的诊断等;
- 成本分析方面,包括CPU浪费分析、内存浪费分析、长期失败分析和任务耗时分析等。
3.效率分析案例


在效率分析方面,有一个长尾Task分析的案例。在整体的WEB界面可以明显看出哪些任务耗时是比较长的,拖慢了整个任务的运行时间。平台会给出一些分析和建议,比如是由于单个Task读取数据量过多或者读取数据过慢,如果读取数据量过多,可能是数据倾斜的问题,建议按照数据倾斜方式处理,如果是读取数据过慢,可能是HDFS集群节点负载过高或者是网络丢包等问题,可以联系运维相关同学进行进一步的排查。
4.成本分析案例


在成本分析方面,这里给出了一个CPU浪费分析的案例,在界面上面也能非常直观地看到每个Driver的cores的运行时间和空闲时间,可以设定一个阈值,当空闲时间超过阈值,就会判定为浪费,并且给出一个降低启用CPU数量的建议。
5.稳定性分析案例
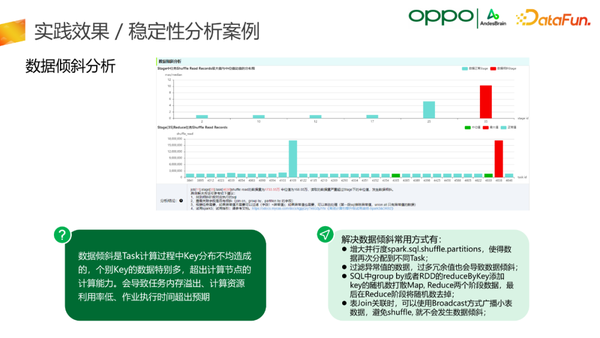

在稳定性分析方面,这里给出了一个数据倾斜分析的案例。数据倾斜是Task计算过程中Key分布不均造成的,个别Key的数据特别多,超出计算节点的计算能力,会导致内存溢出,计算资源利用率低,整体作业超时的问题。我们基于自身大量数据处理的经验,对如何处理这种问题进行了总结,如上图中所示。如果发现数据倾斜的异常,会给出相应的处理建议,结合业务方具体的任务去选择恰当的处理方式。
还有一些SQL的常见问题分析。比如没有权限、表不存在、语法错误等,因为我们在任务上线的时候会做一些SQL的校验,但是在运行过程中会出现权限失效,或者是表被修改了等等问题。我们也能够非常明确地给出问题和解决方法,比如重新去申请相应权限,或者修改SQL和表结构等。
6.实时分析案例


再来分享一个实时分析的案例。我们去跑Flink任务的时候,可以做一些诊断,给用户相关的建议,比如Flink参数设置不合理造成的CPU和内存的浪费,使用率是否过多,并且会给出建议值,比如数量建议是多少,任务的并行程度大概是多少,类似这样的诊断建议。
7.降本增效

最终我们通过异常任务、不合理任务的分析,转换成成本口径的统计,给到数据治理,形成健康分统一的口径,进行数据治理。这样在公司内部,通过长期的推进治理,可以看出成本下降明显,任务问题得到了改善。
04/总结与规划
最后来分享一下整体的总结和规划。
OPPO大数据诊断平台主要围绕的是调度引擎和计算引擎两个方面进行智能化定位分析,为用户快速处理和优化任务,为企业降本增效。
技术方面采用了非入侵方案对接其他系统,这样保证了其他系统的安全性。系统架构基于启发式规则定位和分析问题方式,但知识库比较依赖人员经验,目前计划引入一些数据挖掘算法扩大整体检测范围,实现更加智能化的诊断。目前支持Spark和Flink任务问题的诊断,除了OPPO自研的一些调度平台之外,还支持DolphinScheduler、Airflow等开源调度平台。
为了回馈开源社区,并且希望更多人参与进来,共同解决任务诊断的痛点和难题,我们现在已经把一些功能做了开源的处理,项目名称叫做“罗盘”。上图中给出了Github地址和微信群,大家有兴趣可以关注一下。
开源的版本主要支持DolphinScheduler和Airflow两种主流调度平台;同时支持多版本Spark、Hadoop 2.0和3.0任务日志诊断和解析;目前支持14种异常诊断类型;同时支持各种日志匹配规则编写和异常阈值调整,可自己根据实际场景进行优化。
05
问答环节
Q1:CPU浪费是如何计算出来的?
A1:我们之前相关的介绍文档已经通过公众号发出来了,里面会有比较详细的CPU浪费的计算公式。主要就是针对整体空闲时间和运行时间的计算,判断比例的情况,达到一定的阈值之后判断为浪费。
Q2:请问这里面的诊断是如何实现智能化的?使用的是一些什么样的模型?
回答:我们目前是基于知识库,相当于是基于历史的数据处理经验,智能化是我们仍在探索中的工作,后续还会将成果分享出来。


文章被以下专栏收录
