
python爬虫实战:京东网手机信息获取

唔,先说两句废话....
我一直认为学习是一个既枯燥又有趣的事情,而能够毕业直接从事与自己专业不一样的IT行业,我也有一点点心得:
- 千万不要打鸡血,然后学一天休三天,就像席慕蓉说过
“从云到雾到雨露 最后汇成流泉 也不过只是为了想让这世界知道, 反复与坚持之后, 柔水终成雕刀。”每天哪怕编程一个小时,进步也是肉眼可见的。
- 一定要敲代码,做实例,发现问题解决问题,而不是硬背一些API,python库的使用方法,这都是手册性的东西,Google就好了。


知乎上大佬太多了,我也只是记录一下这段时间做爬虫项目遇到的坑:
怎么使用python库?怎么储存到本地?
如何模拟浏览器,响应错误怎么解决?爬虫效率太低如何增大线程进程?怎么自动监听?
高深一点的,类似于 怎么将数据储存到Elasticsearch,爬虫的数据为动态js加载,如何用浏览器断点在json找到数据源,最后一些类似于scrapy框架,bs,newspaper库的使用等。
说句实话Python爬虫确实没什么智力要求,都是能学会的
我自己会通过几个简单的项目,非常详细的介绍每一步的内容,希望能帮助到新学爬虫的朋友,也希望能和大家一起共勉~
开始啦
实例一:
爬取京东网的手机图片:
1 urllib,re,os库的简单使用。
2静态 html页面的简单分析
3 正则等

首先我们打开京东首页,搜索手机后获取url地址:
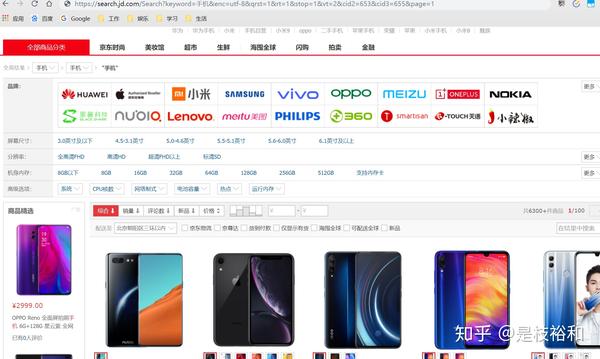

url=https://search.jd.com/Search?keyword=手机&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=1第一步:
然后我们打开编译器,引入三个基本的python库
import re
import urllib.request
import os然后我们测试一下:
html1 = urllib.request.urlopen(url).read()
print(html1)发现报错,原因如下:


重点一:
原来是在url中有“手机”两个中文字符,需要进行编译,可以用quote()函数对中文字符进行编码
ok,我们改写一下
url="https://search.jd.com/Search?keyword=手机&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=1"
key="手机"
key_code=urllib.request.quote(key)
code_url="https://search.jd.com/Search?keyword="+key_code+"&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq="+key_code+"&cid2=653&cid3=655&page="
html1 = urllib.request.urlopen(code_url).read()
print(html1)print以后发现没有问题。
第二步:
鼠标右键单击手机图片=》检查
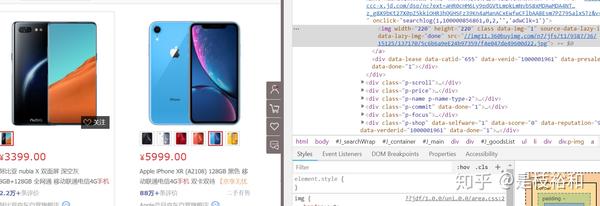

我们可以发现,图片所在的div 主要是在 <div class="p-img></div>的部分
(即你单击右键后控制台深蓝色的部分)
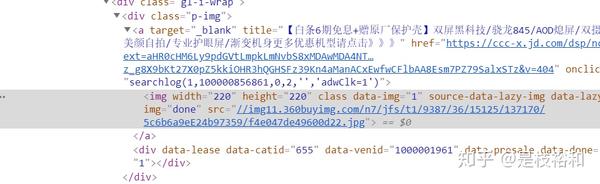

而通过观察div我们可以发现,我们想获取的图片在每个div的src部分:
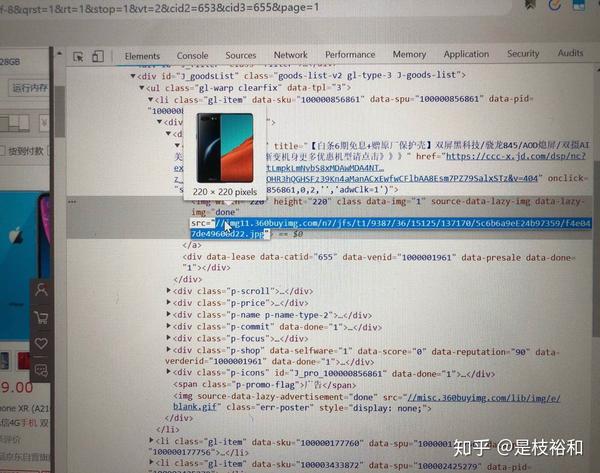

简而言之,我们要爬取的内容就是在<div class="p-img">下的<a>标签下<img>标签中的src部分。
而且通过观察多个图片可得,每个我们所要获取的图片的div都有class=“p-img” ,而<img>标识下有同样的source-data-lazy-img字段,唯一要修改的就是src地址(这个可以通过正则解决),我们可以通过两次过滤来解决这个问题。
第三步:
现在我们可以爬取url地址,并储存图片到本地了。


定义爬虫函数:
def craw(code_url,page): #定义函数craw
html1 = urllib.request.urlopen(code_url).read()
html1 = str(html1)
pat1 = '<div class="p-img".+'
result1 = re.compile(pat1).findall(html1)
result1 = result1[0]
pat2 = 'source-data-lazy-img="//(.+?).jpg" />'
imagelist = re.compile(pat2).findall(result1)- ·第一个正则是为了找到页面中<div class="p-img">的内容
pat1 = '<div class="p-img".+'- 第二个正则是为了找到图片的src
pat2 = 'source-data-lazy-img="//(.+?).jpg" />'(说实话正则真的是最令人讨厌的东西,我第二个写了很久,匹配出来还是少了jpg后缀,其实也没事,循环的时候自己加jpg就好了)
- compile.findall,简单来说就是在所有的html1页面中找到我们写的正则的东西,但是这个函数一些括号啊很重要,这里就不展开了。
re.compile(pat1).findall(html1)补充一下,关于贪婪和惰性匹配是正则最重要的东西,其他时候度娘就好了,反正也记不住
举例说明.+?与.+的区别:
<a href="xxx"><span>
如果用<.+>匹配,则匹配结果是
<a href="xxx"><span>
如果用<.+?>匹配,则匹配结果是
<a href="xxx">
也就是.+?只要匹配就返回了,不会再接着往下找了
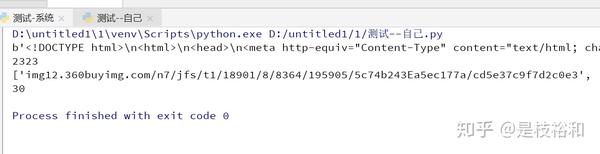

(最后的src没有jpg后缀,自己可以一步一步的print(pat1),print(pat2),看错误处在哪里。)
第四步:
src地址没有问题后,我们提取src文件储存到本地即可(提取的1=》3页的文件),代码如下:
x = 1
for imageurl in imagelist:
imagename = "D:/repfile/"+"第"+str(page)+"页图"+str(x)+".jpg"
imageurl = "http://"+imageurl+".jpg"
try:
urllib.request.urlretrieve(imageurl,filename=imagename)
except urllib.error.URLError as e:
if hasattr(e,"code"):
x+=1
if hasattr(e,"reason"):
x+=1
x+=1
for i in range(1,3):
code_url+str(i)
craw(code_url,i)这部分是URLerror的常用代码,如果有错误就跳过图片执行下一个。(过几天写个URLerror的小文章)
try:
urllib.request.urlretrieve(imageurl,filename=imagename)
except urllib.error.URLError as e:
if hasattr(e,"code"):
x+=1
if hasattr(e,"reason"):
x+=1
x+=1ok,最后图片成功保存到本地了:
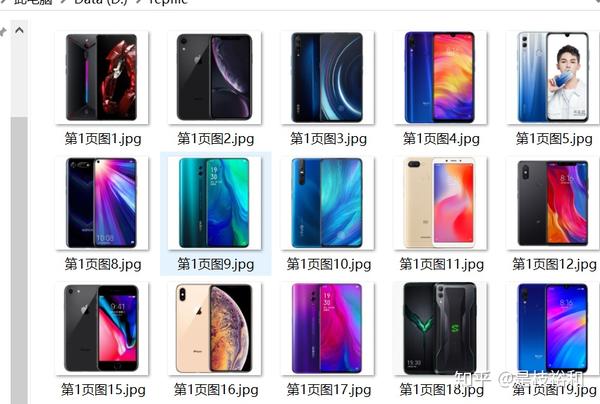

整体的代码如下,直接在pycharm或者用sublime中运行就好了,文件储存在D盘的repfile文件夹中:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# 爬取京东手机图片
import re
import urllib.request
import os
key = "手机"
key_code = urllib.request.quote(key)
# 需要爬取的页面
code_url = "https://search.jd.com/Search?keyword=" + key_code + "&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=" + key_code + "&cid2=653&cid3=655&page="
os.mkdir('d:\\repfile')
def craw(code_url, page): # 定义函数craw
html1 = urllib.request.urlopen(code_url).read()
html1 = str(html1)
pat1 = '<div class="p-img".+'
result1 = re.compile(pat1).findall(html1)
result1 = result1[0]
pat2 = 'source-data-lazy-img="//(.+?).jpg" />'
imagelist = re.compile(pat2).findall(result1)
x = 1
for imageurl in imagelist:
imagename = "D:/repfile/" + "第" + str(page) + "页图" + str(x) + ".jpg"
imageurl = "http://" + imageurl + ".jpg"
try:
urllib.request.urlretrieve(imageurl, filename=imagename)
except urllib.error.URLError as e:
if hasattr(e, "code"):
x += 1
if hasattr(e, "reason"):
x += 1
x += 1
for i in range(1, 3):
code_url + str(i)
craw(code_url, i)文章被以下专栏收录
