
Stata: 三重差分模型简介

作者:李琼琼 (山东大学)
Stata 连享会: 知乎 | 简书 | 码云 | CSDN | StataChina公众号
连享会 最新专题 直播
连享会-知乎推文列表
Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15
主讲:王存同 (中央财经大学);司继春(上海对外经贸大学)
课程主页: https://gitee.com/arlionn/YG | 微信版
http://qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13
主讲:杨海生 (中山大学);范巧 (兰州大学)
课程主页: https://gitee.com/arlionn/SP | 微信版
https://gitee.com/arlionn/DSGE (二维码自动识别)
1. 为什么使用三重差分法?
双重差分法的重要假设是对照组和实验组的时间趋势一样,而当控制组和实验组的时间趋势不同,则无法得到一致的实验估计量,需要进一步改进双重差分估计量。 平行趋势检验可以看往期推文 多期倍分法(DID):平行趋势检验图示。当选择的控制组与实验组时间趋势不同时,可以采用合成控制法(Synthetic Control Method)即对多个对照组加权构造成一个虚拟的对照组和三重差分法 (Difference in Difference in Difference) , 相比较合成控制法,DDD 操作更加简单,本期主要对三重差分法进行介绍。
通过下面具体的例子,我们来说明三重差分法的原理。假设美国 B 州针对 65 岁或以上的老年人 (实验组,Treat = 1) 引入一项新的医疗保健政策,其他年龄群体不适用。考察此政策对健康状况的影响,选用 B 州 65 岁以下群体 (old = 0) 作为对照组。由于人的健康状况随时间的变化并不是线性的,而不同年年龄组的个体的健康状况变化的时间趋势也存在差异,这会导致传统 DID 方法的前提条件——共同趋势假设 (Common Trend) 无法得到满足。简言之,实验组和对照组人群的健康状况随时间的变化趋势不一致。这种时间趋势差异的影响可以通过计算相邻的 A 州 65 岁及以上老年人和年轻群体相对健康情况变化差异来捕捉 (相当于再用一次 DID)。
Y_{ijt} = \alpha_0+ \color\green{\beta_1} \color\red{B_i \times old_j \times time_t} + \\ +\beta_2 B_i \times old_j+ \beta_3 B_i \times time_t+ \beta_4Treat_j \times time_t \\ +\gamma_1 \times B_i+\gamma_2 \times old_j+\gamma_3 \times time_t+\varepsilon_{ijt} \quad (1) \\
E( \overline{Y_{BO2}}) = \alpha_0 + \beta_1 +\beta_2 +\beta_3+\beta_4 +\gamma_1+\gamma_2+\gamma_3 E( \overline{Y_{BO1}}) = \alpha_0 +\beta_2+ \gamma_1+\gamma_2 E( \overline{Y_{BY2}}) = \alpha_0 + \beta_3+ \gamma_1+\gamma_3
E( \overline{Y_{BY1}}) = \alpha_0 + \gamma_1 E( \overline{Y_{AO2}}) = \alpha_0 +\beta_4+ \gamma_2+\gamma_3
E( \overline{Y_{AO1}}) = \alpha_0+\gamma_2 E( \overline{Y_{AY2}}) = \alpha_0 +\gamma_3
E( \overline{Y_{AT1}}) = \alpha_0
其中,E( \overline{Y_{B\color\red{O}\color\green{2}}}) 表示 B 州 65 岁以上老年人 (\color\red{O}ld) 在实施医疗保健政策 以后 (time = \color\green{2}) 的平均健康状况。其它变量的含义可以根据下标来确定,不再赘述。
经由 B 州 的 DID 可以得到 医疗政策差异 和 年龄差异 对健康的平均影响:
[E( \overline{Y_{BO2}}) - E( \overline{Y_{BO1}})] - [E( \overline{Y_{BO2}}) - E( \overline{Y_{BO1}})] =\beta_1+\beta_4 \quad (2a) \\
而经由 A 州 DID 得到的只是 年龄差异 对健康的平均影响:
[E( \overline{Y_{AO2}}) - E( \overline{Y_{AO1}})] - [E( \overline{Y_{AY2}}) - E( \overline{Y_{AY1}})] =\beta_4 \qquad (2b) \\
式 (2a) 减去式 (2b),即可得到 医疗政策效果 的平均效应 \beta_1。\beta_1 是我们在建立 DDD 模型时最感兴趣的估计系数。


连享会 最新专题 直播
2. 三重差分法案例及 Stata 实现
2007 年,中国开始实行 SO_2 碳排放权交易试点政策,先后批复了江苏、天津、浙江、河北、山西等 11 个排放权交易试点省份,但是还有很多省份没有作为试点地区。任胜钢等 (2019) 收集了不同地区不同行业在实施试点政策前后多年全要素增长率的数据,并使用双重差分法 (DID) 估计排污权对上市企业全要素的影响:
Y_{ijt} = \beta_0+\beta_1time*treat_2 + \lambda X + \gamma_t + \mu_i + \eta_j+\varepsilon_{ijt} \\
其中,Y_{ijt} 表示位于省份 i 行业 j 的企业在 t 年的全要素生产率,time 在排污权交易试点后取 1 否则取 0 ,treat_2 表示当试点企业位于试点地区时取 1 否则取 0 ,系数 \beta_1 即为排污权交易试点政策对全要素生产率的影响,X 表示一系列控制变量,\gamma_t 代表时间固定效应, \eta_j 代表行业固定效应,\mu_i 代表地区固定效应,\varepsilon_{ijt} 为随机误差项。
下面我们通过使用 任胜钢等 (2019) 在「中国工业经济」期刊主页上提供的数据 http://www.ciejournal.org/Magazine/show/?id=61750 对这一回归过程进行分析。
*-Notes:
* (1) tt 为试点前后和处理效应的交乘项,
* (2) zcsy-lnzlb 为控制变量,
* (3) SO2 ==1 表明样本均为排放 SO2 的上市企业
. use "https://gitee.com/arlionn/data/raw/master/data01/tfp_DDD.dta", clear
. reg lntfp tt zcsy lf age owner sczy lnaj lnlabor lnzlb ///
i.year i.area i.ind ///
if so2==1,cluster(area)
Linear regression Number of obs = 3,479
F(29, 30) = .
Prob > F = .
R-squared = 0.3707
Root MSE = .79017
(Std. Err. adjusted for 31 clusters in area)
--------------------------------------------------------------------------
| Robust
lntfp | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+----------------------------------------------------------------
tt | .2707783 .0660617 4.10 0.000 .1358623 .4056943
zcsy | .0128422 .002167 5.93 0.000 .0084166 .0172678
lf | -.0068839 .0060244 -1.14 0.262 -.0191875 .0054197
age | -.0043661 .0036656 -1.19 0.243 -.0118523 .0031201
owner | .098856 .0647004 1.53 0.137 -.0332799 .2309918
sczy | .0214466 .0073615 2.91 0.007 .0064125 .0364808
lnaj | .059886 .0275764 2.17 0.038 .0035674 .1162046
lnlabor | .159245 .0325336 4.89 0.000 .0928026 .2256874
lnzlb | .0624774 .0153048 4.08 0.000 .0312208 .093734回归结果显示排污权交易制度对全要素生产率的回归系数为 0.2708 (在 1% 的水平上显著),表明中国 SO_2 排污权交易试点政策显著提高了上市企业的全要素生产率。考虑到采用了 2004-2005 年的面板数据,下面使用控制个体特征的固定效应模型 (FE) 进行回归,结果依旧显著:
. use "https://gitee.com/arlionn/data/raw/master/data01/tfp_DDD.dta", clear
. xtreg lntfp tt zcsy lf age owner sczy lnaj lnlabor lnzlb ///
i.year i.company ///
if so2==1, cluster(area)
Random-effects GLS regression Number of obs = 3,479
Group variable: company Number of groups = 290
R-sq: Obs per group:
within = 0.1656 min = 11
between = 1.0000 avg = 12.0
overall = 0.5634 max = 12
Wald chi2(18) = .
corr(u_i, X) = 0 (assumed) Prob > chi2 = .
(Std. Err. adjusted for 31 clusters in area)
--------------------------------------------------------------------------
| Robust
lntfp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------+----------------------------------------------------------------
tt | .2768365 .0708105 3.91 0.000 .1380505 .4156225
zcsy | .0091712 .0017686 5.19 0.000 .0057048 .0126376
lf | -.0061996 .0061249 -1.01 0.311 -.0182043 .0058051
age | .003685 .0015579 2.37 0.018 .0006316 .0067385
owner | .2201731 .2733538 0.81 0.421 -.3155905 .7559367
sczy | .0064717 .0025088 2.58 0.010 .0015545 .011389
lnaj | .0772762 .0254718 3.03 0.002 .0273524 .1272
lnlabor | .0367946 .0538583 0.68 0.494 -.0687657 .142355
lnzlb | -.0155303 .0227497 -0.68 0.495 -.0601189 .0290583
--------------------------------------------------------------------------然而,双重差分估计策略存在潜在的问题,因为除了 SO_2 排放权交易试点之外,还可能存在其他政策对试点地区和非试点地区产生不一致影响,从而使估计结果进行偏差。需要用三重差分来克服这一问题,即需要找到另外一对不受 SO_2 排放权交易试点政策影响的“处理组”和“对照组”,因为非 SO_2 排放行业不受 SO_2 排污权交易政策影响,此时第二对处理组和对照组的差异只来源于其他政策的影响,将第一对处理组和对照组的差异(包含 SO_2 排污权交易政策和其他政策的差异)减去第二对处理组和对照组的其他政策的差异,得到 SO_2 排污权交易政策的净效应。基于以上分析,构建三重差分模型 (DDD) :
Y_{ijt} = \beta_0+ \beta_1time \times treat_2 \times group \\ + \beta_2time \times treat_2 + \beta_3time \times group \\ +\beta_4treat_2\times group\lambda X + \gamma_t + \mu_i + \eta_j+\varepsilon_{ijt}\\
其中,group 为虚拟变量,当企业属于 SO_2 排放行业时为 1 ,否则为 0,time*treat_2*group 为 1 时表示实施试点政策后处于试点地区的 SO_2 排放企业,估计系数 \beta_1 为“三重差分估计量”代表 SO_2 排放交易试点政策对企业全要素生产率的平均处理效果。回归结果如下:
*-Notes:
* ttt 为 time*treat*group 交乘项
* tt 为 time*treat 交乘项
* treats 为 treat*group 交乘项
* times 为 time*group 交乘项
* so2 代表 group 变量
. use "https://gitee.com/arlionn/data/raw/master/data01/tfp_DDD.dta", clear
. reg lntfp ttt tt treats times so2 zcsy lf owner age sczy lnaj lnlabor ///
lnzlb i.year i.area i.ind, cluster(area)
Linear regression Number of obs = 6,645
F(29, 30) = .
Prob > F = .
R-squared = 0.3603
Root MSE = .8086
(Std. Err. adjusted for 31 clusters in area)
--------------------------------------------------------------------------
| Robust
lntfp | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+----------------------------------------------------------------
ttt | .468231 .1063143 4.40 0.000 .2511083 .6853537
tt | -.1972127 .0811973 -2.43 0.021 -.3630397 -.0313858
treats | -.2544498 .1167903 -2.18 0.037 -.4929675 -.0159321
times | -.3633623 .0631812 -5.75 0.000 -.4923955 -.2343292
so2 | .2824561 .0746324 3.78 0.001 .1300363 .4348759
zcsy | .0143365 .0018823 7.62 0.000 .0104925 .0181806
lf | -.0041467 .003852 -1.08 0.290 -.0120136 .0037202
owner | .0381963 .0351867 1.09 0.286 -.0336645 .1100572
age | -.0041661 .0029964 -1.39 0.175 -.0102855 .0019533
sczy | .0265252 .0077333 3.43 0.002 .0107317 .0423186
lnaj | .0377505 .0218525 1.73 0.094 -.0068782 .0823793
lnlabor | .1899508 .0222101 8.55 0.000 .1445916 .2353099
lnzlb | .0694883 .0101917 6.82 0.000 .0486741 .0903024
--------------------------------------------------------------------------采用固定效应模型,回归结果如下:
. xtreg lntfp ttt tt treats times so2 zcsy lf owner age sczy lnaj ///
lnlabor lnzlb i.year i.company, cluster(area)
Random-effects GLS regression Number of obs = 6,645
Group variable: company Number of groups = 554
R-sq: Obs per group:
within = 0.2069 min = 10
between = 1.0000 avg = 12.0
overall = 0.5661 max = 12
Wald chi2(20) = .
corr(u_i, X) = 0 (assumed) Prob > chi2 = .
(Std. Err. adjusted for 31 clusters in area)
-------------------------------------------------------------------------
| Robust
lntfp | Coef. Std. Err. z P>|z| [95% Conf. Interval]
--------+----------------------------------------------------------------
ttt | .4508811 .1175351 3.84 0.000 .2205166 .6812457
tt | -.1780228 .0874499 -2.04 0.042 -.3494214 -.0066243
treats | .0546155 .0982847 0.56 0.578 -.1380189 .2472499
times | -.377584 .0705263 -5.35 0.000 -.515813 -.239355
so2 | .4183972 .087502 4.78 0.000 .2468965 .589898
zcsy | .0101169 .0015694 6.45 0.000 .007041 .0131929
lf | -.0040799 .0041514 -0.98 0.326 -.0122164 .0040567
owner | .1508904 .1394822 1.08 0.279 -.1224896 .4242705
age | -.0665185 .0064701 -10.28 0.000 -.0791997 -.0538373
sczy | .0100423 .0035932 2.79 0.005 .0029998 .0170848
lnaj | .049198 .0188378 2.61 0.009 .0122766 .0861194
lnlabor | .0715992 .0329644 2.17 0.030 .0069902 .1362082
lnzlb | .0041533 .0144601 0.29 0.774 -.0241879 .0324946
-------------------------------------------------------------------------无论使用 OLS 估计还是个体固定效应模型估计,回归系数 \beta_1 均为为 0.45 以上(在1%的水平上显著),表明三重差分估计 SO_2 排污权交易试点政策对企业全要素生产率的平均促进效应要高于双重差分估计结果,说明双重差分估计可能低估了政策对企业生产效率的提高。
3. 三重差分法的其他应用 —— 作用机理的检验
法律制度如何影响企业债务成本?如果仅从国家或者地区的法律差异来要考察企业债务成本问题,很可能受到遗漏变量、法律变量测度偏误等问题影响,难以清晰揭示法律环境对债务成本地影响。钱雪松等 (2019) 利用 2007 年中国正式通过了《物权法》作为自然实验,从法律变化引致的冲击的角度构造对照组和实验组,运用双重差分法,研究担保了物权制度改革可以降低企业债务融资成本。在采用双重差分之前,作者进行了平行趋势检验,结果表明在《物权法》出台之前两组企业债务成本变动维持相同的趋势,即平行趋势假设是满足的。这里,我们可能会想似乎三重差分检验是没有必要的。作者在这里为了进一步探索《物权法》降低企业的作用机理,从法律制度环境和市场化程度差异性切入,运用三重差分法检验物权改革对企业债务融资成本的影响是否表现出差异性。下面我们做详细分析。
DID 基准模型
Debtcost_{it} = \alpha_0+ \beta_1Low_i \times After_t+\beta_2 X_{it}+ \mu_i+ \lambda_t +\varepsilon_{it} \\
其中,Debtcost_{it} 表示企业 i 在时间 t 的融资成本。Low_i 表示在企业在实验组时取 1,After_t 为时间虚拟变量,样本观测值在《物权法》出台之后取 1,否则取 0, X_{it} 表示一系列控制变量。各变量的定义可见于下表。


加入法律制度环境的 DDD 模型
Debtcost_{it} = \alpha_0+ \beta_1 {\color\red {Low_i \times After_t \times Law_i}} \\ + \beta_2 Low_i \times After_t+ \beta_3Low_i \times Fin_i \\ + \beta_4After_i \times Law_i+\beta_2 X_{it}+ \mu_i+ \lambda_t +\varepsilon_{it} \\
其中,Law_i 是构造法律制度环境虚拟变量,当企业所在省份“市场中介组织的发育与法律制度环境指数”在 2006年 排名前 10 则 Law 取 1 ,否则取 0。在 Low*After 的仍旧显著为负的基础下,{\color\red {Low_i \times After_t \times Law_i}} 的系数显著为正,表明: 与法律制度环境较好的地区相比,《物权法》对债务成本的降低作用在法律制度环境较差的地区下影响更大。回归结果可见下表 (Panel A)。
加入金融市场化程度的 DDD 模型
Debtcost_{it} = \alpha_0+ \beta_1 \color \red {Low_i \times After_t \times Fin_i} \\ + \beta_2 Low_i \times After_t+ \beta_3Low_i \times Fin_i \\ + \beta_4After_i \times Fin_i+\beta_2 X_{it}+ \mu_i+ \lambda_t +\varepsilon_{it} \\
其中,Fin_i 是构造金融化程度的虚拟变量,当企业所在省份「金融业市场化指数」在 2006 年排名前 10 则 Fin 取 1,否则取 0。在 Low \times After 的仍旧显著为负的情况下,Low \times After \times Fin 的系数显著为正,表明:与金融市场化程度较高的地区相比,《物权法》对债务成本的降低作用在金融市场化程度较低的地区相对更大。回归结果可见下表 (Panel B)。
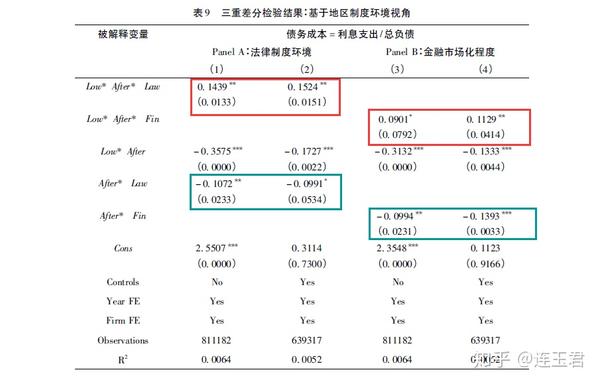

因此,在双重差分基础上,建立三重差分估计量可以进一步研究政策影响的异质性差异,更好地评估政策效应。
参考文献
- 高级计量经济学及 Stata 应用[M].高等教育出版社,陈强, 2014:343-344.
- 任胜钢,郑晶晶,刘东华,陈晓红.排污权交易机制是否提高了企业全要素生产率——来自中国上市公司的证据[J].中国工业经济, 2019(05):5-23.
- 钱雪松,唐英伦,方胜.担保物权制度改革降低了企业债务融资成本吗?——来自中国《物权法》自然实验的经验证据[J].金融研究, 2019(07):115-134.
相关课程
连享会-直播课 上线了!
http://lianxh.duanshu.com
免费公开课:
- 直击面板数据模型 - 连玉君,时长:1 小时 40 分钟
- Stata 33 讲 - 连玉君, 每讲 15 分钟.
- 部分直播课 课程资料下载 (PPT,dofiles 等)

Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15
主讲:王存同 (中央财经大学);司继春(上海对外经贸大学)
课程主页: https://gitee.com/arlionn/YG | 微信版
http://qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13
主讲:杨海生 (中山大学);范巧 (兰州大学)
课程主页: https://gitee.com/arlionn/SP | 微信版
https://gitee.com/arlionn/DSGE (二维码自动识别)

关于我们
- Stata 连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。 直播间 有很多视频课程,可以随时观看。
- 连享会-主页 和 知乎专栏,300+ 推文,实证分析不再抓狂。
- 公众号推文分类: 计量专题 | 分类推文 | 资源工具。推文分成 内生性 | 空间计量 | 时序面板 | 结果输出 | 交乘调节 五类,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。

连享会小程序:扫一扫,看推文,看视频……

扫码加入连享会微信群,提问交流更方便

文章被以下专栏收录
