面向应用的数据库评测基准





评测基准(benchmark)指一套用于评测、比较不同系统性能的规范。基准评测(benchmarking)指制定、利用评测基准,对系统进行评测的过程。


基准评测,一个是客观反映各系统的性能差距,第二是推动技术进步,形成良性竞争局面,第三是引导行业健康发展。




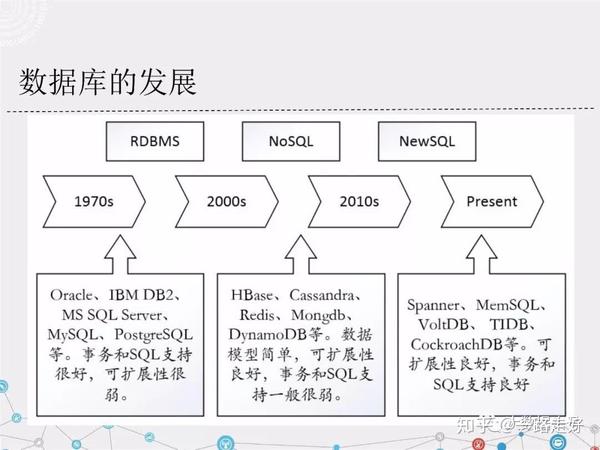



大数据管理系统处于高速发展、百花齐放的阶段BDMS系统功能、接口层次、架构、实现技术、面向应用和底层硬件不同。BDMS系统间的竞争比上世纪80年代RDBMS系统间的竞争更激烈,竞争环境更复杂。
系统类型和任务类型更为多样,基准评测有助于引领大数据管理系统和实现技术进入良性发展阶段。


TPCTC会议2012、2013年都以大数据环境下的基准评测为主要论题,欧盟第七框架项目2007年即开始资助新型评测基准的研究,以期实现新型数据环境下的“TPC”欧盟“地平线2020”科研计划将评测基准列
为2015年“大数据”主题的首要研究任务ICT 16 Big Data research (H2020-ICT-2015)企业和科研组织:
• Teradata: BigBench, BigData Top100
• Facebook: LinkBench
• AMPLab: Big Data Benchmark
• 中科院计算所: BigDataBench




研究目标:
• 一个是过仿真性,评测基准能够忠实模。
• 二是可适配性,评测基准能够通过配置,满足不同类型应用的模拟和评测需求。
• 三是可参考性,评测指标公平、客观、可用。
• 四是可扩展性,评测可满足不同的测试任务需求。
















随着客户端的增加,我的负载能够上去,这点也是能够增加的,也是能够支持的,我们这个组,现在定义了一个新的,模拟的是抢购任务,我们跟技术人员做过交互,我们定义了八张表,十一个负载,我们也实现了自己的工具,这个工具现在已经开源了,我们实现这个工具的同时,秉承着刚才四个维度上的控制,提供给用户的控制能力,去定义自己负载在资源上的竞争,模拟在时间维度上的变化,以及不同类型的负载本身的分布,我们都可以提供。
开源的网址在上面,如果大家感兴趣可以看一看。








我们根据PTCC做了相关的实验,当我们的数据库表大到一定程度,整体的性能是下降的,而不是数据库性能会上升,当你的表大的时候,我数据库的性能会下降,通过这样的方式,我去控制资源其实是比较难的。
第二点,我们通过函数的倾斜度控制负载对资源的竞争,当倾斜度变大,数据库性能下降,当负载落在数据级,相对来说大一点,整个数据库性能的影响其实是很小的,这几条线还是比较平的。我们可以提供两个参数,一个是冲突比例,一个是冲突参数,能够非常有效的看到资源的竞争对数据库性能的影响。




现在对于AP数据库测试常用的benchmark就是TPS-H,负载会更复杂,总量会更多。
TPC-H这种是的benchmark也是抽象于现实的应用,把现实中应用的共有和通用的负载出来。底层数据量和数据分布对于测试出来的数据库性能影响比较大,我们仅仅关注数据的分布,回答是否定的,我们用数据定义数据条件,我们测出来的结果跟真实应用测试出来的结果相差比较大,为什么?


这张图是TPC-H第三个,这是一个查询数,里面有很多算子,通过底层数据输入都会出来最终结果,中间结果以及最终结果级对于整个数据库性能测试影响是非常大的,所以我们就有个想法,我们要把负载,用户技术数据库测试的时候定义负载更大的权限,我们让他制定每一个负载中间结果及大小,我们把对负载约束的这种约束转成对于底层数据生成的约束,把数据约束和负载约束结合起来,满足用户测试需要的数据库。


负载特征分为三类,一个是负载类型,一个是负载分布,还有中间结果集大小,多种查询树物理树。现有的典型TPbenchmark在这方面的支持力度,支持力度还是比较小的,对于查询树的考虑基本没有,负载的约束有一些,中间结果的约束是通过负载约束转换成中间结果约束的。




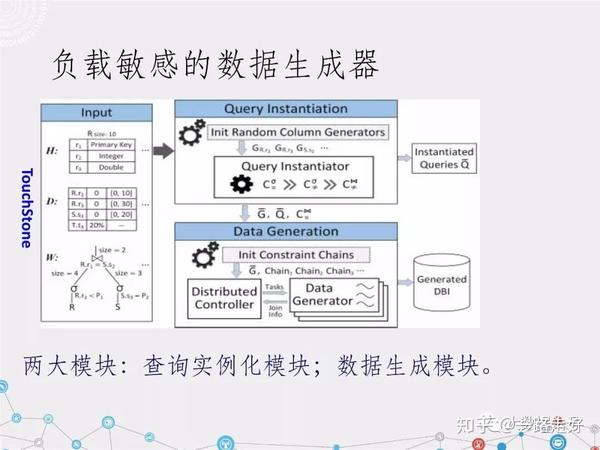
我们这个组在PT库测试的时候提供了负载敏感的数据生成器,主要考虑的负载特征有两类,中间两页我们到现在还没有解决,我们通过中间结果集的约束也转换成数据分布的约束进行并行的数据生成,我希望能够通过的生成一个数据库,同时生成一个数据库和相应的具有用户指定特征的负载集,测试你的AP库,这是我们做的工作,我们的解决主要分为两部分,所有的查询都是以参数的形式给出,用户只需要给出中间结果集,这样的查询相当于一个模式,作为操作,所有算子的选择率控制是通过参数,我们给出一组这样的负载,我们给出最基本的对于底层数据的约束,通过两个约束生成数据测试负载集,以及你的测试数据库。
这个方面的工作今天早晨我才知道被系统架构方面的顶级会议所接受。





我们数据生成器的效果,跟最新的工作比的,首先看一下我们数据生成的效果,随着节点的增加,整个数据生成速度是不停在上涨的,而且我的数据生成速度跟传统方法比高出了三个数量级,我们这边给出了一些查询的模式,我们这个查询模式可以比原来的Mbenchmark复杂多,我们可以解决前16个模式,只要指定中间结果集,我们都可以生成指定大小的数据库,满足负载的约束。
第三张图,我们需要知道表和表的约束,我们设计了一些特殊数据结果来管理表和表之间的关联关系,我们对于红色部分是非常小的,整个方法或者方案可扩展性是非常好的,我们保证生成的最终能够满足你的负载中间结果跟用户定义是一样的,我们的误差跟原有方法比已经远远的小于别人的误差。




以上就是我们在做数据库开发过程中对数据库评测的时候发现原有的benchmark所存在的问题,针对这些问题我们给出了方案,如果大家感兴趣可以去我们开源的地方看一下。
文章被以下专栏收录
